Thinking as Compression: Your Reasoning Model is Secretly a Context Compressor
Pith reviewed 2026-06-29 12:07 UTC · model grok-4.3
The pith
An LLM's own reasoning traces can compress long contexts more effectively than dedicated compression methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
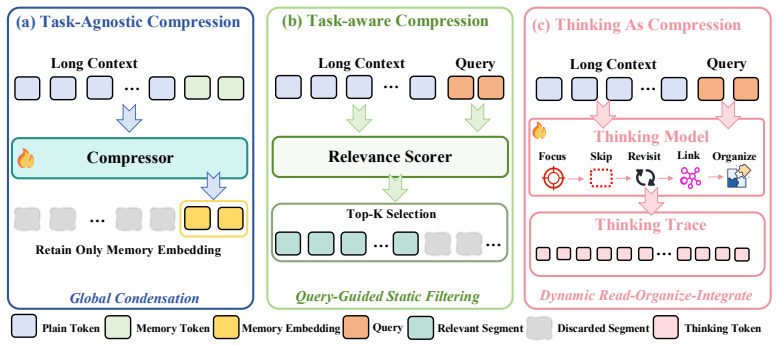
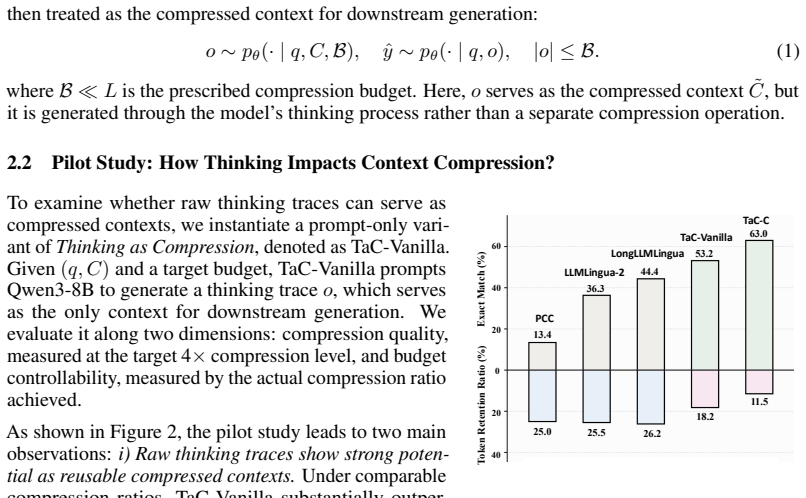
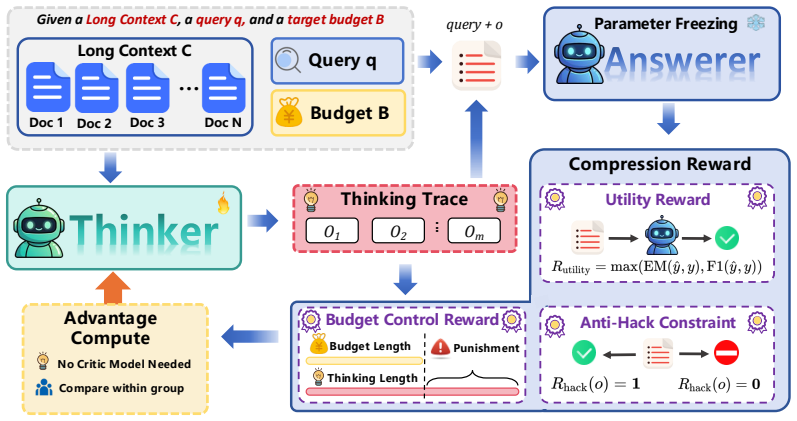
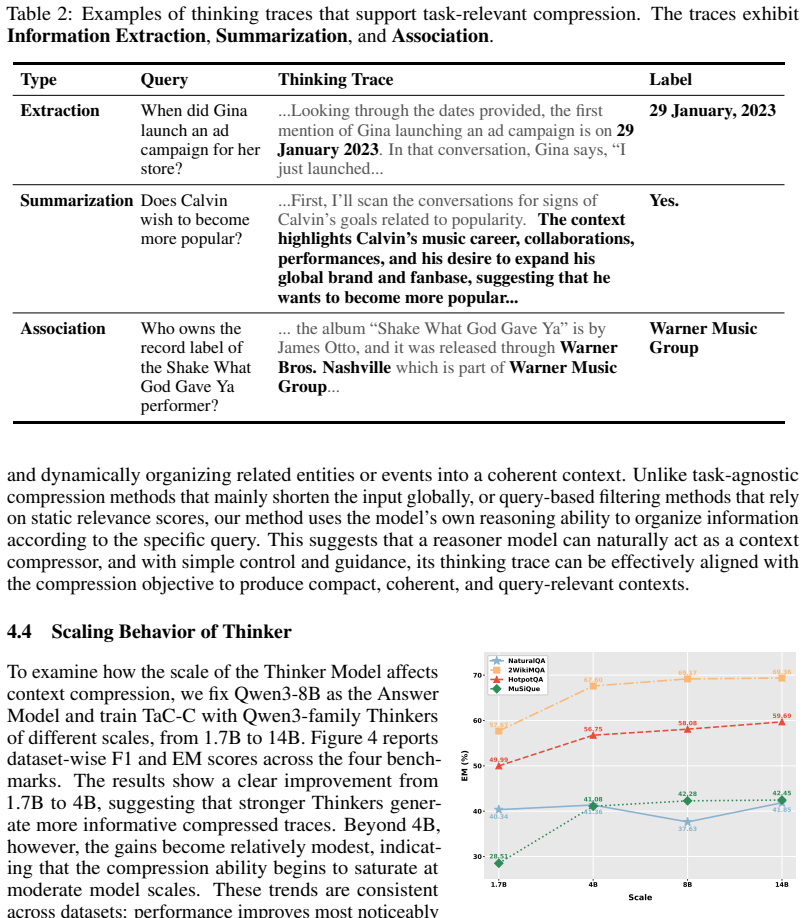
We reveal that a thinking model itself can naturally compress long contexts by organizing task-relevant information. We derive Thinking as Compression (TaC) that directly prompts the thinking model to generate thinking traces as the shortened context. Further, TaC-C leverages a reward-driven optimization framework to elicit compact and controllable compressed context, outperforming baselines on long-context QA benchmarks at 4x and 8x ratios.
What carries the argument
Thinking traces generated by direct prompting of the model, refined via reward-driven optimization to enforce length control and retain task information.
If this is right
- TaC-C outperforms the strongest baseline by 17.4% F1 and 15.7% EM at 4x compression.
- At 8x compression the gains rise to 23.4% F1 and 21.7% EM.
- Thinking traces require no separate compression module or task-specific training.
- Reward optimization controls length while retaining relevant information.
Where Pith is reading between the lines
- This suggests reasoning models may have an innate compression capability that could be unlocked for other long-input tasks.
- Future systems might integrate thinking-based compression to reduce inference costs without additional modules.
- Testing on tasks beyond QA could reveal if the approach generalizes or relies on question-specific structures.
Load-bearing premise
Optimizing the thinking process with rewards will produce traces that preserve all task-relevant details without hidden shortcuts that only succeed on the specific test questions used.
What would settle it
If TaC-C is evaluated on a held-out long-context QA dataset with questions crafted to expose potential shortcuts, and its scores fall below the strongest baseline, the claim of superior compression would be falsified.
Figures
read the original abstract
Context compression aims to shorten long context inputs with minimal information loss for LLM inference acceleration. While existing methods have shown promise, they typically rely on complex compression modules or compression-specific training, leaving the intrinsic capabilities of LLMs underexplored. In contrast, this work reveals that a thinking model itself can naturally compress long contexts by organizing task-relevant information. We thus derive Thinking as Compression (TaC), a new compression paradigm that treats thinking itself as compressed context. Without relying on specific dedicated compressor, TaC directly prompts the thinking model to generate thinking traces as the shortened context, already outperforming most representative compression methods. Further, given that raw thinking output may struggle with budget control and shortcut behaviors, we introduce Thinking as Compression Constrained (TaC-C), leveraging a simple reward-driven optimization framework to elicit intrinsic thinking as compact and controllable compressed context. Experiments across four long-context QA benchmarks demonstrate that TaC-C consistently outperforms existing baselines. At 4x and 8x compression ratios, it surpasses the strongest competitor by 17.4% and 23.4% in average F1, and by 15.7% and 21.7% in average Exact Match Score (EM), respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs' intrinsic thinking traces can serve as compressed context (TaC paradigm) without dedicated modules, and introduces TaC-C, a reward-driven optimization to produce compact, controllable traces. Experiments on four long-context QA benchmarks show TaC-C outperforming baselines, with gains of 17.4% and 23.4% in average F1 (and 15.7%, 21.7% in EM) at 4x and 8x compression ratios over the strongest competitor.
Significance. If the reported gains prove robust to controls for optimization procedure and evaluation, the result would be significant for showing that reasoning models have built-in compression ability, crediting the direct prompting of thinking traces and the constrained optimization framework as a lightweight alternative to complex compressor training. This could simplify context handling in LLM inference.
major comments (2)
- [Abstract] Abstract: The headline performance deltas (17.4%/23.4% F1 at 4x/8x) rest on TaC-C's reward-driven optimization, yet no information is supplied on reward formulation, whether optimization uses train vs. test splits of the four QA benchmarks, or equivalent optimization applied to baselines. This is load-bearing for the central claim that the traces represent general compression rather than benchmark-specific shortcuts.
- [§3] §3 (TaC-C framework): The description of the reward-driven optimization does not specify how the reward is derived from task metrics (F1/EM) or whether it incorporates length penalties and information-preservation terms in a way that prevents encoding of answers or dataset artifacts. Without this, the outperformance cannot be distinguished from optimization for evaluation artifacts.
minor comments (1)
- [Abstract] The abstract and early sections use 'thinking model' and 'reasoning model' interchangeably without a precise definition or citation to the specific model family used in experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in the TaC-C optimization details. We address each major comment below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance deltas (17.4%/23.4% F1 at 4x/8x) rest on TaC-C's reward-driven optimization, yet no information is supplied on reward formulation, whether optimization uses train vs. test splits of the four QA benchmarks, or equivalent optimization applied to baselines. This is load-bearing for the central claim that the traces represent general compression rather than benchmark-specific shortcuts.
Authors: We agree that the current manuscript does not supply sufficient detail on these points. In the revised version we will expand both the abstract and §3 to specify the reward formulation, confirm that optimization was performed only on the training splits of the four benchmarks (with validation used for hyperparameter selection), and report that we applied an analogous reward-driven procedure to the strongest baseline for direct comparison. These additions will make explicit that the reported gains are not attributable to test-set leakage or un-controlled optimization differences. revision: yes
-
Referee: [§3] §3 (TaC-C framework): The description of the reward-driven optimization does not specify how the reward is derived from task metrics (F1/EM) or whether it incorporates length penalties and information-preservation terms in a way that prevents encoding of answers or dataset artifacts. Without this, the outperformance cannot be distinguished from optimization for evaluation artifacts.
Authors: We acknowledge that §3 currently lacks an explicit mathematical description of the reward. The reward combines the downstream F1/EM score with a length penalty and an auxiliary term that penalizes direct leakage of answer spans (detected via string matching against the gold answer). We will revise §3 to present the full reward equation and explain how the penalty terms discourage answer encoding and dataset-specific shortcuts. This change will allow readers to evaluate whether the gains reflect general compression rather than artifact exploitation. revision: yes
Circularity Check
No significant circularity; empirical claims rest on independent benchmarks
full rationale
The paper introduces TaC as a conceptual reframing (thinking traces as compressed context) and TaC-C via reward optimization, then reports empirical gains on four long-context QA benchmarks. No equations, derivations, or self-citations are shown that reduce the reported F1/EM improvements to the optimization inputs by construction. The performance numbers are presented as held-out experimental comparisons rather than tautological outputs of the fitting process itself. This is the common case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can follow prompts to produce task-relevant thinking traces
- domain assumption Reward-driven optimization can improve compactness without harming downstream accuracy
Reference graph
Works this paper leans on
-
[1]
Y . Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. In Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024
2024
-
[2]
Chirkova, T
N. Chirkova, T. Formal, V . Nikoulina, and S. Clinchant. Provence: efficient and robust context pruning for retrieval-augmented generation. 2025
2025
-
[3]
Y . Dai, J. Lian, Y . Huang, W. Zhang, M. Zhou, M. Wu, X. Xie, and H. Liao. Pretraining context compressor for large language models with embedding-based memory. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers), pages 28715–28732, 2025
2025
-
[4]
A. El-Kishky, A. Wei, A. Saraiva, B. Minaiev, D. Selsam, D. Dohan, F. Song, H. Lightman, I. Clavera, J. Pachocki, et al. Competitive programming with large reasoning models. arXiv preprint arXiv:2502.06807, 2025
-
[5]
No Mean Feat: Simple, Strong Baselines for Context Compression
Y . Feldman and Y . Artzi. Simple context compression: Mean-pooling and multi-ratio training. arXiv preprint arXiv:2510.20797, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
L. Feng, Z. Xue, T. Liu, and B. An. Group-in-group policy optimization for llm agent training. arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [7]
-
[8]
Gemma 4 26b a4b model card
Google DeepMind. Gemma 4 26b a4b model card. https://ai.google.dev/gemma/docs/ core/model_card_4, 2026. Accessed: 2026-05-04
2026
-
[9]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
R. Guo, Y . Liu, G. Ma, Y . Wang, Y . Zhang, L. Xia, K. Chen, Z. Sun, and D. Shi. When less is more: The llm scaling paradox in context compression. 2026
2026
-
[12]
Ho, A.-K
X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. In Proceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
2020
-
[13]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3, 2022
2022
-
[14]
Hwang, S
T. Hwang, S. Cho, S. Jeong, H. Song, S. Y . Han, and J. C. Park. Exit: Context-aware extractive compression for enhancing retrieval-augmented generation. 2024
2024
-
[15]
Jiang, Q
H. Jiang, Q. Wu, X. Luo, D. Li, C.-Y . Lin, Y . Yang, and L. Qiu. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers), pages 1658–1677, 2024
2024
-
[16]
Jiang and M
Y . Jiang and M. Bansal. Avoiding reasoning shortcuts: Adversarial evaluation, training, and model development for multi-hop qa. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 2726–2736, 2019
2019
-
[17]
B. Jin, H. Zeng, Z. Yue, J. Yoon, S. Arik, D. Wang, H. Zamani, and J. Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Kwiatkowski, J
T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Lee, et al. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:453–466, 2019
2019
-
[19]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[20]
D. Li, S. Cao, T. Griggs, S. Liu, X. Mo, E. Tang, S. Hegde, K. Hakhamaneshi, S. G. Patil, and M. Zaharia. Llms can easily learn to reason from demonstrations structure, not content, is what matters! 2025
2025
- [21]
-
[22]
X. Li, G. Dong, J. Jin, Y . Zhang, Y . Zhou, Y . Zhu, P. Zhang, and Z. Dou. Search-o1: Agentic search-enhanced large reasoning models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420–5438, 2025
2025
-
[23]
Y . Li, Y . Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen. Snapkv: Llm knows what you are looking for before generation. Advances in Neural Information Processing Systems, 37:22947–22970, 2024
2024
- [24]
-
[25]
Lightman, V
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
2023
-
[26]
T. Lin, J. Xie, S. Yuan, and D. Yang. Implicit reasoning in transformers is reasoning through shortcuts. In Findings of the Association for Computational Linguistics: ACL 2025, pages 9470–9487, 2025
2025
-
[27]
Maharana, D.-H
A. Maharana, D.-H. Lee, S. Tulyakov, M. Bansal, F. Barbieri, and Y . Fang. Evaluating very long-term conversational memory of llm agents. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers), pages 13851–13870, 2024
2024
-
[28]
Z. Pan, Q. Wu, H. Jiang, M. Xia, X. Luo, J. Zhang, Q. Lin, V . Rühle, Y . Yang, C.-Y . Lin, et al. Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression. In Findings of the Association for Computational Linguistics: ACL 2024, pages 963–981, 2024
2024
-
[29]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
HybridFlow: A Flexible and Efficient RLHF Framework
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [31]
- [32]
- [33]
-
[34]
J. F. Ton, M. F. Taufiq, and Y . Liu. Understanding chain-of-thought in llms through information theory. 2024. 11
2024
-
[35]
Trivedi, N
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal. Musique: Multihop ques- tions via single-hop question composition. Transactions of the Association for Computational Linguistics, 10:539–554, 2022
2022
-
[36]
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, and D. Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Z. Wang, C. Li, Z. Yang, Q. Liu, Y . Hao, X. Chen, D. Chu, and D. Sui. Analyzing chain-of-thought prompting in black-box large language models via estimated v-information. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 893–903, 2024
2024
-
[38]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou, et al. Chain-of- thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
- [39]
-
[40]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, and C. Lv. Qwen3 technical report. 2025
2025
-
[41]
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
2018
-
[42]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[43]
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, W. Dai, T. Fan, G. Liu, L. Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [44]
-
[45]
Group Sequence Policy Optimization
C. Zheng, S. Liu, M. Li, X.-H. Chen, B. Yu, C. Gao, K. Dang, Y . Liu, R. Men, A. Yang, et al. Group sequence policy optimization. arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Tredici a tavola
K. Zhu, X. Feng, X. Du, Y . Gu, W. Yu, H. Wang, Q. Chen, Z. Chu, J. Chen, and B. Qin. An information bottleneck perspective for effective noise filtering on retrieval-augmented generation. 2024. A Implementation Details. All reinforcement learning experiments are implemented with VeRL [30] using a pure GRPO objec- tive [29, 10], without training a separat...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.