BIRDNet: Mining and Encoding Boolean Implication Knowledge Graphs as Interpretable Deep Neural Networks
Pith reviewed 2026-06-29 13:24 UTC · model grok-4.3
The pith
BIRDNet mines Boolean implication rules from tabular data and wires each rule into a dedicated hidden unit, producing sparse interpretable networks that stay within 0.02 AUROC of dense baselines while using up to 96 times fewer active param
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
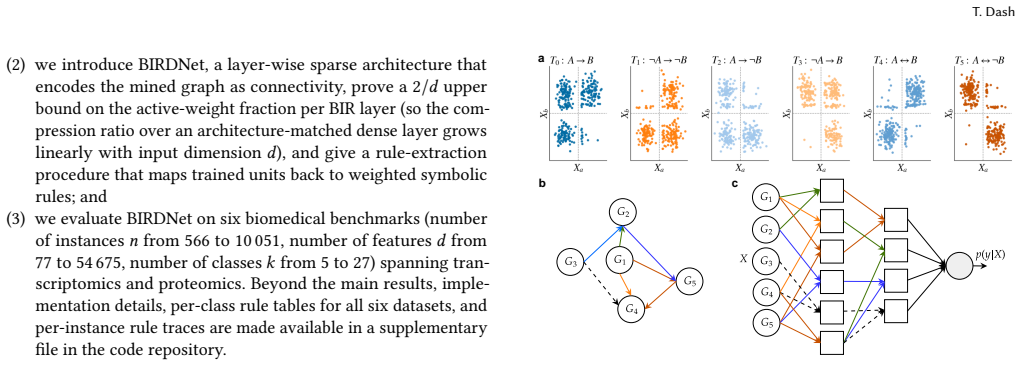
BIRDNet mines Boolean implication relationships with a sparse-exception binomial test to obtain a typed directed graph of 2-literal clauses, then encodes this graph as the connectivity of a layered neural network in which each hidden unit corresponds to one rule and binds only to its two features. The resulting architecture is sparse by construction, activating at most 2/d of the weights in each BIR layer, and remains interpretable because every trained unit keeps a stable symbolic identity so that rules can be read directly from the network. On six transcriptomic and proteomic benchmarks the model stays within 0.02 AUROC of the strongest dense baseline while using up to 96 times fewer activ
What carries the argument
The BIRDNet architecture that assigns each hidden unit to exactly one mined Boolean implication rule and connects it only to the two features in that rule.
If this is right
- Each BIR layer activates at most 2/d of its weights where d is the input dimension.
- First-layer units recover known biological signatures without any post-hoc analysis.
- The model requires no external rule base because the prior is mined directly from the training data.
- Rules remain readable from the network weights because each unit keeps a fixed symbolic identity.
- Accuracy stays within 0.02 AUROC of the strongest dense baseline on the six evaluated benchmarks.
Where Pith is reading between the lines
- The same mining-plus-wiring procedure could be applied to any tabular domain in which feature pairs carry stable implication structure.
- Because each unit is tied to a single rule, gradient updates may preserve the original symbolic meaning more reliably than standard sparsity penalties.
- The approach could be stacked with other layer types to combine rule-based and learned representations in deeper networks.
- Performance on very high-dimensional inputs would depend on how the binomial test scales when the number of candidate pairs grows quadratically.
Load-bearing premise
The Boolean implications identified by the sparse-exception binomial test are both statistically reliable and complete enough to serve as a useful structural prior when encoded as network layers.
What would settle it
On a held-out transcriptomic cancer dataset the first-layer rules extracted from a trained BIRDNet fail to match any of the previously reported canonical amplicons or lineage-defining modules, or the model's AUROC falls more than 0.02 below the matched dense MLP.
Figures
read the original abstract
Tabular data in knowledge-rich domains often carries a latent prior in the form of Boolean implication relationships (BIRs) between pairs of features. We mine such relationships with a sparse-exception binomial test. The mined implications form a typed directed graph, equivalent to a propositional rule base of 2-literal clauses. We encode this graph as the connectivity of a layered neural network, called BIRDNet, in which each hidden unit corresponds to one mined rule and binds only to its two features. We show two consequences of this design: First, the architecture is sparse by construction: at most $2/d$ of the weights in each BIR layer are active, where $d$ is the input dimension. Second, the model is interpretable: every trained unit keeps a stable symbolic identity, so rules can be read off the network without surrogate models. Unlike most neurosymbolic models, BIRDNet does not consume an external rule base; its structural prior is mined from the data. We evaluate BIRDNet on six transcriptomic and proteomic benchmarks. Our results show that BIRDNet stays within 0.02 AUROC of the strongest dense baseline, at a small accuracy cost, while using up to $96\times$ fewer active parameters than an architecture-matched dense MLP. First-layer rules recover known biological signatures across multiple cancer subtypes and tissue types, including canonical amplicons, lineage-defining co-expression modules, and immune-infiltration markers. Data and code are available at: https://github.com/MAHI-Group/BIRDNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BIRDNet, a neurosymbolic architecture that mines Boolean implication relationships (BIRs) from tabular data via a sparse-exception binomial test, encodes the resulting directed graph as the fixed sparse connectivity of a layered MLP (each hidden unit tied to one 2-literal rule), and evaluates the resulting model on six transcriptomic/proteomic classification tasks. It claims that the architecture is sparse by construction (at most 2/d active weights per BIR layer), remains within 0.02 AUROC of dense baselines while using up to 96× fewer active parameters, and yields directly interpretable first-layer rules that recover known biological signatures such as amplicons and immune markers.
Significance. If the mined BIRs prove statistically reliable, the work supplies a concrete route to data-driven structural priors that produce both parameter-efficient networks and human-readable symbolic units without requiring an external rule base. The open release of data and code at the cited GitHub repository is a clear strength that supports reproducibility.
major comments (2)
- [Methods (BIR mining)] Methods section on the sparse-exception binomial test: with d ≈ 20 000 features the test is applied to O(d²) pairs, yet the manuscript provides no mention of multiple-testing correction (Bonferroni, FDR, or otherwise) or power analysis. This directly affects the reliability of the structural prior that is wired into the first layer and is therefore load-bearing for both the performance-parity and biological-recovery claims.
- [Results (benchmark tables)] Results (performance tables): the claim that BIRDNet stays within 0.02 AUROC of the strongest dense baseline is presented without reported data splits, cross-validation folds, standard errors, or ablation of the mined graph versus random sparse wiring. These details are required to establish that the observed parity is attributable to the quality of the BIR prior rather than residual model capacity.
minor comments (2)
- [§3] Notation: the definition of the typed directed graph and its equivalence to 2-literal clauses should be stated once with a small example before the network-construction paragraph.
- [Figure 4] Figure captions: the legend for the biological-signature recovery plots should explicitly list the cancer subtypes and tissue types shown.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical rigor in BIR mining and experimental reporting. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Methods (BIR mining)] Methods section on the sparse-exception binomial test: with d ≈ 20 000 features the test is applied to O(d²) pairs, yet the manuscript provides no mention of multiple-testing correction (Bonferroni, FDR, or otherwise) or power analysis. This directly affects the reliability of the structural prior that is wired into the first layer and is therefore load-bearing for both the performance-parity and biological-recovery claims.
Authors: We agree that the manuscript does not discuss multiple-testing correction for the O(d²) pairwise tests performed by the sparse-exception binomial test. The test identifies implications via a stringent exception-rate threshold combined with a binomial p-value, but without explicit correction the false-positive rate across pairs could be inflated. In the revision we will add a dedicated paragraph describing the application of FDR control (Benjamini-Hochberg) at q < 0.05, report the resulting effective p-value threshold, and include a brief power analysis for the binomial test under the observed class imbalance. These additions will strengthen the justification for wiring the mined graph into the first layer. revision: yes
-
Referee: [Results (benchmark tables)] Results (performance tables): the claim that BIRDNet stays within 0.02 AUROC of the strongest dense baseline is presented without reported data splits, cross-validation folds, standard errors, or ablation of the mined graph versus random sparse wiring. These details are required to establish that the observed parity is attributable to the quality of the BIR prior rather than residual model capacity.
Authors: We acknowledge that the current tables omit explicit reporting of data splits, cross-validation procedure, standard errors, and an ablation against random sparse connectivity of matched density. The six benchmarks were evaluated with 5-fold cross-validation stratified by class label; we will add these details, report mean AUROC ± standard error across folds, and include a new ablation table that replaces the mined BIR edges with random edges while preserving the same sparsity pattern and layer widths. This will directly test whether performance parity depends on the semantic content of the mined implications. revision: yes
Circularity Check
No significant circularity; architecture and claims are self-contained by explicit construction and empirical evaluation
full rationale
The paper defines BIRDNet by mining BIRs via an external statistical test and wiring them into network connectivity; sparsity (at most 2/d active weights) and interpretability follow directly from this construction and are presented as design consequences rather than derived predictions. Performance results (within 0.02 AUROC of dense baselines, 96× fewer parameters) are empirical comparisons on benchmarks, not reductions to fitted quantities or self-citations. No load-bearing self-citation chains, ansatzes smuggled via prior work, or uniqueness theorems appear in the provided text. The derivation chain is independent of its inputs beyond the stated mining step.
Axiom & Free-Parameter Ledger
free parameters (1)
- significance threshold for binomial test
axioms (1)
- domain assumption The sparse-exception binomial test correctly identifies meaningful Boolean implications present in the data.
Forward citations
Cited by 1 Pith paper
-
$p$-adic Bi-Filtrations for Topological Machine Learning on Genomic Sequences
pVR uses a bi-filtration combining p-adic and compositional distances to generate topological features that improve classification accuracy on several low-sample genomic benchmarks.
Reference graph
Works this paper leans on
-
[1]
Rehan Akbani, Patrick Kwok Shing Ng, Henrica MJ Werner, Maria Shahmorad- goli, Fan Zhang, Zhenlin Ju, Wenbin Liu, Ji-Yeon Yang, Kosuke Yoshihara, Jun Li, et al. 2014. A pan-cancer proteomic perspective on The Cancer Genome Atlas. Nature communications5, 1 (2014), 3887
2014
-
[2]
Sebastian Bach, Alexander Binder, Grégoire Montavon, Frederick Klauschen, Klaus-Robert Müller, and Wojciech Samek. 2015. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PloS one10, 7 (2015), e0130140
2015
-
[3]
Christina Curtis, Sohrab P Shah, Suet-Feung Chin, Gulisa Turashvili, Oscar M Rueda, Mark J Dunning, Doug Speed, Andy G Lynch, Shamith Samarajiwa, Yinyin Yuan, et al. 2012. The genomic and transcriptomic architecture of 2,000 breast tumours reveals novel subgroups.Nature486, 7403 (2012), 346–352
2012
-
[4]
Tirtharaj Dash, Sharad Chitlangia, Aditya Ahuja, and Ashwin Srinivasan. 2022. A review of some techniques for inclusion of domain-knowledge into deep neural networks.Scientific Reports12, 1 (2022), 1040
2022
-
[5]
Haitham A Elmarakeby, Justin Hwang, Rand Arafeh, Jett Crowdis, Sydney Gang, David Liu, Saud H AlDubayan, Keyan Salari, Steven Kregel, Camden Richter, et al
-
[6]
Nature598, 7880 (2021), 348–352
Biologically informed deep neural network for prostate cancer discovery. Nature598, 7880 (2021), 348–352
2021
-
[7]
Samuele Fiorini. 2016. gene expression cancer RNA-Seq. UCI Machine Learning Repository. DOI: https://doi.org/10.24432/C5R88H
-
[8]
Artur d’Avila Garcez and Luis C Lamb. 2023. Neurosymbolic ai: The 3 rd wave. Artificial Intelligence Review56, 11 (2023), 12387–12406
2023
-
[9]
Clara Higuera, Katheleen J Gardiner, and Krzysztof J Cios. 2015. Self-organizing feature maps identify proteins critical to learning in a mouse model of down syndrome.PloS one10, 6 (2015), e0129126
2015
-
[10]
P Kauraniemi and A Kallioniemi. 2006. Activation of multiple cancer-associated genes at the ERBB2 amplicon in breast cancer.Endocrine-related cancer13, 1 (2006), 39–49
2006
-
[11]
Jianzhu Ma, Michael Ku Yu, Samson Fong, Keiichiro Ono, Eric Sage, Barry Dem- chak, Roded Sharan, and Trey Ideker. 2018. Using deep learning to model the hierarchical structure and function of a cell.Nature methods15, 4 (2018), 290–298
2018
-
[12]
Laetitia Marisa, Aurélien de Reyniès, Alex Duval, Janick Selves, Marie Pierre Gaub, Laure Vescovo, Marie-Christine Etienne-Grimaldi, Renaud Schiappa, Do- minique Guenot, Mira Ayadi, et al. 2013. Gene expression classification of colon cancer into molecular subtypes: characterization, validation, and prognostic value.PLoS medicine10, 5 (2013), e1001453
2013
-
[13]
Torsten O Nielsen, Forrest D Hsu, Kristin Jensen, et al. 2004. Immunohistochem- ical and clinical characterization of the basal-like subtype of invasive breast carcinoma.Clinical cancer research10, 16 (2004), 5367–5374
2004
-
[14]
Joel S Parker, Michael Mullins, Maggie CU Cheang, et al. 2009. Supervised risk predictor of breast cancer based on intrinsic subtypes.Journal of clinical oncology 27, 8 (2009), 1160–1167
2009
-
[15]
Aleix Prat, Joel S Parker, Olga Karginova, Cheng Fan, Chad Livasy, Jason I Herschkowitz, Xiaping He, and Charles M Perou. 2010. Phenotypic and molecular characterization of the claudin-low intrinsic subtype of breast cancer.Breast cancer research12, 5 (2010), R68
2010
-
[16]
Debashis Sahoo. 2012. The power of boolean implication networks.Frontiers in Physiology3 (2012), 276
2012
-
[17]
Debashis Sahoo, David L Dill, Andrew J Gentles, Robert Tibshirani, and Sylvia K Plevritis. 2008. Boolean implication networks derived from large scale, whole genome microarray datasets.Genome biology9, 10 (2008), R157
2008
-
[18]
Ashwin Srinivasan, A Baskar, Tirtharaj Dash, and Devanshu Shah. 2024. Compo- sition of relational features with an application to explaining black-box predictors. Machine Learning113, 3 (2024), 1091–1132
2024
-
[19]
Ashwin Srinivasan, Lovekesh Vig, and Michael Bain. 2019. Logical explanations for deep relational machines using relevance information.Journal of Machine Learning Research20, 130 (2019), 1–47
2019
-
[20]
Wenguan Wang, Yi Yang, and Fei Wu. 2024. Towards data-and knowledge-driven AI: a survey on neuro-symbolic computing.IEEE transactions on pattern analysis and machine intelligence47, 2 (2024), 878–899
2024
-
[21]
John N Weinstein, Eric A Collisson, Gordon B Mills, Kenna R Shaw, Brad A Ozenberger, Kyle Ellrott, Ilya Shmulevich, Chris Sander, and Joshua M Stuart
-
[22]
The cancer genome atlas pan-cancer analysis project.Nature genetics45, 10 (2013), 1113–1120
2013
-
[23]
Jeffrey A Whitsett, Susan E Wert, and Timothy E Weaver. 2010. Alveolar surfac- tant homeostasis and the pathogenesis of pulmonary disease.Annual review of medicine61, 1 (2010), 105–119
2010
-
[24]
Mengzhou Xia, Zexuan Zhong, and Danqi Chen. 2022. Structured pruning learns compact and accurate models. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1513–1528
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.