Skill-Conditioned Gated Self-Distillation for LLM Reasoning
Pith reviewed 2026-06-29 13:06 UTC · model grok-4.3
The pith
SGSD uses experience-derived skill banks to generate validated teacher signals for self-distillation in LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
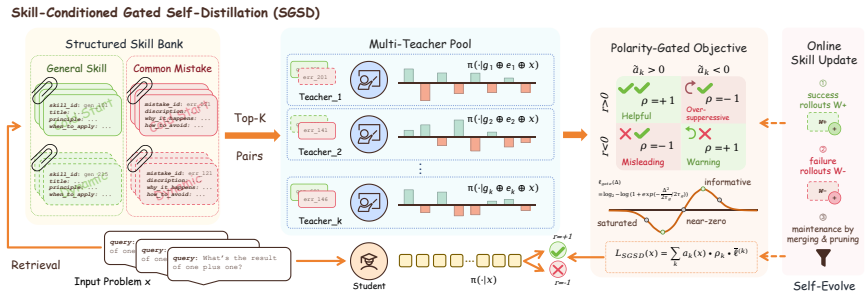
Skill-Conditioned Gated Self-Distillation formulates skill-based self-distillation as teacher hypothesis validation, where retrieved skills from an experience-derived bank are used to construct teachers whose polarity is verified, allowing a gated distillation objective to provide dense supervision from potentially noisy but reusable skills.
What carries the argument
The skill-conditioned multi-teacher pool with polarity validation by a verifier and a robust gated objective that distills informative teacher-student disagreements.
If this is right
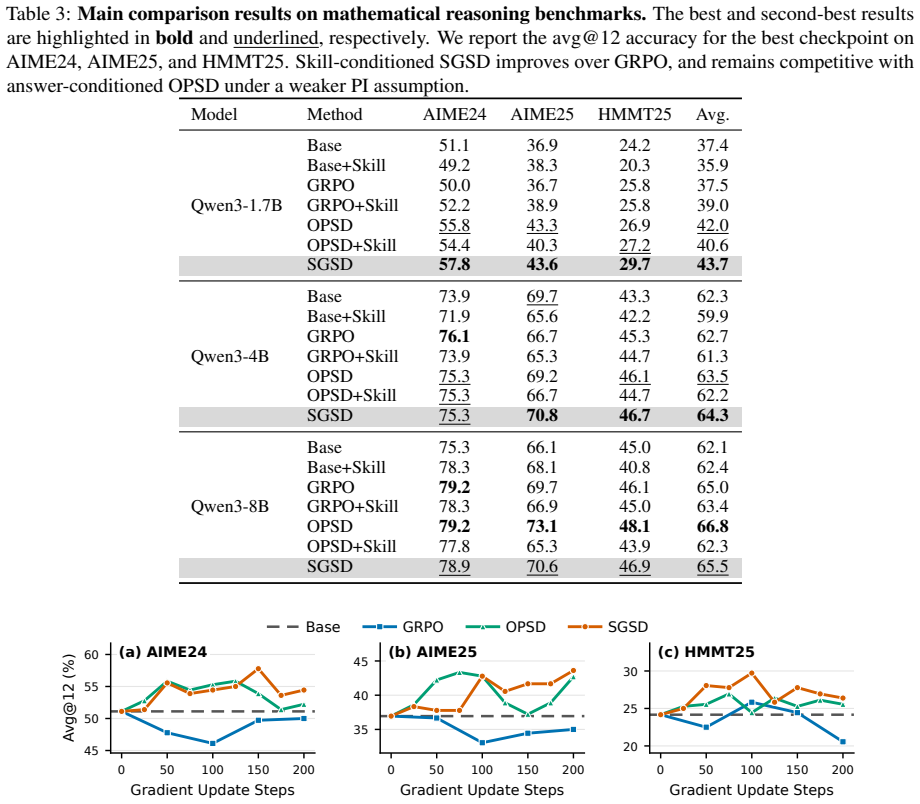
- SGSD consistently improves reasoning performance over GRPO on benchmarks like AIME24, AIME25, and HMMT25.
- It achieves this under a weaker assumption about privileged information compared to methods requiring reference answers.
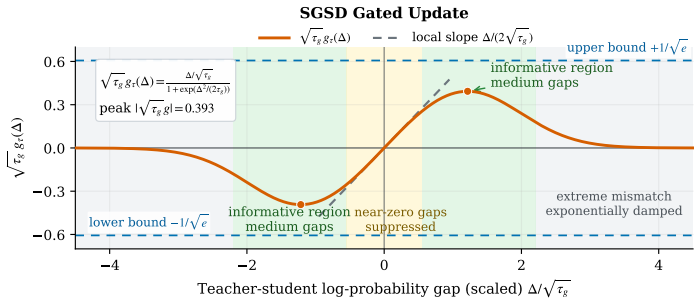
- The gated mechanism suppresses uncertain or extreme signals from irrelevant skills.
- Experiments show gains such as 6.2% over GRPO and 1.7% over OPSD on Qwen3-1.7B model.
Where Pith is reading between the lines
- Building skill banks incrementally from model rollouts could allow continuous improvement without external data.
- The polarity validation step might be applicable to other forms of noisy teacher signals in distillation setups.
- Testing on non-mathematical domains could reveal if reusable skills transfer beyond math reasoning.
Load-bearing premise
A verifier can accurately determine whether each skill-conditioned teacher supports a correct outcome or suppresses an incorrect one, even if some skills are irrelevant.
What would settle it
Running the method with a deliberately inaccurate verifier that misclassifies teacher polarities, resulting in no performance gain or worse results than GRPO on the same benchmarks.
Figures



read the original abstract
On-policy self-distillation (SD) improves LLM reasoning by using teacher-side privileged information (PI) to turn sparse verifier outcomes into dense token-level supervision. Existing methods usually assume trusted PI, such as reference answers or successful traces. We ask whether PI can instead come from an experience-derived skill bank, where retrieved skills are compact and reusable but may also be irrelevant or misleading. We propose Skill-Conditioned Gated Self-Distillation (SGSD), which formulates skill-based SD as teacher hypothesis validation rather than unconditional imitation. SGSD retrieves skill-mistake pairs, constructs a multi-teacher pool, and lets all skill-conditioned teachers score the same plain-prompt student rollout. The verifier validates each teacher's polarity: supporting a success or suppressing a failure gives positive supervision, while the opposite stance is reversed. A robust gated objective then distills informative teacher-student disagreements while suppressing uncertain or extreme signals. Experiments on multiple mathematical reasoning benchmarks show that SGSD consistently improves over GRPO and remains competitive with answer-conditioned OPSD under a weaker PI assumption. For example, on Qwen3-1.7B, SGSD outperforms GRPO by 6.2% and OPSD by 1.7% on average on AIME24, AIME25, and HMMT25. Our code is available at https://github.com/walawalagoose/SGSD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Skill-Conditioned Gated Self-Distillation (SGSD) for LLM reasoning, which derives privileged information from an experience-based skill bank rather than trusted sources such as reference answers. Skill-mistake pairs are retrieved to form a multi-teacher pool; each teacher scores the same student rollout, the verifier labels polarity (support/suppress), and a gated objective distills disagreements while suppressing uncertain signals. Experiments on mathematical reasoning benchmarks (AIME24, AIME25, HMMT25) report that SGSD outperforms GRPO by 6.2% and remains competitive with answer-conditioned OPSD on Qwen3-1.7B (average gains cited). Code is released at the provided GitHub link.
Significance. If the empirical gains hold under the weaker PI assumption, the work shows that compact, reusable skills can substitute for stronger privileged information in on-policy self-distillation, potentially improving scalability. Explicit release of code is a positive contribution to reproducibility. The significance is limited by the absence of statistical validation for the reported improvements and by the untested robustness of polarity validation against irrelevant retrievals.
major comments (2)
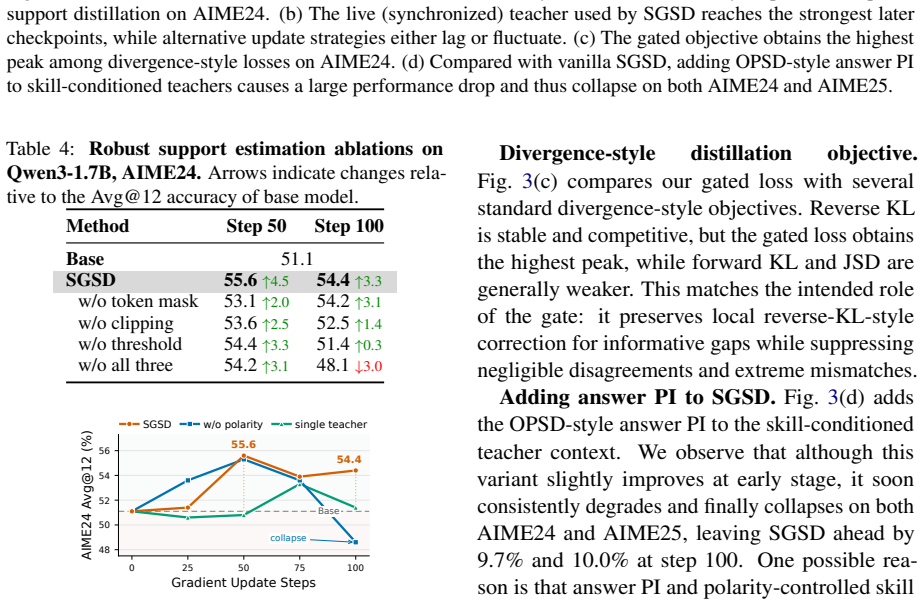
- [Method section (skill-conditioned teachers and gated objective)] The central claim that SGSD improves over GRPO rests on the gated objective successfully filtering signals from irrelevant or misleading skills. The manuscript supplies no formal bound on the fraction of irrelevant retrievals, no ablation isolating retrieval quality, and no analysis of how the gate threshold interacts with verifier noise when stance-to-outcome mapping breaks (see the description of the multi-teacher pool and gated objective).
- [Experiments and results] Table or results section reporting the 6.2% and 1.7% average gains on AIME24/AIME25/HMMT25 for Qwen3-1.7B: no error bars, dataset sizes, statistical tests, or cross-seed variance are provided, so it is impossible to determine whether the gains are distinguishable from noise or post-hoc selection.
minor comments (1)
- [Abstract] The abstract states 'multiple mathematical reasoning benchmarks' but lists only three; an explicit enumeration of all evaluated datasets would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address the two major comments point-by-point below. We plan to incorporate additional empirical analyses and statistical reporting in the revised manuscript while maintaining the core contribution under the weaker privileged-information assumption.
read point-by-point responses
-
Referee: [Method section (skill-conditioned teachers and gated objective)] The central claim that SGSD improves over GRPO rests on the gated objective successfully filtering signals from irrelevant or misleading skills. The manuscript supplies no formal bound on the fraction of irrelevant retrievals, no ablation isolating retrieval quality, and no analysis of how the gate threshold interacts with verifier noise when stance-to-outcome mapping breaks (see the description of the multi-teacher pool and gated objective).
Authors: We agree that the manuscript does not supply a formal theoretical bound on the fraction of irrelevant retrievals; our approach is primarily empirical and relies on the gated objective to suppress uncertain signals via verifier polarity. The multi-teacher pool and gated loss are explicitly motivated by the possibility of misleading skills, but we acknowledge the absence of an isolating ablation on retrieval quality and threshold sensitivity. In the revision we will add (i) an ablation varying the retrieval pool size and measuring downstream accuracy, and (ii) an appendix analysis of gate-threshold behavior under controlled verifier noise, including cases where stance-to-outcome mapping is deliberately broken. revision: yes
-
Referee: [Experiments and results] Table or results section reporting the 6.2% and 1.7% average gains on AIME24/AIME25/HMMT25 for Qwen3-1.7B: no error bars, dataset sizes, statistical tests, or cross-seed variance are provided, so it is impossible to determine whether the gains are distinguishable from noise or post-hoc selection.
Authors: We accept that the current results lack error bars, cross-seed variance, and statistical tests, which limits interpretability. The cited averages are computed on the official benchmark splits (30 problems for AIME24, 30 for AIME25, 20 for HMMT25). In the revision we will report means and standard deviations over three independent training seeds, include error bars in the main table, and add paired t-test p-values comparing SGSD against GRPO to establish whether the observed improvements are statistically distinguishable from run-to-run variance. revision: yes
Circularity Check
No significant circularity; empirical proposal without derivations
full rationale
The paper is an empirical method proposal for SGSD that describes a skill-retrieval and gated distillation procedure but contains no equations, derivations, or parameter-fitting steps that reduce predictions to inputs by construction. Claims rest on benchmark comparisons (e.g., gains over GRPO) rather than any self-definitional, fitted-input, or self-citation load-bearing chain. No uniqueness theorems, ansatzes smuggled via citation, or renamed known results appear; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Self-distillation zero: Self-revision turns bi- nary rewards into dense supervision.arXiv preprint arXiv:2604.12002. Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531. Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, ...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[2]
Trace2Skill: Distill Trajectory-Local Lessons into Transferable Agent Skills
Trace2skill: Distill trajectory-local lessons into transferable agent skills.arXiv preprint arXiv:2603.25158. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow in- structions with human feedback.Advances in ne...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open langua...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Skillrl: Evolving agents via recursive skill- augmented reinforcement learning.arXiv preprint arXiv:2602.08234. Donglai Xu, Hongzheng Yang, Yuzhi Zhao, Pingping Zhang, Jinpeng Chen, Wenao Ma, Zhijian Hou, Mengyang Wu, Xiaolei Li, Senkang Hu, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
From Exploration to Exploitation: A Two- Stage Entropy RLVR Approach for Noise-Tolerant MLLM Training.arXiv preprint arXiv:2511.07738. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others
-
[6]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. 2026. Self-distilled rlvr. arXiv preprint arXiv:2604.03128. Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. 2026. On-policy context distillation for language models.a...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
MemSkill: Learning and Evolving Mem- ory Skills for Self-Evolving Agents.arXiv preprint arXiv:2602.02474. Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. 2024. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642. Siyan Zhao, Zhihui Xie,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Derive 1-3 GENERAL skills that likely contributed to the success
-
[9]
Each skill must be broadly reusable across algebra, geometry, number theory, combinatorics, and olympiad-style reasoning
-
[10]
Phrase each skill as an actionable principle; avoid task-specific constants, entity names, or one-off details unless they express a general method
-
[11]
Merge overlapping ideas inside this response; do not output near-duplicate skills
-
[12]
Successful memory: {memory_json} Return ONLY valid JSON with key general_skills
Use only evidence grounded in the provided memory. Successful memory: {memory_json} Return ONLY valid JSON with key general_skills. Table 7: Prompt template for extracting reusable positive skills from successful cold-start memories. Prompt: Common-Mistake Extraction from a Failed Memory You are an expert at analyzing failed mathematical reasoning and tur...
-
[13]
Derive 1-3 COMMON mistakes that explain the failure
-
[14]
Each item must describe a general failure mode, why it happens, and how to avoid it in future math reasoning
-
[15]
Make every item broadly reusable across algebra, geometry, number theory, combinatorics, and olympiad-style reasoning
-
[16]
Merge overlapping ideas inside this response; do not output near-duplicate mistakes
-
[17]
Failed memory: {memory_json} Return ONLY valid JSON with key common_mistakes
Use only evidence grounded in the provided memory. Failed memory: {memory_json} Return ONLY valid JSON with key common_mistakes. Table 8: Prompt template for extracting reusable mistake patterns from failed cold-start memories. or reversed. For boundedness, 1 + exp ∆2 2τg ≥exp ∆2 2τg ,(36) and hence |gτ(∆)| ≤ |∆| τg exp − ∆2 2τg .(37) The right-hand side ...
-
[18]
Merge semantically duplicate or strongly overlapping skills
-
[21]
Treat recurrence as evidence that the pattern is systematic and synthesize one stronger skill
-
[23]
General skills to merge: {items_json} Return ONLY valid JSON with key general_skills
Do not mention specific problems, source memories, or dataset names. General skills to merge: {items_json} Return ONLY valid JSON with key general_skills. Table 9: Prompt template for hierarchically merging general-skill candidates. Prompt: Common-Mistake Merging You are an expert at consolidating independently-generated math failure lessons into a compac...
-
[24]
Merge semantically duplicate or strongly overlapping mistakes
-
[25]
Preserve all unique insights
-
[26]
Prefer the most general, transferable wording
-
[27]
Treat recurrence as evidence that the failure pattern is systematic and synthesize one stronger mistake item
-
[28]
Do not force a fixed final count
-
[29]
Common mistakes to merge: {items_json} Return ONLY valid JSON with key common_mistakes
Do not mention specific problems, source memories, or dataset names. Common mistakes to merge: {items_json} Return ONLY valid JSON with key common_mistakes. Table 10: Prompt template for hierarchically merging common-mistake candidates. Finally, consider locally close teacher and stu- dent distributions at a fixed historyh t, and define ∆v = logp T (v|h t...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.