{Ω}-QVLA: Robust Quantization for Vision-Language-Action Models via Composite Rotation and Per-step Scaling
Pith reviewed 2026-06-29 12:41 UTC · model grok-4.3
The pith
Omega-QVLA enables uniform W4A4 quantization of entire VLA models including their diffusion action heads without training or mixed precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
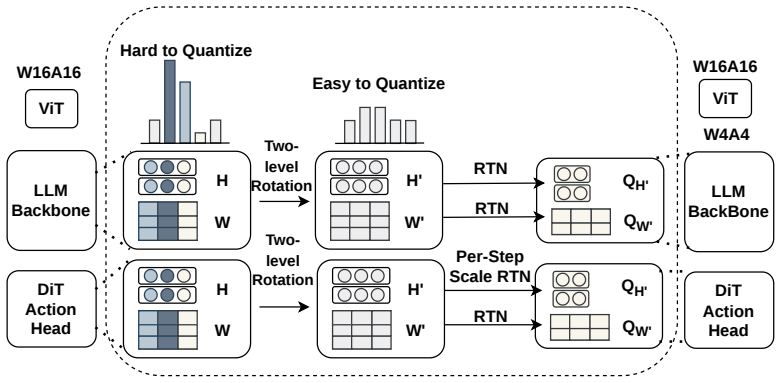
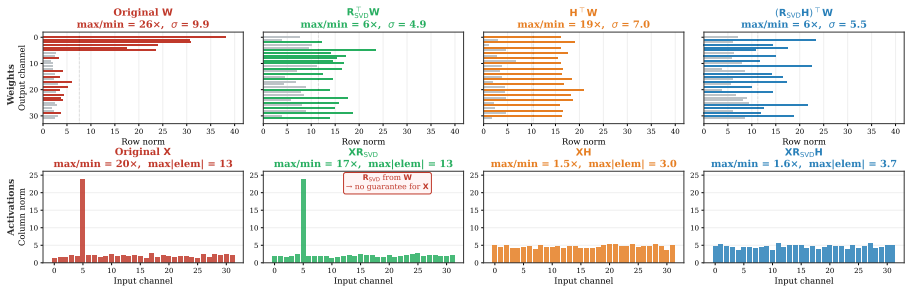
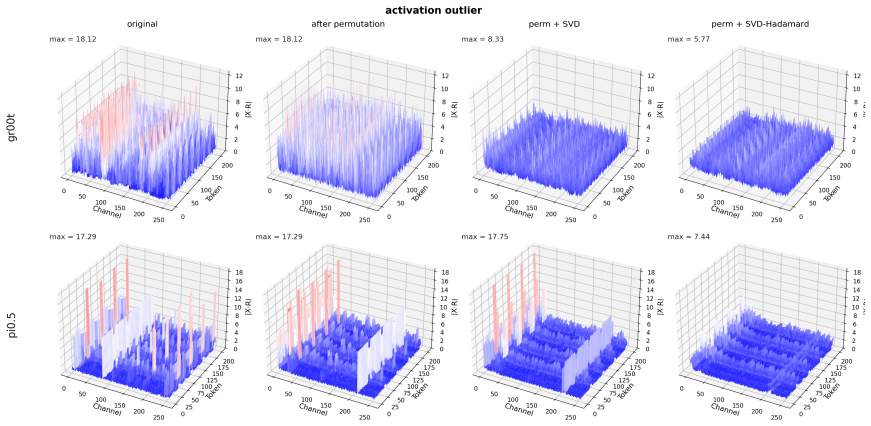
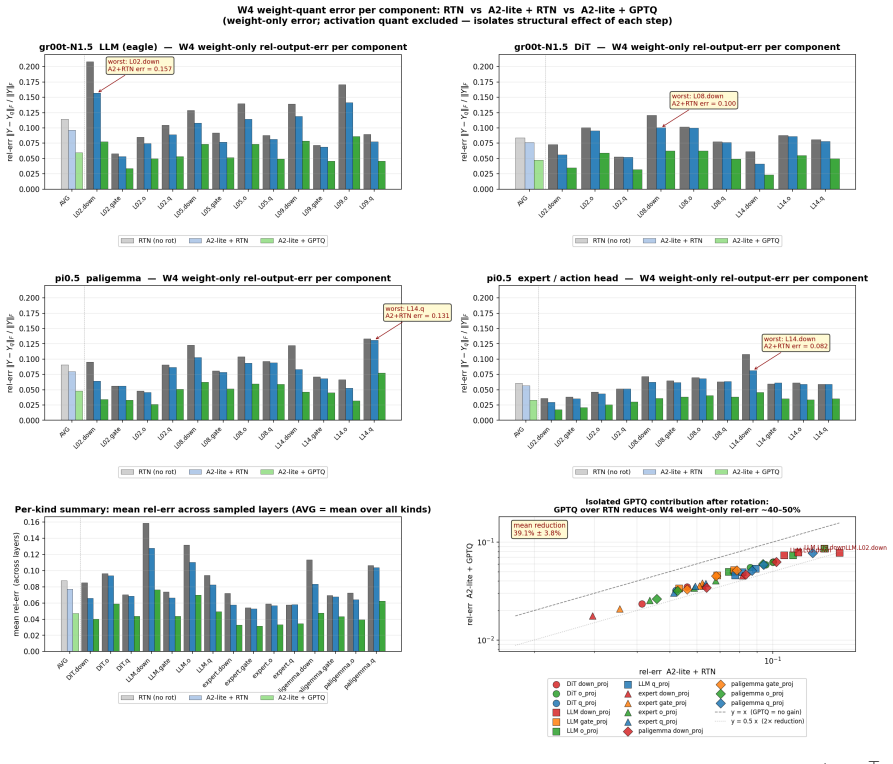
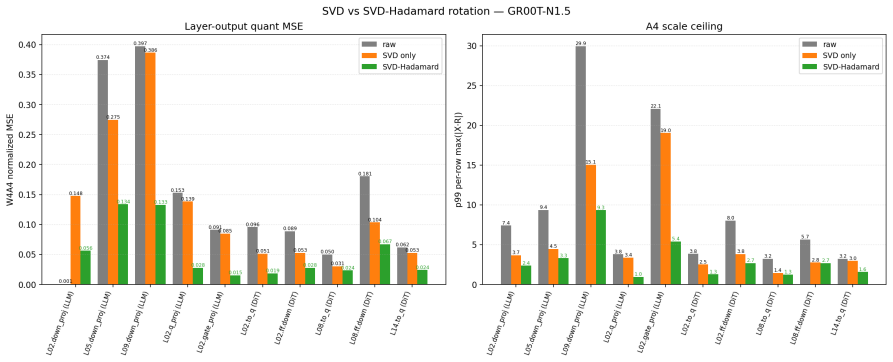
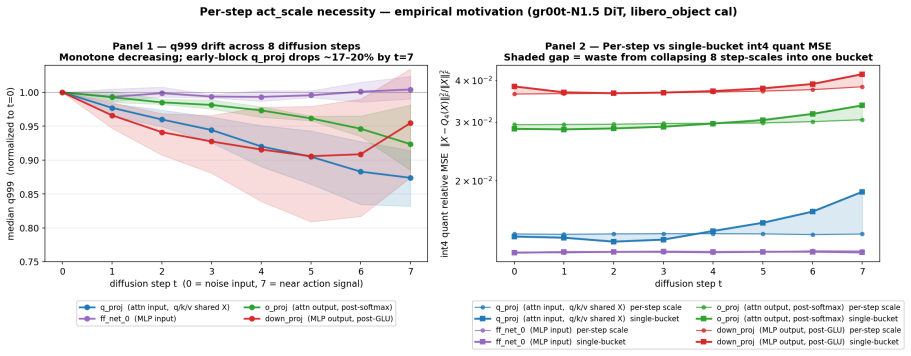
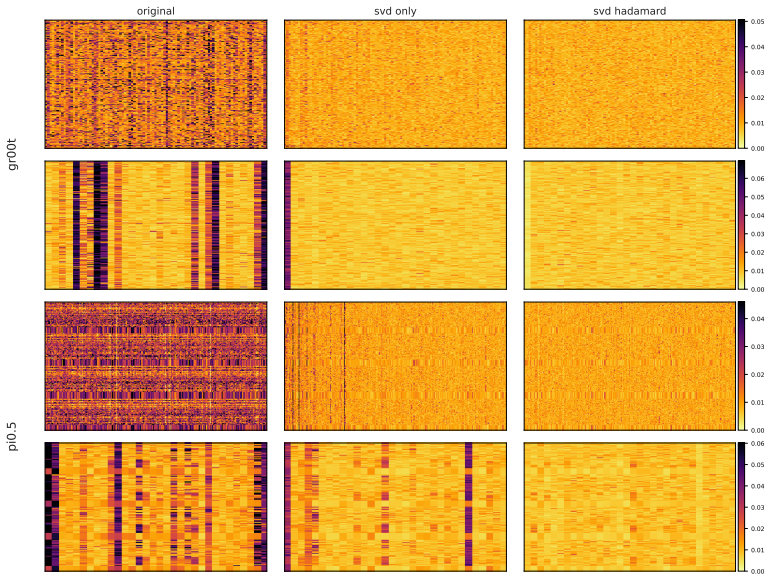
Omega-QVLA is the first training-free post-training quantization framework that compresses both the language backbone and the entire diffusion action head of a VLA model to a uniform W4A4 precision by combining a composite SVD-Hadamard rotation that equalizes per-channel weight energy while diffusing residual activation outliers with per-step DiT activation scaling quantization that absorbs dynamic-range drift across denoising steps, eliminating the need for mixed-precision allocation.
What carries the argument
Composite SVD-Hadamard rotation for weight equalization and outlier diffusion, together with per-step DiT activation scaling to handle denoising drift.
If this is right
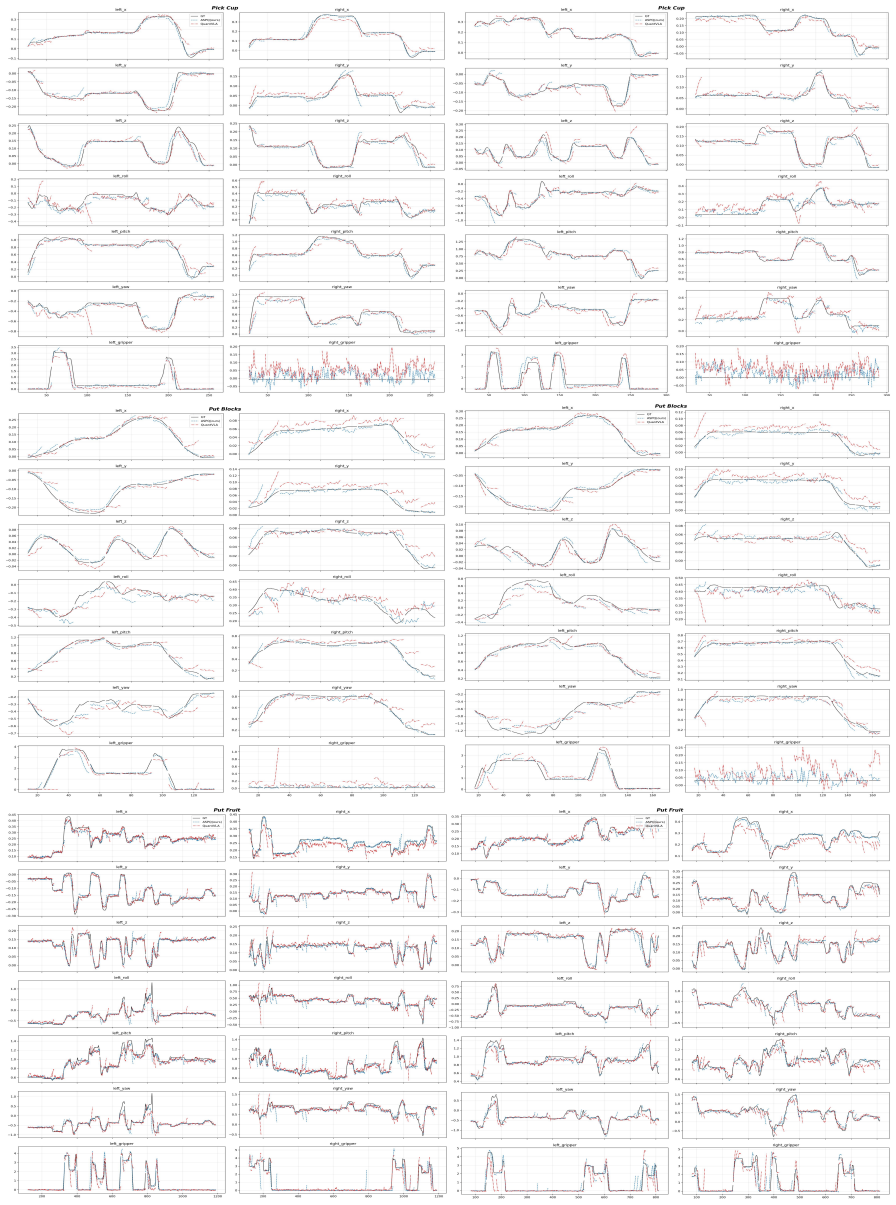
- Pi 0.5 and GR00T N1.5 reach 98.0% and 87.8% success on LIBERO at W4A4, matching or beating their FP16 references.
- Static memory footprint drops 71.3% while preserving policy behavior.
- Real-world manipulation remains smooth and accurate where earlier quantization approaches break down.
- No mixed-precision allocation is required for the action head.
Where Pith is reading between the lines
- The method could extend to other diffusion-based policies by applying similar per-step scaling.
- Reduced memory may support deployment on resource-limited hardware without accuracy loss.
Load-bearing premise
The composite rotation and per-step scaling will equalize energies, diffuse outliers, and absorb range drift enough to keep uniform 4-bit quantization stable in the action head without training.
What would settle it
Task success rates on LIBERO or real-world manipulation falling measurably below the FP16 baselines when the W4A4 model is evaluated.
Figures
read the original abstract
Vision-Language-Action (VLA) models unify perception, reasoning, and control within a single policy, yet their multi-billion-parameter backbones and diffusion-based action heads make on-device deployment prohibitively expensive. Prior quantization efforts offer only partial solutions, compressing the LLM backbone while leaving the DiT action head at full precision, or resorting to mixed-precision schemes, driven by the belief that uniformly quantizing the action head is inherently unstable. We challenge this assumption with Omega-QVLA, the first training-free post-training quantization framework that compresses both the language backbone and the entire diffusion action head of a VLA model to a uniform W4A4 precision, eliminating the need for mixed-precision allocation. Omega-QVLA combines a composite SVD-Hadamard rotation that equalizes per-channel weight energy while diffusing residual activation outliers with per-step DiT activation scaling quantization that absorbs dynamic-range drift across denoising steps. On LIBERO, Omega-QVLA compresses Pi 0.5 and GR00T N1.5 to W4A4 with 98.0% and 87.8% task success rates, matching or exceeding their FP16 references of 97.1% and 87.0%, while reducing the static memory footprint by 71.3%. Real-world manipulation experiments further confirm smooth, accurate manipulation where prior methods fail. Code is available at https://github.com/UCMP13753/Omega-QVLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Ω-QVLA, the first claimed training-free post-training quantization framework for Vision-Language-Action models that achieves uniform W4A4 precision across both the language backbone and the entire diffusion-based action head. It combines a composite SVD-Hadamard rotation to equalize per-channel weight energy and diffuse activation outliers with per-step DiT activation scaling to absorb dynamic-range drift across denoising timesteps. On the LIBERO benchmark, it reports 98.0% success for Pi 0.5 and 87.8% for GR00T N1.5 (vs. FP16 baselines of 97.1% and 87.0%), with 71.3% memory reduction, plus real-world manipulation results.
Significance. If the central technical claims are verified, the result would be significant for on-device deployment of large VLA models, as it removes the need for mixed-precision allocation or retraining of the diffusion head while preserving task performance. The reported parity with FP16 on standard benchmarks and the memory savings would constitute a practical advance in quantizing complex robotics policies.
major comments (2)
- [Abstract] Abstract: the central claim that the composite SVD-Hadamard rotation plus per-step DiT scaling enables stable uniform W4A4 quantization of the full action head (eliminating mixed precision) rests on unshown evidence; no equations, activation-distribution statistics, or quantitative verification of channel-energy equalization and drift absorption are supplied, making it impossible to assess whether residual step-dependent outliers remain.
- [Abstract] Abstract: the reported LIBERO success rates (98.0% / 87.8%) are presented without ablation studies, error analysis, or controls isolating the contribution of each proposed component, so it cannot be determined whether the performance parity is attributable to the claimed transforms or to other unstated factors.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the clarity of evidence presentation in the abstract. We address each point below and propose targeted revisions to the abstract for improved accessibility while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the composite SVD-Hadamard rotation plus per-step DiT scaling enables stable uniform W4A4 quantization of the full action head (eliminating mixed precision) rests on unshown evidence; no equations, activation-distribution statistics, or quantitative verification of channel-energy equalization and drift absorption are supplied, making it impossible to assess whether residual step-dependent outliers remain.
Authors: The abstract summarizes the approach at a high level. Full technical details, including the equations defining the composite SVD-Hadamard rotation (Equations 3–5) and per-step DiT activation scaling (Equation 7), activation-distribution statistics, and quantitative verification of channel-energy equalization plus drift absorption (Figures 4–5 and Table 3), appear in Sections 3.2–3.3. These sections explicitly demonstrate the reduction of step-dependent outliers. We will revise the abstract to add a concise reference to these supporting analyses in the main text. revision: yes
-
Referee: [Abstract] Abstract: the reported LIBERO success rates (98.0% / 87.8%) are presented without ablation studies, error analysis, or controls isolating the contribution of each proposed component, so it cannot be determined whether the performance parity is attributable to the claimed transforms or to other unstated factors.
Authors: The reported rates are the outcome of the full evaluation pipeline. Ablation studies that isolate the SVD-Hadamard rotation and per-step scaling contributions, together with error analysis and controls, are presented in Section 4.3 and Appendix B. These results attribute the observed parity directly to the proposed components. We will revise the abstract to include an explicit reference to these ablations and controls. revision: yes
Circularity Check
No circularity; method is an independent technical proposal evaluated on external benchmarks.
full rationale
The paper introduces a composite SVD-Hadamard rotation plus per-step DiT scaling for uniform W4A4 quantization of VLA models. The abstract and description present this as a novel post-training technique whose effectiveness is demonstrated via empirical success rates on LIBERO (98.0%/87.8% vs. FP16 baselines) and real-world experiments. No equations, self-citations, or steps are shown that reduce the claimed performance to fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations. The derivation chain is self-contained against standard benchmarks with no reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quarot: Outlier-free 4-bit inference in rotated llms.arXiv preprint arXiv:2404.00456. Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Di- eter Fox, Fengyuan Hu, Spencer Huang, and 1 oth- ers
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734. Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323. Xing Hu, Yuan Cheng, Dawei Yang, Zukang Xu, Zhi- hang Yuan, Jiangyong Yu, Chen Xu, Zhe Jiang, and Sifan Zhou
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2501.13987
Ostquant: Refining large language model quantization with orthogonal and scaling transformations for better distribution fitting. arXiv preprint arXiv:2501.13987. Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fu- sai, and 1 others
-
[5]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
π0.5: a vision–language– action model with open-world generalization.arXiv preprint arXiv:2504.16054. Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag San- keti, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
OpenVLA: An Open-Source Vision-Language-Action Model
Openvla: An open- source vision-language-action model.arXiv preprint arXiv:2406.09246. Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Svdquant: Absorbing outliers by low-rank components for 4-bit diffusion models, 2025
Svdquant: Absorbing outliers by low-rank components for 4-bit diffusion models.arXiv preprint arXiv:2411.05007. Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Ying- tao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Ying Wei. 2024a. Duquant: Distributing outliers via dual transformation makes stronger quantized llms.Advances in Neural Information Processi...
-
[8]
Flatquant: Flat- ness matters for llm quantization.arXiv preprint arXiv:2410.09426. Hugo Touvron, Louis Martin, Kevin Stone, Peter Al- bert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and 1 others
-
[9]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foun- dation and fine-tuned chat models.arXiv preprint arXiv:2307.09288. Junyi Wu, Haoxuan Wang, Yuzhang Shang, Mubarak Shah, and Yan Yan
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
QuantVLA: Scale-Calibrated Post-Training Quantization for Vision-Language-Action Models
Quantvla: Scale-calibrated post- training quantization for vision-language-action mod- els.CoRR, abs/2602.20309. Tianchen Zhao, Tongcheng Fang, Haofeng Huang, En- shu Liu, Rui Wan, Widyadewi Soedarmadji, Shiyao Li, Zinan Lin, Guohao Dai, Shengen Yan, and 1 oth- ers
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Vidit-q: Efficient and accurate quantiza- tion of diffusion transformers for image and video generation.arXiv preprint arXiv:2406.02540. A Appendix A.1 Description of Baselines and Benchmarks Benchmark.We evaluate all methods on LIBERO (Liu et al., 2023), a standard benchmark for VLA policy evaluation in robotic manipulation. LIBERO consists of four task ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.