Emergent Semantic Representations in World Models through Physical Interaction without Linguistic Supervision
Pith reviewed 2026-06-30 15:39 UTC · model grok-4.3
The pith
Physical exploration induces world model latents organized by real geometry without any language input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
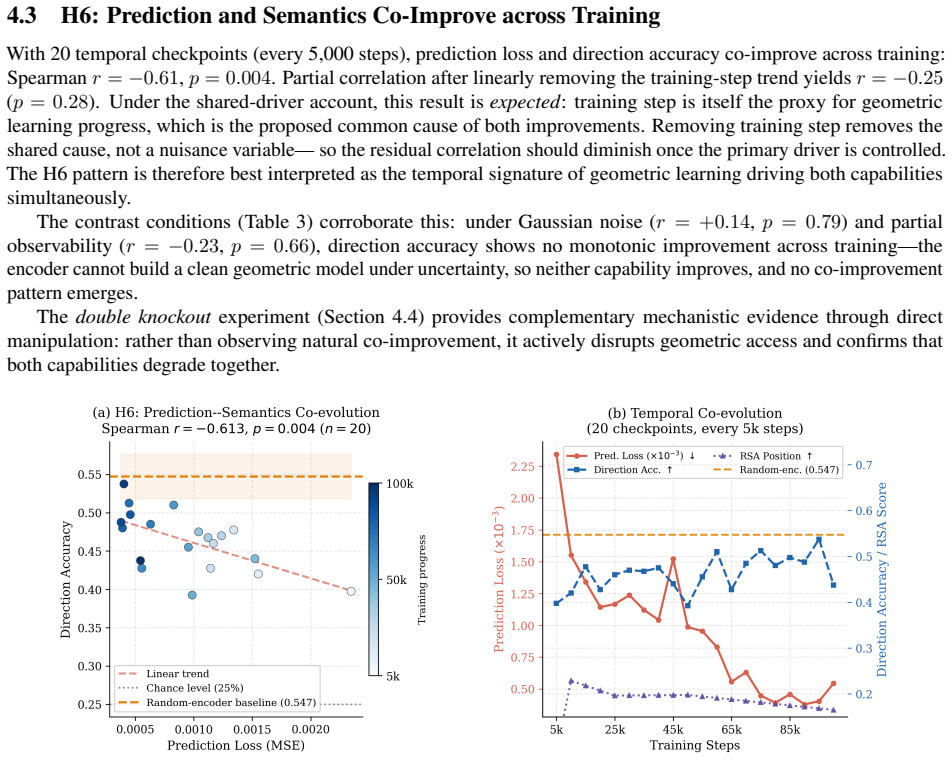
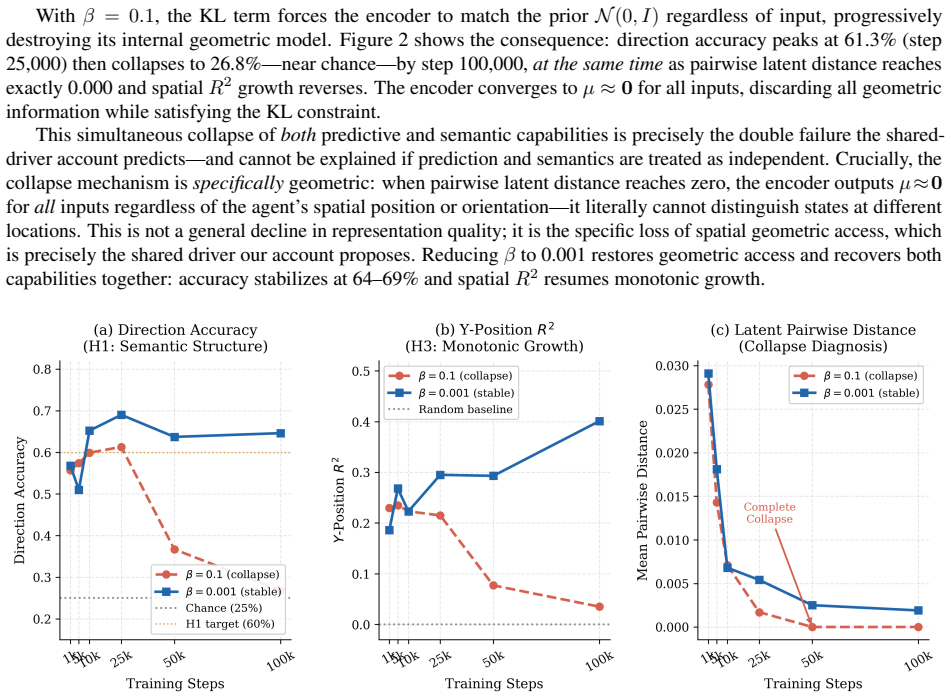
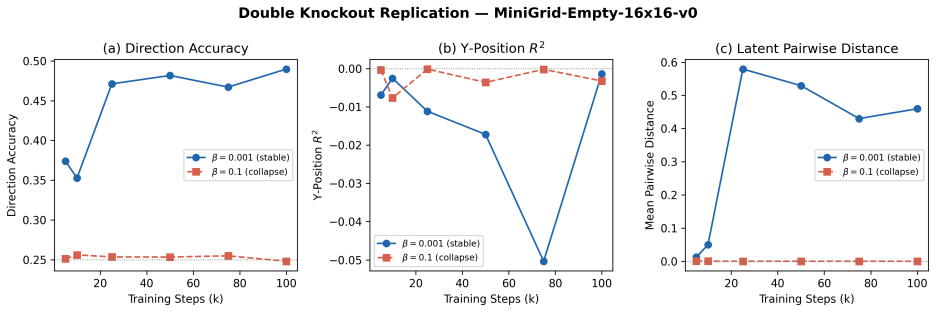
Training a VAE-based world model on random embodied exploration leads to a latent space with spatial semantic structure that mirrors physical geometry. This is shown by direction accuracy of 0.677 versus 0.547 for random encoders and position RSA of 0.192 versus 0.029, a 6.6-fold gain. Prediction performance and semantic alignment improve together (Spearman r = -0.61). Standard beta regularization pushes the encoder away from geometric structure and drives both prediction and alignment to near chance; lowering beta restores geometric access and recovers both capabilities at once.
What carries the argument
The beta-regularized VAE encoder whose latent space is shaped by physical interaction trajectories, with lower beta values permitting the emergence of direction and position encodings that align with actual geometry.
If this is right
- Prediction performance and semantic alignment with physical geometry improve together over the course of training.
- Raising the KL regularization coefficient forces the latent space away from geometric structure and simultaneously destroys both prediction accuracy and semantic alignment.
- Lowering the regularization coefficient restores access to geometric structure and recovers both prediction and alignment.
- The same physical-interaction data that drives prediction also drives the formation of spatially meaningful representations.
Where Pith is reading between the lines
- Design choices for embodied agents could prioritize interaction data volume and low regularization over explicit semantic supervision.
- The same geometric-organization effect may appear in other world-model architectures trained on interaction trajectories in different environments.
- Measuring latent alignment with physical geometry could serve as an early diagnostic for whether a world model will later support spatial reasoning tasks.
Load-bearing premise
The measured gains in direction accuracy and position RSA arise specifically from the geometric structure present in the physical interaction data rather than from the CNN architecture or other fixed training choices.
What would settle it
A trained model that shows no gain in direction accuracy or position RSA over its random-encoder baseline even after beta is lowered to 0.001 would falsify the claim that physical geometry organizes the representations.
Figures
read the original abstract
What does a world model learn from physical exploration, without any linguistic supervision? We argue the answer is organized by a single principle: the geometric structure of the physical world. Training a VAE-based world model on random embodied exploration, we find that its latent space develops spatial semantic structure that mirrors physical geometry -- direction accuracy 0.677+-0.029 versus 0.547 for a randomly initialized encoder, and position RSA 0.192+-0.047 versus 0.029 for random encoders (6.6x improvement), showing that training induces genuine structural organization beyond CNN inductive bias. Across 20 temporal checkpoints, prediction performance and semantic alignment co-improve (Spearman r=-0.61, p=0.004), consistent with the shared-driver account. We confirm this through a double knockout: standard KL regularization (beta=0.1) forces the encoder away from geometric structure, and both prediction performance and semantic alignment collapse simultaneously to near-chance by step 50,000 -- exactly as the shared-driver account predicts. Reducing beta to 0.001 restores geometric access and recovers both capabilities together. These findings establish physical world geometry as the organizing principle of world model representations, with direct implications for the design of semantically grounded embodied agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a VAE-based world model trained on random embodied exploration trajectories develops latent representations organized by physical geometry without linguistic supervision. Evidence includes direction accuracy of 0.677±0.029 (vs. 0.547 for random encoder), position RSA of 0.192±0.047 (vs. 0.029, 6.6x improvement), co-improvement of prediction performance and semantic alignment across 20 checkpoints (Spearman r=-0.61, p=0.004), and a beta ablation where KL regularization at 0.1 collapses both metrics while reducing beta to 0.001 restores them.
Significance. If the attribution to physical geometry holds, the results would indicate that embodied interaction can induce semantically grounded structure in world models, informing design of embodied agents. The temporal correlation analysis and double-knockout beta experiment are positive elements that tie performance and alignment together.
major comments (2)
- [Abstract (beta ablation and controls)] Abstract (controls paragraph): The random-initialized encoder baseline and beta=0.1 ablation do not isolate physical geometry from the CNN's translation-equivariant filters or the structured sampling produced by the embodied policy. A control training the same architecture on non-embodied data (static views or shuffled frames) is required to support the claim that the measured gains in direction accuracy and position RSA arise specifically from physical interaction rather than architecture or data-collection confounds. This directly affects the central assertion that physical world geometry is the organizing principle.
- [Abstract (correlation analysis)] Abstract (correlation paragraph): The reported Spearman correlation is consistent with a shared driver but does not distinguish geometry induction from other co-varying factors during training; an additional non-embodied training condition would be needed to strengthen the interpretation.
minor comments (2)
- Provide full details on the environment, dataset size, number of trajectories, and exact statistical procedures for computing direction accuracy and position RSA.
- Clarify whether the random-encoder baseline uses the same weight initialization distribution as the trained model or a different one.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our controls. We address each point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract (beta ablation and controls)] Abstract (controls paragraph): The random-initialized encoder baseline and beta=0.1 ablation do not isolate physical geometry from the CNN's translation-equivariant filters or the structured sampling produced by the embodied policy. A control training the same architecture on non-embodied data (static views or shuffled frames) is required to support the claim that the measured gains in direction accuracy and position RSA arise specifically from physical interaction rather than architecture or data-collection confounds. This directly affects the central assertion that physical world geometry is the organizing principle.
Authors: We agree that a non-embodied control (static views or shuffled frames) would more cleanly isolate the contribution of physical interaction from architecture and data-collection structure. The random encoder already shows that training is required beyond CNN biases, and the beta ablation demonstrates that high regularization collapses both prediction and alignment on the same embodied data. To strengthen the central claim, we will add the requested non-embodied training conditions and report direction accuracy and position RSA for them in the revised manuscript. revision: yes
-
Referee: [Abstract (correlation analysis)] Abstract (correlation paragraph): The reported Spearman correlation is consistent with a shared driver but does not distinguish geometry induction from other co-varying factors during training; an additional non-embodied training condition would be needed to strengthen the interpretation.
Authors: We acknowledge that the Spearman correlation by itself leaves room for alternative co-varying factors. The beta ablation already functions as an internal control by removing geometric structure while preserving the training data and objective. We will extend the correlation analysis to include the non-embodied training runs, allowing direct comparison of the co-improvement trajectory under conditions that lack physical interaction. revision: yes
Circularity Check
No circularity; empirical measurements and ablations are independent of definitional reduction
full rationale
The paper reports results from training a VAE-based world model on embodied trajectories, then measuring emergent properties (direction accuracy, position RSA) against random-encoder baselines and performing beta-regularization ablations. These steps rely on experimental outcomes and statistical correlations rather than any equation or definition that reduces the claimed geometric organization to a fitted input or self-citation by construction. No load-bearing premise is justified solely by prior author work, and the derivation chain consists of observable training dynamics and controls that remain falsifiable outside the reported numbers.
Axiom & Free-Parameter Ledger
free parameters (1)
- beta =
0.1 / 0.001
axioms (1)
- domain assumption VAE encoder can capture geometric structure from embodied trajectories when KL weight is low.
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 8
2023
-
[2]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
Randall Balestriero and Yann LeCun. LeJEPA: Provable and scalable self-supervised learning without the heuristics. arXiv preprint arXiv:2511.08544, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
VICReg: Variance-invariance-covariance regularization for self-supervised learning
Adrien Bardes, Jean Ponce, and Yann LeCun. VICReg: Variance-invariance-covariance regularization for self-supervised learning. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[4]
Barsalou
Lawrence W. Barsalou. Perceptual symbol systems.Behavioral and Brain Sciences, 22(4):577–660, 1999
1999
-
[5]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Anthony Brohan et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning (CoRL), 2023
2023
-
[6]
MiniGrid: A minimalist gridworld environment for openai gym, 2018
Maxime Chevalier-Boisvert, Lucas Willems, and Suman Pal. MiniGrid: A minimalist gridworld environment for openai gym, 2018
2018
-
[7]
Oxford University Press, 2016
Andy Clark.Surfing Uncertainty: Prediction, Action, and the Embodied Mind. Oxford University Press, 2016
2016
-
[8]
The free-energy principle: A unified brain theory?Nature Reviews Neuroscience, 11:127–138, 2010
Karl Friston. The free-energy principle: A unified brain theory?Nature Reviews Neuroscience, 11:127–138, 2010
2010
-
[9]
Learning latent action world models in the wild
Quentin Garrido, Tushar Nagarajan, Basile Terver, Nicolas Ballas, Yann LeCun, and Michael Rabbat. Learning latent action world models in the wild. arXiv preprint arXiv:2601.05230, 2026
-
[10]
Bootstrap your own latent: A new approach to self- supervised learning
Jean-Bastien Grill, Florian Strub, Florent Altché, et al. Bootstrap your own latent: A new approach to self- supervised learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[11]
Mastering Diverse Domains through World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering diverse domains through world models. arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
The symbol grounding problem.Physica D: Nonlinear Phenomena, 42(1–3):335–346, 1990
Stevan Harnad. The symbol grounding problem.Physica D: Nonlinear Phenomena, 42(1–3):335–346, 1990
1990
-
[13]
Emergent multi-agent communication in the deep learning era
Angeliki Lazaridou and Marco Baroni. Emergent multi-agent communication in the deep learning era. arXiv preprint arXiv:2006.02419, 2020
-
[14]
Don’t blame the ELBO! a linear V AE perspective on posterior collapse
James Lucas, George Tucker, Roger Grosse, and Mohammad Norouzi. Don’t blame the ELBO! a linear V AE perspective on posterior collapse. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[15]
Efros, and Trevor Darrell
Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. Curiosity-driven exploration by self- supervised prediction. InInternational Conference on Machine Learning (ICML), 2017
2017
-
[16]
International Universities Press, 1952
Jean Piaget.The Origins of Intelligence in Children. International Universities Press, 1952
1952
-
[17]
Harvard University Press, 1999
Michael Tomasello.The Cultural Origins of Human Cognition. Harvard University Press, 1999
1999
-
[18]
World Action Models: The Next Frontier in Embodied AI
Siyin Wang, Junhao Shi, Zhaoyang Fu, et al. World action models: The next frontier in embodied AI. arXiv preprint arXiv:2605.12090, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Barlow twins: Self-supervised learning via redundancy reduction
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. Barlow twins: Self-supervised learning via redundancy reduction. InInternational Conference on Machine Learning (ICML), 2021. 9
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.