PrismFlow: Residual Dynamics for Flow Matching in Time-Series Generation
Pith reviewed 2026-06-30 16:25 UTC · model grok-4.3
The pith
PrismFlow adds residual dynamical corrections from specialized experts to standard flow matching, recovering high-frequency structures lost to spectral contraction in time-series generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
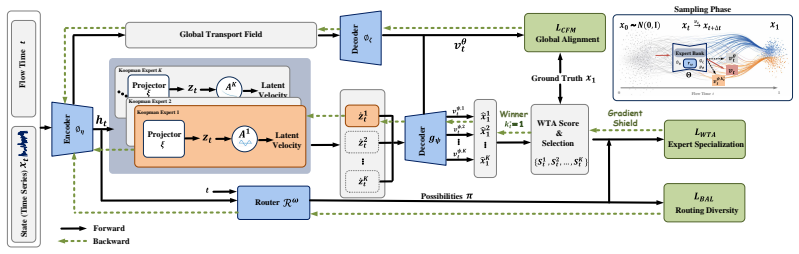
PrismFlow is a flow matching method that deploys a collection of dynamical experts, each learning residual corrections in a latent space where local nonlinear temporal evolution can be approximated by linear transitions; a confidence-aware winner-take-all objective updates only the best-aligned expert for each sample, so that at inference the chosen expert adds a mode-specific residual to the global transport field and thereby restores fine-grained and high-frequency temporal structures.
What carries the argument
Koopman-inspired dynamical experts that learn residual corrections in latent space, activated by a confidence-aware winner-take-all objective during training.
If this is right
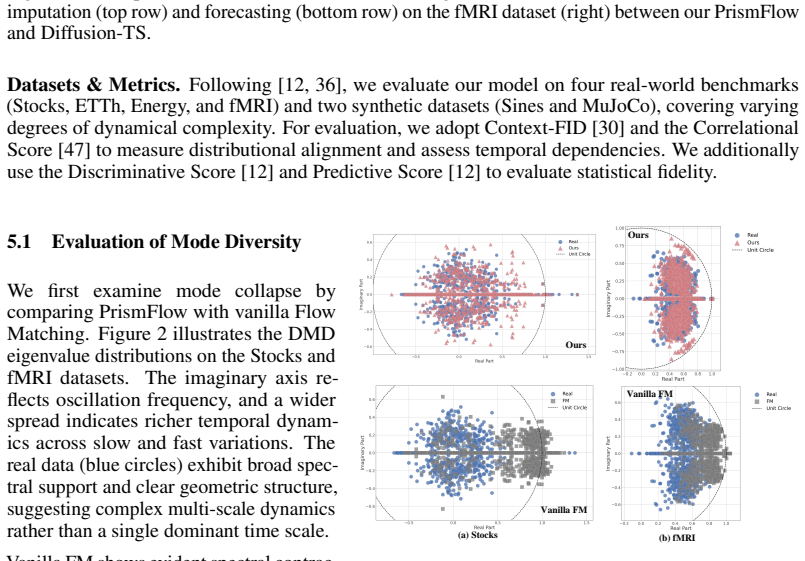
- The method reduces spectral contraction that appears in monolithic flow-matching estimators on heterogeneous time series.
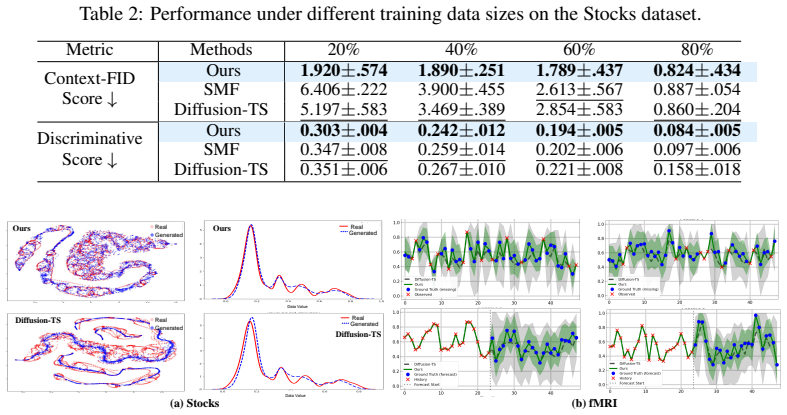
- It yields a 15.6 percent gain in Context-FID and 38.6 percent improvement in Discriminative Score on reported benchmarks.
- Performance remains strong when training data are limited.
- The same architecture supports both unconditional generation and conditional tasks such as forecasting and imputation.
Where Pith is reading between the lines
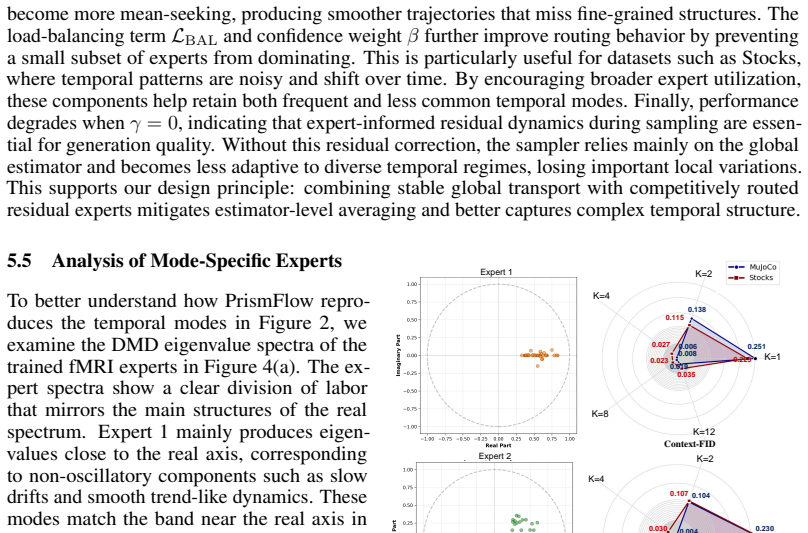
- The latent-space linearization may allow post-hoc inspection of which expert activates on which regime, offering a route to interpretability not present in the base model.
- Because the experts operate as additive residuals, the framework could be grafted onto other flow-matching or diffusion pipelines that already use a global field.
- If the winner-take-all selection proves stable, the same pattern might address mode collapse in other multimodal generation settings outside time series.
Load-bearing premise
Distinct temporal regimes pass through nearby flow states yet require incompatible conditional velocities that cannot be captured by any single finite-capacity estimator.
What would settle it
Generate samples from both PrismFlow and standard flow matching on a benchmark with known multimodal high-frequency content and measure whether the spectral power spectrum or Context-FID of PrismFlow outputs is measurably closer to the real data.
Figures
read the original abstract
Generating high-quality time-series data is challenging because real-world signals often exhibit multimodal patterns and multiscale dynamics, including oscillations and high-frequency variations. Flow Matching (FM) offers an efficient alternative to diffusion models, but practical implementations typically rely on a single finite-capacity global vector-field estimator. In such heterogeneous temporal distributions, distinct regimes may pass through nearby flow states while requiring incompatible conditional velocities. A monolithic estimator trained with the standard $\ell_2$ velocity-matching objective may therefore learn an overly smoothed approximation of the local transport field. This estimator-level smoothing can attenuate branch-specific dynamics, leading to spectral distortion and poor mode coverage. To address this, we propose PrismFlow, a new FM method with Koopman-inspired dynamical experts. Each expert learns residual corrections in a latent space where local nonlinear temporal evolution can be approximated by linear transitions. We further propose a confidence-aware Winner-Take-All (WTA) objective that updates only the expert best aligned with each sample while masking gradients to the others, encouraging mode-specific specialization. During sampling, the selected expert adds a residual dynamical correction to the global transport field, preserving FM stability while recovering fine-grained and high-frequency temporal structures. Across various benchmarks, PrismFlow effectively mitigates the spectral contraction in standard FM and achieves state-of-the-art performance, with a 15.6% gain in Context-FID and a 38.6% improvement in Discriminative Score, while remaining robust in low-data settings and effective for forecasting and imputation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PrismFlow, an extension of flow matching (FM) for time-series generation. It argues that a single finite-capacity velocity estimator under the standard ℓ₂ objective produces spectral contraction when distinct temporal regimes share nearby flow states but require incompatible conditional velocities. To remedy this, PrismFlow introduces Koopman-inspired dynamical experts that learn residual corrections in a latent space (where local nonlinear evolution is approximated linearly), a confidence-aware Winner-Take-All (WTA) objective that updates only the best-aligned expert while masking gradients to others, and additive residual corrections from the selected expert at sampling time. The paper reports state-of-the-art results across benchmarks, including a 15.6% improvement in Context-FID and 38.6% in Discriminative Score, plus robustness in low-data regimes and utility for forecasting and imputation.
Significance. If the central empirical claims hold after verification of the experimental protocol, the work provides a targeted, modular extension to FM that preserves its training stability while recovering branch-specific high-frequency dynamics. The residual-expert construction with WTA specialization is a concrete mechanism that could be adopted in other conditional generative settings for sequential data. The manuscript earns credit for supplying implementation details, loss derivations, and benchmark protocols that allow the argument to be checked on its own terms.
major comments (2)
- [Introduction / §3 (method motivation)] The central premise (distinct regimes share flow states yet demand incompatible velocities that a monolithic ℓ₂ estimator cannot capture) is stated in the abstract and motivates the entire construction, yet the manuscript provides no direct diagnostic—such as a spectral analysis of the learned velocity field or a controlled comparison of per-regime transport errors—showing that standard FM indeed exhibits the claimed contraction on the evaluated datasets. Without this, the performance gains cannot be unambiguously attributed to the proposed remedy rather than other factors.
- [Experiments (§5)] Table 2 (or equivalent results table) reports the 15.6% Context-FID and 38.6% Discriminative Score gains; the manuscript must include per-dataset standard deviations across at least three random seeds, the exact train/validation/test splits, and an ablation that isolates the contribution of the residual experts versus the WTA objective alone. These details are load-bearing for the SOTA claim.
minor comments (2)
- [Method (§4)] Notation for the latent Koopman operator and the residual correction term should be introduced with an explicit equation (e.g., Eq. (X) in §4) rather than only in prose, to make the additive sampling step reproducible.
- [§4.2] The description of the confidence-aware WTA objective would benefit from a short pseudocode block clarifying how the masking is implemented during the backward pass.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive evaluation of the work's potential impact. We address each major comment below.
read point-by-point responses
-
Referee: [Introduction / §3 (method motivation)] The central premise (distinct regimes share flow states yet demand incompatible velocities that a monolithic ℓ₂ estimator cannot capture) is stated in the abstract and motivates the entire construction, yet the manuscript provides no direct diagnostic—such as a spectral analysis of the learned velocity field or a controlled comparison of per-regime transport errors—showing that standard FM indeed exhibits the claimed contraction on the evaluated datasets. Without this, the performance gains cannot be unambiguously attributed to the proposed remedy rather than other factors.
Authors: We agree that a direct diagnostic would strengthen attribution of the gains. The motivation in §3 is grounded in the known limitations of finite-capacity models under ℓ₂ regression in multimodal settings, and the reported improvements are consistent with recovery of high-frequency dynamics. In revision we will add a spectral analysis of the learned velocity field (standard FM vs. PrismFlow) on the benchmark datasets together with per-regime transport error comparisons where regime labels can be obtained. revision: yes
-
Referee: [Experiments (§5)] Table 2 (or equivalent results table) reports the 15.6% Context-FID and 38.6% Discriminative Score gains; the manuscript must include per-dataset standard deviations across at least three random seeds, the exact train/validation/test splits, and an ablation that isolates the contribution of the residual experts versus the WTA objective alone. These details are load-bearing for the SOTA claim.
Authors: We will revise Table 2 to report per-dataset standard deviations over at least three random seeds. The exact train/validation/test splits will be documented in §5. We will also add an ablation study that isolates the residual-expert component from the WTA objective. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces PrismFlow as an architectural extension to flow matching, using residual dynamical experts inspired by Koopman operators and a confidence-aware WTA objective to mitigate smoothing in a single global velocity estimator. No equations, fitted parameters, or self-citations are shown that reduce the claimed performance gains or the core modeling premise to a redefinition of the inputs by construction. The derivation of the method, the description of spectral contraction, and the reported benchmark improvements remain independent of the target results; the argument is self-contained on its stated assumptions and empirical protocols.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Distinct regimes may pass through nearby flow states while requiring incompatible conditional velocities.
- domain assumption Local nonlinear temporal evolution can be approximated by linear transitions in a suitable latent space.
invented entities (1)
-
dynamical experts
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ai in healthcare: time-series forecasting using statistical, neural, and ensemble architectures.Frontiers in big data, 3:4, 2020
Shruti Kaushik, Abhinav Choudhury, Pankaj Kumar Sheron, Nataraj Dasgupta, Sayee Natarajan, Larry A Pickett, and Varun Dutt. Ai in healthcare: time-series forecasting using statistical, neural, and ensemble architectures.Frontiers in big data, 3:4, 2020
2020
-
[2]
Diffusion-guided diversity for single domain generalization in time series classification
Junru Zhang, Lang Feng, Xu Guo, Han Yu, Yabo Dong, and Duanqing Xu. Diffusion-guided diversity for single domain generalization in time series classification. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 3764–3773, 2025
2025
-
[3]
Generative learning for financial time series with irregular and scale-invariant patterns
Hongbin Huang, Minghua Chen, and Xiao Qiao. Generative learning for financial time series with irregular and scale-invariant patterns. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[4]
Dual adaptation of time-series foundation models for financial forecasting
Fatemeh Chitsaz and Saman Haratizadeh. Dual adaptation of time-series foundation models for financial forecasting. In1st ICML Workshop on Foundation Models for Structured Data
-
[5]
Diffusion language-shapelets for semi- supervised time-series classification
Zhen Liu, Wenbin Pei, Disen Lan, and Qianli Ma. Diffusion language-shapelets for semi- supervised time-series classification. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 14079–14087, 2024
2024
-
[6]
Ltcr: Long temporal characteristic reconstruction for segmentation in contrastive learning
Yang He, Yuhan Wu, Junru Zhang, and Yabo Dong. Ltcr: Long temporal characteristic reconstruction for segmentation in contrastive learning. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 355–371. Springer, 2024
2024
-
[7]
On the constrained time-series generation problem.Advances in Neural Information Processing Systems, 36:61048–61059, 2023
Andrea Coletta, Sriram Gopalakrishnan, Daniel Borrajo, and Svitlana Vyetrenko. On the constrained time-series generation problem.Advances in Neural Information Processing Systems, 36:61048–61059, 2023
2023
-
[8]
Yuhan Wu, Xiyu Meng, Junru Zhang, Yang He, Joseph A Romo, Yabo Dong, and Dongming Lu. Effective lstms with seasonal-trend decomposition and adaptive learning and niching-based backtracking search algorithm for time series forecasting.Expert Systems with Applications, 236:121202, 2024
2024
-
[9]
Data privacy and security in it: a review of techniques and challenges.Computer Science & IT Research Journal, 5(3):606–615, 2024
Oluwatoyin Ajoke Farayola, Oluwabukunmi Latifat Olorunfemi, and Philip Olaseni Shoetan. Data privacy and security in it: a review of techniques and challenges.Computer Science & IT Research Journal, 5(3):606–615, 2024
2024
-
[10]
Tal Gonen, Itai Pemper, Ilan Naiman, Nimrod Berman, and Omri Azencot. Time series generation under data scarcity: A unified generative modeling approach.arXiv preprint arXiv:2505.20446, 2025
-
[11]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[12]
Time-series generative adversarial networks.Advances in neural information processing systems, 32, 2019
Jinsung Yoon, Daniel Jarrett, and Mihaela Van der Schaar. Time-series generative adversarial networks.Advances in neural information processing systems, 32, 2019
2019
-
[13]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Stochastic Interpolants: A Unifying Framework for Flows and Diffusions
Michael S Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions.arXiv preprint arXiv:2303.08797, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[16]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Diff2flow: Training flow matching models via diffusion model alignment
Johannes Schusterbauer, Ming Gui, Frank Fundel, and Björn Ommer. Diff2flow: Training flow matching models via diffusion model alignment. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28347–28357, 2025. 10
2025
-
[18]
Generalization and equilibrium in generative adversarial nets (gans)
Sanjeev Arora, Rong Ge, Yingyu Liang, Tengyu Ma, and Yi Zhang. Generalization and equilibrium in generative adversarial nets (gans). InInternational conference on machine learning, pages 224–232. PMLR, 2017
2017
-
[19]
Improved training of generative adversarial networks using representative features
Duhyeon Bang and Hyunjung Shim. Improved training of generative adversarial networks using representative features. InInternational conference on machine learning, pages 433–442. PMLR, 2018
2018
-
[20]
A geometry-aware metric for mode collapse in time series generative models
Yassine Abbahaddou and Amine M Aboussalah. A geometry-aware metric for mode collapse in time series generative models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=YAc0O13qMc
2025
-
[21]
Aksel Wilhelm Wold Eide, Eilif Solberg, and Ingebjørg Kåsen. Sample weighting as an expla- nation for mode collapse in generative adversarial networks.arXiv preprint arXiv:2010.02035, 2020
-
[22]
Unigan: Reducing mode collapse in gans using a uniform generator.Advances in neural information processing systems, 35:37690–37703, 2022
Ziqi Pan, Li Niu, and Liqing Zhang. Unigan: Reducing mode collapse in gans using a uniform generator.Advances in neural information processing systems, 35:37690–37703, 2022
2022
-
[23]
Hamiltonian systems and transformation in hilbert space.Proceedings of the National Academy of Sciences, 17(5):315–318, 1931
Bernard O Koopman. Hamiltonian systems and transformation in hilbert space.Proceedings of the National Academy of Sciences, 17(5):315–318, 1931
1931
-
[24]
Linearization in the large of nonlinear systems and koopman operator spectrum.Physica D: Nonlinear Phenomena, 242(1):42–53, 2013
Yueheng Lan and Igor Mezi´c. Linearization in the large of nonlinear systems and koopman operator spectrum.Physica D: Nonlinear Phenomena, 242(1):42–53, 2013
2013
-
[25]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Adaptive mixtures of local experts.Neural computation, 3(1):79–87, 1991
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts.Neural computation, 3(1):79–87, 1991
1991
-
[27]
C-RNN-GAN: Continuous recurrent neural networks with adversarial training
Olof Mogren. C-rnn-gan: Continuous recurrent neural networks with adversarial training.arXiv preprint arXiv:1611.09904, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[28]
Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs
Cristóbal Esteban, Stephanie L Hyland, and Gunnar Rätsch. Real-valued (medical) time series generation with recurrent conditional gans.arXiv preprint arXiv:1706.02633, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Cot-gan: Generating sequential data via causal optimal transport.Advances in neural information processing systems, 33:8798–8809, 2020
Tianlin Xu, Li Kevin Wenliang, Michael Munn, and Beatrice Acciaio. Cot-gan: Generating sequential data via causal optimal transport.Advances in neural information processing systems, 33:8798–8809, 2020
2020
-
[30]
Psa-gan: Progressive self attention gans for synthetic time series
Paul Jeha, Michael Bohlke-Schneider, Pedro Mercado, Shubham Kapoor, Rajbir Singh Nirwan, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. Psa-gan: Progressive self attention gans for synthetic time series. InThe tenth international conference on learning representations, 2022
2022
-
[31]
Abhyuday Desai, Cynthia Freeman, Zuhui Wang, and Ian Beaver. Timevae: A variational auto-encoder for multivariate time series generation.arXiv preprint arXiv:2111.08095, 2021
-
[32]
Latent independent excitation for general- izable sensor-based cross-person activity recognition
Hangwei Qian, Sinno Jialin Pan, and Chunyan Miao. Latent independent excitation for general- izable sensor-based cross-person activity recognition. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 11921–11929, 2021
2021
-
[33]
Diverse intra-and inter-domain activity style fusion for cross-person generalization in activity recognition
Junru Zhang, Lang Feng, Zhidan Liu, Yuhan Wu, Yang He, Yabo Dong, and Duanqing Xu. Diverse intra-and inter-domain activity style fusion for cross-person generalization in activity recognition. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4213–4222, 2024
2024
-
[34]
A survey on diffusion models for time series and spatio-temporal data.ACM Computing Surveys, 2024
Yiyuan Yang, Ming Jin, Haomin Wen, Chaoli Zhang, Yuxuan Liang, Lintao Ma, Yi Wang, Chenghao Liu, Bin Yang, Zenglin Xu, et al. A survey on diffusion models for time series and spatio-temporal data.ACM Computing Surveys, 2024
2024
-
[35]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761, 2020. 11
work page internal anchor Pith review Pith/arXiv arXiv 2009
- [36]
-
[37]
Sd- former: Similarity-driven discrete transformer for time series generation.Advances in Neural Information Processing Systems, 37:132179–132207, 2024
Zhicheng Chen, FENG SHIBO, Zhong Zhang, Xi Xiao, Xingyu Gao, and Peilin Zhao. Sd- former: Similarity-driven discrete transformer for time series generation.Advances in Neural Information Processing Systems, 37:132179–132207, 2024
2024
-
[38]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[39]
Goku: Flow based video generative foundation models
Shoufa Chen, Chongjian Ge, Yuqi Zhang, Yida Zhang, Fengda Zhu, Hao Yang, Hongxiang Hao, Hui Wu, Zhichao Lai, Yifei Hu, et al. Goku: Flow based video generative foundation models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23516–23527, 2025
2025
-
[40]
Conditional flow matching for time series modelling
Ella Tamir, Najwa Laabid, Markus Heinonen, Vikas Garg, and Arno Solin. Conditional flow matching for time series modelling. InICML 2024 Workshop on Structured Probabilistic Inference{\&}Generative Modeling, 2024
2024
-
[41]
Yunfeng Ge, Jiawei Li, Yiji Zhao, Haomin Wen, Zhao Li, Meikang Qiu, Hongyan Li, Ming Jin, and Shirui Pan. T2s: High-resolution time series generation with text-to-series diffusion models.arXiv preprint arXiv:2505.02417, 2025
-
[42]
Sundial: A Family of Highly Capable Time Series Foundation Models
Yong Liu, Guo Qin, Zhiyuan Shi, Zhi Chen, Caiyin Yang, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Sundial: A family of highly capable time series foundation models. arXiv preprint arXiv:2502.00816, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Flow matching with Gaussian process priors for probabilistic time series forecasting
Marcel Kollovieh, Marten Lienen, David Lüdke, Leo Schwinn, and Stephan Günnemann. Flow matching with gaussian process priors for probabilistic time series forecasting.arXiv preprint arXiv:2410.03024, 2024
-
[44]
Sequence modeling with spectral mean flows.arXiv preprint arXiv:2510.15366, 2025
Jinwoo Kim, Max Beier, Petar Bevanda, Nayun Kim, and Seunghoon Hong. Sequence modeling with spectral mean flows.arXiv preprint arXiv:2510.15366, 2025
-
[45]
Adrien Cortés, Rémi Rehm, and Victor Letzelter. Winner-takes-all for multivariate probabilistic time series forecasting.arXiv preprint arXiv:2506.05515, 2025
-
[46]
Dynamic mode decomposition of numerical and experimental data.Journal of fluid mechanics, 656:5–28, 2010
Peter J Schmid. Dynamic mode decomposition of numerical and experimental data.Journal of fluid mechanics, 656:5–28, 2010
2010
-
[47]
Conditional sig-wasserstein gans for time series generation.arXiv preprint arXiv:2006.05421, 2020
Shujian Liao, Hao Ni, Lukasz Szpruch, Magnus Wiese, Marc Sabate-Vidales, and Baoren Xiao. Conditional sig-wasserstein gans for time series generation.arXiv preprint arXiv:2006.05421, 2020
-
[48]
On the guidance of flow matching.arXiv preprint arXiv:2502.02150, 2025
Ruiqi Feng, Chenglei Yu, Wenhao Deng, Peiyan Hu, and Tailin Wu. On the guidance of flow matching.arXiv preprint arXiv:2502.02150, 2025. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.