TaxDistill: Improving Metagenomic Taxonomic Annotation via Distilled Genomic Foundation Models
Pith reviewed 2026-06-30 16:21 UTC · model grok-4.3
The pith
Distilling soft labels from a large genomic foundation model into a small student network corrects noise from similarity searches and raises accuracy in identifying microbial sources of DNA fragments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
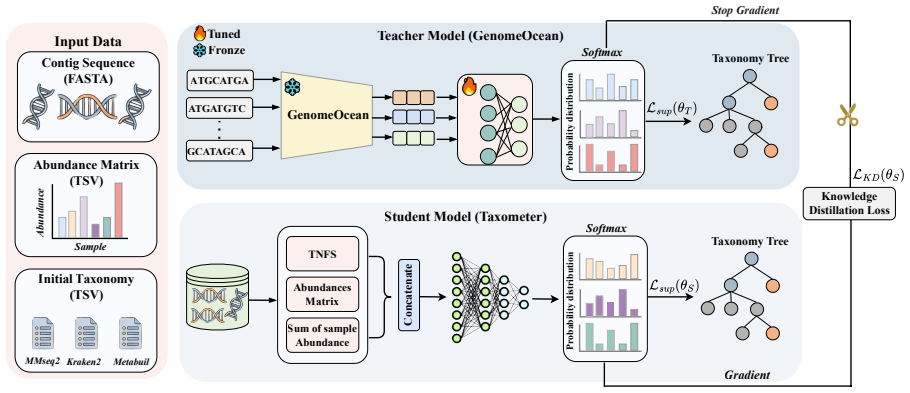
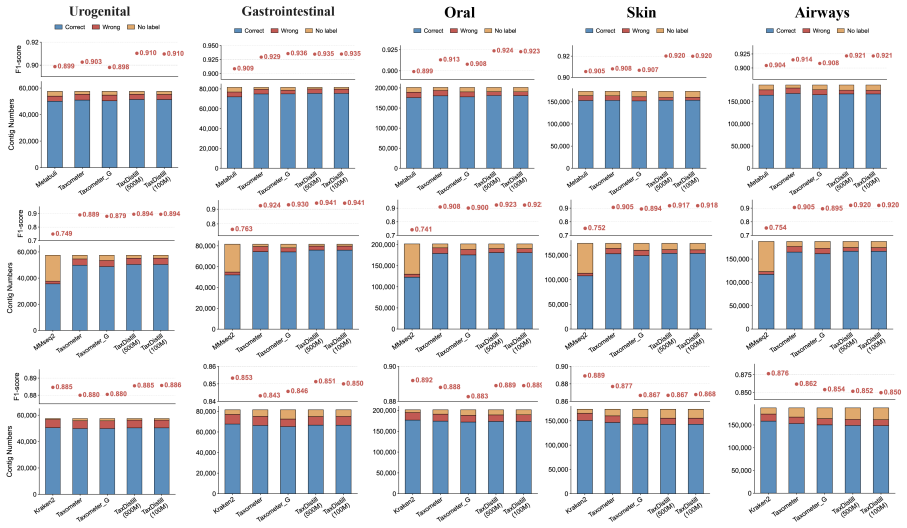
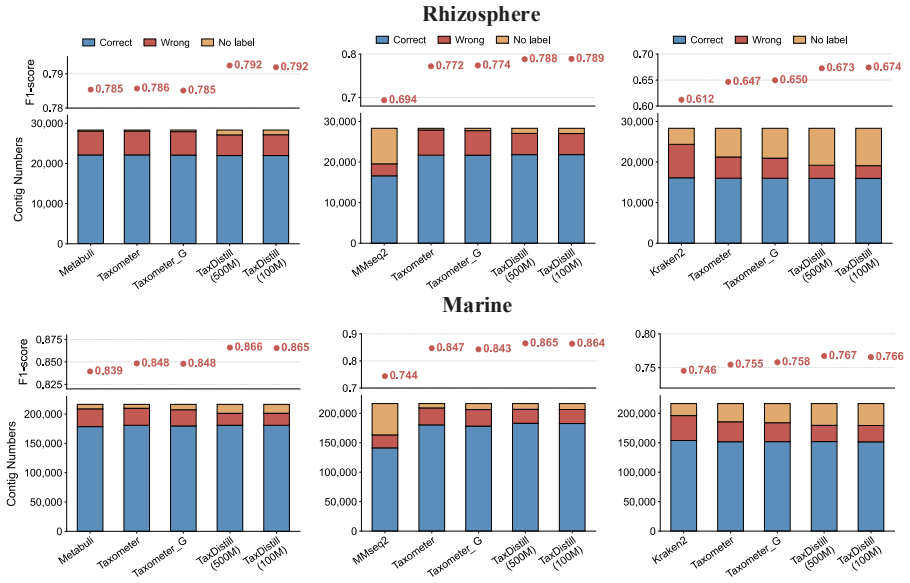
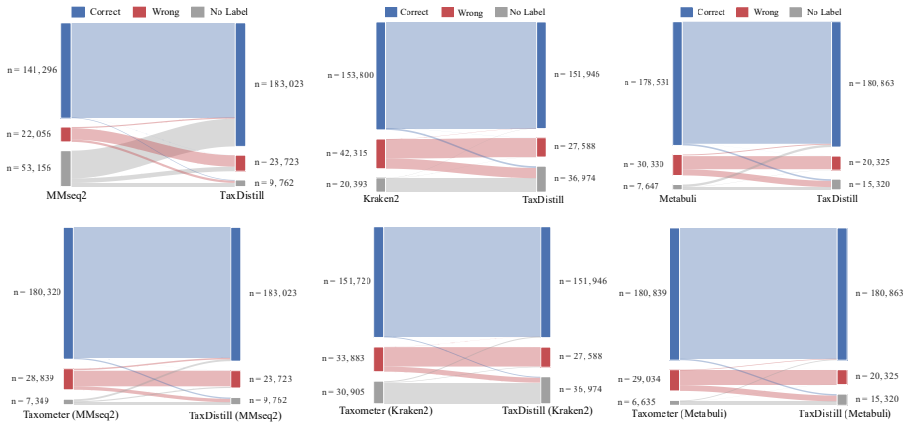
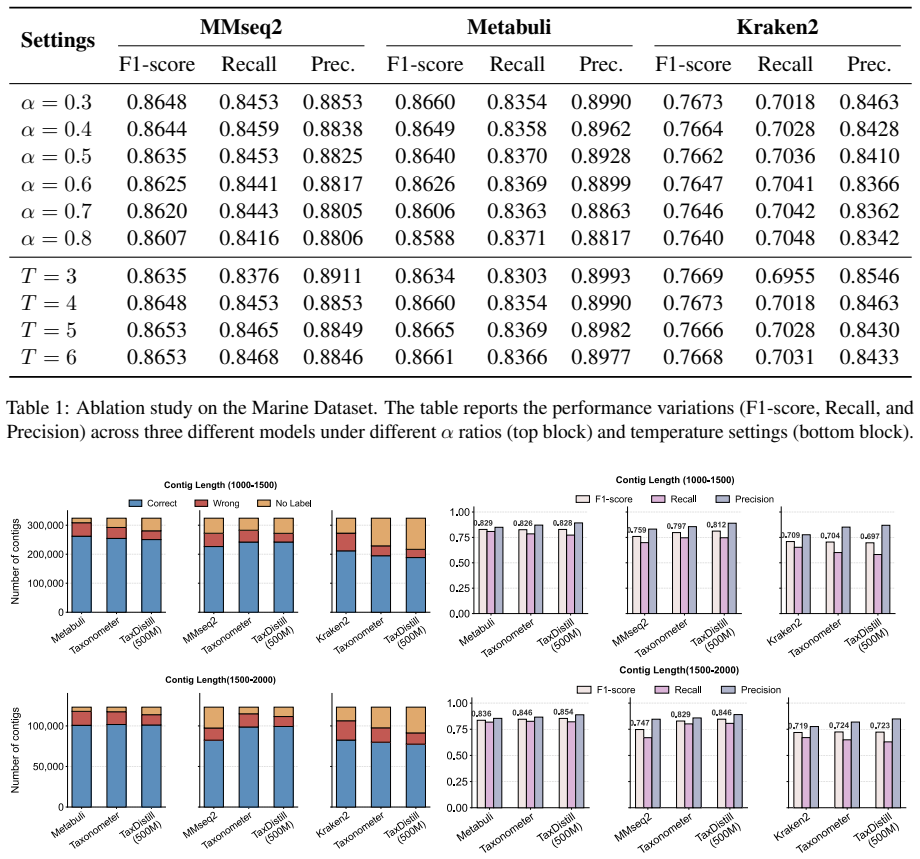
TaxDistill introduces a knowledge distillation framework in which a 500M-parameter genomic foundation model serves as teacher to extract semantic features and emit soft labels, which are then transferred to a lightweight student network; this process reduces label noise originating from initial retrieval tools and produces higher F1 scores than prior baselines on seven CAMI2 datasets, such as lifting MMseqs2 performance from 0.763 to 0.941 on the Gastrointestinal set while also surpassing the Taxometer baseline.
What carries the argument
Knowledge distillation of soft labels generated by a genomic foundation model teacher into a student classifier to reduce noise in taxonomic labels.
If this is right
- F1 score on the Gastrointestinal CAMI2 dataset rises from 0.763 with MMseqs2 alone to 0.941 after distillation.
- The method outperforms the Taxometer baseline on most of the seven tested CAMI2 datasets.
- Label noise from incomplete reference databases is mitigated through the use of confidence-weighted soft labels.
- Representation learning for metagenomic sequences becomes more reliable when training signals are cleaned by distillation.
Where Pith is reading between the lines
- The same distillation pattern could be applied to other sequence labeling tasks that currently rely on noisy similarity-derived labels.
- A lightweight student obtained this way might enable accurate annotation pipelines to run on portable sequencing hardware with limited compute.
- If the teacher's semantic features capture relationships beyond database matches, the approach may help annotate fragments from microbes absent from existing references.
Load-bearing premise
The soft labels produced by the large genomic foundation model are less noisy and more informative than the hard labels supplied by similarity search tools.
What would settle it
Training the student network on the distilled soft labels and observing no improvement in F1 score over a student trained directly on the hard labels from the retrieval tools across the CAMI2 evaluation sets would falsify the claim.
Figures

read the original abstract
Metagenomic taxonomic annotation aims to identify the microbial origins of DNA fragments in environmental samples. Traditional methods that rely on sequence similarity are often constrained by the high microbial diversity and the incompleteness of reference databases, which has motivated the development of learning approaches such as Taxometer that perform post hoc correction to learn more informative metagenomic sequence representations. However, these methods typically rely on labels derived from similarity search tools during training, which inevitably introduces noise that can impair representation learning and degrade classification performance. To address this issue, we propose TaxDistill, a knowledge distillation framework for metagenomic classification. We introduce GenomeOcean, a 500M parameter genomic foundation model, as the teacher network to extract deep semantic features and generate soft labels based on confidence. By distilling this soft label information into a lightweight student network, TaxDistill effectively reduces the label noise introduced by initial retrieval tools. Comprehensive experiments on seven diverse CAMI2 datasets demonstrate that TaxDistill outperforms existing baselines in most scenarios. For instance, on the Gastrointestinal dataset, it improves the F1 score of MMseqs2 from 0.763 to 0.941, outperforming the Taxometer baseline. Overall, TaxDistill provides a reliable method for label correction in complex metagenomic analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TaxDistill, a knowledge-distillation framework for metagenomic taxonomic annotation. A 500M-parameter genomic foundation model (GenomeOcean) serves as teacher to generate soft labels from deep semantic features; these are distilled into a lightweight student network to reduce label noise arising from initial similarity-search tools such as MMseqs2. Experiments on seven CAMI2 datasets report substantial F1 gains (e.g., MMseqs2 F1 rising from 0.763 to 0.941 on the Gastrointestinal dataset) and outperformance relative to Taxometer and other baselines.
Significance. If the reported gains are shown to arise specifically from the use of lower-noise soft labels rather than from architecture, training regime, or data handling differences, the work would demonstrate a practical route for leveraging large genomic foundation models to correct noisy labels in metagenomic classification. The concrete numerical improvements on standard CAMI2 benchmarks constitute a clear empirical contribution, though their attribution remains to be verified.
major comments (2)
- [§4] §4 (Experiments) and associated tables: the central performance claim (e.g., F1 0.763 → 0.941) is presented without an ablation that directly measures whether argmax(teacher soft labels) matches ground-truth CAMI2 labels more frequently than the hard labels from MMseqs2 or other retrieval tools. Without this comparison, it is impossible to confirm that the distillation step reduces label noise rather than that gains arise from the student architecture or training procedure alone.
- [§4, §3.2] §4 and §3.2 (Methods): no statistical significance tests, error bars, or cross-validation details are reported for the F1 improvements across the seven datasets, nor is there an oracle experiment isolating the contribution of soft-label distillation versus simply training the student on teacher hard labels. These omissions make the load-bearing claim that soft labels are “less noisy and more informative” unverifiable from the presented evidence.
minor comments (2)
- [Abstract, §1] The abstract and §1 refer to “seven diverse CAMI2 datasets” but do not list the exact dataset identifiers or accession numbers; this should be added for reproducibility.
- [§3] Notation for the distillation loss and the precise definition of “confidence” used to produce soft labels from GenomeOcean are not stated explicitly; a short equation or pseudocode block would clarify the procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that additional ablations and statistical analyses are needed to strengthen attribution of gains to soft-label noise reduction and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and associated tables: the central performance claim (e.g., F1 0.763 → 0.941) is presented without an ablation that directly measures whether argmax(teacher soft labels) matches ground-truth CAMI2 labels more frequently than the hard labels from MMseqs2 or other retrieval tools. Without this comparison, it is impossible to confirm that the distillation step reduces label noise rather than that gains arise from the student architecture or training procedure alone.
Authors: We agree that an explicit comparison of label accuracy (argmax of teacher soft labels versus MMseqs2 hard labels against CAMI2 ground truth) is required to isolate the contribution of the teacher. In the revised version we will add this ablation, reporting the percentage of correct labels for each source on all seven datasets. revision: yes
-
Referee: [§4, §3.2] §4 and §3.2 (Methods): no statistical significance tests, error bars, or cross-validation details are reported for the F1 improvements across the seven datasets, nor is there an oracle experiment isolating the contribution of soft-label distillation versus simply training the student on teacher hard labels. These omissions make the load-bearing claim that soft labels are “less noisy and more informative” unverifiable from the presented evidence.
Authors: We concur that statistical tests, error bars, and an oracle ablation are necessary. The revision will include: multiple training runs with standard deviations and paired significance tests; an oracle experiment training the student on teacher hard labels; and clarification of any cross-validation procedures used. revision: yes
Circularity Check
No circularity: empirical distillation evaluated on external benchmarks
full rationale
The paper describes TaxDistill as a standard knowledge-distillation pipeline: GenomeOcean (introduced as a 500M-parameter teacher) produces soft labels that are distilled into a student network, with performance measured by F1 on the independent CAMI2 benchmark suites. No equations, uniqueness theorems, or fitted parameters are presented whose outputs reduce by construction to the inputs; the reported gains (e.g., MMseqs2 F1 0.763 → 0.941) are obtained via ordinary supervised training and held-out evaluation. The derivation chain therefore consists of externally falsifiable experimental comparisons rather than self-definitional or self-citation loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Garyk Brixi, Matthew G Durrant, Jerome Ku, Mohsen Naghipourfar, Michael Poli, Gwanggyu Sun, Greg Brockman, Daniel Chang, Alison Fanton, Gabriel A Gonzalez, and 1 others. 2026. Genome modelling and design across all domains of life with evo 2. Nature, pages 1--13
2026
-
[3]
Xingyi Cheng, Bo Chen, Pan Li, Jing Gong, Jie Tang, and Le Song. 2024. Training compute-optimal protein language models. Advances in Neural Information Processing Systems, 37:69386--69418
2024
-
[4]
Charles Y Chiu and Steven A Miller. 2019. Clinical metagenomics. Nature Reviews Genetics, 20(6):341--355
2019
-
[5]
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. 2021. Knowledge distillation: A survey. International journal of computer vision, 129(6):1789--1819
2021
-
[6]
Jo Handelsman. 2004. Metagenomics: application of genomics to uncultured microorganisms. Microbiology and molecular biology reviews, 68(4):669--685
2004
-
[7]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Felix Kallenborn, Alejandro Chacon, Christian Hundt, Hassan Sirelkhatim, Kieran Didi, Sooyoung Cha, Christian Dallago, Milot Mirdita, Bertil Schmidt, and Martin Steinegger. 2025. Gpu-accelerated homology search with mmseqs2. Nature Methods, 22(10):2024--2027
2025
-
[9]
Daehwan Kim, Li Song, Florian P Breitwieser, and Steven L Salzberg. 2016. Centrifuge: rapid and sensitive classification of metagenomic sequences. Genome research, 26(12):1721--1729
2016
-
[10]
Jaebeom Kim and Martin Steinegger. 2024. Metabuli: sensitive and specific metagenomic classification via joint analysis of amino acid and dna. Nature methods, 21(6):971--973
2024
-
[11]
Svetlana Kutuzova, Mads Nielsen, Pau Piera, Jakob Nybo Nissen, and Simon Rasmussen. 2024. Taxometer: Improving taxonomic classification of metagenomics contigs. Nature Communications, 15(1):8357
2024
-
[12]
Eli Levy Karin and Martin Steinegger. 2025. Cutting-edge deep-learning based tools for metagenomic research. National Science Review, 12(6):nwaf056
2025
-
[13]
Yuncheng Li, Jianchao Yang, Yale Song, Liangliang Cao, Jiebo Luo, and Li-Jia Li. 2017. Learning from noisy labels with distillation. In Proceedings of the IEEE international conference on computer vision, pages 1910--1918
2017
-
[14]
Qiaoxing Liang, Paul W Bible, Yu Liu, Bin Zou, and Lai Wei. 2020. Deepmicrobes: taxonomic classification for metagenomics with deep learning. NAR Genomics and Bioinformatics, 2(1):lqaa009
2020
-
[15]
Zeming Lin, Halil Akin, Roshan Rao, Brian Hie, Zhongkai Zhu, Wenting Lu, Nikita Smetanin, Robert Verkuil, Ori Kabeli, Yaniv Shmueli, and 1 others. 2023. Evolutionary-scale prediction of atomic-level protein structure with a language model. Science, 379(6637):1123--1130
2023
-
[16]
Sheng Liu, Jonathan Niles-Weed, Narges Razavian, and Carlos Fernandez-Granda. 2020. Early-learning regularization prevents memorization of noisy labels. Advances in neural information processing systems, 33:20331--20342
2020
-
[17]
Fernando Meyer, Adrian Fritz, Zhi-Luo Deng, David Koslicki, Till Robin Lesker, Alexey Gurevich, Gary Robertson, Mohammed Alser, Dmitry Antipov, Francesco Beghini, and 1 others. 2022. Critical assessment of metagenome interpretation: the second round of challenges. Nature methods, 19(4):429--440
2022
-
[18]
Rafael M \"u ller, Simon Kornblith, and Geoffrey E Hinton. 2019. When does label smoothing help? Advances in neural information processing systems, 32
2019
-
[19]
Stephen Nayfach, Simon Roux, Rekha Seshadri, Daniel Udwary, Neha Varghese, Frederik Schulz, Dongying Wu, David Paez-Espino, I-Min Chen, Marcel Huntemann, and 1 others. 2021. A genomic catalog of earth’s microbiomes. Nature biotechnology, 39(4):499--509
2021
-
[20]
R Prabakaran and Yana Bromberg. 2025. Deciphering enzymatic potential in metagenomic reads through dna language models. Nucleic Acids Research, 53(16):gkaf836
2025
-
[21]
H Ye Simon, Katherine J Siddle, Daniel J Park, and Pardis C Sabeti. 2019. Benchmarking metagenomics tools for taxonomic classification. Cell, 178(4):779--794
2019
-
[22]
Luke R Thompson, Jon G Sanders, Daniel McDonald, Amnon Amir, Joshua Ladau, Kenneth J Locey, Robert J Prill, Anupriya Tripathi, Sean M Gibbons, Gail Ackermann, and 1 others. 2017. A communal catalogue reveals earth’s multiscale microbial diversity. Nature, 551(7681):457--463
2017
-
[23]
Jack Valmadre. 2022. Hierarchical classification at multiple operating points. Advances in Neural Information Processing Systems, 35:18034--18045
2022
-
[24]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30
2017
-
[25]
Harit Vishwakarma, Yi Chen, Satya Sai Srinath Namburi Gnvv, Sui Jiet Tay, Ramya Korlakai Vinayak, and Frederic Sala. 2025. Rethinking confidence scores and thresholds in pseudolabeling-based ssl. In Forty-second International Conference on Machine Learning
2025
-
[26]
u ller, Daniel J \
Alexander Wichmann, Etienne Buschong, Andr \'e M \"u ller, Daniel J \"u nger, Andreas Hildebrandt, Thomas Hankeln, and Bertil Schmidt. 2023. Metatransformer: deep metagenomic sequencing read classification using self-attention models. NAR Genomics and Bioinformatics, 5(3):lqad082
2023
-
[27]
Derrick E Wood, Jennifer Lu, and Ben Langmead. 2019. Improved metagenomic analysis with kraken 2. Genome biology, 20(1):257
2019
-
[28]
Rongguang Ye, Ming Tang, and Edith CH Ngai. 2025. On-the-fly adaptation to quantization: Configuration-aware lora for efficient fine-tuning of quantized llms. arXiv preprint arXiv:2509.25214
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Rongye Ye, Lun Li, Ana Tereza Ribeiro de Vasconcelos, and Shuhui Song. 2026. Influ-bert: a domain-adaptive genomic language model for advancing influenza a virus research. Briefings in Bioinformatics, 27(2):bbag171
2026
-
[30]
Li Yuan, Francis EH Tay, Guilin Li, Tao Wang, and Jiashi Feng. 2020. Revisiting knowledge distillation via label smoothing regularization. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3903--3911
2020
-
[31]
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. 2016. Understanding deep learning requires rethinking generalization. arXiv preprint arXiv:1611.03530
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[32]
Zhihan Zhou, Robert Riley, Satria Kautsar, Weimin Wu, Rob Egan, Steven Hofmeyr, Shira Goldhaber-Gordon, Mutian Yu, Harrison Ho, Fengchen Liu, and 1 others. 2025. Genomeocean: an efficient genome foundation model trained on large-scale metagenomic assemblies. bioRxiv
2025
-
[33]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[34]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.