CosmicFish-HRM: Adaptive Reasoning via Hierarchical Recurrent Mechanisms in Compact Language Models
Pith reviewed 2026-06-29 14:00 UTC · model grok-4.3
The pith
A compact language model learns to vary the number of reasoning steps it applies to each input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
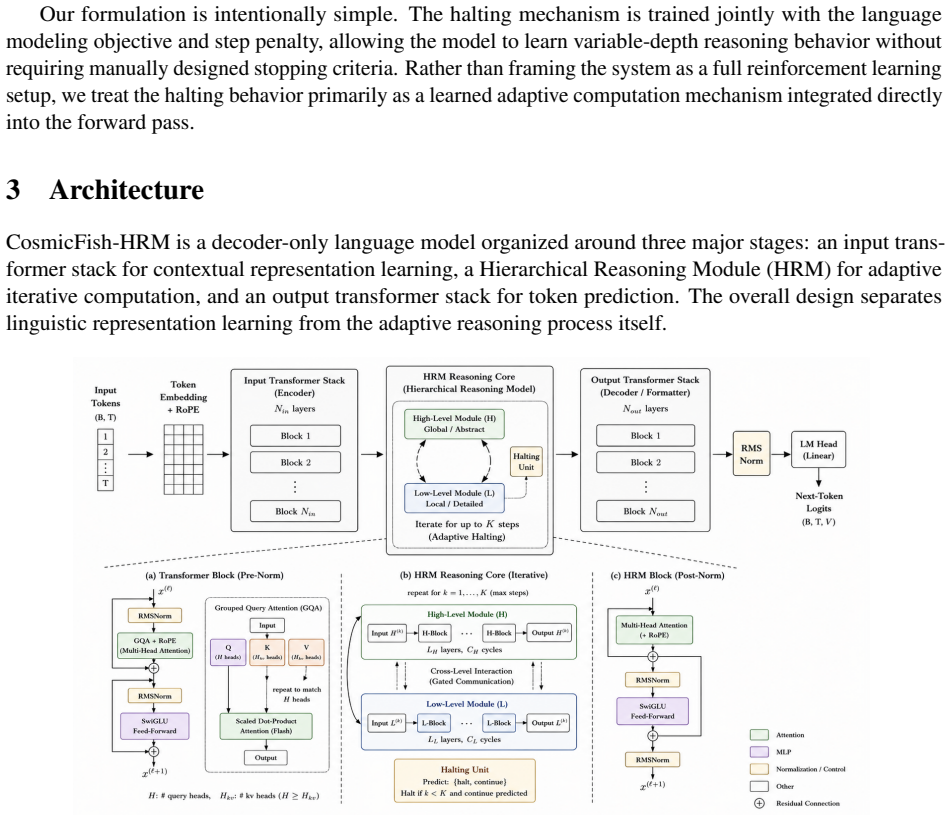
By integrating a Hierarchical Reasoning Module into a compact language model that also uses Grouped Query Attention, RoPE, and SwiGLU, the system learns to perform a variable number of high-level and low-level reasoning cycles and to halt based on input complexity, resulting in different amounts of computation being allocated to different tasks and inputs instead of uniform fixed-depth processing.
What carries the argument
The Hierarchical Reasoning Module (HRM), which executes iterative high-level and low-level reasoning cycles and learns when to stop according to input complexity.
If this is right
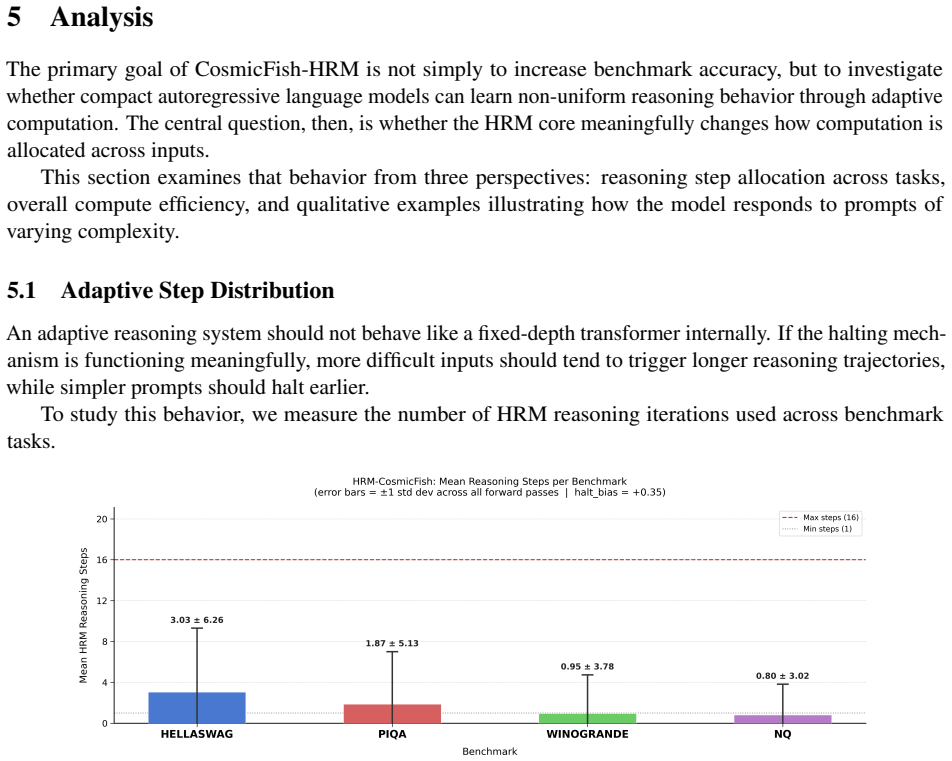
- The model automatically assigns more reasoning cycles to harder inputs and fewer to easier ones.
- The overhead of the additional reasoning infrastructure becomes proportionally smaller at larger model sizes.
- Adaptive reasoning depth provides an alternative route to improved reasoning performance besides simply increasing parameter count.
- Reasoning capability can emerge from learned control over computation depth rather than from fixed architecture depth alone.
Where Pith is reading between the lines
- Measuring total compute across an entire benchmark set would show whether the variable depth actually reduces average cost compared with fixed-depth baselines.
- The same halting logic could be tested in other iterative architectures such as recurrent vision models or planning agents.
- If the learned stopping rule transfers across domains, it might reduce the need for task-specific prompt engineering that forces extra reasoning steps.
Load-bearing premise
The added cost of the hierarchical reasoning module will become relatively smaller and more advantageous as the size of the base language model increases.
What would settle it
Training larger versions of the model and measuring whether they reach higher reasoning accuracy per total floating-point operation than standard transformers of matched size on the same tasks; if the efficiency gap does not appear or reverses, the adaptive approach does not deliver the claimed scaling benefit.
Figures
read the original abstract
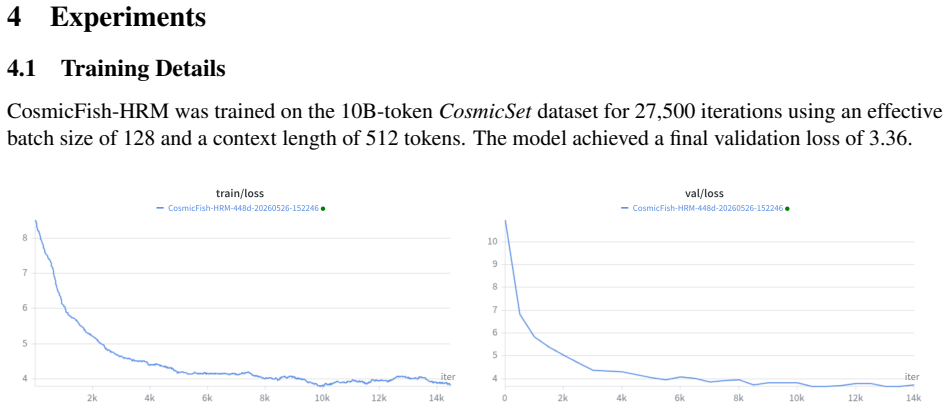
Large language models have achieved strong reasoning capabilities, though often at the cost of massive parameter counts and expensive inference. In this work, we explore a different direction: adaptive reasoning depth in compact language models. We present CosmicFish-HRM, a compact language model built around a Hierarchical Reasoning Module (HRM) that dynamically allocates computational effort during inference. Instead of applying fixed computation to every input, the model iterates through high-level and low-level reasoning cycles and learns when to halt based on input complexity. CosmicFish-HRM combines this adaptive reasoning core with modern transformer components including Grouped Query Attention, RoPE, and SwiGLU activations. While the additional reasoning infrastructure introduces overhead at small scale, we hypothesize that this tradeoff becomes increasingly favorable as model size grows and the relative cost of the HRM core diminishes. Our results show that the model learns non-uniform reasoning behavior, allocating different numbers of reasoning steps across tasks and inputs. These findings suggest that adaptive reasoning depth may offer a promising alternative to relying solely on parameter scale for reasoning capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CosmicFish-HRM, a compact language model built around a Hierarchical Reasoning Module (HRM) that performs iterative high-level and low-level reasoning cycles and learns a halting condition based on input complexity. It integrates this module with standard transformer components (Grouped Query Attention, RoPE, SwiGLU) and reports that the resulting model exhibits non-uniform reasoning behavior by allocating different numbers of reasoning steps across tasks and inputs; a scaling hypothesis is stated that the overhead of the HRM core becomes relatively less costly at larger model sizes.
Significance. If the empirical claims hold, the work would be significant as a concrete demonstration that adaptive computation depth can be learned inside compact models rather than relying exclusively on parameter count, providing a potential efficiency route for reasoning tasks.
major comments (1)
- Abstract: the central claim that 'our results show that the model learns non-uniform reasoning behavior' is stated without any accompanying data, tables, figures, error bars, ablation studies, or methodological details sufficient to evaluate support for the claim.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and the opportunity to clarify the presentation of our results. Below we respond directly to the single major comment.
read point-by-point responses
-
Referee: Abstract: the central claim that 'our results show that the model learns non-uniform reasoning behavior' is stated without any accompanying data, tables, figures, error bars, ablation studies, or methodological details sufficient to evaluate support for the claim.
Authors: We agree that an abstract should not make unsupported claims. The manuscript body (Section 4 and Figures 2–4) contains the supporting evidence: histograms of per-input reasoning-step counts across tasks, tables reporting mean and variance of step allocation with error bars from multiple runs, and ablations isolating the halting mechanism. The abstract, however, is written as a high-level summary and therefore omits these specifics. We will revise the abstract to either (a) qualify the claim (“as shown in Section 4”) or (b) add one sentence referencing the observed distribution of reasoning depths, keeping the abstract within length limits. revision: yes
Circularity Check
No significant circularity identified
full rationale
The manuscript text consists of high-level architectural description and empirical observations without any equations, derivation chains, fitted parameters presented as predictions, or load-bearing self-citations. The claim that the model learns non-uniform reasoning behavior is stated as an observed result from training, not derived by construction from its own inputs. The scaling tradeoff is explicitly labeled a hypothesis rather than a proven result. No steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zeiler, Sumit Sanghai, and Yuexin Xu. GQA: Training generalized multi-query transformer models from multi-head checkpoints.arXiv preprint arXiv:2305.13245, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Andrea Banino, Jan Balaguer, and Charles Blundell. PonderNet: Learning to ponder.arXiv preprint arXiv:2107.05407, 2021
-
[3]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Moham- mad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. InProceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[4]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. PIQA: Reasoning about physical commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence, 2020
2020
-
[5]
On the Measure of Intelligence
Franc ¸ois Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[6]
Think you have solved question answering? Try ARC, the AI2 reasoning challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC, the AI2 reasoning challenge. 2018
2018
-
[7]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers. arXiv preprint arXiv:1807.03819, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[9]
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio C´esar Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. Textbooks are all you need.arXiv preprint arXiv:2306.11644, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, 2017
2017
-
[12]
Farrar, Straus and Giroux, 2011
Daniel Kahneman.Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011
2011
-
[13]
Natural questions: A benchmark for question answering research
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: A benchmark for question answering research. volume 7, pages 453–466, 2019
2019
-
[14]
Human-level control through deep reinforcement learning.Nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.Nature, 518(7540):529–533, 2015
2015
-
[15]
GPT-4 technical report
OpenAI. GPT-4 technical report. Technical report, OpenAI, 2023. URL https://arxiv.org/abs/2303. 08774
2023
-
[16]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.arXiv preprint arXiv:2203.02155, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Using the Output Embedding to Improve Language Models
Ofir Press and Lior Wolf. Using the output embedding to improve language models.arXiv preprint arXiv:1608.05859, 2017. 16
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Language models are unsupervised multitask learners.OpenAI Blog, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Blog, 2019
2019
-
[19]
Mixture-of-Depths: Dynamically allocating compute in transformer-based language models
David Raposo, Sam Ritter, Blake Richards, Timothy Lillicrap, Peter Humphreys, and Adam Santoro. Mixture of depths: Dynamically allocating compute in transformer-based language models.arXiv preprint arXiv:2404.02258, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
WinoGrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An adversarial winograd schema challenge at scale. InCommunications of the ACM, 2021
2021
-
[21]
Tran, Yi Tay, and Donald Metzler
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Tran, Yi Tay, and Donald Metzler. Confident adaptive language modeling.arXiv preprint arXiv:2207.07061, 2022
-
[22]
GLU Variants Improve Transformer
Noam Shazeer. GLU variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[23]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations, 2017
2017
-
[24]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengding Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, and Yasin Abbasi Yadkori. Hierarchical reasoning model.arXiv preprint arXiv:2506.21734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
On layer normalization in the transformer architecture
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tie-Yan Liu. On layer normalization in the transformer architecture. InProceedings of the 37th International Conference on Machine Learning, 2020
2020
-
[28]
HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
2019
-
[29]
Root mean square layer normalization
Biao Zhang and Rico Sennrich. Root mean square layer normalization. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[30]
TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang, Guangtao Zeng, Tianhao Wang, and Wei Lu. TinyLlama: An open-source small language model. arXiv preprint arXiv:2401.02385, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. OPT: Open pre-trained transformer language models.arXiv preprint arXiv:2205.01068, 2022. 17
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.