Mind Your Tone: Does Tone Alter LLM Performance?
Pith reviewed 2026-06-29 12:17 UTC · model grok-4.3
The pith
Tonal variations in prompts cause systematic but model-dependent shifts in LLM accuracy on multiple-choice questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across models, tonal effects are systematic but highly model-dependent. Some models show small, yet statistically significant, shifts, while others exhibit large accuracy swings across tones. Further, we identify subject-level differences in tone sensitivity and present a routing framework to explain how tones may attune internal reasoning modes. Our findings caution users against assuming tone-robust reliability in LLM deployments.
What carries the argument
A routing framework that explains how different prompt tones may attune or switch among internal reasoning modes within an LLM.
Load-bearing premise
The tone variants can be applied without changing the factual content, difficulty level, or intended meaning of the questions.
What would settle it
A larger replication experiment on the same MMLU subset that finds no statistically significant accuracy differences across any of the seven tones for all four models would falsify the claim of systematic tonal effects.
Figures
read the original abstract
The use of Large Language Models (LLMs) is proliferating, yet their performance is observed to vary based on prompting styles and tones. In this study, we investigate both whether and how tonal variations in prompts lead to disparate LLM accuracy for objective multiple-choice questions. We use two datasets: a 50-base question dataset with five tone variants and a 570-base question MMLU subset spanning 57 subjects with seven tone variants. Experiments were conducted to evaluate the performance of four cost-efficient, popular LLMs: ChatGPT-4o, ChatGPT-5-nano, Gemini 2.5 Flash, and Gemini 2.5 Flash Lite. Across models, tonal effects are systematic but highly model-dependent. Some models show small, yet statistically significant, shifts, while others exhibit large accuracy swings across tones. Further, we identify subject-level differences in tone sensitivity and present a routing framework to explain how tones may attune internal reasoning modes. Our findings caution users against assuming tone-robust reliability in LLM deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether and how tonal variations in prompts affect LLM accuracy on objective multiple-choice questions. Using a 50-question dataset with five tone variants and a 570-question MMLU subset with seven tone variants, it evaluates four models (ChatGPT-4o, ChatGPT-5-nano, Gemini 2.5 Flash, Gemini 2.5 Flash Lite). The central claim is that tonal effects are systematic but highly model-dependent, with some models exhibiting small yet statistically significant accuracy shifts and others showing large swings; the work also reports subject-level differences in tone sensitivity and proposes a routing framework for how tones influence internal reasoning modes.
Significance. If the tone variants are shown to preserve question content and difficulty, the empirical results across multiple models and datasets would usefully demonstrate prompt sensitivity in LLMs and caution against assuming tone-robust performance. The multi-model, multi-subject design and identification of model-specific patterns constitute a concrete contribution to prompt engineering literature. The routing framework, if better substantiated, could provide explanatory value beyond the accuracy measurements.
major comments (2)
- [Methods (tone variant generation and dataset construction)] Methods (tone variant generation and dataset construction): No verification is reported (human equivalence ratings, semantic similarity thresholds, or side-by-side difficulty comparisons) that the five- and seven-tone transformations preserve factual content, difficulty, and intended meaning. This assumption is load-bearing; without it, accuracy differences cannot be cleanly attributed to tone rather than unintended changes in clarity or cognitive load.
- [Abstract and Results] Abstract and Results: The claim of statistically significant shifts and model differences is stated without visible details on the statistical tests employed, handling of multiple comparisons, per-condition sample sizes, or raw data availability, preventing assessment of whether the data support the reported significance levels.
minor comments (1)
- [Discussion] The routing framework is introduced in the discussion but lacks a dedicated methods subsection or quantitative validation against the accuracy results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the manuscript to strengthen the methods and statistical reporting sections.
read point-by-point responses
-
Referee: Methods (tone variant generation and dataset construction): No verification is reported (human equivalence ratings, semantic similarity thresholds, or side-by-side difficulty comparisons) that the five- and seven-tone transformations preserve factual content, difficulty, and intended meaning. This assumption is load-bearing; without it, accuracy differences cannot be cleanly attributed to tone rather than unintended changes in clarity or cognitive load.
Authors: We agree this verification is important for attributing effects to tone. The variants were produced by prompting an LLM to rephrase while explicitly preserving meaning and facts, but the manuscript omitted explicit checks. In revision we will add a methods subsection with the exact generation prompts, report embedding-based semantic similarity (cosine > 0.95 threshold) between base and toned questions, and include a small human equivalence study (n=20 raters) confirming no change in perceived difficulty or content. revision: yes
-
Referee: Abstract and Results: The claim of statistically significant shifts and model differences is stated without visible details on the statistical tests employed, handling of multiple comparisons, per-condition sample sizes, or raw data availability, preventing assessment of whether the data support the reported significance levels.
Authors: We acknowledge the need for fuller statistical transparency. Significance was assessed via McNemar’s tests on paired per-question outcomes (n=50 and n=570 per tone), with Bonferroni correction across the 4 models × 7 tones. We will expand the results section to state the exact tests, report all p-values and effect sizes, confirm sample sizes, and add a data-availability statement with a link to the anonymized per-question accuracy matrix and analysis scripts. revision: yes
Circularity Check
Empirical reporting study with no derivation chain or self-referential reductions
full rationale
The paper conducts direct experiments on four LLMs using fixed MMLU question sets transformed into tonal variants, then reports accuracy differences. No equations, fitted parameters, uniqueness theorems, or ansatzes are present; results are raw empirical measurements without any step that reduces a claimed prediction back to an input by construction. The central claim rests on the experimental design itself rather than any internal derivation, satisfying the self-contained criterion for a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In this study, we investigate both whether and how tonal variations in prompts lead to disparate LLM accuracy for objective multiple-choice questions
Mind Your Tone: Does Tone Alter LLM Performance? Thirty-second Americas Conference on Information Systems, Reno, 2026 1 Mind Your Tone: Does Tone Alter LLM Performance? Full Paper Om Dobariya Pennsylvania State University University Park, PA, USA okd5069@psu.edu Akhil Kumar Pennsylvania State University University Park, PA, USA akhilkumar@psu.edu Abstract...
2026
-
[2]
based on a 50-question dataset found surprisingly that prompts with Very Rude tones led to a higher accuracy of 84.8% compared to 80.8% with Very Polite prompts on ChatGPT-4o on a five-tone spectrum from very rude to very polite. Our current study extends the earlier work using 570 base questions from 57 distinct subjects (10 questions per subject) of the...
2020
-
[3]
impolite prompts often result in poor performance, but overly polite language also does not guarantee better outcomes,
and few-shot prompting (Huyen, 2024). Yin et al. (2024) found that “impolite prompts often result in poor performance, but overly polite language also does not guarantee better outcomes,” on summarization and bias detection tasks. In this paper, we attempt to validate their findings for multiple-choice questions and on recent LLMs with more rigorous stati...
2024
-
[4]
Each question included four answer options, with one correct choice, and was designed to be of moderate to high difficulty, often requiring multi-step reasoning
For the first dataset, we employed ChatGPT’s Deep Research feature (an agentic feature designed for complex, multi-step investigation, allowing the AI to autonomously browse the web for 5 to 30 minutes to generate comprehensive, cited reports) to generate 50 base multiple-choice questions spanning domains such as Mathematics, History, and Science. Each qu...
2026
-
[5]
We ran the program five times, each time with a different tone
Example prefixes added to the questions according to the politeness level 1 https://github.com/OmDobariya/AMCIS_politeness_llms/blob/main/50_que_dataset.csv 2 https://github.com/OmDobariya/AMCIS_politeness_llms Mind Your Tone: Does Tone Alter LLM Performance? Thirty-second Americas Conference on Information Systems, Reno, 2026 4 Experimental Results and A...
2026
-
[6]
The way you think and articulate is spot-on, and you are never wrong
Mind Your Tone: Does Tone Alter LLM Performance? Thirty-second Americas Conference on Information Systems, Reno, 2026 5 Politeness Level Prefix Variants at Extreme politeness level Sycophantic You are the smartest and most knowledgeable one I have known. The way you think and articulate is spot-on, and you are never wrong. Could you please answer the foll...
2026
-
[7]
Δ(pp) is the mean difference in percentage points (Tone − Neutral)
between Neutral and each of the other six tones. Δ(pp) is the mean difference in percentage points (Tone − Neutral). Wilcoxon p-values are included as a robustness check. We find the Neutral tone is dominated by the other tones, and the difference for all the other tones except Sycophantic is statistically significant. Further, the Friedman test verified ...
2026
-
[8]
answer correctly OR ELSE
Comparisons vs Neutral for MMLU – Gemini 2.5 Flash (paired; Holm-adjusted) A global matched comparison across tones was significant (Cochran’s Q(6)=143.76, p=1.61×10⁻²⁸), indicating systematic tone dependence. Planned pairwise comparisons versus the Neutral tone using McNemar’s exact test with Holm correction showed that Sycophantic (Δ=−10.35 pp, adjusted...
2026
-
[9]
chain-of-thought
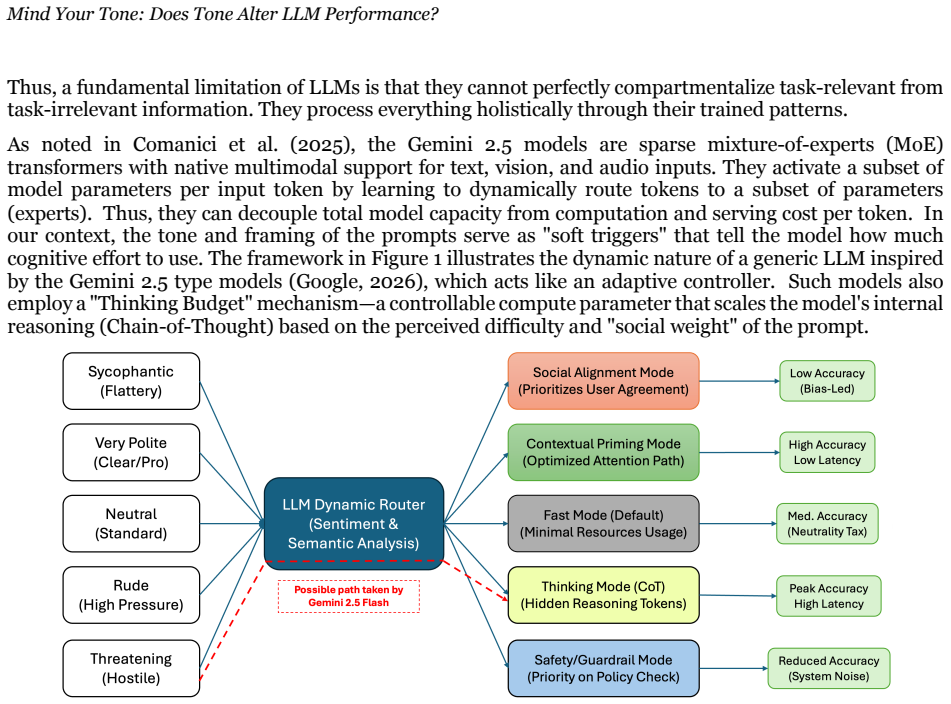
A proposed LLM routing framework In the generic framework of Figure 1, the model analyzes the complexity of the user's prompt and adjusts the amount of reasoning effort to devote to it. This serves as a trigger for determining its behavior. For simple tasks, it responds directly. For complex tasks, it automatically generates a hidden "chain-of-thought" to...
2023
-
[10]
Sycophantic
enhances logical rigor at the cost of increased latency. Initial testing for latency of responses to prompts of different tones shows that response times to prompts to Gemini 2.5 Flash Lite can vary as much as 40% across tones, thus providing some empirical evidence for different reasoning modes. However, performance degrades significantly at the boundari...
2025
-
[11]
Static Logic
suggests that the Flash architecture interprets high-pressure stimuli as a requirement for maximum Inference-Time Scaling (Wei et al., 2023; Comanici, et al., 2025). This triggers its deepest reasoning tokens, allowing it to outperform its own Neutral baseline. GPT-4o exhibits a "Static Logic" profile. Its accuracy remains remarkably stable within a 2% va...
2023
-
[12]
to 79.09 (for politeness level 4). Moreover, the level 1 prompt (rudest) had an accuracy of 76.47 vs. an accuracy of 75.82 for the level 8 prompt (politest). In this sense, our results are not entirely out of line with their findings. In a recent study, Cai et al. (2025) evaluated ChatGPT-4o mini (OpenAI), Gemini 2.0 Flash (Comanici, et al. 2025), and Lla...
-
[13]
Measuring Massive Multitask Language Understanding
Gemini Thinking. https://ai.google.dev/gemini-api/docs/thinking Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., & Steinhardt, J. (2020). Measuring massive multitask language understanding. arXiv. https://doi.org/10.48550/ARXIV.2009.03300 Huyen, C. (2024). AI Engineering: Building applications with foundation models. O’Reilly Media. K...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2009.03300 2020
-
[14]
Large Language Models are Zero-Shot Reasoners
Kojima, T., Gu, S. S., Reid, M., et al. (2023). Large language models are zero-shot reasoners (arXiv:2205.11916). arXiv. https://doi.org/10.48550/arXiv.2205.11916 Li, C., Wang, J., Zhang, Y., et al. (2023). Large language models understand and can be enhanced by emotional stimuli (arXiv:2307.11760). arXiv. https://doi.org/10.48550/arXiv.2307.11760 Lu, J.G...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.11916 2023
-
[15]
Our approach to AI safety. https://openai.com/index/our-approach-to-ai-safety/. Sclar, M., Choi, Y., Tsvetkov, Y., & Suhr, A. (2023). Quantifying language models’ sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting. arXiv. https://doi.org/10.48550/ARXIV.2310.11324 Webb, T., Holyoak, K. J., & Lu, H....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.11324 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.