OISD: On-Policy Internal Self-Distillation of Language Models
Pith reviewed 2026-06-29 13:41 UTC · model grok-4.3
The pith
Language models improve reasoning by distilling final-layer signals into intermediate layers during on-policy RL training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
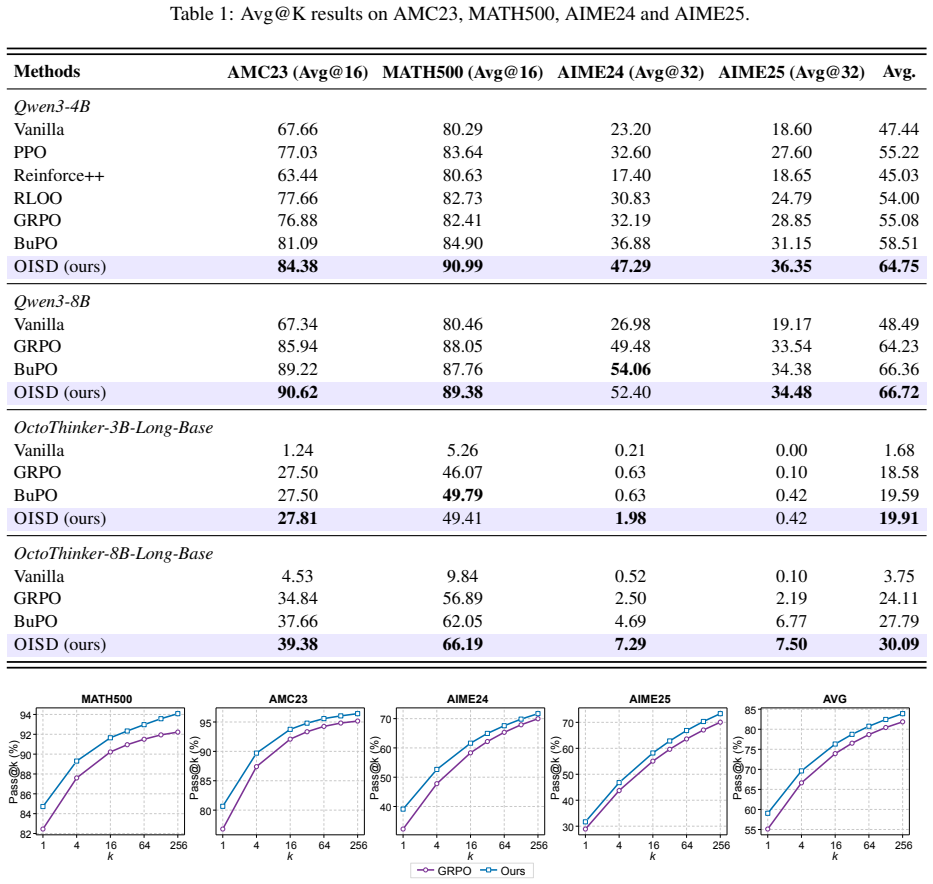
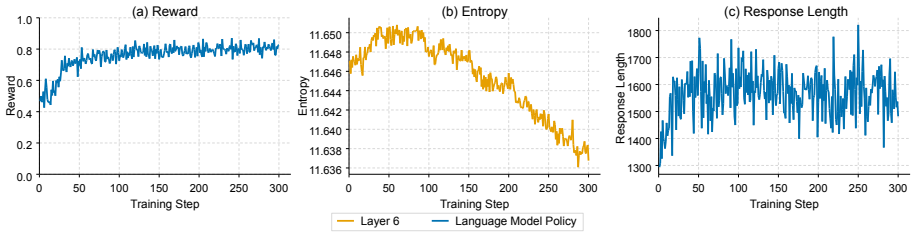
OISD uses the final layer as both the acting policy and a detached internal teacher during rollout and GRPO optimization. Selected intermediate layers are guided to match the final layer through logit alignment, which copies reasoning behaviors, and attention alignment, which copies focus patterns. The alignment employs signed advantage-weighted Jensen-Shannon divergence so that distillation occurs while preserving policy consistency under a single unified acting policy. Experiments show this produces substantial and consistent gains over strong reasoning RL baselines on four mathematical reasoning tasks.
What carries the argument
Signed advantage-weighted Jensen-Shannon alignment that distills logits and attention from the final layer to intermediate layers under a unified on-policy acting policy.
If this is right
- The approach transfers high-level reasoning behaviors without any external privileged information or separate teacher models.
- It enforces consistent attention patterns across layers while the model continues to act under one policy.
- The method yields measurable gains on four separate mathematical reasoning tasks over strong RL baselines.
- Distillation happens on-policy during the same rollouts used for policy optimization.
Where Pith is reading between the lines
- The same internal-teacher pattern could be tested on non-mathematical domains where intermediate layers already encode useful task signals.
- OISD might be combined with other forms of auxiliary supervision inside the same RL loop to compound gains.
- If the final layer's signals prove transferable, future post-training pipelines could routinely add lightweight internal alignment heads rather than only optimizing final outputs.
Load-bearing premise
The final layer's on-policy representations contain transferable predictive signals about reasoning that are worth distilling to intermediate layers without causing policy degradation.
What would settle it
Applying OISD during GRPO training and observing no improvement or outright degradation on the four mathematical reasoning benchmarks compared with GRPO alone would falsify the central claim.
Figures




read the original abstract
Recent reinforcement learning (RL) post-training approaches primarily optimize the final output policy using sparse outcome-level rewards, while largely overlooking predictive signals encoded in intermediate representations. In this paper, we introduce a new paradigm called on-policy internal self-distillation and propose the OISD framework, which improves reasoning by transferring on-policy predictive signals from the final layer to intermediate representations. During rollout and Group Relative Policy Optimization (GRPO) optimization, the final layer acts as both the policy and a detached internal teacher for selected intermediate layers, which are guided to align with it through two complementary mechanisms: logit alignment, which transfers high-level reasoning behaviors (how to think), and attention alignment, which enforces consistent attention patterns (where to look) from the final layer to the selected intermediate layer, both without requiring external privileged information. Our OISD, together with GRPO, employs signed advantage-weighted Jensen--Shannon alignment to distill informative intermediate representations while preserving policy consistency under a unified acting policy. Experimental results demonstrate the effectiveness of OISD, with substantial and consistent improvements over strong reasoning RL baselines across four mathematical reasoning tasks. The code will be released at https://github.com/THE-MALT-LAB/OISD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the OISD framework for on-policy internal self-distillation during RL post-training of language models with GRPO. The final layer serves as a detached teacher that aligns selected intermediate layers via logit alignment (transferring reasoning behaviors) and attention alignment (enforcing consistent patterns) using signed advantage-weighted Jensen-Shannon divergence, without external privileged information. The central claim is that this distills informative intermediate representations while preserving policy consistency under a unified acting policy, yielding substantial and consistent improvements over strong reasoning RL baselines on four mathematical reasoning tasks.
Significance. If the on-policy property is preserved and the improvements hold under proper controls, the approach would address a gap in outcome-only RL by leveraging internal predictive signals for better reasoning representations. The use of a unified policy and detached teacher is a clean design choice that could generalize beyond the reported tasks.
major comments (2)
- [Abstract] Abstract: the claim of 'substantial and consistent improvements' and 'preserving policy consistency under a unified acting policy' is load-bearing, yet the abstract supplies no quantitative results, baseline names, effect sizes, statistical tests, or ablation numbers. Without these, the empirical support for the central claim cannot be assessed.
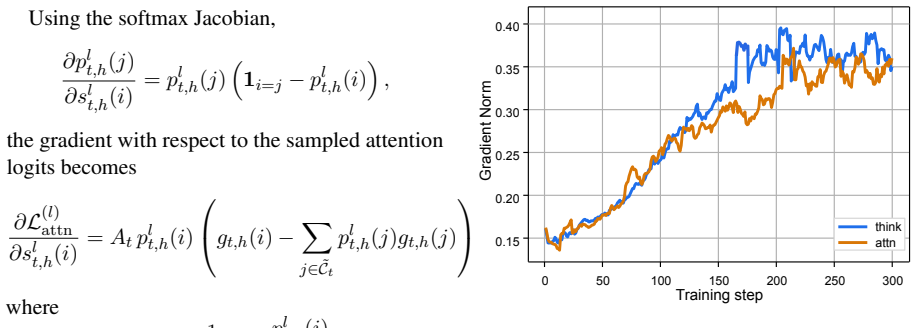
- [OISD framework description] OISD + GRPO description (alignment mechanism paragraph): the signed advantage-weighted Jensen-Shannon alignment is jointly optimized with the GRPO objective, but no equation shows the combined loss, the coefficient on the alignment term, or stop-gradient placement on the advantage weights and final-layer teacher. If the advantage weighting is not fully detached, the gradient for the acting policy incorporates representation-matching terms, which would alter the on-policy assumption that advantages derive solely from outcome rewards.
minor comments (2)
- [Abstract] The abstract mentions 'four mathematical reasoning tasks' but does not name them; adding the task names would improve clarity.
- [Abstract] The code release link is welcome, but the manuscript should include a short reproducibility checklist (hyperparameters for the alignment loss, layer selection criteria, and exact JS weighting) to support the promised release.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation and clarify technical details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'substantial and consistent improvements' and 'preserving policy consistency under a unified acting policy' is load-bearing, yet the abstract supplies no quantitative results, baseline names, effect sizes, statistical tests, or ablation numbers. Without these, the empirical support for the central claim cannot be assessed.
Authors: We agree that the abstract would benefit from quantitative support for the central claims. In the revised version we will incorporate specific results, including average performance gains over the GRPO baseline across the four mathematical reasoning tasks, the primary baseline names, and a brief reference to the evaluation protocol. revision: yes
-
Referee: [OISD framework description] OISD + GRPO description (alignment mechanism paragraph): the signed advantage-weighted Jensen-Shannon alignment is jointly optimized with the GRPO objective, but no equation shows the combined loss, the coefficient on the alignment term, or stop-gradient placement on the advantage weights and final-layer teacher. If the advantage weighting is not fully detached, the gradient for the acting policy incorporates representation-matching terms, which would alter the on-policy assumption that advantages derive solely from outcome rewards.
Authors: We acknowledge that the manuscript describes the alignment mechanisms but omits an explicit combined-loss equation and the precise stop-gradient placements. The intended design detaches both the final-layer teacher and the advantage weights (computed exclusively from outcome rewards) so that representation-matching gradients do not affect the policy update. We will add the equation L_total = L_GRPO + λ L_OISD, report the coefficient λ used in experiments, and explicitly document the stop-gradient operations to confirm that the on-policy property is preserved. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper introduces OISD as an on-policy internal self-distillation mechanism added to GRPO, using signed advantage-weighted Jensen-Shannon alignment with the final layer as detached teacher for logit and attention alignment. The abstract and description present this as an empirical augmentation that transfers predictive signals while preserving policy consistency, without any equations or definitions that reduce the claimed improvements, policy consistency, or advantages to self-referential fits or tautologies by construction. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the provided text. The central claims rest on the proposed mechanisms and experimental results rather than circular reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pages 39578–39601. MAA. 2023. American mathematics contest 12 (amc 12). MAA. 2024. American invitational mathematics exami- nation (aime). MAA. 2025. American invitational mathematics exami- nation (aime). 9 María Luisa Menéndez, Julio Angel Pardo, Leandro Pard...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover
Reinforcement learning fine-tuning enhances activation intensity and diversity in the internal cir- cuitry of llms.arXiv preprint arXiv:2509.21044. Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover
-
[3]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-distilled reasoner: On-policy self- distillation for large language models.arXiv preprint arXiv:2601.18734. Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, and 1 others. 2025a. Group sequence policy optimization.arXiv preprint arXiv:2507.18071. Chujie Zheng, Zhenru Zhang, Beichen Zha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
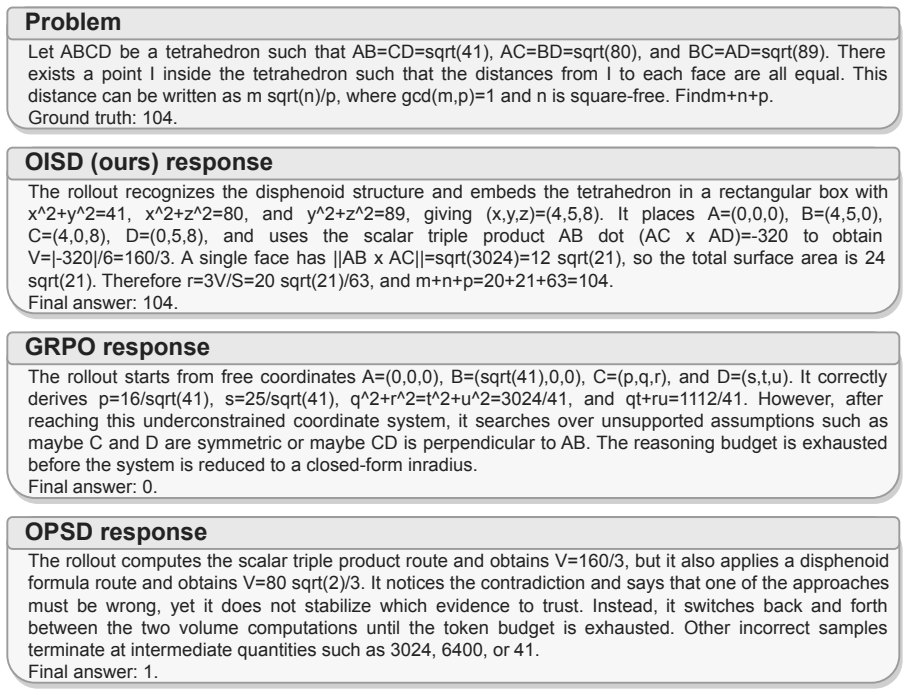
This distance can be written in the form m√n p , where m, n, p are positive integers, m and p are relatively prime, and n is not divisible by the square of any prime
There exists a point I inside the tetrahedron such that the distances from I to each of the faces of the tetrahedron are all equal. This distance can be written in the form m√n p , where m, n, p are positive integers, m and p are relatively prime, and n is not divisible by the square of any prime. Find m+n+p . Ground truth:104. 13 Problem Let ABCD be a te...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.