unix-ctf: Procedural Environments for Unix-Competence Reinforcement Learning
Pith reviewed 2026-06-29 11:16 UTC · model grok-4.3
The pith
A procedural generator of Unix CTF tasks isolates shell skills and raises fine-tuned model solve rates from 11.6% to 43.6% on holdouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
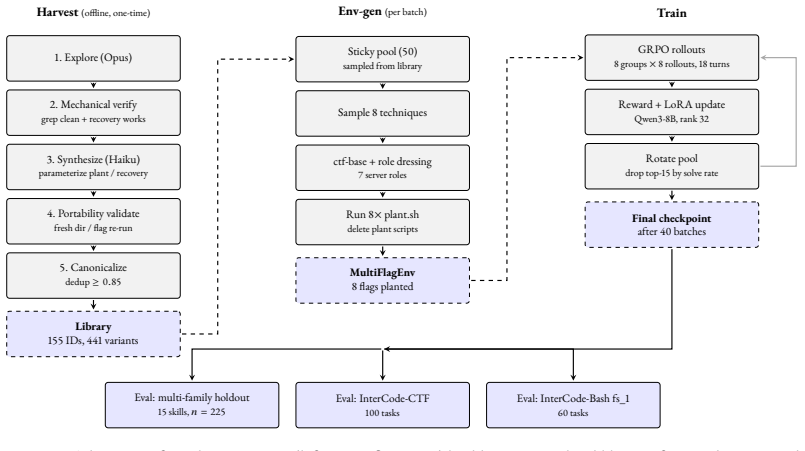
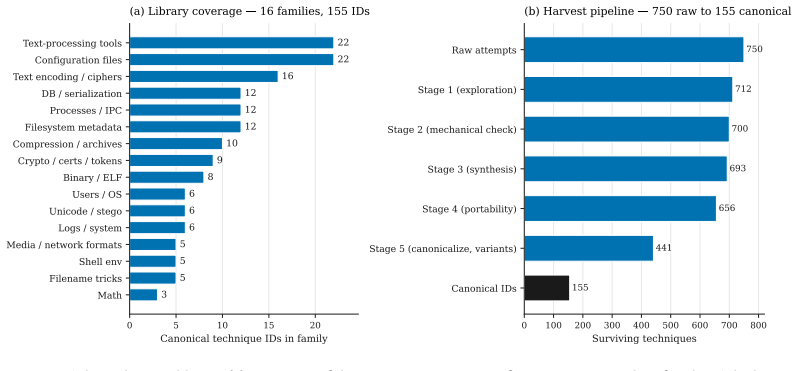
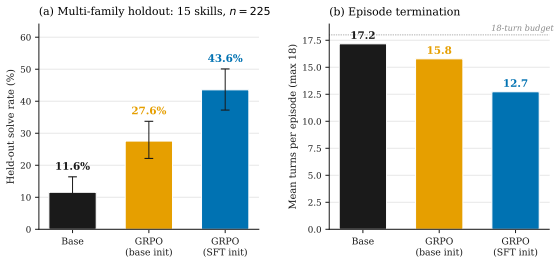
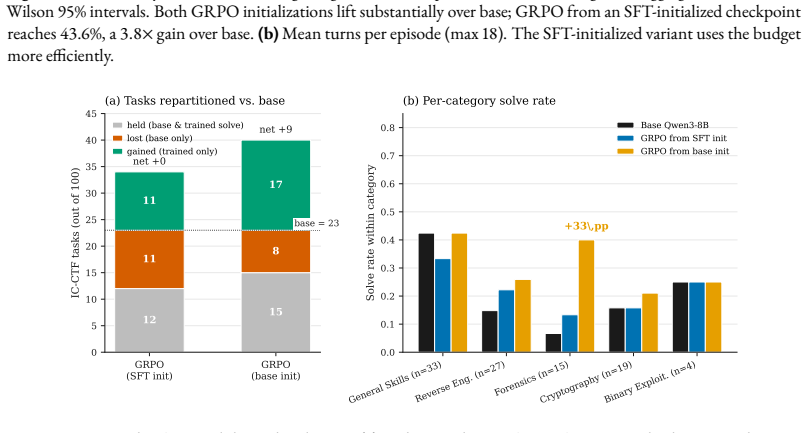
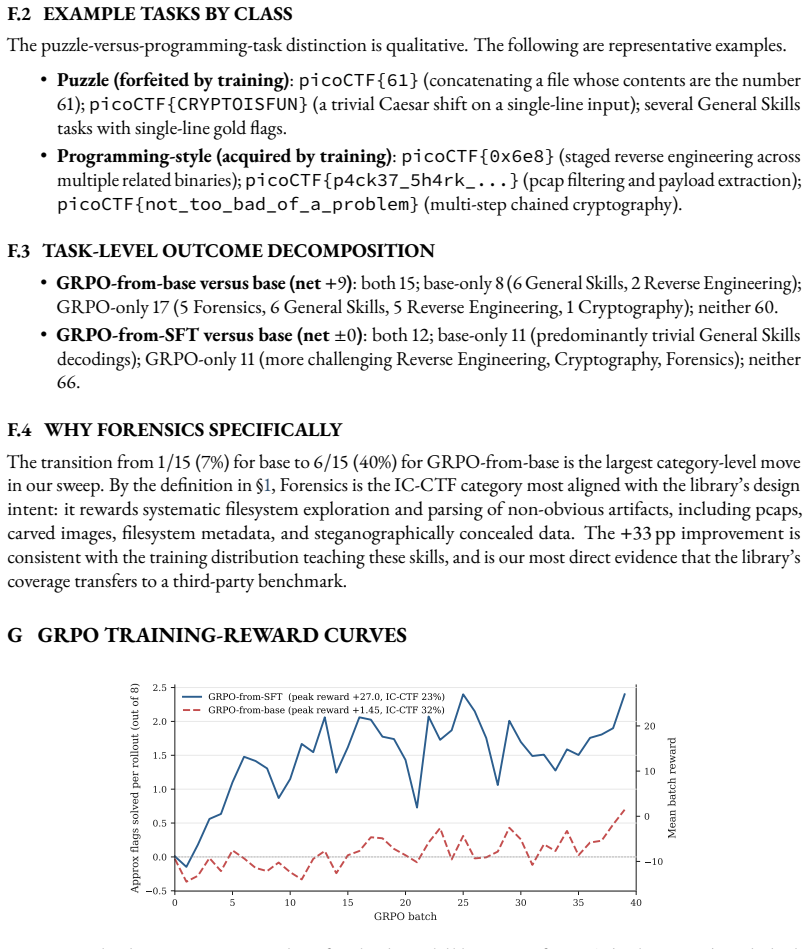
Unix competence is the ability to use shell and operating-system primitives as first-class tools. unix-ctf produces tasks by an LLM-assisted synthesis pipeline that generates candidate hiding techniques, rewrites them into parameterized hide-and-find script pairs, and filters them with a bidirectional contract. The pipeline yields 656 valid variants from 750 attempts. Fine-tuning Qwen3-8B with LoRA using GRPO on this surface lifts solve rate from 11.6% to 43.6% on a 15-skill multi-family holdout (n=225), redistributes which InterCode-CTF tasks the model solves, and produces a +33 pp gain in Forensics while reaching 32/100 on InterCode-CTF.
What carries the argument
The bidirectional contract in the LLM-assisted synthesis pipeline, which requires hide scripts to leave no plaintext trace of the flag and find scripts to recover it in a fresh directory.
If this is right
- The generated tasks achieve an 87.5% success rate under the contract checks.
- Fine-tuning redistributes success across InterCode-CTF tasks.
- The approach yields a 33 percentage point gain in the Forensics category.
- Overall performance reaches 32 out of 100 on InterCode-CTF after training.
Where Pith is reading between the lines
- This method might allow creation of similar training sets for other specific computing skills.
- Future benchmarks could separate Unix competence from programming skills to better measure progress.
- Agents trained this way could handle real shell tasks more reliably without needing full programming knowledge.
Load-bearing premise
The tasks generated by the pipeline test actual Unix competence without artifacts from the LLM synthesis or the fixed container layout.
What would settle it
A test showing that models trained on unix-ctf perform no better than untrained models on a collection of Unix tasks created without using the generator would falsify the separability and trainability claim.
Figures
read the original abstract
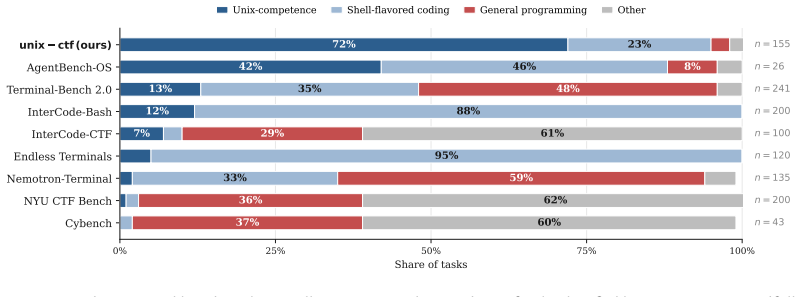
Unix competence is the ability to use shell and operating-system primitives as first-class tools, not merely to write programs through a terminal. Current terminal benchmarks tend to blur this distinction: a solver fluent in Python but weak in Unix can pass a substantial fraction of Terminal-Bench 2.0, while the reverse skill profile is rarely exercised. We make the distinction operational and build a training surface for the Unix component. unix-ctf is a procedural generator of capture-the-flag tasks for shell agents. Each task hides a short token (a flag of the form flag(a3b1c9...)) inside a fresh Linux container using a single Unix feature, and the agent must recover it. Tasks are produced by an LLM-assisted synthesis pipeline that generates candidate hiding techniques, rewrites them into parameterized hide-and-find script pairs, and filters them with a bidirectional contract: the hide script must leave no plaintext trace of the flag on disk, and the find script must recover the flag in a fresh directory. Because the LLM only writes the planting and recovery steps (the container, layout, and grading harness are fixed), the pipeline lands 656 of 750 raw attempts as portable, reusable variants (87.5\%). Our reproduction of Endless Terminals' full-container-generation approach lands only 17.4\% under the same checks. The 656 variants canonicalize to 155 distinct techniques. Fine-tuning Qwen3-8B with LoRA using GRPO on this surface lifts solve rate from 11.6\% to 43.6\% on a 15-skill multi-family holdout (n=225), redistributes which InterCode-CTF tasks the model solves, and produces a +33 pp gain in Forensics while reaching 32/100 on InterCode-CTF. These results suggest that Unix competence is separable, trainable, and best evaluated directly rather than folded into programming-through-a-shell.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces unix-ctf, a procedural generator of Unix CTF tasks for training shell agents on Unix competence. Tasks hide a flag using a single Unix feature inside a fixed Linux container via an LLM-assisted pipeline that produces hide-and-find script pairs, filtered by a bidirectional contract (no plaintext flag trace after hiding; full recoverability by the find script). The pipeline achieves 87.5% yield (656/750) versus 17.4% for a reproduced full-container baseline, yielding 155 distinct techniques. Fine-tuning Qwen3-8B with LoRA + GRPO raises solve rate from 11.6% to 43.6% on a 15-skill multi-family holdout (n=225), redistributes solved InterCode-CTF tasks, delivers a +33 pp gain in Forensics, and reaches 32/100 on InterCode-CTF. The work concludes that Unix competence is separable, trainable, and best evaluated directly.
Significance. If the reported gains reflect acquisition of genuine, separable Unix skills, the work supplies a high-yield, reproducible procedural training surface for RL on terminal agents that isolates Unix primitives from general programming. The fixed harness, bidirectional contract, and direct comparison to prior generation methods are concrete strengths that support reproducibility and controlled experimentation.
major comments (2)
- [Abstract / Results] Abstract / Results: the reported performance figures (11.6% o 43.6% on the 15-skill holdout, +33 pp Forensics gain, 32/100 on InterCode-CTF) are presented without error bars, holdout-construction details, statistical tests, or description of how the 15 skill families were selected and balanced. These omissions make the central empirical claims difficult to evaluate for reliability.
- [Task Generation Pipeline] Task Generation Pipeline: the bidirectional contract only enforces absence of plaintext flag traces and recoverability; it does not constrain statistical regularities in the 155 techniques, directory-naming conventions, permission patterns, or command sequences produced by the fixed container/layout. Because training and the internal holdout are sampled from the same generator, shared artifacts could produce the observed lift and InterCode-CTF redistribution without the model having acquired transferable Unix competence. A targeted test (e.g., distribution-shifted holdout or adversarial variants) is needed to support the separability claim.
minor comments (2)
- [Abstract] The canonicalization step that reduces 656 variants to 155 distinct techniques would benefit from an explicit description of the deduplication criteria.
- [Evaluation] Clarify whether the 15-skill families were chosen to ensure balanced coverage or based on other criteria.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing evaluation rigor and the need to rule out generator-specific artifacts. We address both major comments below and will incorporate revisions to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract / Results: the reported performance figures (11.6% o 43.6% on the 15-skill holdout, +33 pp Forensics gain, 32/100 on InterCode-CTF) are presented without error bars, holdout-construction details, statistical tests, or description of how the 15 skill families were selected and balanced. These omissions make the central empirical claims difficult to evaluate for reliability.
Authors: We agree that the absence of error bars, statistical tests, and explicit holdout-construction details weakens the presentation of the central results. In the revised manuscript we will add: (1) bootstrap 95% confidence intervals computed over 1000 resamples for all solve-rate figures; (2) a dedicated subsection detailing how the 15 skill families were chosen (maximal coverage of Unix primitives while ensuring no overlap with training families) and balanced by task count; and (3) results of McNemar’s test for paired pre-/post-fine-tuning comparisons on the holdout. These additions will make the reliability of the reported gains directly assessable. revision: yes
-
Referee: [Task Generation Pipeline] Task Generation Pipeline: the bidirectional contract only enforces absence of plaintext flag traces and recoverability; it does not constrain statistical regularities in the 155 techniques, directory-naming conventions, permission patterns, or command sequences produced by the fixed container/layout. Because training and the internal holdout are sampled from the same generator, shared artifacts could produce the observed lift and InterCode-CTF redistribution without the model having acquired transferable Unix competence. A targeted test (e.g., distribution-shifted holdout or adversarial variants) is needed to support the separability claim.
Authors: The referee correctly notes that the bidirectional contract does not eliminate the possibility of low-level distributional artifacts shared between training and the internal holdout. While the 15-skill holdout already uses disjoint technique families and the external InterCode-CTF results show redistribution and a +33 pp Forensics gain on a benchmark with different task distributions, these do not fully substitute for an explicit distribution-shift experiment. In revision we will add an explicit limitations paragraph acknowledging this gap and, resources permitting, report a small-scale distribution-shifted probe (e.g., tasks with altered directory-naming conventions or permission patterns) to quantify sensitivity to generator regularities. We believe the current InterCode-CTF transfer evidence still supports separability but will present it more cautiously. revision: partial
Circularity Check
No significant circularity; empirical measurements on procedurally generated tasks
full rationale
The paper describes an empirical pipeline: LLM-assisted synthesis of hide/find script pairs under a bidirectional contract, canonicalization to 155 techniques, and RL fine-tuning (GRPO + LoRA) whose outcomes are measured as solve-rate lifts on a held-out 15-skill set and on InterCode-CTF. No equations, fitted parameters renamed as predictions, or derivation steps appear. The 87.5 % yield figure is a direct count of pipeline success, not a self-referential claim. Self-citation is absent; the comparison to Endless Terminals is external reproduction. Claims rest on observed performance deltas rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The LLM-assisted synthesis produces portable, reusable variants that satisfy the bidirectional contract without introducing systematic bias in task difficulty or coverage.
Reference graph
Works this paper leans on
-
[1]
Windows agent arena: Evaluating multi-modal os agents at scale, 2024
URL https://www.anthropic.com/claude/ opus. Model identifier:claude-opus-4-7. Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Y adong Lu, Justin W agle, Kazuhito Koishida, Arthur Bucker, Lawrence Jang, and Zack Hui. Windows agent arena: Evaluating multi-modal OS agents at scale.arXiv preprint arXiv:2409.08264,
-
[2]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del V erme, T om Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David V azquez, Nicolas Chapados, and Alexandre Lacoste. W orkArena: How capable are web agents at solving common knowledge work tasks?arXiv preprint arXiv:2403.07718,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Goodman, and Dimitris Papailiopoulos
Kanishk Gandhi et al. Endless terminals: Scaling rl environments for terminal agents.arXiv preprint arXiv:2601.16443,
-
[4]
LoRA: Low-Rank Adaptation of Large Language Models
arXiv:2106.09685. Naman Jain, Jaskirat Singh, Manish Shetty, Liang Zheng, Koushik Sen, and Ion Stoica. R2E-Gym: Procedural environ- ments and hybrid verifiers for scaling open-weights SWE agents.arXiv preprint arXiv:2504.07164,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
arXiv:2310.06770. Xiao Liu et al. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv:2308.03688. Mike A. Merrill et al. T erminal-Bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Training Software Engineering Agents and Verifiers with SWE-Gym
PMLR 267; arXiv:2412.21139. Renjie Pi, Grace Lam, Mohammad Shoeybi, Pooya Jannaty, Bryan Catanzaro, and W ei Ping. On data engineering for scaling LLM terminal capabilities.arXiv preprint arXiv:2602.21193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
W AL T: W eb agents that learn tools.arXiv preprint arXiv:2510.01524,
Viraj Prabhu et al. W AL T: W eb agents that learn tools.arXiv preprint arXiv:2510.01524,
-
[9]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan W altz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, W ei Li, Folawiyo Campbell-Ajala, Daniel T oyama, Robert Berry, Divya T yamagundlu, Timothy Lillicrap, and Oriana Riva. AndroidW orld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Minghao Shao, Sofija Jancheska, Meet Udeshi, Brendan Dolan-Gavitt, Haoran Xi, Kimberly Milner, Boyuan Chen, Max Yin, Siddharth Garg, Prashanth Krishnamurthy, Farshad Khorrami, Ramesh Karri, and Muhammad Shafique. NYU CTF Bench: A scalable open-source benchmark dataset for evaluating LLMs in offensive security.arXiv preprint arXiv:2406.05590, 2024a. Zhihon...
-
[11]
Os-copilot: Towards generalist computer agents with self-improvement, 2024
Zhiyong Wu, Chengcheng Han, Zichen Ding, Zhenmin W eng, Zhoumianze Liu, Shunyu Y ao, T ao Yu, and Lingpeng Kong. OS-Copilot: T owards generalist computer agents with self-improvement.arXiv preprint arXiv:2402.07456,
-
[12]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, T oh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and T ao Yu. OSW orld: Benchmarking multimodal agents for open-ended tasks in real computer environments.arXiv preprint arXiv:2404.07972,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
An Y ang et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. John Y ang, Akshara Prabhakar, Karthik Narasimhan, and Shunyu Y ao. InterCode: Standardizing and benchmarking interactive coding with execution feedback. InNeurIPS Datasets and Benchmarks Track,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
John Y ang, Kilian Lieret, Carlos E
arXiv:2306.14898. John Y ang, Kilian Lieret, Carlos E. Jimenez, Alexander W ettig, Kabir Khandpur, Y anzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Y ang. SWE-smith: Scaling data for software engineering agents.arXiv preprint arXiv:2504.21798, 2025b. Andy K. Zhang, Neil Perry, Riya Dulepet, et al. Cybench: A framework for evaluating cybers...
-
[15]
SkillWeaver: Web Agents can Self-Improve by Discovering and Honing Skills
Boyuan Zheng et al. SkillW eaver: W eb agents can self-improve by discovering and honing skills.arXiv preprint arXiv:2504.07079,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Y onatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. W ebArena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Self-challenging language model agents.arXiv preprint arXiv:2506.01716,
Yifei Zhou et al. Self-challenging language model agents.arXiv preprint arXiv:2506.01716,
-
[18]
CTF-Dojo: Executable-environment trajectory training for cyber agents, 2025
T erry Yue Zhuo, Dingmin W ang, Hantian Ding, V arun Kumar, and Zijian W ang. T raining language model agents to find vulnerabilities with CTF-Dojo.arXiv preprint arXiv:2508.18370,
-
[19]
buildid.note
+ name + desc_padded with open("buildid.note", "wb") as f: f.write(note) PYEOF cp /bin/ls ./hidden_elf objcopy --update-section .note.gnu.build-id=buildid.note ./hidden_elf ./ hidden_elf_marked rm -f buildid.note hidden_elf mv hidden_elf_marked hidden_elf # recovery.sh readelf -n "$target_dir/hidden_elf" 2>/dev/null \ | grep -oE ’Build ID: [0-9a-f]+’ |awk...
1970
-
[20]
Reward per rollout is points_earned− turn_cost×turns_used , with turn_cost= 1, per-technique points 15, and −1per incorrect flag submission
adapters.SFT format pass.492 successful Haiku-solver trajectories against the unix-ctf library, ∼92 gradient updates on hosted Tinker; we use Tinker’s recipe defaults for optimizer, learning rate, and batch size at this stage and treat the pass as harness alignment rather than capability transfer.GRPO.40 batches, 8 groups × 8 rollouts (64 trajectories per...
2026
-
[21]
category
The same judge model (gpt-5.4-nano (OpenAI, 2026)) classifies each task into one of four skill categories. The per-task input is the instruction text, canonical solution, and grading specification. The output is {"category": "<one of four>", "reason": "<one sentence>"}. Discriminating question for unix_competence vs the others: "Could a competent Python p...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.