Unveiling Multi-regime Patterns in SciML: Distinct Failure Modes and Regime-specific Optimization
Pith reviewed 2026-06-29 13:14 UTC · model grok-4.3
The pith
SciML models exhibit a consistent three-regime structure in training with regime-specific optimization needs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
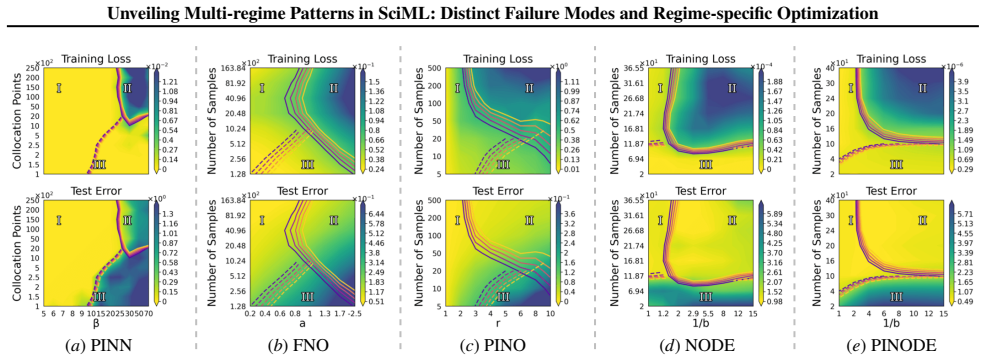
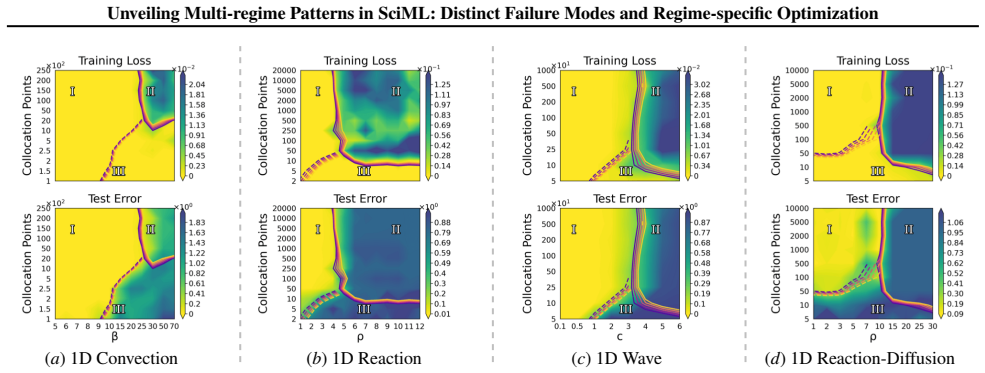
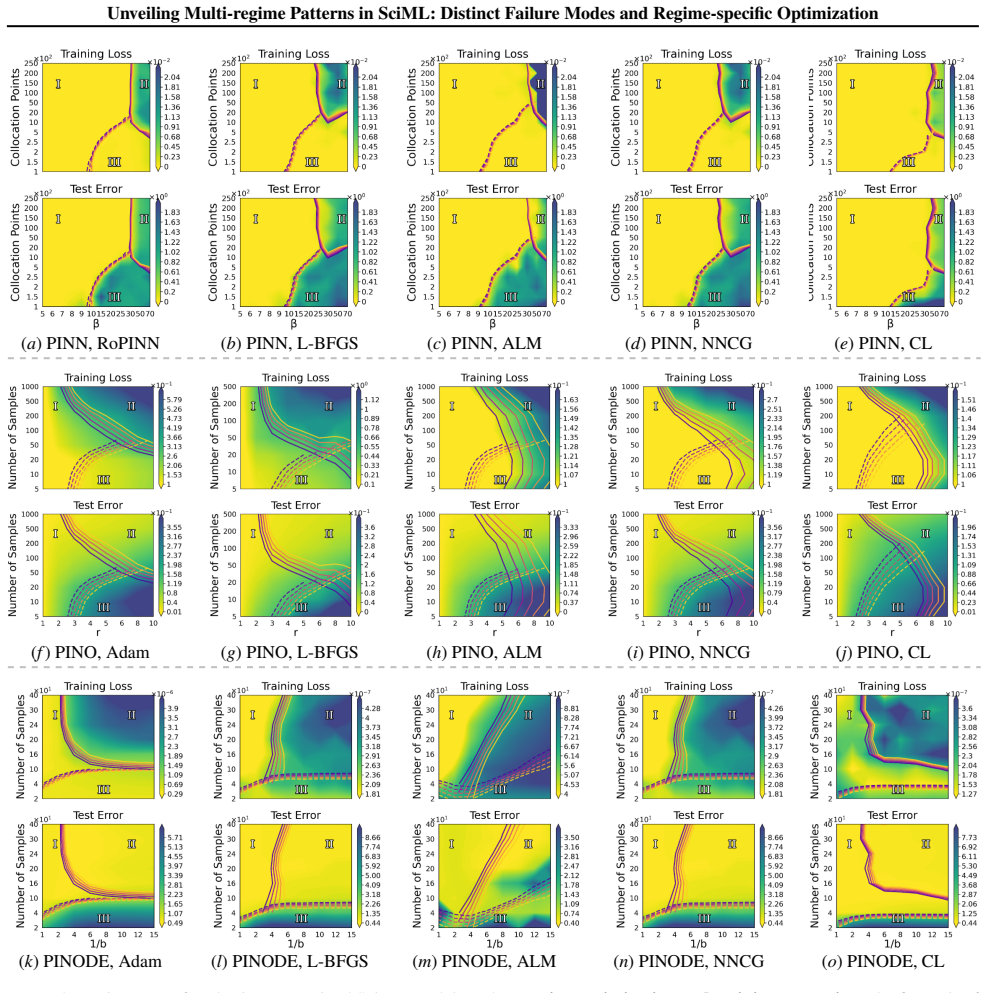
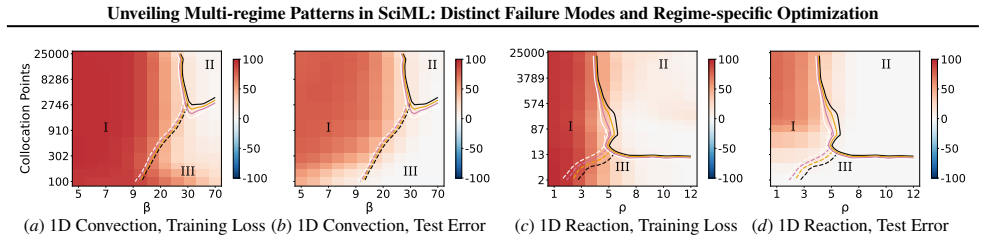
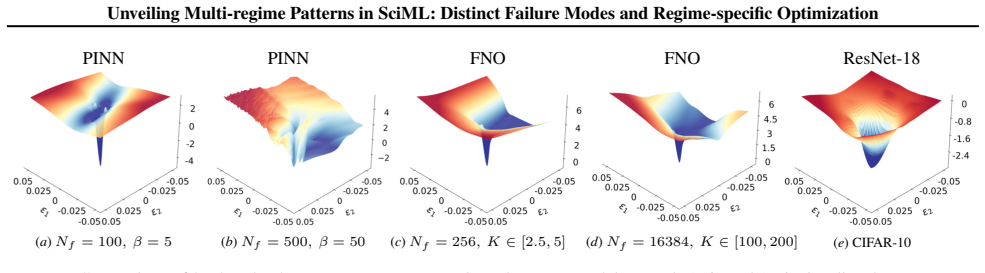
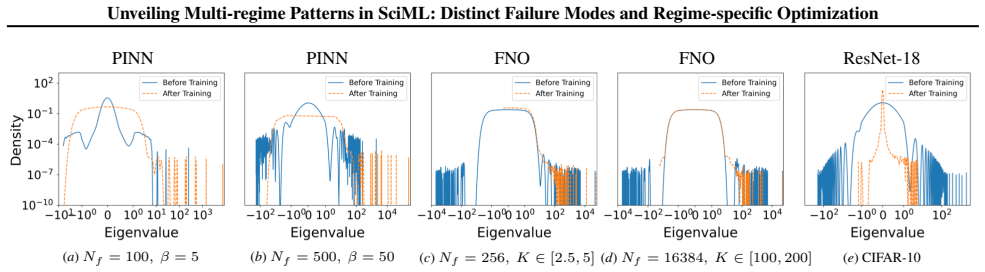
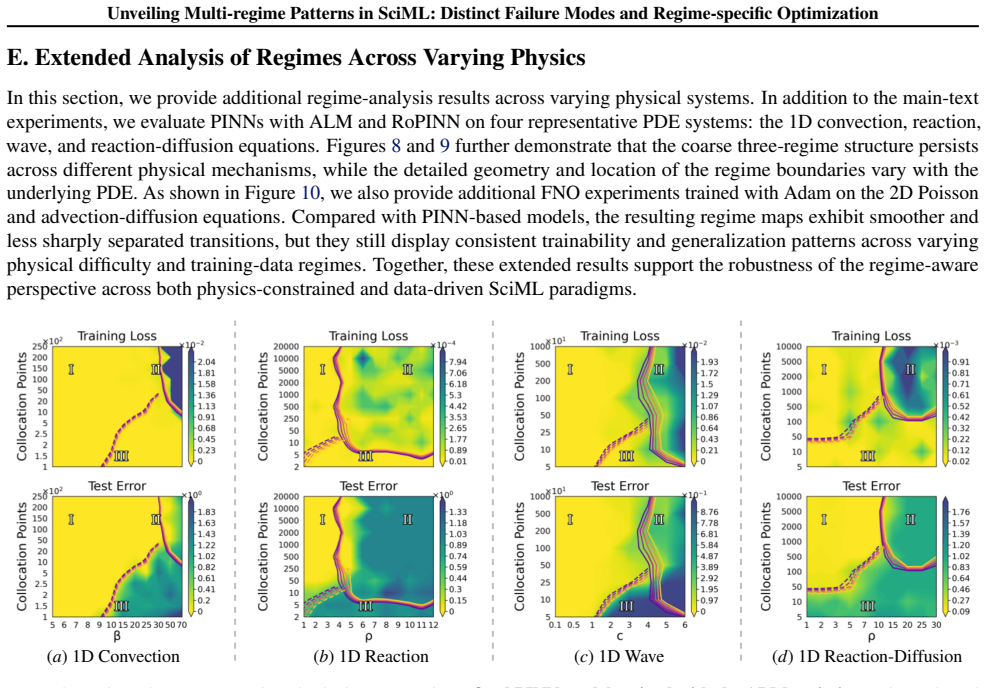
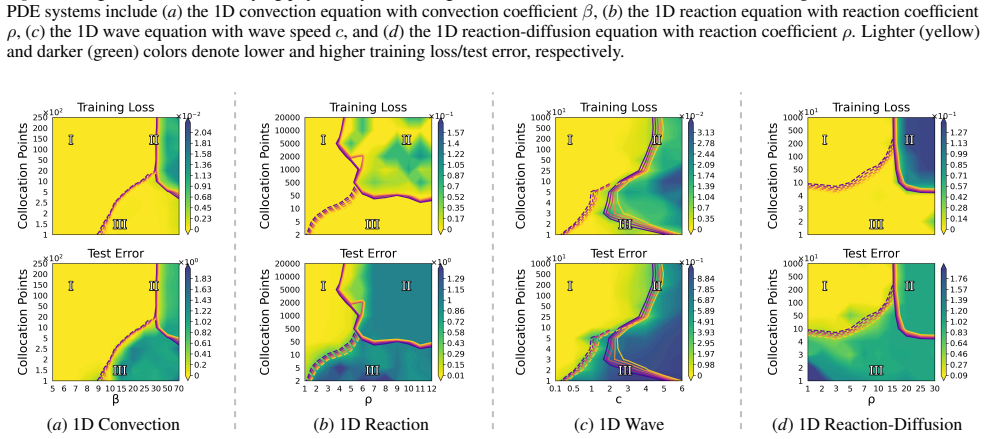
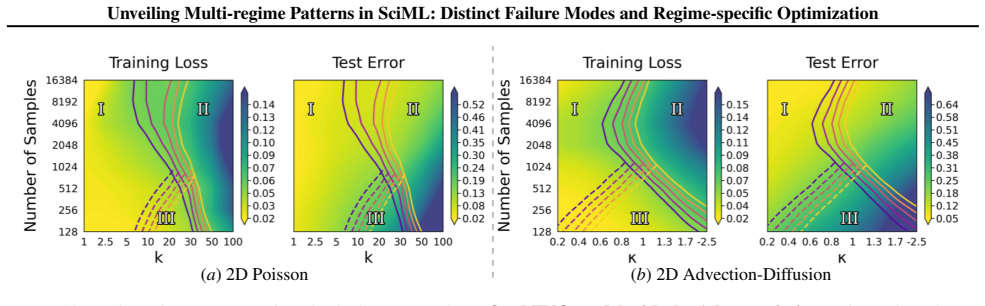
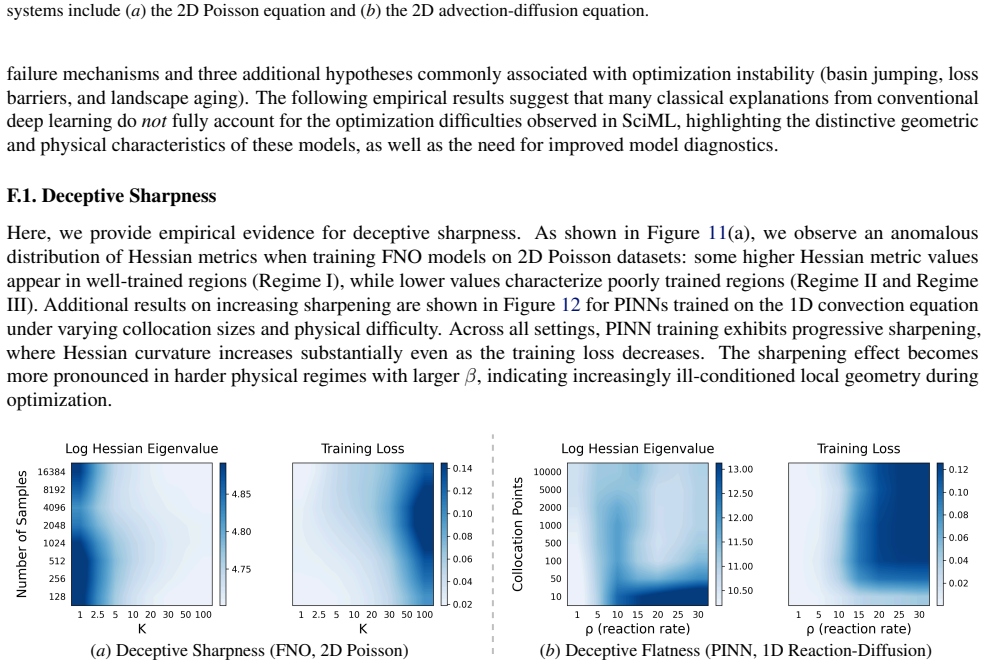
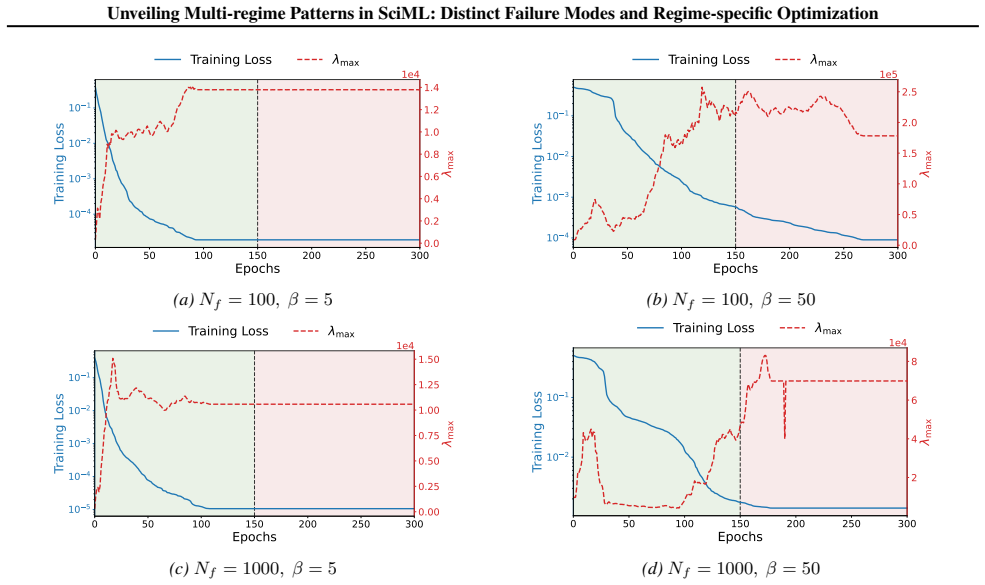
A consistent three-regime structure emerges across many standard SciML models, different constraint enforcements, and various optimizer designs. Optimization effectiveness is regime-specific, with no single method performing well across all regimes. SciML models can exhibit fine-grained failure modes that can challenge conventional interpretations of standard loss-landscape metrics. These results provide an approach to establish a unified, task-oblivious perspective on failure modes in SciML and to inform regime-aware guidance for improving robustness.
What carries the argument
The regime-aware diagnostic framework that jointly analyzes performance, training dynamics, and loss-landscape geometry.
If this is right
- No single optimization method performs well across all three regimes.
- Optimization must be chosen or adapted based on the identified regime.
- Fine-grained failure modes exist beyond what standard loss-landscape metrics reveal.
- The three-regime pattern holds for physics-informed neural networks, neural operators, and neural ODEs on ODE and PDE benchmarks.
Where Pith is reading between the lines
- Regime detection could be integrated into training loops to automatically adjust hyperparameters or optimizers.
- The framework might apply to other areas of machine learning where constraints or physical priors are used.
- Further tests with different model architectures could reveal if the three regimes are universal in SciML.
Load-bearing premise
The diagnostic framework accurately identifies distinct regimes that are not artifacts of the specific hyperparameter settings or models tested.
What would settle it
Observing that different hyperparameter settings or new SciML models produce regimes that do not align with the three identified ones would falsify the consistency of the structure.
Figures
read the original abstract
Neural networks trained under different hyperparameter settings can fall into distinct training "regimes," with consistent behavior within regimes and qualitative differences across regimes. In this paper, we study such multi-regime behavior in scientific machine learning (SciML) models through a regime-aware diagnostic framework that jointly analyzes performance, training dynamics, and loss-landscape geometry. We identify three key findings: (i) a consistent three-regime structure emerges across many standard SciML models, different constraint enforcements, and various optimizer designs; (ii) optimization effectiveness is regime-specific, with no single method performing well across all regimes; and (iii) SciML models can exhibit fine-grained failure modes that can challenge conventional interpretations of standard loss-landscape metrics. Our results provide an approach to establish a unified, task-oblivious perspective on failure modes in SciML and to inform regime-aware guidance for improving robustness. We validate these findings across widely-used SciML models, including physics-informed neural networks, neural operators, and neural ordinary differential equations, on benchmarks spanning representative ordinary and partial differential equations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a regime-aware diagnostic framework that jointly examines performance metrics, training dynamics, and loss-landscape geometry to identify multi-regime behavior in SciML models. It claims that a consistent three-regime structure appears across PINNs, neural operators, and neural ODEs under varied constraint enforcements and optimizers; that no single optimizer works well across all regimes; and that fine-grained failure modes exist that challenge standard loss-landscape interpretations. These findings are validated on representative ODE and PDE benchmarks.
Significance. If the three-regime partition is shown to be intrinsic to the optimization dynamics rather than an artifact of the diagnostic choices, the work could supply a task-oblivious taxonomy of SciML failure modes and motivate regime-aware training protocols. The breadth of models and benchmarks tested is a positive feature; however, the absence of explicit sensitivity checks on the framework's internal parameters limits the strength of the consistency claim.
major comments (2)
- [Section 3] Diagnostic framework (Section 3 and associated figures): the central claim of a 'consistent three-regime structure' across model families requires demonstration that the partition is insensitive to the specific feature set, distance metric, normalization, or clustering cutoff employed. The manuscript should include an ablation varying these choices (or reporting the exact fixed thresholds used uniformly) and showing that the number and boundaries of regimes remain stable; without this, the observed structure could be induced by the analysis pipeline rather than the loss surfaces themselves.
- [Section 4.2] Regime-specific optimization results (Section 4.2, Tables 2-4): the statement that 'no single method performing well across all regimes' is load-bearing for the practical takeaway, yet the quantitative support (e.g., win rates or relative error distributions per regime) is not accompanied by statistical significance tests across the multiple random seeds or hyperparameter sweeps. The reported performance gaps could be within noise for some regime-optimizer pairs.
minor comments (2)
- Notation for the loss-landscape features (e.g., gradient-norm variance, Hessian-trace quantiles) should be defined once in a dedicated table or subsection rather than introduced piecemeal in the text.
- Figure captions for the regime visualizations should explicitly state the exact hyperparameter settings and random seeds used to generate each panel so that the consistency claim can be reproduced.
Simulated Author's Rebuttal
We appreciate the referee's feedback on our manuscript. The comments highlight areas where additional analysis can strengthen our claims regarding the robustness of the regime identification and the statistical support for regime-specific optimization. We outline our responses below and commit to incorporating the suggested revisions.
read point-by-point responses
-
Referee: [Section 3] Diagnostic framework (Section 3 and associated figures): the central claim of a 'consistent three-regime structure' across model families requires demonstration that the partition is insensitive to the specific feature set, distance metric, normalization, or clustering cutoff employed. The manuscript should include an ablation varying these choices (or reporting the exact fixed thresholds used uniformly) and showing that the number and boundaries of regimes remain stable; without this, the observed structure could be induced by the analysis pipeline rather than the loss surfaces themselves.
Authors: We thank the referee for this important observation. To address this, we will conduct an ablation study in the revised version by varying the feature set, distance metrics, normalization methods, and clustering cutoffs. We will demonstrate that the three-regime structure persists across these variations, thereby strengthening the claim that the partition reflects intrinsic properties of the loss surfaces. Additionally, we will explicitly report the fixed thresholds used in our analysis. revision: yes
-
Referee: [Section 4.2] Regime-specific optimization results (Section 4.2, Tables 2-4): the statement that 'no single method performing well across all regimes' is load-bearing for the practical takeaway, yet the quantitative support (e.g., win rates or relative error distributions per regime) is not accompanied by statistical significance tests across the multiple random seeds or hyperparameter sweeps. The reported performance gaps could be within noise for some regime-optimizer pairs.
Authors: We agree that statistical validation is necessary to support the claim. In the revision, we will include statistical significance tests (such as paired t-tests or Wilcoxon tests) across the random seeds for the performance differences between optimizers in each regime. This will confirm whether the observed gaps are statistically significant or within noise levels. revision: yes
Circularity Check
No detectable circularity; regime identification presented as empirical observation without reduction to fitted inputs or self-citations
full rationale
The abstract and provided context describe an empirical diagnostic framework applied across multiple SciML models to identify a three-regime structure, with claims resting on observed consistency in performance, dynamics, and geometry rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equations, ansatzes, or uniqueness theorems are quoted that would make the regime partition equivalent to the analysis choices by construction. The framework is presented as task-oblivious and validated on standard benchmarks, keeping the derivation self-contained against external data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1710.09553 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.