ReasonOps: Operator Segmentation for LLM Reasoning Traces
Pith reviewed 2026-06-29 08:02 UTC · model grok-4.3
The pith
Seven recurring operators structure chain-of-thought traces across every tested LLM family and benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
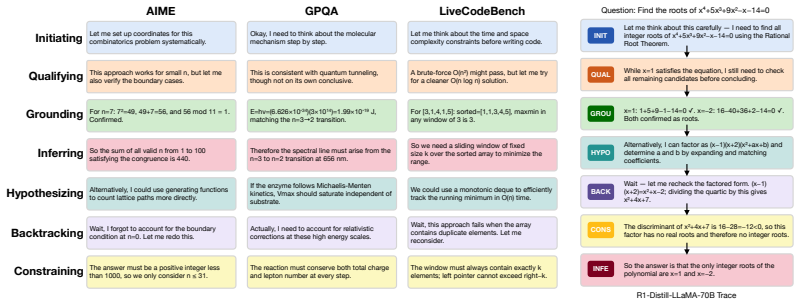
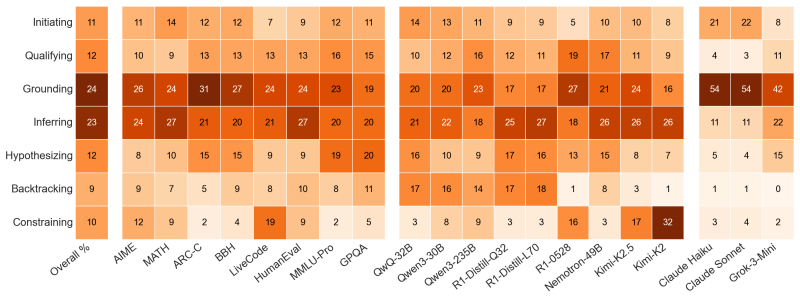
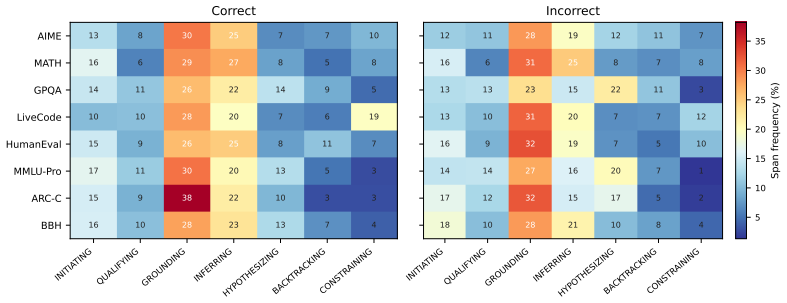
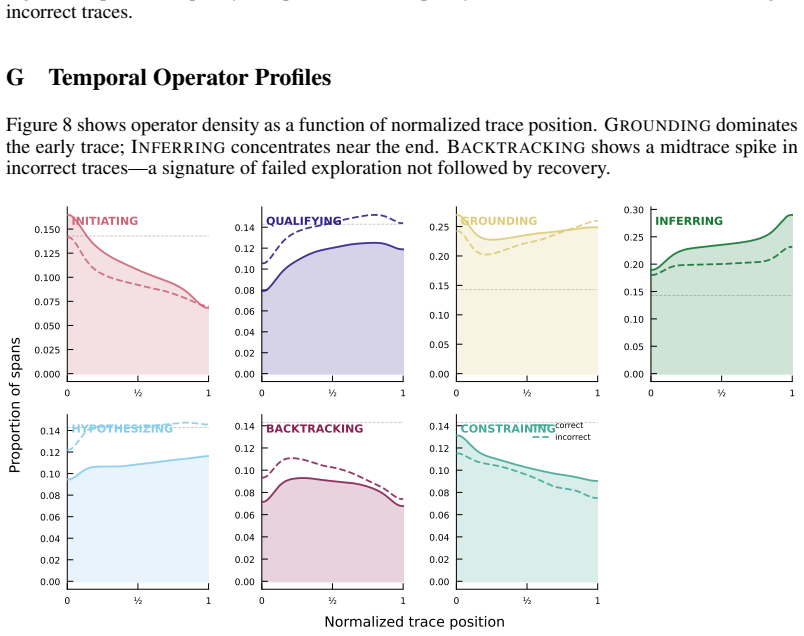
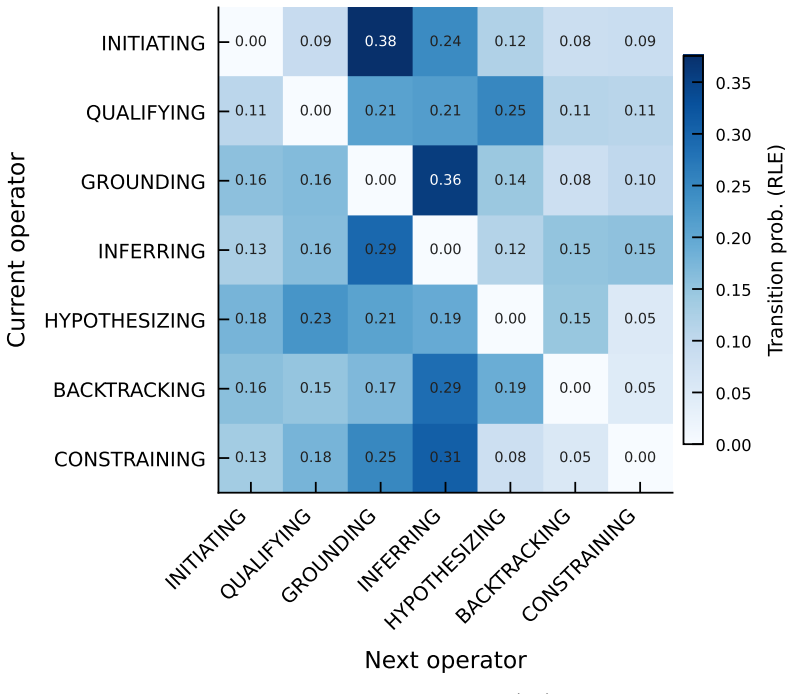
ReasonOps shows that chain-of-thought traces share a common compositional structure: seven recurring reasoning operators that emerge from unsupervised clustering of sentence-initial 3-token pivots and appear across every model family and benchmark domain.
What carries the argument
ReasonOps, an unsupervised pipeline that clusters sentence-initial 3-token pivots to annotate traces with discourse-level reasoning operators.
If this is right
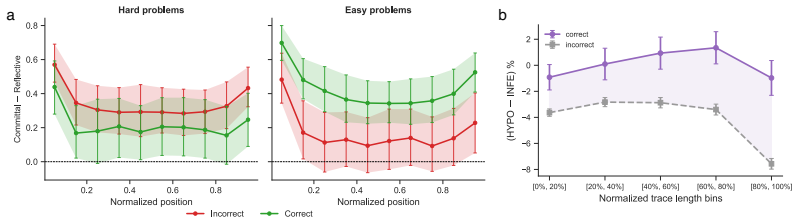
- Reflective operators are more helpful on hard problems and harm performance on easy problems.
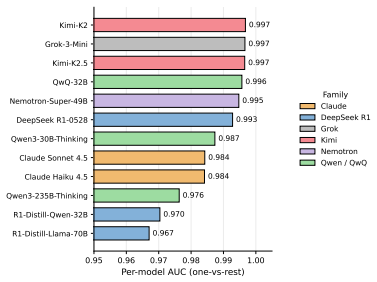
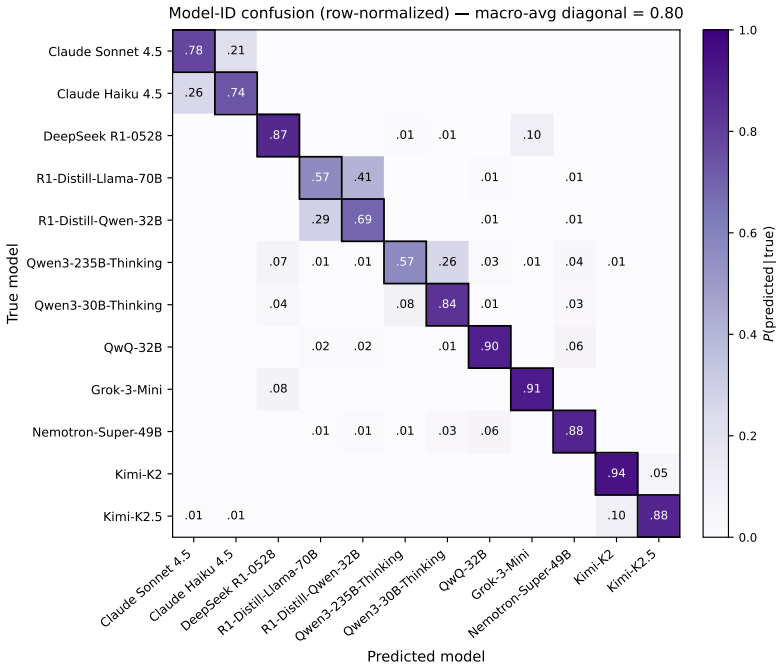
- Operator sequences are highly model-identifying, with a classifier on operator distributions alone recovering the source model.
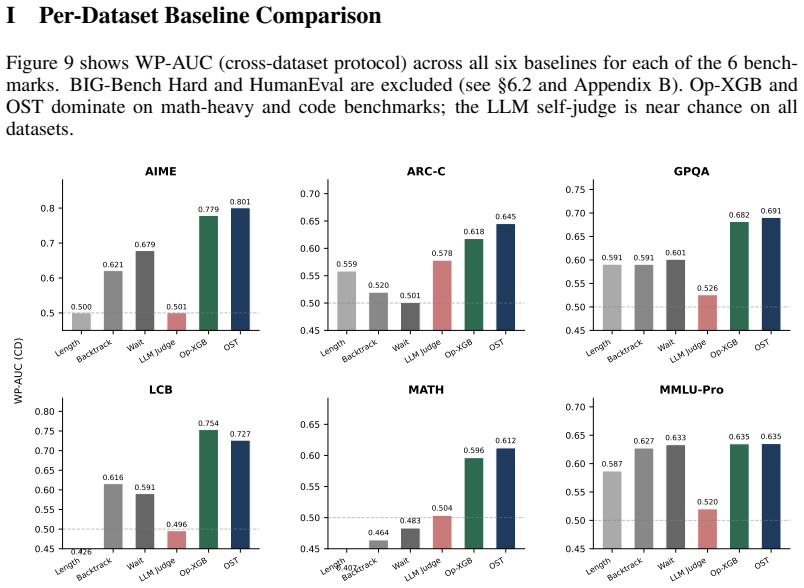
- Structural operator features predict within-problem answer correctness well above baselines.
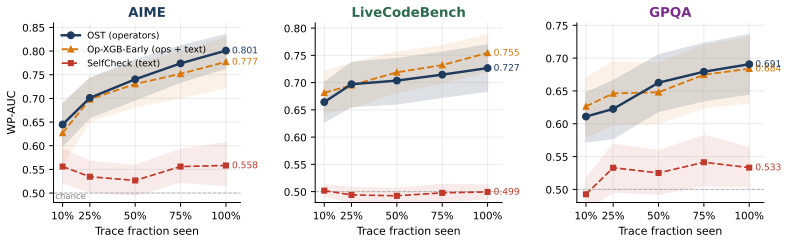
- Classifiers built on operators enable early quality estimation at only 50 percent of the trace length.
Where Pith is reading between the lines
- The same segmentation approach could be applied to human-written reasoning or to outputs from non-LLM systems to test for similar operator structure.
- Training objectives could be designed to encourage or suppress particular operators depending on problem difficulty.
- Model-specific operator fingerprints might be used to detect fine-tuning or distillation effects on reasoning style.
Load-bearing premise
Sentence-initial 3-token pivots are sufficient to capture meaningful, universal discourse-level reasoning operators that generalize across domains, models, and problem difficulties.
What would settle it
Clustering sentence-initial 3-token pivots on traces from new models or benchmarks yields clusters that do not align with the original seven operators, or LLM judges classify held-out samples into these operators at rates no better than chance.
Figures

read the original abstract
Chain-of-thought traces from large reasoning models can span tens of thousands of tokens, yet we lack a vocabulary for describing their internal structure. Previous methods developed to analyze chain-of-thought traces are either too rigid or not expressive enough, failing to capture features across domains and models. To remedy this, we develop ReasonOps, an unsupervised, expressive method for annotating chain-of-thought traces, providing succinct universal operators. Using ReasonOps, we analyze 44,662 traces from 12 thinking LLMs spanning 6 families across 8 reasoning benchmarks and discover that they share a common compositional structure: 7 recurring reasoning operators -- discourse-level moves such as backtracking, inferring, and hypothesizing -- that emerge from unsupervised clustering of sentence-initial 3-token pivots. These operators appear across every model family and benchmark domain, confirmed by three independent LLM judges who classify held-out samples at 70 -76% accuracy. We analyze the structure of operators on easy vs. hard problems, revealing that reflective operators are more helpful on hard problems and harm performance on easy problems. Operator sequences are highly model-identifying: a classifier trained on operator distributions alone recovers the source model with macro-AUC, revealing that each model family has a distinctive reasoning fingerprint. Structural operator features predict within-problem answer correctness well above baselines. Classifiers built on these operators reach WP-AUC and on AIME specifically. ReasonOps further enables early quality estimation well before the trace completes: we predict at WP-AUC for only 50% of the trace. The ReasonOps pipeline is unsupervised and annotation-free, enabling deep insights into LLM reasoning traces as well as strong downstream results on model identification and correctness prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReasonOps, an unsupervised pipeline that clusters sentence-initial 3-token pivots from 44,662 CoT traces across 12 LLMs and 8 benchmarks to discover 7 recurring discourse-level reasoning operators (e.g., backtracking, inferring). These operators are claimed to be universal across model families and domains, validated by three LLM judges at 70-76% accuracy on held-out samples, and shown to enable model identification (high macro-AUC from operator distributions), within-problem correctness prediction (WP-AUC), and early trace-quality estimation (WP-AUC at 50% trace length). Additional analyses contrast operator use on easy vs. hard problems.
Significance. If the 7 operators are shown to be stable, non-artifactual, and not dependent on the specific pivot choice, the work would supply a compact, annotation-free vocabulary for reasoning traces that generalizes across models and domains. The downstream results on model fingerprinting and predictive utility would then constitute a concrete advance in interpretability and diagnostic tooling for LLM reasoning.
major comments (3)
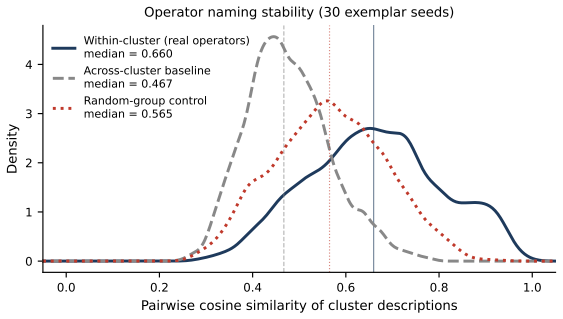
- [Abstract / Methods] Abstract and Methods: The central claim that exactly 7 universal operators emerge from unsupervised clustering of sentence-initial 3-token pivots lacks any reported details on cluster stability (e.g., adjusted Rand index across seeds or data subsets), the criterion used to select k=7, or ablation on pivot length/window position. Without these, it is impossible to assess whether the reported operators reflect functional reasoning moves or token co-occurrence patterns.
- [Abstract / Validation] Validation paragraph: The 70-76% LLM-judge accuracy on held-out samples is presented without inter-judge agreement statistics, a random or majority-class baseline, or confirmation that the judges were blinded to the clustering-derived labels. This leaves open the possibility that the accuracy merely reflects consistency with the pivot-derived taxonomy rather than independent recovery of meaningful operators.
- [Results / Downstream tasks] Downstream evaluation: The reported macro-AUC for model identification and WP-AUC for correctness prediction do not state whether operator discovery was performed on a disjoint subset from the evaluation traces. If the same traces contribute to both clustering and classifier training, the claimed generalization and fingerprinting results are at risk of leakage.
minor comments (1)
- [Abstract] The abstract contains truncated phrases ("reach WP-AUC and on AIME specifically") that should be completed for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on the manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the work.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The central claim that exactly 7 universal operators emerge from unsupervised clustering of sentence-initial 3-token pivots lacks any reported details on cluster stability (e.g., adjusted Rand index across seeds or data subsets), the criterion used to select k=7, or ablation on pivot length/window position. Without these, it is impossible to assess whether the reported operators reflect functional reasoning moves or token co-occurrence patterns.
Authors: We agree that the original submission omitted quantitative details on cluster stability, the selection criterion for k=7, and ablations on the pivot choice. These omissions make it difficult to fully evaluate the robustness of the discovered operators. In the revised manuscript, we will add a dedicated subsection in Methods reporting adjusted Rand index across multiple random seeds and data subsets, the specific criterion (e.g., elbow method combined with silhouette scores) used to select k=7, and an ablation study varying pivot length (2-4 tokens) and window position. This will allow readers to assess whether the operators capture functional reasoning moves. revision: yes
-
Referee: [Abstract / Validation] Validation paragraph: The 70-76% LLM-judge accuracy on held-out samples is presented without inter-judge agreement statistics, a random or majority-class baseline, or confirmation that the judges were blinded to the clustering-derived labels. This leaves open the possibility that the accuracy merely reflects consistency with the pivot-derived taxonomy rather than independent recovery of meaningful operators.
Authors: We acknowledge that the validation paragraph lacked inter-judge agreement metrics, baseline comparisons, and explicit blinding details. We will revise this section to report inter-judge agreement (e.g., Fleiss' kappa), performance relative to random (approximately 14%) and majority-class baselines, and confirmation that the three LLM judges received only the operator definitions and were blinded to the original clustering assignments when labeling held-out samples. These additions will clarify that the reported accuracy reflects meaningful recovery of the operators. revision: yes
-
Referee: [Results / Downstream tasks] Downstream evaluation: The reported macro-AUC for model identification and WP-AUC for correctness prediction do not state whether operator discovery was performed on a disjoint subset from the evaluation traces. If the same traces contribute to both clustering and classifier training, the claimed generalization and fingerprinting results are at risk of leakage.
Authors: This concern about potential leakage is valid, as the manuscript does not explicitly describe whether clustering and downstream evaluation used disjoint trace subsets. We will revise the Results and Methods sections to specify the data partitioning (e.g., clustering on a training subset with evaluation on held-out traces). If the original experiments did not enforce disjoint sets, we will re-run the model identification and correctness prediction tasks under proper splits and report whether the macro-AUC and WP-AUC results remain consistent. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation begins with unsupervised clustering on sentence-initial 3-token pivots to surface 7 operators, followed by independent LLM-judge validation on held-out samples and separate downstream predictive tasks (model identification, correctness prediction, early estimation). No quoted step reduces the operators to a self-definition, renames a fitted input as a prediction, or relies on a load-bearing self-citation chain. The approach remains data-driven and externally benchmarked, rendering the central claims self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sentence-initial 3-token pivots capture discourse-level reasoning moves in a domain- and model-independent way
Reference graph
Works this paper leans on
-
[2]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[4]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[6]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
2023
-
[7]
Melody Y Guan, Miles Wang, Micah Carroll, Zehao Dou, Annie Y Wei, Marcus Williams, Benjamin Arnav, Joost Huizinga, Ian Kivlichan, Mia Glaese, et al. Monitoring monitorability. arXiv preprint arXiv:2512.18311, 2025
-
[8]
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, et al. Chain of thought monitorability: A new and fragile opportunity for ai safety.arXiv preprint arXiv:2507.11473, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Measuring Progress on Scalable Oversight for Large Language Models
Samuel R Bowman, Jeeyoon Hyun, Ethan Perez, Edwin Chen, Craig Pettit, Scott Heiner, Kamil˙e Lukoši¯ut˙e, Amanda Askell, Andy Jones, Anna Chen, et al. Measuring progress on scalable oversight for large language models.arXiv preprint arXiv:2211.03540, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity.arXiv preprint arXiv:2506.06941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Reasoning models generate societies of thought.arXiv preprint arXiv:2601.10825, 2026
Junsol Kim, Shiyang Lai, Nino Scherrer, James Evans, et al. Reasoning models generate societies of thought.arXiv preprint arXiv:2601.10825, 2026
-
[12]
Demystifying long chain-of-thought reasoning
Shiming Yang, Yuxuan Tong, Xinyao Niu, Graham Neubig, and Xiang Yue. Demystifying long chain-of-thought reasoning. InForty-second International Conference on Machine Learning, 2025
2025
-
[13]
Understand- ing reasoning in thinking language models via steering vectors
Constantin Venhoff, Iván Arcuschin, Philip Torr, Arthur Conmy, and Neel Nanda. Understand- ing reasoning in thinking language models via steering vectors. InWorkshop on Reasoning and Planning for Large Language Models, 2025
2025
-
[14]
Reasoningflow: Semantic structure of complex reasoning traces.arXiv preprint arXiv:2506.02532, 2025
Jinu Lee, Sagnik Mukherjee, Dilek Hakkani-Tur, and Julia Hockenmaier. Reasoningflow: Semantic structure of complex reasoning traces.arXiv preprint arXiv:2506.02532, 2025. 10
-
[15]
Thought anchors: Which llm reasoning steps matter?arXiv preprint arXiv:2506.19143, 2025
Paul C Bogdan, Uzay Macar, Neel Nanda, and Arthur Conmy. Thought anchors: Which llm reasoning steps matter?arXiv preprint arXiv:2506.19143, 2025
-
[16]
Understanding the thinking process of reasoning models: A perspec- tive from schoenfeld’s episode theory
Ming Li, Nan Zhang, Chenrui Fan, Hong Jiao, Yanbin Fu, Sydney Peters, Qingshu Xu, Robert Lissitz, and Tianyi Zhou. Understanding the thinking process of reasoning models: A perspec- tive from schoenfeld’s episode theory. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18278–18299, 2025
2025
-
[17]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xinlong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Ma- jumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training.arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Priyanka Kargupta, Shuyue Stella Li, Haocheng Wang, Jinu Lee, Shan Chen, Orevaoghene Ahia, Dean Light, Thomas L Griffiths, Max Kleiman-Weiner, Jiawei Han, et al. Cognitive foundations for reasoning and their manifestation in llms.arXiv preprint arXiv:2511.16660, 2025
-
[19]
On scalable oversight with weak llms judging strong llms.Advances in Neural Information Processing Systems, 37:75229–75276, 2024
Zachary Kenton, Noah Y Siegel, János Kramár, Jonah Brown-Cohen, Samuel Albanie, Jannis Bulian, Rishabh Agarwal, David Lindner, Yunhao Tang, Noah D Goodman, et al. On scalable oversight with weak llms judging strong llms.Advances in Neural Information Processing Systems, 37:75229–75276, 2024
2024
-
[20]
Baek, Subhash Kantamneni, and Max Tegmark
Joshua Engels, David D. Baek, Subhash Kantamneni, and Max Tegmark. Scaling laws for scalable oversight. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[21]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faith- fulness in chain-of-thought reasoning.arXiv preprint arXiv:2307.13702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Making reasoning matter: Mea- suring and improving faithfulness of chain-of-thought reasoning
Debjit Paul, Robert West, Antoine Bosselut, and Boi Faltings. Making reasoning matter: Mea- suring and improving faithfulness of chain-of-thought reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15012–15032, 2024
2024
-
[23]
Selfcheck: Using llms to zero-shot check their own step-by-step reasoning
Ning Miao, Yee Whye Teh, and Tom Rainforth. Selfcheck: Using llms to zero-shot check their own step-by-step reasoning. InThe Twelfth International Conference on Learning Representa- tions (ICLR), 2024
2024
-
[24]
When Is Thinking Enough? Early Exit via Sufficiency Assessment for Efficient Reasoning
Yang Xiang, Yixin Ji, Ruotao Xu, Dan Qiao, Zheming Yang, Juntao Li, and Min Zhang. When is thinking enough? early exit via sufficiency assessment for efficient reasoning.arXiv preprint arXiv:2604.06787, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Ver- ifying chain-of-thought reasoning via its computational graph
Zheng Zhao, Yeskendir Koishekenov, Xianjun Yang, Naila Murray, and Nicola Cancedda. Ver- ifying chain-of-thought reasoning via its computational graph. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[26]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
Generative verifiers: Reward modeling as next-token prediction
Lunjun Zhang, Arian Hosseini, Hritik Bansal, Mehran Kazemi, Aviral Kumar, and Rishabh Agarwal. Generative verifiers: Reward modeling as next-token prediction. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[28]
V-STar: Training verifiers for self-taught reasoners
Arian Hosseini, Xingdi Yuan, Nikolay Malkin, Aaron Courville, Alessandro Sordoni, and Rishabh Agarwal. V-STar: Training verifiers for self-taught reasoners. InFirst Conference on Language Modeling, 2024
2024
-
[29]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024. 11
2024
-
[30]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reason- ing in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[31]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute op- timally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. NeurIPS, 2021
2021
-
[34]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. GPQA: A graduate-level google-proof Q&A benchmark.arXiv preprint arXiv:2311.12022, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contami- nation free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
2021
-
[37]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
2024
-
[38]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Challenging big-bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Compu- tational Linguistics: ACL 2023, pages 13003–13051, 2023
2023
-
[40]
Teaching large reasoning models effective reflection.arXiv preprint arXiv:2601.12720, 2026
Hanbin Wang, Jingwei Song, Jinpeng Li, Qi Zhu, Fei Mi, Ganqu Cui, Yasheng Wang, and Lifeng Shang. Teaching large reasoning models effective reflection.arXiv preprint arXiv:2601.12720, 2026
-
[41]
Liwei Kang, Yue Deng, Yao Xiao, Zhanfeng Mo, Wee Sun Lee, and Lidong Bing. First try matters: Revisiting the role of reflection in reasoning models.arXiv preprint arXiv:2510.08308, 2025
-
[42]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016. 12
2016
-
[43]
Guorui Zhou, Xiaoqiang Zhu, Chengru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1059–1068, 2018. 13 A Model Details Table 4 lists the 12 thinking models used ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.