Stochastic Lifting for Generating Trajectories of Stochastic Physical Systems
Pith reviewed 2026-06-29 08:46 UTC · model grok-4.3
The pith
Stochastic lifting attaches random labels to state transitions to train a regression model that generates diverse trajectories for stochastic physical systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
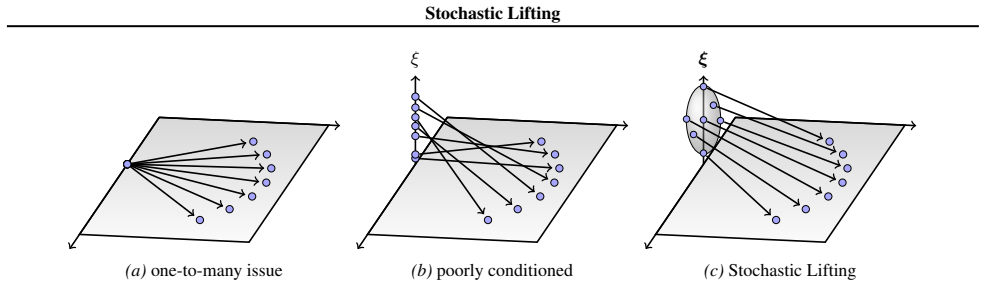
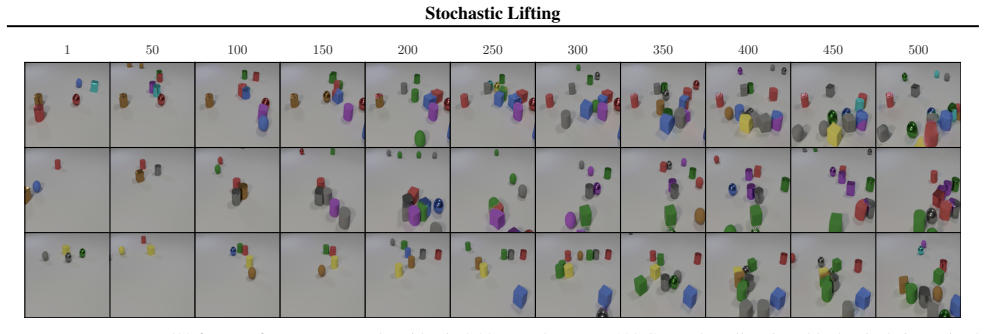
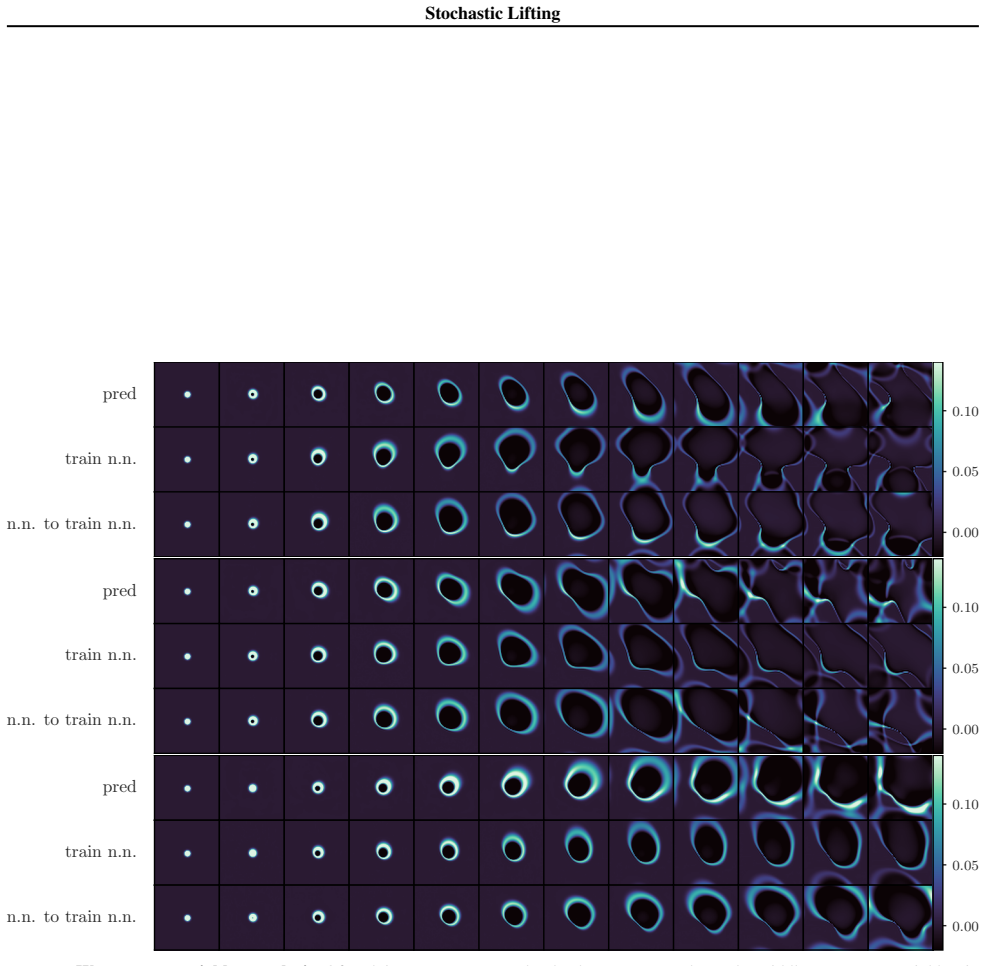
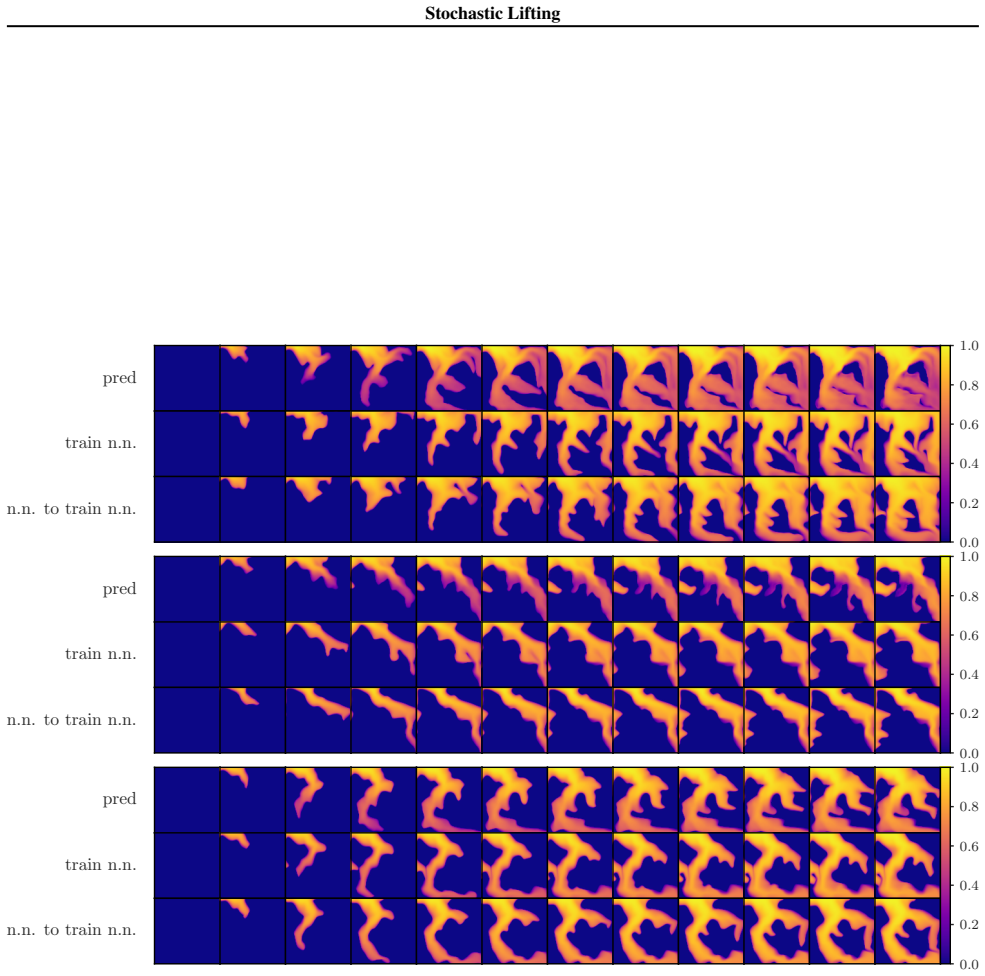
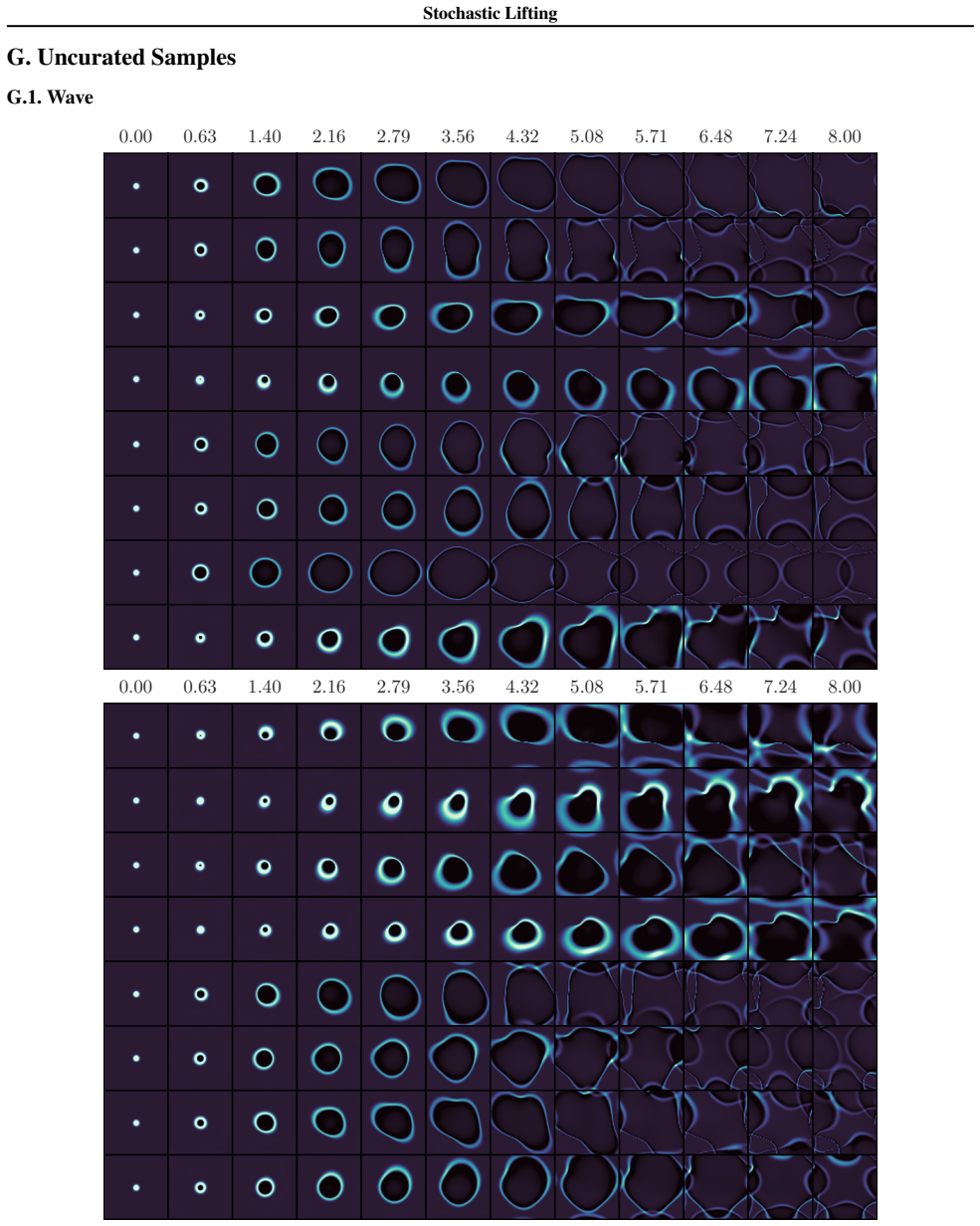
Stochastic Lifting exploits this structure by attaching an independent, high-dimensional random label to each state transition in the training data and fitting a transition map from the current state and label to the next state using a standard regression loss. The labels act as auxiliary coordinates that let the model represent multiple plausible next states from similar current states, avoiding collapse to a mean prediction in the finite-sample size regime. At inference, fresh labels are sampled at each time step and the learned map is rolled forward autoregressively, generating diverse trajectories with a single network evaluation per time step.
What carries the argument
Stochastic Lifting, the technique of augmenting training transitions with independent random labels to enable a regression-based transition map that captures stochasticity.
If this is right
- The method allows generating multiple plausible trajectories using only one forward pass of the network per time step.
- Standard regression losses suffice instead of specialized generative modeling objectives.
- The approach maintains diversity in predictions even with finite training data by using the labels as explicit randomness sources.
- Trajectories can be produced autoregressively by resampling labels at each step.
Where Pith is reading between the lines
- This technique might extend naturally to reinforcement learning environments with stochastic transitions.
- Similar label-augmentation ideas could improve uncertainty estimation in other time-series forecasting tasks.
- Testing on systems where the smooth-map-plus-randomness assumption holds weakly would reveal the method's robustness limits.
Load-bearing premise
The transition from current state to the next state can often be modeled as the combination of a smooth map and an explicit source of randomness.
What would settle it
Observing that different random labels produce identical or nearly identical next-state predictions for the same input state would indicate the method does not capture the intended stochastic variability.
Figures

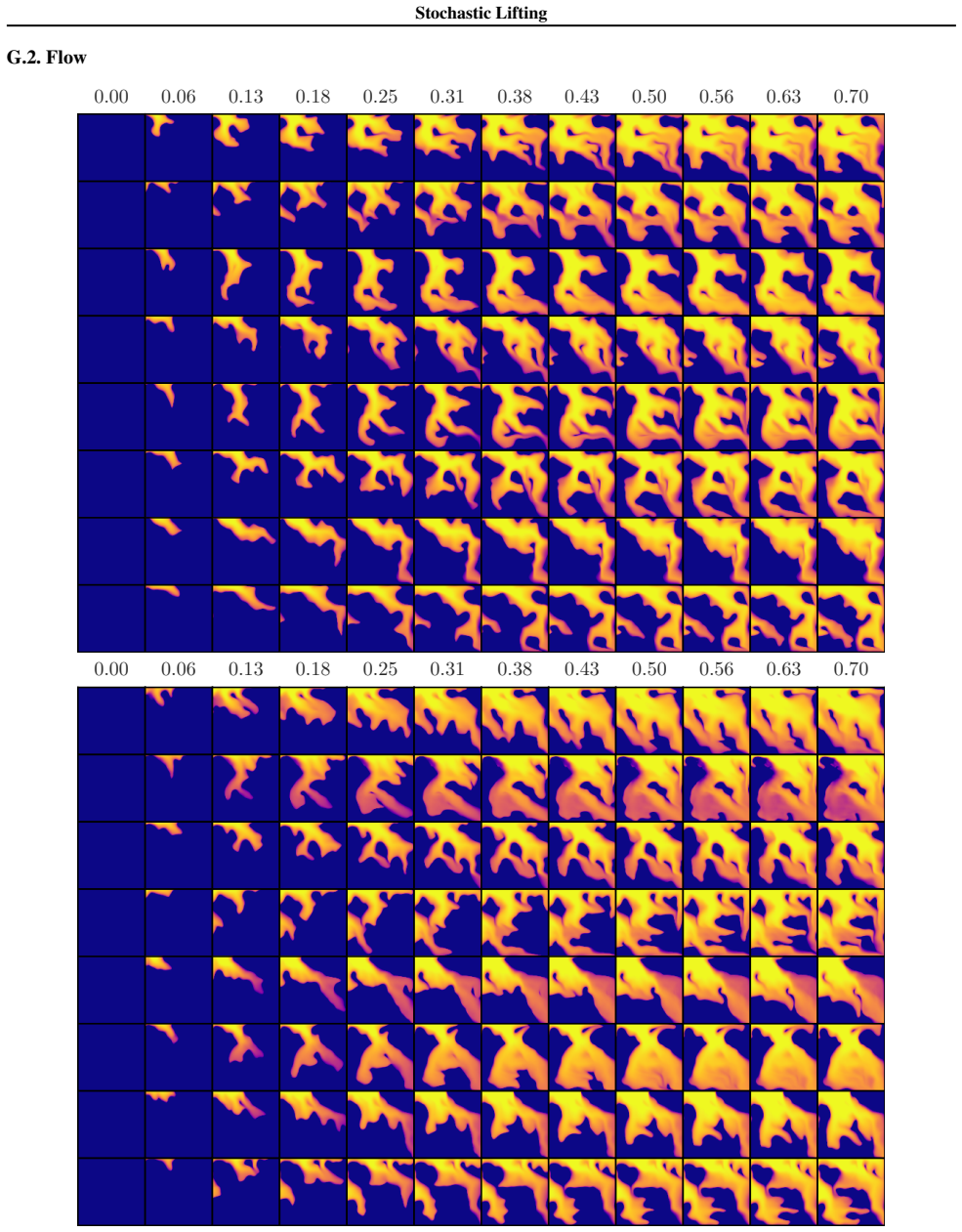
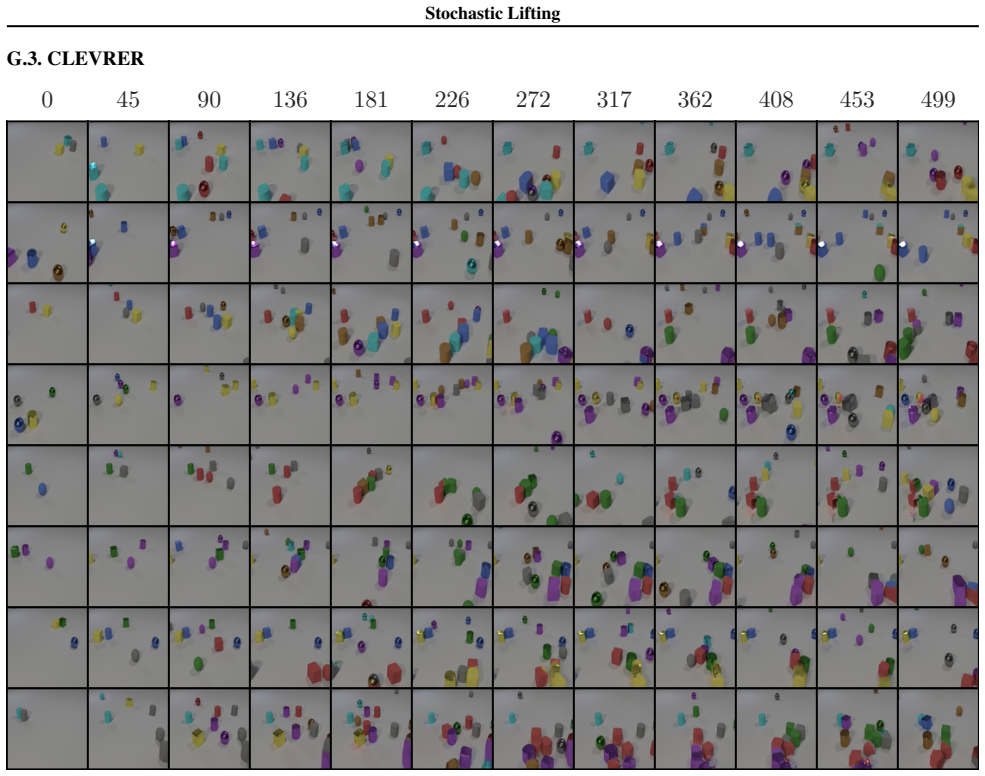
read the original abstract
Many stochastic physical systems evolve smoothly over time in the sense that the distribution of states changes regularly across time steps. The transition from current state to the next state can often be modeled as the combination of a smooth map and an explicit source of randomness. Stochastic Lifting exploits this structure by attaching an independent, high-dimensional random label to each state transition in the training data and fitting a transition map from the current state and label to the next state using a standard regression loss. The labels act as auxiliary coordinates that let the model represent multiple plausible next states from similar current states, avoiding collapse to a mean prediction in the finite-sample size regime. At inference, fresh labels are sampled at each time step and the learned map is rolled forward autoregressively, generating diverse trajectories with a single network evaluation per time step.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Stochastic Lifting for generating trajectories of stochastic physical systems. It attaches an independent high-dimensional random label to each state transition in the training data and fits a deterministic transition map from (current state, label) to next state via standard regression loss. The labels act as auxiliary coordinates to represent multiple plausible next states from similar inputs, avoiding mean collapse in the finite-sample regime. At inference, fresh labels are sampled at each step and the map is rolled out autoregressively to produce diverse trajectories with one network evaluation per time step.
Significance. If the learned map generalizes correctly from training labels to fresh inference labels while reproducing the true conditional distribution, the approach would offer a lightweight alternative to mean-collapse issues in trajectory modeling, using only regression and a single network. This could be useful for efficient simulation of stochastic physical dynamics where explicit randomness can be injected via auxiliary coordinates.
major comments (1)
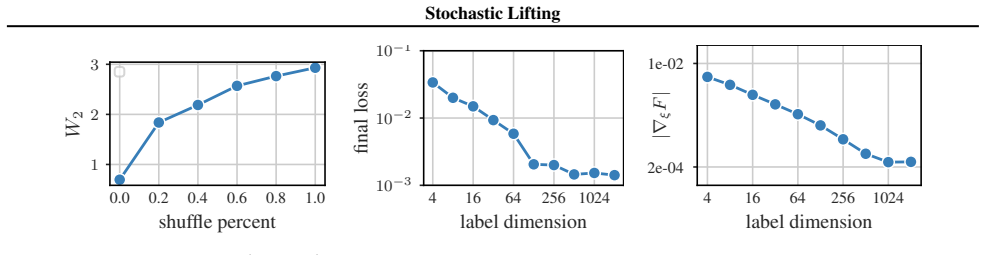
- [Abstract] Abstract / central construction: the claim that sampling fresh labels at inference produces trajectories whose distribution matches the true conditional relies on the regression optimization discovering a label-to-variation mapping that generalizes beyond the training set. With only a standard regression loss and no explicit structure or regularization on the label space, the network can instead treat each training label as an identifier for its paired next state, yielding outputs for new labels that lie outside the support of the data distribution. This is load-bearing for the method and requires either a theoretical argument or empirical demonstration that the mapping generalizes as intended.
minor comments (2)
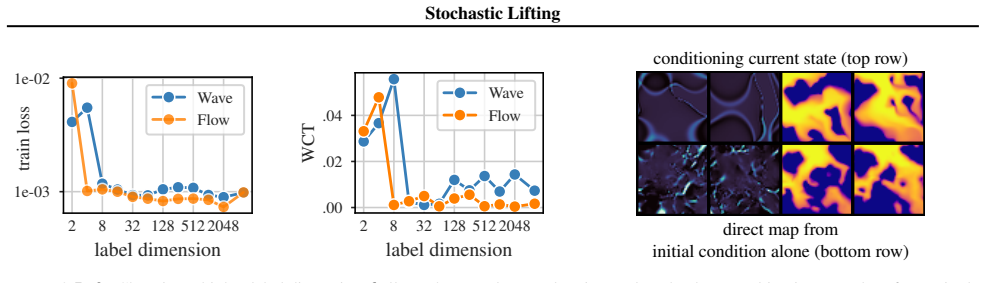
- The abstract does not specify the dimension chosen for the random labels, the sampling distribution used for both training and inference labels, or any ablation on these choices.
- No information is given on the network architecture, training procedure details, or how autoregressive rollout is stabilized in practice.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of major revision. We respond to the single major comment below, focusing on the generalization of the learned mapping.
read point-by-point responses
-
Referee: [Abstract] Abstract / central construction: the claim that sampling fresh labels at inference produces trajectories whose distribution matches the true conditional relies on the regression optimization discovering a label-to-variation mapping that generalizes beyond the training set. With only a standard regression loss and no explicit structure or regularization on the label space, the network can instead treat each training label as an identifier for its paired next state, yielding outputs for new labels that lie outside the support of the data distribution. This is load-bearing for the method and requires either a theoretical argument or empirical demonstration that the mapping generalizes as intended.
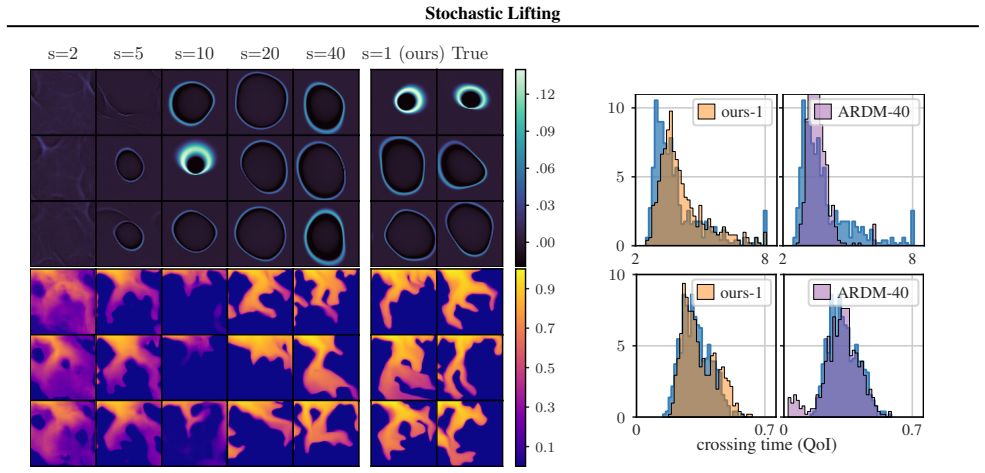
Authors: We agree that generalization from training labels to fresh inference labels is essential for the method. The manuscript provides empirical demonstration rather than a theoretical argument: Section 4 reports results on several stochastic physical systems (e.g., stochastic Lorenz, double pendulum with noise) where trajectories generated by sampling new labels at each step reproduce the correct conditional statistics, as quantified by moment matching, distribution distances, and qualitative trajectory diversity. These outcomes indicate that the network learns an interpolating map over the label space instead of treating labels as unique identifiers. The high dimensionality of the labels combined with the smoothness assumption on the underlying dynamics appears sufficient in practice to avoid out-of-support outputs. We do not claim a general theoretical guarantee and acknowledge that stronger regularization or analysis could be added in future work. revision: no
Circularity Check
Method presented as explicit algorithmic construction with no reduction to inputs
full rationale
The paper defines Stochastic Lifting directly as the procedure of attaching independent random labels to each training transition, fitting a deterministic regression map from (state, label) to next state, and sampling fresh labels at inference. No equations, theorems, or claims in the provided text reduce the generated distribution to a fitted parameter by construction, invoke self-citations as load-bearing uniqueness results, or rename known patterns. The central claim is the proposal of this augmentation technique itself, which is self-contained and does not rely on prior results from the same authors to justify its validity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The transition from current state to the next state can often be modeled as the combination of a smooth map and an explicit source of randomness.
Reference graph
Works this paper leans on
-
[1]
Arjovsky, M., Chintala, S., and Bottou, L
URL https://openreview.net/forum? id=li7qeBbCR1t. Arjovsky, M., Chintala, S., and Bottou, L. Wasserstein gen- erative adversarial networks. InInternational conference on machine learning, pp. 214–223. PMLR, 2017. Babaeizadeh, M., Finn, C., Erhan, D., Campbell, R. H., and Levine, S. Stochastic variational video prediction. In International Conference on Le...
2017
-
[2]
URL https://openreview.net/forum? id=rk49Mg-CW. Babaeizadeh, M., Saffar, M. T., Nair, S., Levine, S., Finn, C., and Erhan, D. Fitvid: Overfitting in pixel-level video prediction.arXiv preprint arXiv:2106.13195, 2021. Bao, F., Nie, S., Xue, K., Cao, Y ., Li, C., Su, H., and Zhu, J. All are worth words: A vit backbone for diffusion models. InProceedings of ...
-
[3]
arXiv preprint arXiv:1907.06571 (2019) 3
URL https://openreview.net/forum? id=Di5apl8HSH. Carreira, J. and Zisserman, A. Quo vadis, action recogni- tion? a new model and the kinetics dataset. Inproceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6299–6308, 2017. Chen, Y ., Goldstein, M., Hua, M., Albergo, M. S., Boffi, N. M., and Vanden-Eijnden, E. Probabilistic ...
-
[4]
doi: 10.1007/BF00994018. URL https://doi. org/10.1007/BF00994018. Davtyan, A., Sameni, S., and Favaro, P. Efficient video prediction via sparsely conditioned flow matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 23263–23274, 2023. Dupont, E., Doucet, A., and Teh, Y . W. Augmented neural odes.Advances in neural info...
-
[5]
One Step Diffusion via Shortcut Models
URL https://proceedings.mlr.press/ v78/frederik-ebert17a.html. Federer, H.Geometric Measure Theory. Springer, 1996. Frans, K., Hafner, D., Levine, S., and Abbeel, P. One step diffusion via shortcut models.arXiv preprint arXiv:2410.12557, 2024. Garnelo, M., Rosenbaum, D., Maddison, C., Ramalho, T., Saxton, D., Shanahan, M., Teh, Y . W., Rezende, 10 Stochas...
work page internal anchor Pith review Pith/arXiv arXiv 1996
-
[6]
cc/paper_files/paper/2014/file/ f033ed80deb0234979a61f95710dbe25-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2014/file/ f033ed80deb0234979a61f95710dbe25-Paper. pdf. Gu, C. QLMOR: A projection-based nonlinear model order reduction approach using quadratic-linear representation of nonlinear systems.IEEE Transactions on Computer- Aided Design of Integrated Circuits and Systems, 30(9): 1307–1320, 2011. Hastie, T....
2014
-
[7]
doi: 10.1214/21-AOS2133. URL https://doi. org/10.1214/21-AOS2133. Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 6840–6851. Curran Associates, Inc.,
-
[8]
Kidger, On neural differential equations, arXiv preprint (2022).doi:10.48550/arXiv.2202.02435
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ 4c5bcfec8584af0d967f1ab10179ca4b-Paper. pdf. Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., and Fleet, D. J. Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022. Hoogeboom, E., Gritsenko, A. A., Bastings, J., Poole, B., van den Berg, R., ...
-
[9]
Lipman, Y ., Chen, R
OpenReview.net, 2021. Lipman, Y ., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Represen- tations, 2023. URL https://openreview.net/ forum?id=PqvMRDCJT9t. Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rect...
2021
-
[10]
Lu, L., Jin, P., Pang, G., Zhang, Z., and Karni- adakis, G
URL https://openreview.net/forum? id=XVjTT1nw5z. Lu, L., Jin, P., Pang, G., Zhang, Z., and Karni- adakis, G. E. Learning nonlinear operators via deep- onet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3(3):218– 229, Mar 2021. ISSN 2522-5839. doi: 10.1038/ s42256-021-00302-5. URL https://doi.org/10. 1038/s42256-021...
-
[11]
cc/paper_files/paper/2007/file/ 013a006f03dbc5392effeb8f18fda755-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2007/file/ 013a006f03dbc5392effeb8f18fda755-Paper. pdf. Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with la- tent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 10674–10685, 2022. Ron...
2007
-
[12]
R¨uhling Cachay, S., Zhao, B., Joren, H., and Yu, R
URL https://proceedings.mlr.press/ v235/ruhe24a.html. R¨uhling Cachay, S., Zhao, B., Joren, H., and Yu, R. Dyf- fusion: A dynamics-informed diffusion model for spa- tiotemporal forecasting.Advances in neural information processing systems, 36:45259–45287, 2023. Sato, H., Fehler, M. C., and Maeda, T.Seismic Wave Propagation and Scattering in the Heterogene...
-
[13]
Springer-Verlag. ISBN 978-3-031-73015-3. doi: 10.1007/978-3-031-73016-0 6. URL https://doi. org/10.1007/978-3-031-73016-0_6. Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequi- librium thermodynamics. In Bach, F. and Blei, D. (eds.), Proceedings of the 32nd International Conference on Ma- chine Lea...
-
[14]
cc/paper_files/paper/2019/file/ 3001ef257407d5a371a96dcd947c7d93-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ 3001ef257407d5a371a96dcd947c7d93-Paper. pdf. Song, Y ., Garg, S., Shi, J., and Ermon, S. Sliced score matching: A scalable approach to density and score estimation. InProceedings of the Thirty-Fifth Conference on Uncertainty in Artificial Intelligence, UAI 2019, Tel Aviv, Israel, July 22-25,...
2019
-
[15]
Towards Accurate Generative Models of Video: A New Metric & Challenges
URL https://openreview.net/forum? id=PxTIG12RRHS. Song, Y ., Dhariwal, P., Chen, M., and Sutskever, I. Con- sistency models.International conference on machine learning, 2023. Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., and Gelly, S. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arX...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
doi: 10.3150/18-BEJ1065. Wu, C., Liang, J., Ji, L., Yang, F., Fang, Y ., Jiang, D., and Duan, N. N ¨uwa: Visual synthesis pre-training for neural visual world creation. InEuropean conference on computer vision, pp. 720–736. Springer, 2022. Yi, K., Gan, C., Li, Y ., Kohli, P., Wu, J., Torralba, A., and Tenenbaum, J. B. Clevrer: Collision events for video r...
-
[17]
This normalization prevents the network’s predictions from diverging during rollout, making it particularly suitable for video data, which naturally lies within[0,1]
with a perceptual-based LPIPS loss (Zhang et al., 2018) which we find improves FVD scores. This normalization prevents the network’s predictions from diverging during rollout, making it particularly suitable for video data, which naturally lies within[0,1]. 22 Stochastic Lifting Table 3.Hyper-parameters used for each dataset. Wave Flow BAIR CLEVRER Batch ...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.