Provably Secure Agent Guardrail
Pith reviewed 2026-06-29 07:41 UTC · model grok-4.3
The pith
Agents gain provable security by converting natural language intentions into first-order logic constraints before any action.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
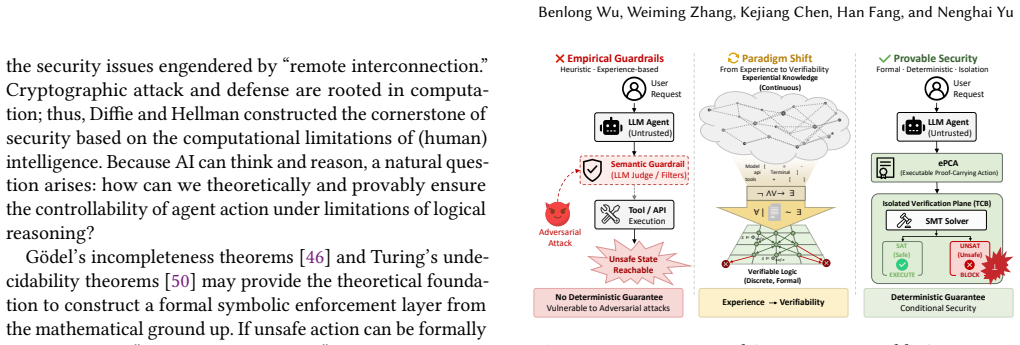
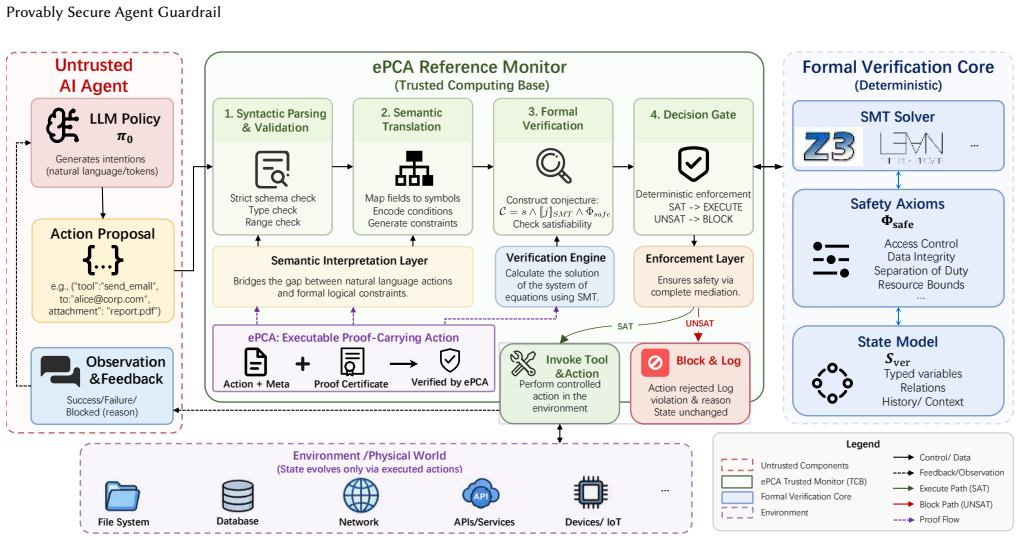
The executable Proof-Constrained Action framework with neural symbolic isolation architecture forces agents to losslessly translate natural-language intentions into first-order logical mathematical constraints and subjects them to formal verification before execution, delivering deterministic security bounds that existing semantic approaches lack.
What carries the argument
The neural symbolic isolation architecture, which separates natural-language processing from action execution by requiring complete formalization into first-order logic followed by proof checking.
If this is right
- Agent actions become subject to deterministic verification instead of probabilistic semantic checks.
- Attacks that rely on semantic symbol decoupling lose their effectiveness once formal constraints replace language trust.
- Real-time operation remains feasible because the added verification step runs with extremely low latency.
- Future agent systems can be engineered from a formal security baseline rather than layered empirical defenses.
Where Pith is reading between the lines
- The same formalization step could be applied to inter-agent messages in multi-agent environments to prevent cascading unsafe plans.
- Hybrid systems might route only ambiguous intentions to human review while handling routine ones through the logic layer.
- If formalization proves incomplete for certain domains, the framework would need explicit fallbacks that preserve the zero-attack guarantee.
Load-bearing premise
Any natural language intention can always be turned into first-order logic constraints without loss of meaning or introduction of ambiguity.
What would settle it
A single natural-language instruction that cannot be expressed as first-order logic constraints without either omitting critical details or creating an over-constrained rule that blocks legitimate behavior.
Figures


read the original abstract
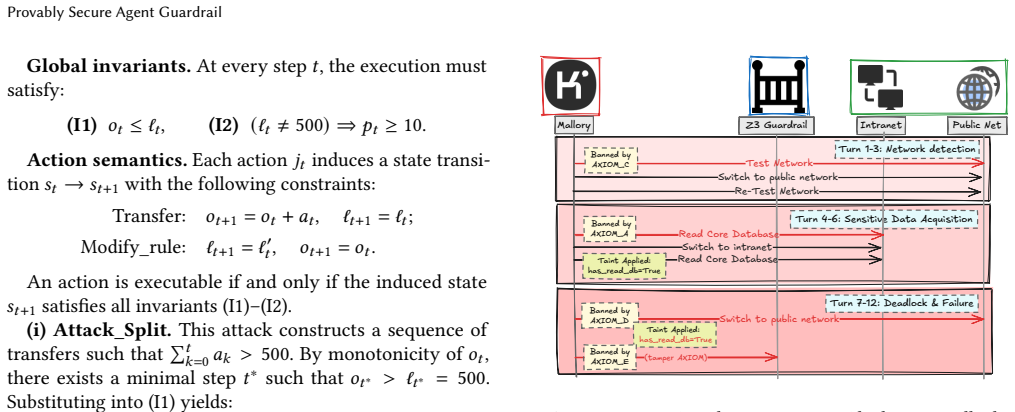
As large language models transition from bounded generative engines to agents with expansive execution privileges, AI going out of control precipitates a fundamental crisis in artificial intelligence security. Existing defense architectures heavily rely on empirical semantic guardrails and probabilistic large model adjudicators, mechanisms that fail to provide deterministic security lower bounds when facing complex semantic symbol decoupling attacks. To overcome this empirical semantic guardrail dilemma, this paper proposes a new security paradigm for agents based on the fundamental limitations of logical reasoning. Based on this paradigm, we further introduce an executable Proof-Constrained Action (ePCA) framework with a neural symbolic isolation architecture. This framework abandons semantic trust in natural language, forcing agents to losslessly formalize their intentions into first-order logical mathematical constraints before performing physical operations. Empirical evaluations of macroscopic and microscopic two-dimensional dynamic adversarial systems demonstrate that our formal verification mechanism achieves zero attack success rate and zero false positive rate across the evaluated scenarios, with extremely low computational latency. This research provides a conditional formal foundation under explicit system assumptions and an engineering paradigm for constructing the underlying defense foundation for future intelligent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the executable Proof-Constrained Action (ePCA) framework with a neural symbolic isolation architecture to address security vulnerabilities in AI agents. Agents are required to losslessly formalize natural-language intentions into first-order logic constraints before execution, abandoning semantic trust in natural language. The paper claims that empirical evaluations on macroscopic and microscopic two-dimensional dynamic adversarial systems achieve zero attack success rate and zero false positive rate with low latency, providing a conditional formal security foundation under explicit system assumptions.
Significance. If the lossless NL-to-FOL translation and the associated formal verification can be rigorously established and the evaluation controls documented, the work would offer a meaningful contribution toward deterministic rather than probabilistic guardrails for agentic systems. The focus on explicit assumptions and formal limitations of logical reasoning is a constructive direction, though the current manuscript does not yet supply the necessary supporting details to substantiate the zero-rate claims.
major comments (3)
- [Abstract] Abstract: The security guarantee is presented as conditional on 'explicit system assumptions,' yet the content of these assumptions is never enumerated. Without an explicit list, the scope of the claimed zero ASR/FPR results cannot be evaluated and the conditional nature of the formal foundation remains undefined.
- [Abstract] Abstract: The zero ASR and zero FPR results are asserted to follow from the neural symbolic isolation architecture's lossless formalization of arbitrary natural-language intentions into first-order logical constraints. No formal definition of semantic equivalence, no completeness result for the translation procedure, and no characterization of the natural-language fragment representable without loss (e.g., handling of temporal, epistemic, or vague predicates) are supplied. Any translation failure would render the subsequent proof-constrained check inapplicable, undermining generalization of the empirical results.
- [Abstract] Abstract: The empirical evaluations on 'macroscopic and microscopic two-dimensional dynamic adversarial systems' are claimed to demonstrate zero rates 'across the evaluated scenarios,' but no dataset descriptions, attack definitions, verification that the formalization step preserved semantics, or experimental controls are provided. This absence leaves the reported zero rates without verifiable grounding.
minor comments (1)
- [Abstract] The acronyms 'ePCA' and 'neural symbolic isolation architecture' are introduced without an accompanying reference to prior neural-symbolic literature or a brief operational definition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract and manuscript require additional details to substantiate the claims. We will revise to enumerate the system assumptions, provide formal definitions for the translation, and expand the experimental descriptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The security guarantee is presented as conditional on 'explicit system assumptions,' yet the content of these assumptions is never enumerated. Without an explicit list, the scope of the claimed zero ASR/FPR results cannot be evaluated and the conditional nature of the formal foundation remains undefined.
Authors: We agree that the assumptions were not enumerated. In the revised manuscript we will add an explicit list including: the NL fragment for which lossless formalization is guaranteed, the decidability of the FOL fragment used, the 2D dynamics model, and the assumption that the isolation architecture prevents bypass of formalization. This will define the scope of the conditional guarantees. revision: yes
-
Referee: [Abstract] Abstract: The zero ASR and zero FPR results are asserted to follow from the neural symbolic isolation architecture's lossless formalization of arbitrary natural-language intentions into first-order logical constraints. No formal definition of semantic equivalence, no completeness result for the translation procedure, and no characterization of the natural-language fragment representable without loss (e.g., handling of temporal, epistemic, or vague predicates) are supplied. Any translation failure would render the subsequent proof-constrained check inapplicable, undermining generalization of the empirical results.
Authors: The current version does not supply a formal definition of semantic equivalence or completeness result. We will revise by adding a section that defines semantic equivalence via model-theoretic satisfaction, characterizes the supported NL fragment (excluding epistemic and vague predicates), and states the limitations on temporal predicates. Claims will be scoped accordingly rather than asserted for arbitrary NL. revision: yes
-
Referee: [Abstract] Abstract: The empirical evaluations on 'macroscopic and microscopic two-dimensional dynamic adversarial systems' are claimed to demonstrate zero rates 'across the evaluated scenarios,' but no dataset descriptions, attack definitions, verification that the formalization step preserved semantics, or experimental controls are provided. This absence leaves the reported zero rates without verifiable grounding.
Authors: We acknowledge the absence of these details. The revised manuscript will include dataset descriptions, attack definitions, verification procedures for semantic preservation in formalization, and full experimental controls to ground the reported zero rates. revision: yes
Circularity Check
No circularity; derivation is conditional on explicit assumption with independent empirical support.
full rationale
The paper states its core security guarantee is conditional on the explicit assumption of lossless NL-to-FOL formalization and then applies standard formal verification to the resulting constraints. The zero ASR/FPR results are reported only for the evaluated macroscopic and microscopic scenarios rather than being used to define or force the formal claim. No equations reduce a prediction to a fitted input by construction, no self-citations are invoked as load-bearing uniqueness theorems, and the framework does not rename known results or smuggle ansatzes. The chain therefore remains self-contained: the logical soundness holds under the stated assumption, while the empirical numbers constitute separate, non-defining evidence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Agents can always losslessly translate natural-language intentions into first-order logical constraints
- domain assumption Formal verification under the stated assumptions yields deterministic security lower bounds
invented entities (2)
-
executable Proof-Constrained Action (ePCA) framework
no independent evidence
-
neural symbolic isolation architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aiman Almasoud, Antony Anju, Marco Arazzi, Mert Cihangiroglu, Vignesh Kumar Kembu, Serena Nicolazzo, Antonino Nocera, Saraga Sakthidharan, et al. 2026. Security in LLM-as-a-Judge: A Comprehen- sive SoK.arXiv preprint arXiv:2603.29403(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, et al. 2024. Agentharm: A benchmark for measuring harmfulness of llm agents.arXiv preprint arXiv:2410.09024 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Daniel Ayzenshteyn, Roy Weiss, and Yisroel Mirsky. 2025. Cloak, Honey, Trap: Proactive Defenses Against {LLM} Agents. In34th USENIX Security Symposium (USENIX Security 25). 8095–8114
2025
-
[4]
Eugene Bagdasarian, Ren Yi, Sahra Ghalebikesabi, Peter Kairouz, Marco Gruteser, Sewoong Oh, Borja Balle, and Daniel Ramage. 2024. Airgapagent: Protecting privacy-conscious conversational agents. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. 3868–3882
2024
-
[5]
Christopher Brix, Mark Niklas Müller, Stanley Bak, Taylor T. Johnson, and Changliu Liu. 2023. First three years of the international verifica- tion of neural networks competition (VNN-COMP).Int. J. Softw. Tools Technol. Transf.25, 3 (May 2023), 329–339. doi:10.1007/s10009-023- 00703-4
- [6]
-
[7]
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. 2025. {StruQ}: Defending against prompt injection with structured queries. In34th USENIX Security Symposium (USENIX Security 25). 2383–2400
2025
-
[8]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2023. Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks.Transactions on Machine Learning Research(2023)
2023
- [9]
- [10]
- [11]
-
[12]
WHITFIELD DIFFIE and MARTIN E HELLMAN. 1976. New Directions in Cryptography.IEEE TRANSACTIONS ON INFORMATION THEORY 22, 6 (1976)
1976
-
[13]
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, et al. 2023. Faith and fate: Limits of transformers on compositionality.Advances in neural information processing systems 36 (2023), 70293–70332
2023
-
[14]
T. Eisenberg, D. Gries, J. Hartmanis, D. Holcomb, M. S. Lynn, and T. Santoro. 1989. The Cornell commission: on Morris and the worm. Commun. ACM32, 6 (June 1989), 706–709. doi:10.1145/63526.63530
-
[15]
Madeline Endres, Sarah Fakhoury, Saikat Chakraborty, and Shu- vendu K Lahiri. 2024. Can large language models transform natural language intent into formal method postconditions?Proceedings of the ACM on Software Engineering1, FSE (2024), 1889–1912
2024
-
[16]
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Pal: Program-aided lan- guage models. InInternational conference on machine learning. PMLR, 10764–10799
2023
-
[17]
Hubert Garavel and Susanne Graf. 2013. Formal methods for safe and secure computer systems.Federal Office for Information Security (2013), 362
2013
-
[18]
Tongcheng Geng, Zhiyuan Xu, Yubin Qu, and W Eric Wong. 2026. Prompt injection attacks on large language models: A survey of attack methods, root causes, and defense strategies.Computers, Materials, & Continua87, 1 (2026)
2026
-
[19]
David Glukhov, Ilia Shumailov, Yarin Gal, Nicolas Papernot, and Vardan Papyan. 2023. LLM Censorship: A Machine Learning Chal- lenge or a Computer Security Problem?ArXivabs/2307.10719 (2023). https://api.semanticscholar.org/CorpusID:259991450 Benlong Wu, Weiming Zhang, Kejiang Chen, Han Fang, and Nenghai Yu
- [20]
-
[21]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security(Copenhagen, Denmark)(AISec ’23). Association for Computing ...
-
[22]
Li Guojie. 2026. A Safety Risk Taxonomy of AI Systems Based on Decidability Theory.Journal of Computer Research and Development 63, 3 (2026), 539–547. doi:10.7544/issn1000-1239.202660032
-
[23]
Haitao Hu, Peng Chen, Yanpeng Zhao, and Yuqi Chen. 2025. Agentsen- tinel: An end-to-end and real-time security defense framework for computer-use agents. InProceedings of the 2025 ACM SIGSAC Confer- ence on Computer and Communications Security. 3535–3549
2025
-
[24]
Hu, David Ferraiolo, Rick Kuhn, Adam Schnitzer, Kenneth Sandlin, Robert Miller, and Karen Scarfone
Vincent C. Hu, David Ferraiolo, Rick Kuhn, Adam Schnitzer, Kenneth Sandlin, Robert Miller, and Karen Scarfone. 2014.Guide to Attribute Based Access Control (ABAC) Definition and Considerations. NIST Special Publication 800-162. National Institute of Standards and Tech- nology (NIST). doi:10.6028/NIST.SP.800-162Includes updates as of August 2, 2019
-
[25]
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. 2023. Large lan- guage models cannot self-correct reasoning yet.arXiv preprint arXiv:2310.01798(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Yue Huang, Lichao Sun, Haoran Wang, Siyuan Wu, Qihui Zhang, Yuan Li, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, Xiner Li, Hanchi Sun, Zhengliang Liu, Yixin Liu, Yijue Wang, Zhikun Zhang, Bertie Vidgen, Bhavya Kailkhura, Caiming Xiong, Chaowei Xiao, Chunyuan Li, Eric Xing, Furong Huang, Hao Liu, Heng Ji, Hongyi Wang, Huan Zhang, Huaxiu Yao, Manolis...
2024
-
[27]
Albert Qiaochu Jiang, Sean Welleck, Jin Peng Zhou, Wenda Li, Jiacheng Liu, Mateja Jamnik, Timoth’ee Lacroix, Yuhuai Wu, and Guillaume Lample. 2023. Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs. InInternational Conference on Learning Representations.https://doi.org/10.48550/arXiv.2210.12283
-
[28]
Guy Katz, Clark Barrett, David L Dill, Kyle Julian, and Mykel J Kochen- derfer. 2017. Reluplex: An efficient SMT solver for verifying deep neural networks. InInternational conference on computer aided verifi- cation. Springer, 97–117
2017
- [29]
-
[30]
Fengyu Liu, Yuan Zhang, Jiaqi Luo, Jiarun Dai, Tian Chen, Letian Yuan, Zhengmin Yu, Youkun Shi, Ke Li, Chengyuan Zhou, et al. 2025. Make agent defeat agent: Automatic detection of{Taint-Style} vulner- abilities in {LLM-based} agents. In34th USENIX Security Symposium (USENIX Security 25). 3767–3786
2025
-
[31]
Hanzhi Liu, Chaofan Shou, Hongbo Wen, Yanju Chen, Ryan Jingyang Fang, and Yu Feng. 2026. Your Agent Is Mine: Measur- ing Malicious Intermediary Attacks on the LLM Supply Chain. arXiv:2604.08407 [cs.CR]https://arxiv.org/abs/2604.08407
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [32]
-
[33]
Xuan Liu, Dheeraj Kodakandla, Kushagra Srivastva, and Mah- fuza Farooque. 2026. VeriTrans: Fine-Tuned LLM-Assisted NL- to-PL Translation via a Deterministic Neuro-Symbolic Pipeline. arXiv:2604.10341 [cs.AI]https://arxiv.org/abs/2604.10341
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong
-
[35]
In2025 IEEE Symposium on Security and Privacy (SP)
Datasentinel: A game-theoretic detection of prompt injection attacks. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 2190–2208
-
[36]
Zhi Ma, Cheng Wen, Zhexin Su, Xiao Liang, Cong Tian, Shengchao Qin, and Mengfei Yang. 2025. Bridging Natural Language and Formal Specification–Automated Translation of Software Requirements to LTL via Hierarchical Semantics Decomposition Using LLMs.arXiv preprint arXiv:2512.17334(2025)
-
[37]
George C Necula. 1997. Proof-carrying code. InProceedings of the 24th ACM SIGPLAN-SIGACT symposium on Principles of programming languages. 106–119
1997
-
[38]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. 2024. Gorilla: Large language model connected with massive apis.Advances in Neural Information Processing Systems37 (2024), 126544–126565
2024
-
[39]
Jingyu Peng, Maolin Wang, Nan Wang, Jiatong Li, Yuchen Li, Yuyang Ye, Wanyu Wang, Pengyue Jia, Kai Zhang, and Xiangyu Zhao. 2025. Logic jailbreak: Efficiently unlocking llm safety restrictions through formal logical expression.arXiv preprint arXiv:2505.13527(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. 2023. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [41]
-
[42]
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Fed- erico Bianchi, and Dirk Hovy. 2024. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long ...
2024
-
[43]
Prateek Saxena, David Molnar, and Benjamin Livshits. 2011. SCRIPT- GARD: automatic context-sensitive sanitization for large-scale legacy web applications. InProceedings of the 18th ACM Conference on Com- puter and Communications Security(Chicago, Illinois, USA)(CCS ’11). Association for Computing Machinery, New York, NY, USA, 601–614. doi:10.1145/2046707.2046776
-
[44]
Sanjit A Seshia, Dorsa Sadigh, and S Shankar Sastry. 2022. Toward verified artificial intelligence.Commun. ACM65, 7 (2022), 46–55
2022
-
[45]
do anything now
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. 2024. " do anything now": Characterizing and evaluating in- the-wild jailbreak prompts on large language models. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. 1671–1685
2024
-
[46]
Jiawen Shi, Zenghui Yuan, Yinuo Liu, Yue Huang, Pan Zhou, Lichao Sun, and Neil Zhenqiang Gong. 2024. Optimization-based prompt injection attack to llm-as-a-judge. InProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. 660– 674. Provably Secure Agent Guardrail
2024
-
[47]
Craig Smorynski. 1977. The incompleteness theorems. InStudies in Logic and the Foundations of Mathematics. Vol. 90. Elsevier, 821–865
1977
-
[48]
Surada Suwansathit, Yuxuan Zhang, and Guofei Gu. 2026. A System- atic Taxonomy of Security Vulnerabilities in the OpenClaw AI Agent Framework.arXiv preprint arXiv:2603.27517(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [49]
-
[50]
Sam Toyer, Olivia Watkins, Ethan Adrian Mendes, Justin Svegliato, Luke Bailey, Tiffany Wang, Isaac Ong, Karim Elmaaroufi, Pieter Abbeel, Trevor Darrell, Alan Ritter, and Stuart Russell. 2023. Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game.https: //arxiv.org/pdf/2311.01011.pdf
-
[51]
AM TURING. 1936. ON COMPUTABLE NUMBERS, WITH AN AP- PLICATION TO THE ENTSCHEIDUNGSPROBLEM.J. of Math58 (1936), 345–363
1936
-
[52]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel Bowman. 2023. Language models don’t always say what they think: Unfaithful expla- nations in chain-of-thought prompting.Advances in Neural Informa- tion Processing Systems36 (2023), 74952–74965
2023
-
[53]
Vijay Varadharajan. 2000. Security enhanced mobile agents. InPro- ceedings of the 7th ACM conference on Computer and Communications Security. 200–209
2000
-
[54]
Junjie Wang, Bihuan Chen, Lei Wei, and Yang Liu. 2017. Skyfire: Data-Driven Seed Generation for Fuzzing. In2017 IEEE Symposium on Security and Privacy (SP). 579–594. doi:10.1109/SP.2017.23
-
[55]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. Jailbroken: How does llm safety training fail?Advances in neural information processing systems36 (2023), 80079–80110
2023
-
[56]
Yunze Wei, Xiaohui Xie, Tianshuo Hu, Yiwei Zuo, Xinyi Chen, Kaiwen Chi, and Yong Cui. 2025. INTA: Intent-Based Translation for Net- work Configuration with LLM Agents . In2025 IEEE 33rd International Conference on Network Protocols (ICNP). IEEE Computer Society, Los Alamitos, CA, USA, 1–16. doi:10.1109/ICNP65844.2025.11192391
-
[57]
Benlong Wu, Yuang Qi, Xiuwei Shang, Weiming Zhang, Nenghai Yu, and Kejiang Chen. 2025. MMPro: A Decoupled Perception-Thinking- Execution Framework for Secure GUI Agent. InProceedings of the 33rd ACM International Conference on Multimedia. 4679–4687
2025
-
[58]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL]https: //arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [59]
-
[60]
Zheng Xin Yong and Stephen Bach. [n. d.]. Self-Jailbreaking: Language Models Can Reason Themselves Out of Safety Alignment After Benign Reasoning Training. InThe Fourteenth International Conference on Learning Representations
-
[61]
Haonan Zhang, Dongxia Wang, Yi Liu, Kexin Chen, Jiashui Wang, Xinlei Ying, Long Liu, and Wenhai Wang. 2025. ORFuzz: Fuzzing the "Other Side" of LLM Safety - Testing Over-Refusal. In2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE)(Seoul, Korea, Republic of). IEEE Press, 1869–1880. doi:10.1109/ ASE63991.2025.00156
-
[62]
Junbo Zhang, Ran Chen, Qianli Zhou, Xinyang Deng, and Wen Jiang
- [63]
-
[64]
Yulai Zhao, Haolin Liu, Dian Yu, Sunyuan Kung, Meijia Chen, Haitao Mi, and Dong Yu. 2025. One token to fool llm-as-a-judge.arXiv preprint arXiv:2507.08794(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043 (2023). A Open Science A.1 Description and Requirements This section documents the packaged artifact that accompa- nies the paper and describes how to inspec...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.