Code-QA-Bench: Separating Code Reasoning from Documentation Memorization in Repository-Level QA
Pith reviewed 2026-06-29 06:57 UTC · model grok-4.3
The pith
Code access improves repository QA performance much more than documentation does.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The framework produces 528 code-derivable tasks and 100 doc-dependent tasks. Frontier models tested under closed-book, code-only, and documented conditions show that code access accounts for a mean gain of 0.23 over closed-book, documentation supplies an additional 0.071 gain only on doc-dependent tasks, and scores on code-derivable tasks are nearly identical between code-only and documented conditions.
What carries the argument
The three-condition experimental design (closed-book, code-only, documented) that measures separate effects of code access and documentation by direct performance deltas.
If this is right
- Code access is the dominant factor behind improved answers on repository tasks.
- Documentation supplies only modest extra value beyond code on tasks that depend on it.
- Performance with code alone nearly equals performance with full documentation when questions can be answered from code structure.
- The synthesis method applies to any well-documented Python repository.
Where Pith is reading between the lines
- Future benchmarks could adopt code-only conditions as the default to focus evaluation on reasoning rather than recall.
- The modest documentation benefit suggests that repository QA systems might prioritize code indexing over full text retrieval.
- Similar three-condition tests on other languages or task sources could check whether the pattern holds beyond the current Python repositories.
Load-bearing premise
The three conditions isolate documentation utility and memorization without interference from the agent used to generate answers or from the way tasks were selected from the repositories.
What would settle it
Re-running the evaluation and finding substantially higher scores in the documented condition than in the code-only condition on tasks labeled code-derivable.
Figures
read the original abstract
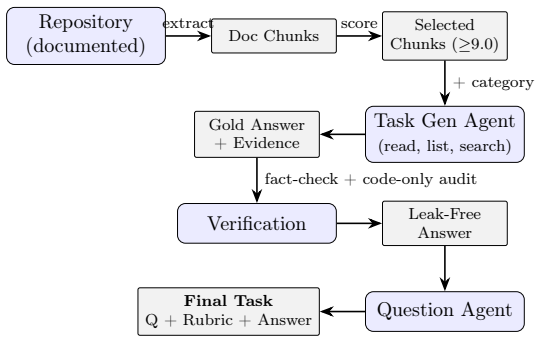
We present Code-QA-Bench, a fully automated framework for synthesizing repository-level code understanding benchmarks that separates genuine code comprehension from documentation recall and pretraining memorization. The framework makes two methodological contributions: (1) an answer-first generation pipeline where a tool-equipped agent explores source code to produce verified gold answers before deriving questions, ensuring every task is grounded in real code structure; and (2) a three-condition experimental design evaluating agents under closed-book (no repository), code-only (documentation removed), and documented (full repository) conditions, with deltas directly quantifying documentation utility and memorization. We generate 528 code-derivable and 100 doc-dependent tasks across 10 Python repositories from SWE-Bench, scored by an LLM judge on accuracy, completeness, and specificity. Experiments on four frontier models reveal that code access is the dominant factor (+0.23 mean gain over closed-book), documentation provides modest additional benefit (+0.071 on doc-dependent tasks), and code-only $\approx$ documented on code-derivable tasks, validating the design. The framework is open-source and applicable to any well-documented Python repository.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Code-QA-Bench, a fully automated framework for synthesizing repository-level code understanding benchmarks. It introduces an answer-first generation pipeline in which a tool-equipped agent explores source code to produce verified gold answers before questions are derived, and a three-condition experimental design (closed-book, code-only with documentation removed, and documented) that is intended to quantify documentation utility and memorization effects. The work generates 528 code-derivable and 100 doc-dependent tasks from 10 Python repositories in SWE-Bench, evaluates four frontier models using an LLM judge on accuracy/completeness/specificity, and reports that code access yields a +0.23 mean gain over closed-book while documentation adds only +0.071 on doc-dependent tasks, with code-only performance approximately matching documented performance on code-derivable tasks.
Significance. If the separation claim holds after addressing validation gaps, the benchmark supplies a reproducible, open-source method for isolating code reasoning from documentation recall that could improve evaluation practices for repository-level QA in software engineering. The quantitative deltas and the applicability to any well-documented Python repository constitute concrete, falsifiable contributions that other researchers could directly extend or refute.
major comments (3)
- [Abstract] Abstract: the reported deltas (+0.23 code gain, +0.071 documentation benefit) and the claim that the three-condition design 'directly quantif[ies] documentation utility and memorization' rest on LLM-judge scores, yet the manuscript supplies no information on judge calibration, inter-rater agreement, or human validation of the judge; this absence is load-bearing for interpreting the numerical results as evidence of separation.
- [Abstract] Abstract (answer-first pipeline description): the gold-answer generation step uses a tool-equipped agent whose capabilities relative to the four evaluated frontier models are not characterized; if the generation agent shares relevant strengths with the evaluated models, the resulting task distribution could artifactually inflate the observed code-only versus closed-book gap and undermine the central separation claim.
- [Abstract] Abstract (task split): the classification of tasks into 528 code-derivable and 100 doc-dependent subsets is presented without a detailed selection protocol, inter-annotator agreement statistics, or ablation on classification criteria; without these, it is impossible to rule out that the reported code-only ≈ documented equivalence on code-derivable tasks arises from curation artifacts rather than the intended isolation of documentation utility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the opportunity to clarify key methodological aspects of Code-QA-Bench. The comments correctly identify areas where additional validation and documentation will strengthen the separation claims. We address each point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported deltas (+0.23 code gain, +0.071 documentation benefit) and the claim that the three-condition design 'directly quantif[ies] documentation utility and memorization' rest on LLM-judge scores, yet the manuscript supplies no information on judge calibration, inter-rater agreement, or human validation of the judge; this absence is load-bearing for interpreting the numerical results as evidence of separation.
Authors: We agree that the absence of judge validation details limits interpretability of the deltas. In the revised manuscript we will add a new subsection (Section 4.3) that specifies the LLM judge prompt, reports calibration against human annotations on a 50-task random sample (including accuracy, completeness, and specificity scores with Cohen's kappa), and provides inter-rater agreement statistics between the judge and two human annotators. These additions will allow readers to assess the reliability of the reported +0.23 and +0.071 gains. revision: yes
-
Referee: [Abstract] Abstract (answer-first pipeline description): the gold-answer generation step uses a tool-equipped agent whose capabilities relative to the four evaluated frontier models are not characterized; if the generation agent shares relevant strengths with the evaluated models, the resulting task distribution could artifactually inflate the observed code-only versus closed-book gap and undermine the central separation claim.
Authors: The generation agent uses the same base model as one of the evaluated models but is equipped with repository-specific tools (file search, AST parsing, execution) unavailable to the evaluated models during testing. While this design difference reduces direct comparability concerns, we acknowledge the need for explicit characterization. We will add an appendix comparing the agent's closed-book success rate on the generated tasks against the four evaluated models' closed-book performance to quantify any capability overlap. revision: partial
-
Referee: [Abstract] Abstract (task split): the classification of tasks into 528 code-derivable and 100 doc-dependent subsets is presented without a detailed selection protocol, inter-annotator agreement statistics, or ablation on classification criteria; without these, it is impossible to rule out that the reported code-only ≈ documented equivalence on code-derivable tasks arises from curation artifacts rather than the intended isolation of documentation utility.
Authors: Task classification was performed by two authors who independently labeled whether each gold answer could be derived from code alone. We will expand the methods section with the full annotation guidelines, report inter-annotator agreement (Cohen's kappa on a 20% stratified sample), and include a sensitivity analysis that varies the classification criteria to test robustness of the code-only ≈ documented equivalence on the code-derivable subset. revision: yes
Circularity Check
No significant circularity; experimental outcomes are independent of inputs
full rationale
The paper describes an empirical benchmark construction pipeline and reports direct experimental deltas from evaluating four frontier models under three conditions. No equations, fitted parameters, or predictions defined in terms of the inputs appear. No self-citations are invoked to justify uniqueness or load-bearing premises. Task classification and scoring are presented as procedural outcomes rather than quantities that reduce to the generation agent or SWE-Bench selection by construction. The derivation chain consists of observable measurements and is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SWE-Bench+: Enhanced Coding Benchmark for LLMs.arXiv preprint arXiv:2410.06992, 2024
Aleithan, R., Kang, M.J., and Kamalloo, E. SWE-Bench+: Enhanced Coding Benchmark for LLMs.arXiv preprint arXiv:2410.06992, 2024
-
[2]
Program Synthesis with Large Language Models
Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., and Sutton, C. Program Synthesis with Large Language Models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Cai, S., Lyu, Z., Ni, Y., Chen, X., Zhou, B., Zhu, S., Lu, Y., Wang, H., Ruan, C., Schnei- der, B., Zhang, W., Li, X., Zheng, A., Zhang, Y., Nie, P., and Chen, W. SWE-QA-Pro: A Representative Benchmark and Scalable Training Recipe for Repository-Level Code Un- derstanding.arXiv preprint arXiv:2603.16124, 2025
-
[4]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H.P.O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Chou, J., Liu, A., Deng, Y., Zeng, Z., Zhang, T., Zhu, H., Cai, J., Mao, Y., Zhang, C., Tan, L., Xu, Z., Zhai, B., Liu, H., Zhu, S., Zhou, W., and Lian, F. AutoCodeBench: Large Language Models are Automatic Code Benchmark Generators.arXiv preprint arXiv:2508.09101, 2025
-
[6]
CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion
Ding, Y., Wang, Z., Ahmad, W.U., Ramanathan, M.K., Nallapati, R., Bhatia, P., Roth, D., and Xiang, B. CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion. InNeurIPS, 2024
2024
-
[7]
CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution
Gu, A., Rozière, B., Leather, H., Solar-Lezama, A., Synnaeve, G., and Wang, S.I. CRUX- Eval: A Benchmark for Code Reasoning, Understanding and Execution.arXiv preprint arXiv:2401.03065, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Husain, H., Wu, H.-H., Gazit, T., Allamanis, M., and Brockschmidt, M. CodeSearchNet Challenge: EvaluatingtheStateofSemanticCodeSearch.arXiv preprint arXiv:1909.09436, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[9]
Measuring Coding Challenge Competence with APPS
Hendrycks, D., Basart, S., Kadavath, S., Mazeika, M., Arora, A., Guo, E., Burns, C., Puranik, S., He, H., Song, D., and Steinhardt, J. Measuring Coding Challenge Competence with APPS. InNeurIPS, 2021
2021
-
[10]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Jain, N., Han, K., Gu, A., Li, W.-D., Yan, F., Zhang, T., Wang, S.I., Solar-Lezama, A., Sen, K., and Stoica, I. LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
R2E: Turning any Github Repository into a Programming Agent Environment
Jain, N., Shetty, M., Zhang, T., Han, K., Sen, K., and Stoica, I. R2E: Turning any Github Repository into a Programming Agent Environment. InICML, 2024
2024
-
[12]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? InICLR, 2024
Jimenez, C.E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., and Narasimhan, K. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? InICLR, 2024
2024
-
[13]
Lee, J., Seo, J., Ahn, J., and Seo, M. CS1QA: A Dataset for Assisting Code-based Question AnsweringinanIntroductoryProgrammingCourse.arXiv preprint arXiv:2210.14921, 2022. 14
-
[14]
DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories
Li, J., Qi, G., Li, Y., Dong, Y., and Guo, D. DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories. InACL, 2024
2024
-
[15]
DevBench: A Comprehensive Benchmark for Software Development.arXiv preprint arXiv:2403.08604, 2024
Li, B., Fang, T., Cui, Y., Jiang, Y., Wu, J., Gong, Y., Ding, L., Sun, J., and Tao, D. DevBench: A Comprehensive Benchmark for Software Development.arXiv preprint arXiv:2403.08604, 2024
-
[16]
Competition-Level Code Generation with AlphaCode
Li, Y., Choi, D., Chung, J., Kushman, N., Schrittwieser, J., Leblond, R., Eccles, T., Keeling, J., Gimeno, F., Dal Lago, A., et al. Competition-Level Code Generation with AlphaCode. Science, 378(6624):1092–1097, 2022
2022
-
[17]
Li, J., Su, Y., and Lyu, M.R. From Laboratory to Real-World Applications: Benchmarking Agentic Code Reasoning at the Repository Level.arXiv preprint arXiv:2601.03731, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Li, T., Chiang, W.-L., Frick, E., Dunlap, L., Zhu, B., Gonzalez, J.E., and Stoica, I. From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline. arXiv preprint arXiv:2406.11939, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation
Liu, J., Xia, C.S., Wang, Y., and Zhang, L. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. InNeurIPS, 2024
2024
-
[20]
CodeMind: Evaluating Large Language Models for Code Reasoning
Liu, T., Fang, J., Wen, Y., and Xie, T. CodeMind: A Framework to Challenge Large Language Models for Code Reasoning.arXiv preprint arXiv:2402.09664, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
CodeQA: A Question Answering Dataset for Source Code Comprehension
Liu, J., Wan, C., Tao, C., Zhao, K., and Sun, C. CodeQA: A Question Answering Dataset for Source Code Comprehension. InFindings of EMNLP, 2021
2021
-
[22]
RepoBench: Benchmarking Repository-Level Code Auto- Completion Systems
Liu, T., Xu, C., and McAuley, J. RepoBench: Benchmarking Repository-Level Code Auto- Completion Systems. InICLR, 2024
2024
-
[23]
Stimulus Structures and Mental Representations in Expert Comprehension of Computer Programs.Cognitive Psychology, 19(3):295–341, 1987
Pennington, N. Stimulus Structures and Mental Representations in Expert Comprehension of Computer Programs.Cognitive Psychology, 19(3):295–341, 1987
1987
-
[24]
SWE-QA: Can Language Models Answer Repository-level Code Questions?
Peng, W., Shi, Y., Wang, Y., Zhang, X., Shen, B., and Gu, X. SWE-QA: Can Language Models Answer Repository-level Code Questions?arXiv preprint arXiv:2509.14635, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Descriptive Compound Identifier Names Improve Source Code Comprehension
Schankin, A., Berger, A., Holt, D.V., Hofmeister, J.C., Riedel, T., and Beigl, M. Descriptive Compound Identifier Names Improve Source Code Comprehension. InICPC, 2018
2018
-
[26]
ProgramComprehensionDuringSoftwareMaintenance and Evolution.IEEE Computer, 28(8):44–55, 1995
vonMayrhauser, A.andVans, A.M. ProgramComprehensionDuringSoftwareMaintenance and Evolution.IEEE Computer, 28(8):44–55, 1995
1995
-
[27]
A Survey on Large Language Models for Code Generation
Xia, C.S., Deng, Y., and Zhang, L. A Survey on Large Language Models for Code Genera- tion.arXiv preprint arXiv:2406.00515, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Agentless: Demystifying LLM-based Software Engineering Agents
Xia, C.S., Deng, Y., Dunn, S., and Zhang, L. Agentless: Demystifying LLM-based Software Engineering Agents.arXiv preprint arXiv:2407.01489, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
FeatureBench: Benchmarking Agentic Coding for Complex Feature Development.arXiv preprint, 2025
Xie, Y., Liu, Z., Chen, Y., Li, J., et al. FeatureBench: Benchmarking Agentic Coding for Complex Feature Development.arXiv preprint, 2025
2025
-
[30]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
Yang, J., Jimenez, C.E., Wettig, A., Liber, K., Yao, S., Narasimhan, K., and Press, O. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering.arXiv preprint arXiv:2405.15793, 2024. 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
EvoCodeBench: An Evolving Code Generation Benchmark Aligned with Real-World Code Repositories
Li, J., Zhang, G., Li, Y., Dong, Y., Luo, L., Zhu, M., Guo, Y., and He, Q. EvoCodeBench: An Evolving Code Generation Benchmark Aligned with Real-World Code Repositories. arXiv preprint arXiv:2404.00599, 2024
-
[32]
CodeScope: An Execution-Based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation
Yan, W., Liu, H., Wang, Y., Li, Z., Zhao, Q., Wei, F., Liu, T., and Sui, Z. CodeScope: An Execution-Based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation. InACL, 2024
2024
-
[33]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E.P., et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. In NeurIPS, 2023. A Example Tasks We present four example tasks, one per category, drawn from different repositories. Where / data_control_flow (sympy) Question:Where doesipartfracget call...
2023
-
[34]
Internally it usesfunctools.reduceto compute total product of denominators, builds complement values, and passes them tomigcdexwhich callsigcdexpair- wise
Itbuildscomplementvalues(denom // xforeachx)andpassesthemtomigcdex Gold answer (abridged):Theipartfracfunction flows data through the follow- ing call chain: it is called incos._eval_rewrite_as_sqrt()intrigonometric.py. Internally it usesfunctools.reduceto compute total product of denominators, builds complement values, and passes them tomigcdexwhich call...
-
[35]
Finalizers are popped in LIFO order (using.pop())
-
[36]
Finalizers are popped in LIFO order
Multiple exceptions are wrapped in aBaseExceptionGroupwith exceptions reversed 16 Gold answer (abridged):FixtureDef.finish()runs all finalizers even if some fail. Finalizers are popped in LIFO order. If multiple exceptions occur, they are wrapped in aBaseExceptionGroupwithexceptions[::-1]. After finalization, cached_resultis set toNoneand_finalizers.clear...
-
[37]
Defined incommon.pywith three@overloadsignatures and a single implemen- tation acceptingos.PathLike | str | T
-
[38]
Performstwotransformations:os.fspath()forPathLike, andos.path.abspath(os.path.expanduser(path)) for local strings
-
[39]
It has three@overloadsignatures:PathLike→str, str→str, and genericT→T
Remote URIs detected viais_remote_uri()(regex-based inutils.py) are left unmodified Gold answer (abridged):_normalize_pathnormalizes file paths throughout xar- ray’s backend I/O system. It has three@overloadsignatures:PathLike→str, str→str, and genericT→T. It converts PathLike objects viaos.fspath(), expands local strings, and passes remote URIs through u...
-
[40]
The management command calls_ogrinspectdirectly to collect lines into a list and append the mapping dictionary before joining
-
[41]
""Calculate Euclidean distance between two points. Args: point_a: A tuple (x, y). point_b: A tuple (x, y). Returns: The Euclidean distance
The command usesget_func_args(_ogrinspect)to dynamically filter CLI options to accepted parameters Gold answer (abridged):The separation serves two purposes: (1) streaming vs. string output —_ogrinspectyields lines one at a time, allowing the management command to append additional output before joining; (2) dynamic argument filtering — the command usesge...
-
[42]
Accuracy (0-5): Are the factual claims correct?
-
[43]
Completeness (0-5): Does the answer cover all rubric points?
-
[44]
accuracy
Specificity (0-5): Does the answer reference specific files/functions? Return JSON: {"accuracy": N, "completeness": N, "specificity": N, "explanation": "..."} D Comparison with SWE-QA and SWE-QA-Pro Table 9: Feature comparison of repository-level code QA benchmarks. F eature SWE-QA SWE-QA-Pro Code-QA-Bench Repositories 12 (popular) 26 (long-tail) 10 (popu...
-
[45]
Start by locating the code referenced in the documentation chunk
-
[46]
Read the primary file(s) and identify the key functions/classes
-
[47]
Go ONE LEVEL DEEPER: trace at least one callee, one parent class, or one related module to understand how the code connects to the broader system
-
[48]
{repo_name}
Your answer must include facts you discovered from code that are NOT stated in the documentation chunk -- this is what makes the benchmark challenging Theuser promptprovides the documentation chunk as a topic guide and specifies the target category: The following documentation chunk from "{repo_name}" identifies the TOPIC for your answer. Use it to know W...
-
[49]
Use tools to find and read the source code
-
[50]
Go deeper: trace at least one callee, parent class, or import
-
[51]
answer":
Write an answer that includes specific code details NOT found in the documentation chunk above When done exploring, respond with JSON (no tool calls): { "answer": "...", "key_files": ["relative/path.py", ...], "code_evidence": [ "specific fact verified by reading code (file + function)", ... ] } Your answer MUST include at least 3 items in code_evidence. ...
-
[52]
23 I Per-Repository Breakdown Table 13 shows code-only scores by repository for all four models
mean that model-to-model differences in∆ doc are not individually significant, but the consistent directionality across all four models provides strong evidence for the aggregate effect. 23 I Per-Repository Breakdown Table 13 shows code-only scores by repository for all four models. Scores are consistent across repositories: within each model, the range s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.