STAMP: Training Explicit Memory for Mobile GUI Agents in Controllable and Scalable Virtual Environments
Pith reviewed 2026-06-29 07:42 UTC · model grok-4.3
The pith
Virtual environments with injected memory variables train GUI agents to explicitly remember information across long tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
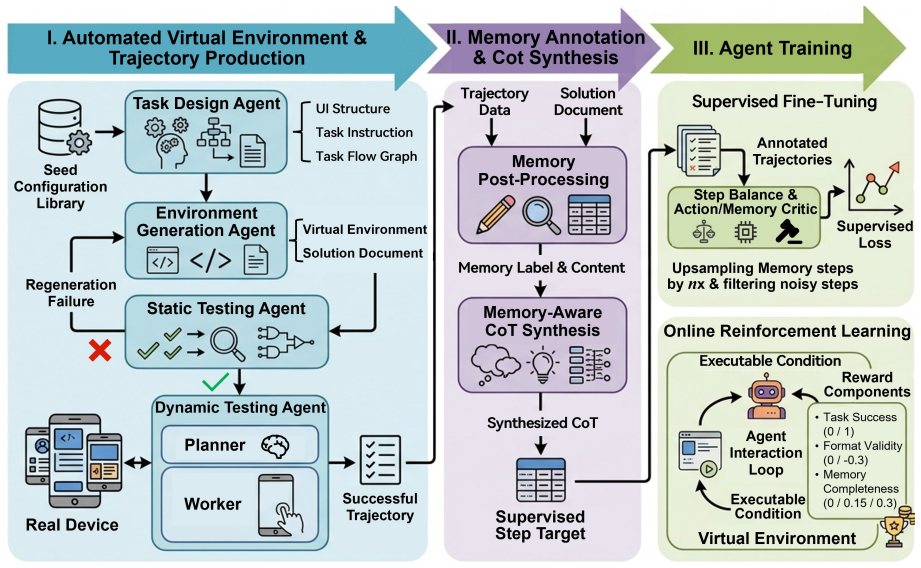
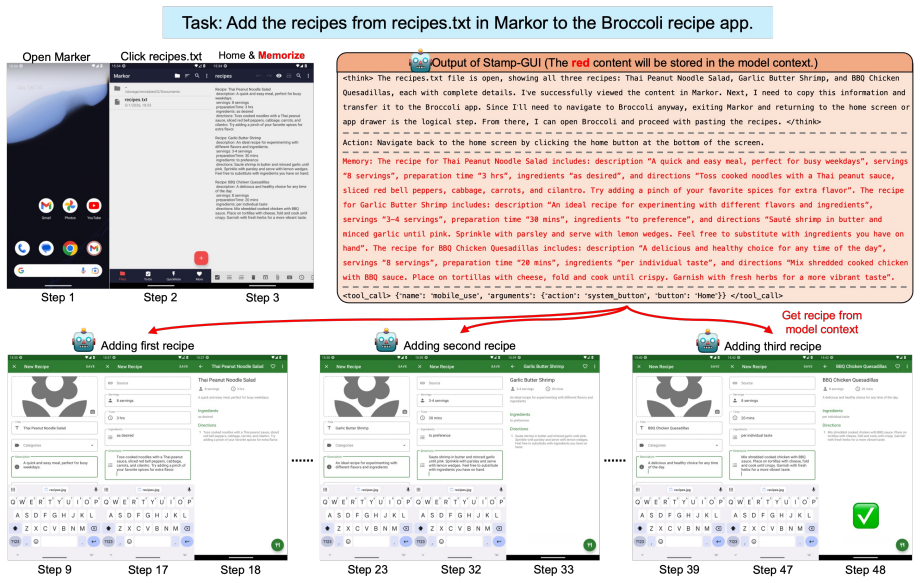
STAMP trains explicit memory in mobile GUI agents by building controllable virtual environments that inject deterministic memory variables into synthesized tasks, specifying exactly what must be memorized, when it must be encoded, and when it must be retrieved, thereby yielding verifiable training signals at scale and enabling online reinforcement learning with environment-driven rewards.
What carries the argument
Programmatically injected deterministic memory variables in virtual environments that control encoding and retrieval timing to create supervised memory data.
If this is right
- Agents gain the ability to retain transient details across dozens of steps without exhausting context windows.
- Training data for memory behavior can be generated programmatically instead of collected from expensive real interactions.
- Online reinforcement learning becomes feasible because environment rewards directly score correct recall timing.
- General mobile navigation performance remains intact while memory accuracy improves on the Memory-World benchmark.
Where Pith is reading between the lines
- The same injection technique could be adapted to train memory in non-GUI agents such as web or desktop controllers.
- If virtual memory variables transfer well, real-device data collection for long-horizon tasks could be reduced.
- Benchmark results on Memory-World may understate failure modes that appear only when memory variables are not explicitly provided.
Load-bearing premise
That the memory variables and rewards programmed into virtual environments match the memory demands of actual mobile GUI use.
What would settle it
A test showing that an agent trained only on the virtual memory tasks performs no better than baseline agents when given the same long real-world mobile navigation sequences.
Figures

read the original abstract
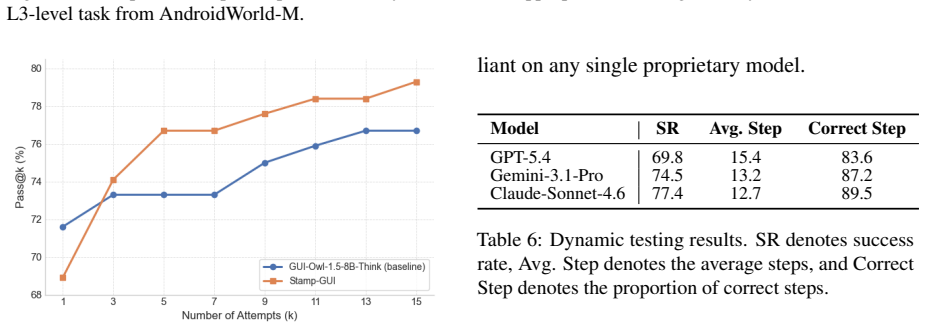
Mobile GUI agents excel at immediate reactive control but frequently fail in realistic, long-horizon tasks that require memory. This failure stems from a fundamental conflict between limited context windows and token-heavy screenshots. To save the limited context, agents must progressively discard older visual history, permanently losing crucial transient information. Furthermore, existing action-centric datasets fail to teach agents what or when to explicitly memorize, and augmenting static real-world data is prohibitively expensive and lacks interactive verification. To resolve this, we present STAMP, a framework that trains explicit memory in mobile agents through controllable virtual environments, where deterministic memory variables are programmatically injected into synthesized tasks to control what must be memorized, when it should be encoded, and when it must later be retrieved, thereby producing verifiable supervised data at scale and enabling online reinforcement learning through environment-driven reward feedback. Evaluated on our newly introduced Memory-World benchmark, the resulting Stamp-GUI agent achieves state-of-the-art performance among GUI-specialized models and sets a new high watermark on our Memory-World benchmark, demonstrating exceptional memory accuracy and task resilience while maintaining strong general mobile navigation capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the STAMP framework for training explicit memory capabilities in mobile GUI agents. It uses controllable virtual environments in which deterministic memory variables are programmatically injected into synthesized tasks to generate verifiable supervised data at scale and to supply environment-driven rewards for online reinforcement learning. The work also introduces the Memory-World benchmark; the resulting Stamp-GUI agent is claimed to achieve state-of-the-art performance among GUI-specialized models, set a new high watermark on Memory-World, exhibit exceptional memory accuracy and task resilience, and retain strong general mobile navigation capabilities.
Significance. If the central claim holds and the virtual-environment training signal transfers, the approach would supply a scalable, controllable route to teaching long-horizon memory policies that current context-window-limited agents lack, addressing a recognized bottleneck in realistic GUI task execution.
major comments (2)
- [Abstract] Abstract: the claim that Stamp-GUI 'achieves state-of-the-art performance among GUI-specialized models and sets a new high watermark on our Memory-World benchmark' is asserted without any reported metrics, baselines, ablation results, or experimental protocol, rendering the central empirical claim unsupported in the provided text.
- [Method description] Method description (and Abstract): the training signal rests on the assumption that programmatically injected deterministic memory variables and environment rewards accurately capture the memory requirements of real mobile GUI tasks. Real GUIs contain non-deterministic state, implicit visual/layout cues, and app-internal state not exposed as variables; no cross-domain evaluation on unmodified real-device traces or human-annotated memory tasks is described to test transfer of the learned policies.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that Stamp-GUI 'achieves state-of-the-art performance among GUI-specialized models and sets a new high watermark on our Memory-World benchmark' is asserted without any reported metrics, baselines, ablation results, or experimental protocol, rendering the central empirical claim unsupported in the provided text.
Authors: We agree that the abstract asserts the central empirical claims without including supporting metrics or protocol details. The full manuscript reports these results in the experiments section. We will revise the abstract to include key quantitative results (e.g., Memory-World accuracy scores and baseline comparisons) and a concise reference to the evaluation setup. revision: yes
-
Referee: [Method description] Method description (and Abstract): the training signal rests on the assumption that programmatically injected deterministic memory variables and environment rewards accurately capture the memory requirements of real mobile GUI tasks. Real GUIs contain non-deterministic state, implicit visual/layout cues, and app-internal state not exposed as variables; no cross-domain evaluation on unmodified real-device traces or human-annotated memory tasks is described to test transfer of the learned policies.
Authors: We acknowledge the assumption underlying the virtual-environment training signal and the absence of cross-domain transfer experiments on real devices. The manuscript deliberately centers on controllable virtual environments to enable scalable, verifiable memory supervision; it does not claim or evaluate transfer to unmodified real-device traces. We will revise the method description and abstract to state this scope more explicitly and will add a limitations paragraph discussing the gap to real-world non-deterministic GUIs as future work. revision: partial
Circularity Check
No circularity: training and benchmark both rely on explicit injected variables but the performance metric is not forced by construction
full rationale
The paper describes a methodological framework that programmatically injects deterministic memory variables into synthesized virtual tasks to generate training signals and then evaluates the resulting agent on the newly introduced Memory-World benchmark. No equations, self-citations, or derivations are presented that reduce the reported SOTA memory accuracy or task resilience to a tautological fit or renaming of the injected variables themselves. The central claim remains an empirical statement about agent behavior in the constructed environments rather than a self-referential prediction. This is the most common honest non-finding for a methods paper that introduces both its training distribution and its evaluation distribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Yuxiang Chai, Siyuan Huang, Yazhe Niu, Han Xiao, Liang Liu, Guozhi Wang, Dingyu Zhang, Shuai Ren, and Hongsheng Li. 2025. Amex: Android multi- annotation expo dataset for mobile gui agents. In Findings of the Association for Computational Lin- guistics: ACL 2025, pages 2138–2156. Tongbo Chen, Zhen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Memgui-bench: Benchmarking memory of mobile gui agents in dynamic environments.arXiv preprint arXiv:2602.06075. Xiao Liu, Bo Qin, Dongzhu Liang, Guang Dong, Hanyu Lai, Hanchen Zhang, Hanlin Zhao, Iat Long Iong, Jiadai Sun, Jiaqi Wang, and 1 others. 2024. Auto- glm: Autonomous foundation agents for guis.arXiv preprint arXiv:2411.00820. Quanfeng Lu, Wenqi S...
-
[3]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458. Dang Nguyen, Jian Chen, Yu Wang, Gang Wu, Namy- ong Park, Zhengmian Hu, Hanjia Lyu, Junda Wu, Ryan Aponte, Yu Xia, and 1 others. 2024. Gui agents: A survey.ArXiv preprint, abs/2412.13501. OpenAI. 2026. Gpt 5.4. Technical report, OpenAI. System Card. ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Ui-venus-1.5 technical report.arXiv preprint arXiv:2602.09082. Tongyi. 2026. Qwen-3.5. Technical report, Tongyi. System Card. Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, and 1 others. 2025a. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcemen...
-
[5]
Appagent: Multimodal agents as smartphone users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–20. Jiwen Zhang, Jihao Wu, Teng Yihua, Minghui Liao, Nuo Xu, Xiao Xiao, Zhongyu Wei, and Duyu Tang. 2024b. Android in the zoo: Chain-of-action-thought for gui agents. InFindings of the Association for Computational Lingu...
-
[6]
Action: a short imperative describing what to do in the UI
-
[7]
Memory: the key information need to memory in the screenshot
-
[8]
name": <function-name>,
A single <tool_call>...</tool_call> block containing only the JSON: {"name": <function-name>, "arguments": <args- json-object>}. Rules: - Output exactly in the order: Action, Memory, <tool_call>. - Be brief: one for Action. - Do not output anything else outside those three parts. - If finishing, use action=terminate in the tool call. Table 15: System prom...
-
[9]
Do not perform exploratory actions based on your own assumptions
Follow the task guideline strictly. Do not perform exploratory actions based on your own assumptions
-
[10]
The input action already includes one click, so you do not need to click the input box separately before inputting
-
[11]
If a popup appears, try closing it first
-
[12]
You must first browse all information according to the detailed guideline, and only then input the answer
Do not try to input the final answer directly. You must first browse all information according to the detailed guideline, and only then input the answer
-
[13]
Table 16: Prompt used by the dynamic testing planner
Before entering the final answer, you must review the action history and screenshots to ensure that all required information for the task has already appeared. Table 16: Prompt used by the dynamic testing planner. Memory-Acc Evaluation Prompt I have a task to perform using Chrome on my phone, as follows: {} Please note that this task requires memorizing s...
-
[14]
Complete Match
If the mobile phone agent’s memory completely matches the provided content to be memorized, output “Complete Match”
-
[15]
Partial Match
If the mobile phone agent’s memory partially matches the provided content to be memorized, output “Partial Match”
-
[16]
No Match
If the mobile phone agent’s memory does not match the provided content to be memorized at all, output “No Match”. “Match” means that both expressions convey the same meaning. They do not need to be completely identical. As long as the core content to be memorized, such as numbers or strings, is the same, it is acceptable. Now, after careful consideration,...
-
[17]
task.final_action.gold must be exactly identical to scenario.data.truth.gold
-
[18]
task.grading.gold must be exactly identical to task.final_action.gold
-
[19]
task.grading.pass_regex must match the gold string, preferably using ˆ...$
-
[20]
required_testids must include at least: - all tabs: tab-* - search input: search-input (if the scenario has a search page) - final submission: go-submit-answer, answer-input, answer-submit, result - fact display containers used by memory_items, such as fact-xxx / followers-name / price-sku
-
[21]
task.natural_language must clearly describe the task flow, such as which pages to visit and what kind of information to look for, but it must not reveal the actual values that need to be remembered
-
[22]
task.guideline must be a more detailed version of task.natural_language, and must describe the full workflow, all memory targets, and the final submission process in detail
-
[23]
Find the code 1234 in My > Orders > History
task.guideline must include the exact location and exact content for every memory item, for example: “Find the code 1234 in My > Orders > History” and “Find the event code 5678 in Home > Activities > Popular Events”. Table 19: Prompt used by the task generation agent. 22 Webpage Generation Agent Prompt You are a web app generator. You must generate a sing...
-
[24]
A mobile app style bottom tab bar using task_spec.platform.tabs, with corresponding unique data-testid values in the form tab-*
-
[25]
Every testid listed in task_spec.ui_contract.required_testids must exist, be unique, and be interactable when appropriate
-
[26]
The navigation behavior described in task_spec.ui_contract.navigation_contract must be implemented
-
[27]
Do not alter truth values or truth text
The truth facts in scenario.data.truth.facts must be displayed on the appropriate pages exactly as specified. Do not alter truth values or truth text
-
[28]
go-submit-answer
There must be an entry point with data-testid="go-submit-answer" that leads to a dedicated answer submission page containing: - data-testid="answer-input" - data-testid="answer-submit" - data-testid="result"
-
[29]
Example: xxx
Do not use the <select> element to implement the filter function. If you need to implement the filter function, please use multiple clickable buttons instead. Submission and validation requirements: - The one and only correct answer is: {gold} - Make sure no distractor content creates ambiguity. - {gold} must remain the unique correct answer under all cir...
-
[30]
predicted_answer must comply with task_spec.task.final_action.required_output_format, or at least follow the same exact formatting style as task_spec.task.final_action.gold
-
[31]
ok=true if and only if: - predicted_answer is exactly equal to gold - uniqueness.is_unique is true - the task flow is executable and the required information can actually be found in the HTML without contradiction
-
[32]
evidence.key_observations must contain enough information for a third party to verify how predicted_answer was obtained without running the page
-
[33]
Use the smallest possible fix strategy, with the following priority: (a) first adjust distractor values, ordering, labels, or section membership so they no longer affect the task result (b) second move distractors out of the relevant comparison or calculation area, such as from a ranking list into a recommendation or ad section (c) avoid changing scenario...
-
[34]
For common bugs involving highest value, top-k, sorting, filtering, or ranking, you must check all candidate items that look comparable, including newly introduced distractors, and ensure they do not change the result away from gold
-
[35]
Comparison scope for this task: Popularity ranking
You may modify the HTML to make the task interpretation clearer, for example by renaming a section title to “Comparison scope for this task: Popularity ranking”, but do not leak the answer in instructional text
-
[36]
If the final answer is formed by combining multiple strings, list each minimal component separately
evidence.key_notes must list all minimal memory units required for the final answer. If the final answer is formed by combining multiple strings, list each minimal component separately
-
[37]
All output content must be in English only
-
[38]
Do not include any Chinese characters anywhere, including in the repaired HTML
-
[39]
It must be implemented through multiple clickable buttons
Please ensure that the filter functionality of the webpage is not implemented through the <select> element. It must be implemented through multiple clickable buttons. scenario.truth.facts: {json.dumps(facts, ensure_ascii=False, indent=2)} gold: {gold} scenario JSON: {json.dumps(scn, ensure_ascii=False, indent=2)} task_spec JSON: {json.dumps(task_spec, ens...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.