KBF: Knowledge Boundary as Fingerprint for Language Model and Black-Box API Auditing
Pith reviewed 2026-06-29 06:42 UTC · model grok-4.3
The pith
KBF fingerprints LLM APIs by measuring stable numerical recall near the knowledge boundary to detect substitutions and routing inconsistencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
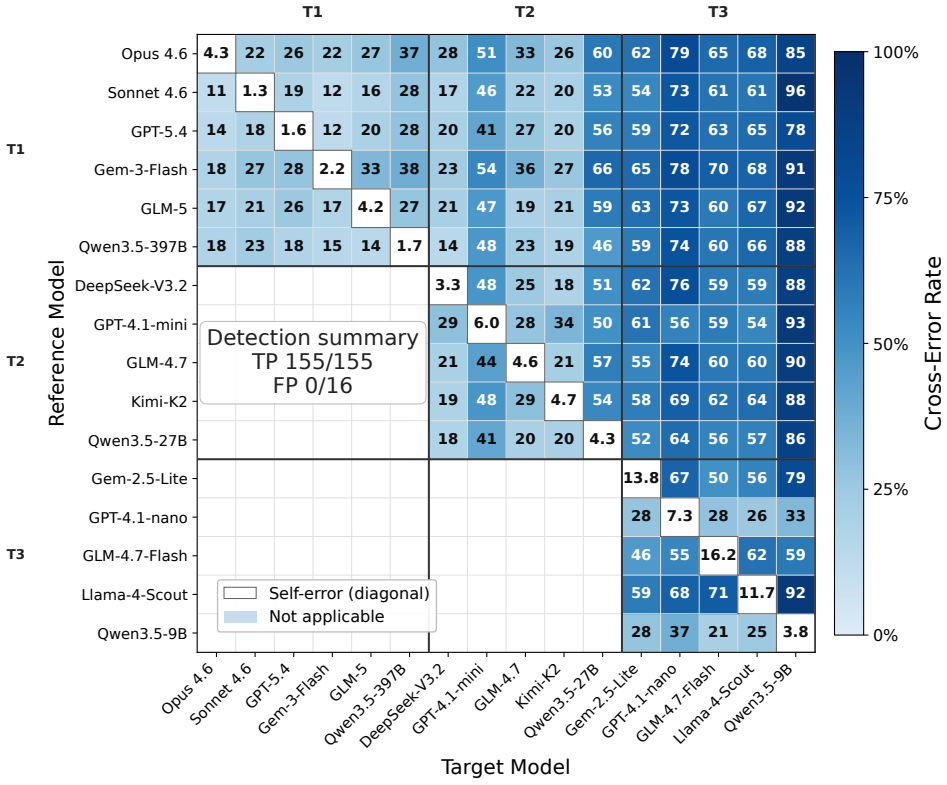
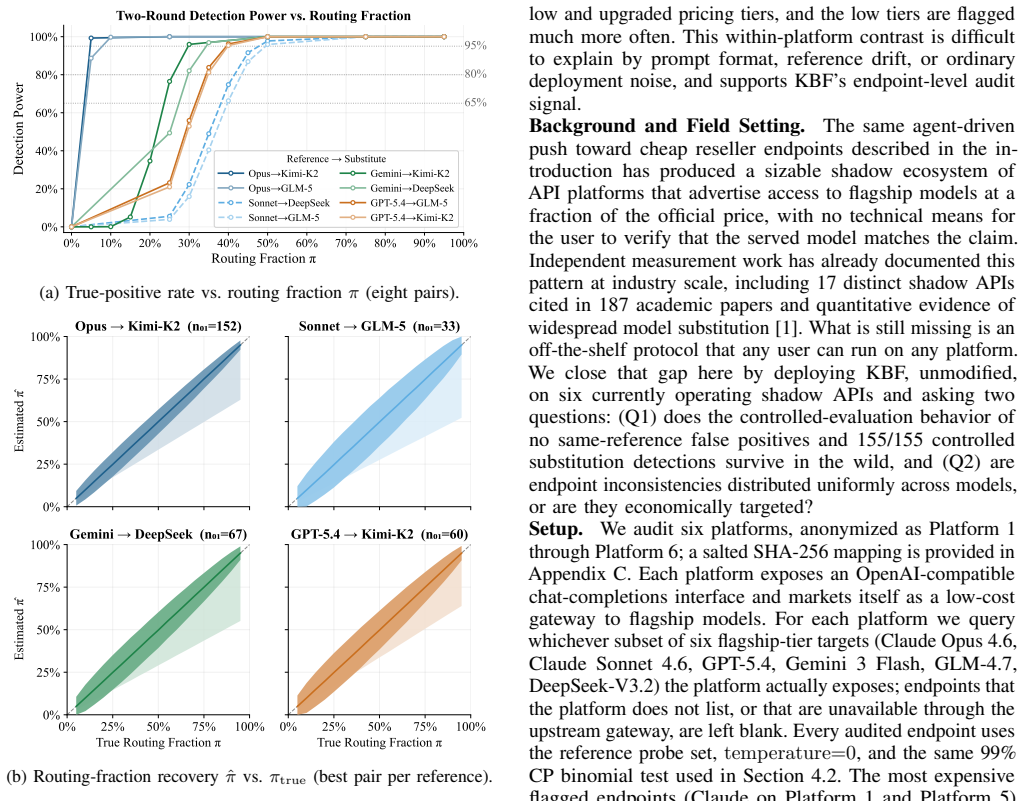
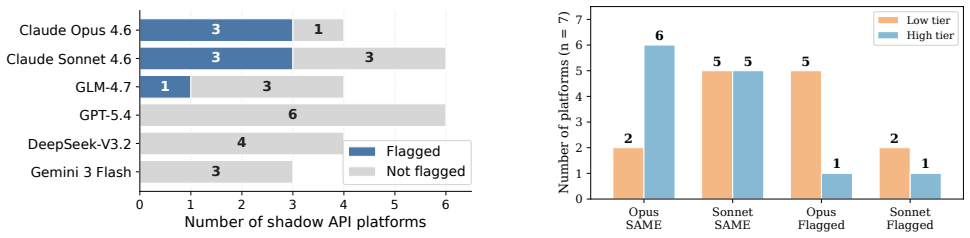
The numerical recall rate near the knowledge boundary functions as a stable, model-specific fingerprint that enables reliable auditing of claimed LLM endpoints without white-box access. When applied to 16 production APIs, the fingerprint correctly identifies all 155 tested substitutions, produces no false rejections on control cases, remains consistent under deployment changes, detects mixed-routing attacks at 5-10 percent substitution rates, and uncovers statistical mismatches in 7 of 27 audited platform cells, concentrated on premium Claude endpoints.
What carries the argument
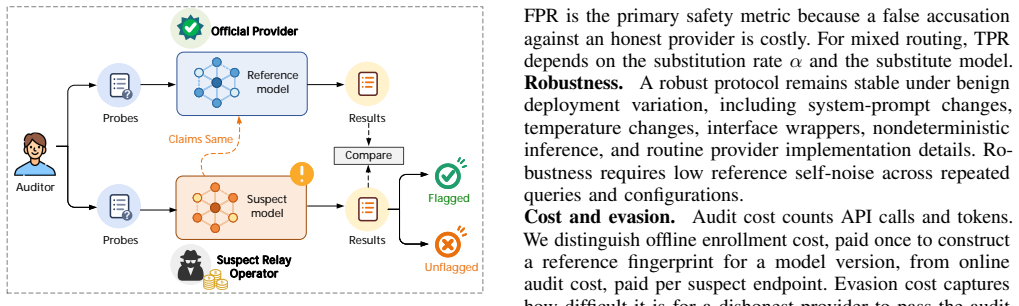
KBF protocol, which extracts a fingerprint from the numerical recall rate of facts positioned near a model's knowledge boundary and compares it across endpoints.
If this is right
- All tested economically relevant substitutions are detected with zero false rejections on same-model controls.
- The fingerprint remains usable under deployment variation and prompt changes.
- Mixed-routing attacks become detectable when as little as 5-10 percent of traffic is substituted.
- Seven of twenty-seven platform model cells show inconsistencies with reference endpoints in a six-platform audit.
Where Pith is reading between the lines
- Users could run periodic checks on commercial APIs to verify they receive the advertised model version.
- The same boundary-recall idea might extend to auditing other black-box services that claim specific capabilities.
- Platforms might adopt boundary-recall benchmarks as part of transparency reporting.
Load-bearing premise
Recall rates near the knowledge boundary stay stable enough and distinct enough across different deployments and minor updates to serve as a reliable unique identifier.
What would settle it
A same-model endpoint that produces recall rates statistically different from its reference fingerprint under normal operation, or a substituted endpoint whose rates match the claimed model within the audit threshold.
Figures



read the original abstract
Relay and reseller APIs increasingly intermediate access to large language models (LLMs), but users have no direct way to verify that a claimed endpoint is actually serving the advertised model. We introduce KBF, a low-cost black-box auditing protocol that fingerprints model APIs using stable numerical recall near the knowledge boundary. Across 16 production LLM endpoints, KBF flags all 155 economically relevant substitutions without rejecting any same-model controls, remains stable under deployment variation, detects high-separation mixed-routing attacks when only 5-10% of traffic is substituted, and finds that 7 of 27 platform model cells in a six-platform shadow API audit are statistically inconsistent with their reference endpoints, with inconsistencies concentrated on premium Claude endpoints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KBF, a black-box auditing protocol that fingerprints LLM APIs via numerical recall rates on fixed probes near the knowledge boundary. It reports that across 16 production endpoints the method flags all 155 economically relevant substitutions with zero false positives on same-model controls, remains stable under deployment variation, detects mixed-routing attacks at 5-10% substitution levels, and identifies statistical inconsistencies in 7 of 27 platform-model cells in a six-platform shadow audit (concentrated on premium Claude endpoints).
Significance. If the empirical stability and model-specificity claims hold, KBF supplies a low-cost, practical tool for verifying claimed LLM endpoints in the presence of relays and resellers—an increasingly relevant security and trust issue. The real-world audit results on 27 platform cells constitute concrete, falsifiable evidence of the method’s utility; the absence of free parameters or fitted models is a strength of the protocol as described.
major comments (3)
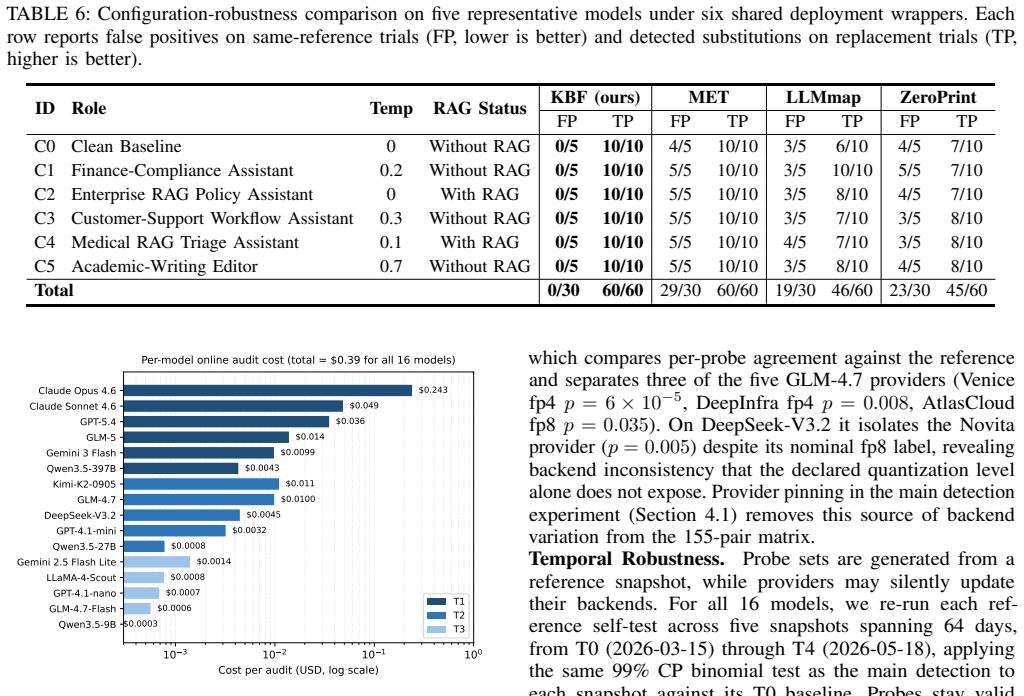
- [Abstract / stability results] Abstract and results on stability: the central claim that recall rates near the knowledge boundary function as a reliable, unique fingerprint requires that within-model variance (across deployments, prompts, or minor updates) remains smaller than inter-model separation. The manuscript states stability under deployment variation but supplies no explicit quantification or experiments on version updates or fine-tunes; this assumption is load-bearing for the auditing application and for the zero-false-positive claim on same-model controls.
- [Abstract] Abstract: the reported performance figures (155/155 detections, 0 false positives, 5-10% traffic detection) are presented without accompanying error bars, dataset definitions, probe-set construction details, or statistical tests. This prevents independent verification that the data support the stated claims and is load-bearing for the empirical validation of the method.
- [Audit results] Shadow-audit results (7/27 inconsistent cells): the claim of statistical inconsistency with reference endpoints requires a clear definition of the inconsistency test, threshold, and multiple-testing correction. Without these, it is unclear whether the concentration on premium Claude endpoints reflects a genuine finding or an artifact of the chosen metric.
minor comments (2)
- [Abstract] The abstract supplies numerical success rates but no methodological details; moving a concise methods paragraph or reference to the relevant section into the abstract would improve readability.
- [Method] Notation for the recall metric and probe-set construction should be defined once at first use and used consistently; current presentation leaves the exact numerical recall computation implicit.
Simulated Author's Rebuttal
Thank you for your thorough review and valuable feedback on our manuscript. We appreciate the recognition of KBF's potential utility for LLM API auditing. We address each of the major comments below and will incorporate revisions to improve the manuscript's clarity and completeness.
read point-by-point responses
-
Referee: [Abstract / stability results] Abstract and results on stability: the central claim that recall rates near the knowledge boundary function as a reliable, unique fingerprint requires that within-model variance (across deployments, prompts, or minor updates) remains smaller than inter-model separation. The manuscript states stability under deployment variation but supplies no explicit quantification or experiments on version updates or fine-tunes; this assumption is load-bearing for the auditing application and for the zero-false-positive claim on same-model controls.
Authors: We concur that quantifying within-model variance is crucial for validating the fingerprint reliability. The manuscript provides evidence through same-model controls showing no false positives across varied deployments and prompts. To address the gap on version updates and fine-tunes, the revised manuscript will include new experiments or analysis using available model version data to demonstrate that variance remains smaller than inter-model separation, thereby supporting the auditing claims. revision: yes
-
Referee: [Abstract] Abstract: the reported performance figures (155/155 detections, 0 false positives, 5-10% traffic detection) are presented without accompanying error bars, dataset definitions, probe-set construction details, or statistical tests. This prevents independent verification that the data support the stated claims and is load-bearing for the empirical validation of the method.
Authors: The full paper contains the probe-set construction details and dataset information in the methodology section. However, to enhance the abstract and results presentation, we will revise to include error bars (e.g., via bootstrap or binomial confidence intervals), explicit dataset sizes, and results of statistical tests (such as chi-square for detection rates) in the revised abstract or a supplementary results table. revision: yes
-
Referee: [Audit results] Shadow-audit results (7/27 inconsistent cells): the claim of statistical inconsistency with reference endpoints requires a clear definition of the inconsistency test, threshold, and multiple-testing correction. Without these, it is unclear whether the concentration on premium Claude endpoints reflects a genuine finding or an artifact of the chosen metric.
Authors: We agree that precise definition of the statistical procedure is necessary. The current manuscript implies inconsistency based on recall rate deviation from reference, but the revision will explicitly state the test (e.g., z-test against control mean and variance), the threshold used, and apply a multiple-testing correction such as Bonferroni to the 27 cells. This will confirm the robustness of the finding regarding Claude endpoints. revision: yes
Circularity Check
No significant circularity; empirical protocol with no derivations or self-referential fits.
full rationale
The paper describes KBF as a black-box auditing protocol relying on empirical measurement of numerical recall rates near the knowledge boundary across production endpoints. No equations, parameter fittings, uniqueness theorems, or derivation chains appear in the abstract or described claims. Results are presented as direct experimental outcomes (zero false positives on controls, detection at 5-10% substitution) rather than quantities forced by construction from inputs. The approach is self-contained against external benchmarks via reported measurements on 16 endpoints and 27 platform cells.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Real money, fake models: Deceptive model claims in shadow apis,
Y . Zhang, Y . Jiang, Z. Chen, M. Backes, X. Shen, and Y . Zhang, “Real money, fake models: Deceptive model claims in shadow apis,” arXiv preprint arXiv:2603.01919, 2026
-
[2]
I’m spartacus, no, i’m spartacus: Measuring and under- standing llm identity confusion,
K. Li, S. Zhuang, Y . Zhang, M. Xu, R. Wang, K. Xu, X. Fu, and X. Cheng, “I’m spartacus, no, i’m spartacus: Measuring and under- standing llm identity confusion,”arXiv preprint arXiv:2411.10683, 2024
-
[3]
Turning your weakness into a strength: Watermarking deep neural networks by backdooring,
Y . Adi, C. Baum, M. Cisse, B. Pinkas, and J. Keshet, “Turning your weakness into a strength: Watermarking deep neural networks by backdooring,” in27th USENIX security symposium (USENIX Security 18), 2018, pp. 1615–1631
2018
-
[4]
Hey, that’s my model! introduc- ing chain & hash, an llm fingerprinting technique,
M. Russinovich and A. Salem, “Hey, that’s my model! introduc- ing chain & hash, an llm fingerprinting technique,”arXiv preprint arXiv:2407.10887, 2024
-
[5]
Instruc- tional fingerprinting of large language models,
J. Xu, F. Wang, M. Ma, P. W. Koh, C. Xiao, and M. Chen, “Instruc- tional fingerprinting of large language models,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 3277–3306
2024
-
[6]
zkllm: Zero knowledge proofs for large language models,
H. Sun, J. Li, and H. Zhang, “zkllm: Zero knowledge proofs for large language models,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 4405–4419
2024
-
[7]
Telesparse: Practical privacy-preserving verification of deep neural networks,
M. M. Maheri, H. Haddadi, and A. Davidson, “Telesparse: Practical privacy-preserving verification of deep neural networks,”arXiv preprint arXiv:2504.19274, 2025
-
[8]
Immaculate: A practical llm auditing frame- work via verifiable computation,
Y . Guo, W. Qu, L. Wu, S. Zhai, L. Z. Wang, M. Xu, Y . Liu, B. Yuan, D. Song, and J. Zhang, “Immaculate: A practical llm auditing frame- work via verifiable computation,”arXiv preprint arXiv:2602.22700, 2026
-
[9]
Are robust llm fingerprints adversarially robust?
A. Nasery, E. Contente, A. Kaz, P. Viswanath, and S. Oh, “Are robust llm fingerprints adversarially robust?”arXiv preprint arXiv:2509.26598, 2025. [Online]. Available: https://arxiv.org/abs/ 2509.26598
-
[10]
Model equality testing: Which model is this api serving?
I. Gao, P. Liang, and C. Guestrin, “Model equality testing: Which model is this api serving?”arXiv preprint arXiv:2410.20247, 2024
-
[11]
Reading between the lines: Towards reliable black-box llm fingerprinting via zeroth-order gradient estimation,
S. Shao, Y . Li, H. Yao, Y . Chen, Y . Yang, and Z. Qin, “Reading between the lines: Towards reliable black-box llm fingerprinting via zeroth-order gradient estimation,” inProceedings of the ACM Web Conference 2026, 2026, pp. 2637–2648
2026
-
[12]
{LLMmap}: Fingerprinting for large language models,
D. Pasquini, E. M. Kornaropoulos, and G. Ateniese, “ {LLMmap}: Fingerprinting for large language models,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 299–318
2025
-
[13]
Fingerprinting LLMs via Prompt Injection
Y . Hu, Z. Jiang, M. Li, O. Ahmed, Z. Huang, C. Hong, and N. Gong, “Fingerprinting llms via prompt injection,”arXiv preprint arXiv:2509.25448, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Y . Mahajan, N. Bansal, and S. K. Karmaker, “The daunting dilemma with sentence encoders: Success on standard benchmarks, failure in capturing basic semantic properties,”arXiv preprint arXiv:2309.03747, 2023
-
[15]
Understanding zero-shot adversarial robustness for large-scale models,
C. Mao, S. Geng, J. Yang, X. Wang, and C. V ondrick, “Understanding zero-shot adversarial robustness for large-scale models,” inThe Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=P4bXCawRi5J
2023
-
[16]
Trusted execution environment: What it is, and what it is not,
M. Sabt, M. Achemlal, and A. Bouabdallah, “Trusted execution environment: What it is, and what it is not,” in2015 IEEE Trust- com/BigDataSE/Ispa, vol. 1. IEEE, 2015, pp. 57–64
2015
-
[17]
Slalom: Fast, Verifiable and Private Execution of Neural Networks in Trusted Hardware
F. Tramer and D. Boneh, “Slalom: Fast, verifiable and private execution of neural networks in trusted hardware,”arXiv preprint arXiv:1806.03287, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Rofl: Robust fingerprinting of language models,
Y .-Y . Tsai, C. Guo, J. Yang, and L. van der Maaten, “Rofl: Robust fingerprinting of language models,”arXiv preprint arXiv:2505.12682, 2025
-
[19]
Trap: Targeted random adversarial prompt honeypot for black-box identification,
M. Gubri, D. Ulmer, H. Lee, S. Yun, and S. J. Oh, “Trap: Targeted random adversarial prompt honeypot for black-box identification,” in Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 11 496–11 517
2024
-
[20]
Fdllm: A dedicated detector for black-box llms fingerprinting,
Z. Fu, J. Chen, L. Zhang, T. Yang, J. Niu, H. Sun, R. Li, P. Liu, J. Wang, F. Heet al., “Fdllm: A dedicated detector for black-box llms fingerprinting,” in2025 IEEE 24th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom). IEEE, 2025, pp. 1374–1379
2025
-
[21]
JPL Small-Body Database Lookup,
NASA Jet Propulsion Laboratory, “JPL Small-Body Database Lookup,” https://ssd.jpl.nasa.gov/tools/sbdb lookup.html, accessed May 9, 2026
2026
-
[22]
The On-Line Encyclopedia of Integer Sequences,
The OEIS Foundation Inc., “The On-Line Encyclopedia of Integer Sequences,” https://oeis.org/, accessed May 11, 2026
2026
-
[23]
Binomial test,
M. M. Wagner-Menghin, “Binomial test,”Encyclopedia of statistics in behavioral science, 2005
2005
-
[24]
Note on the sampling error of the difference between correlated proportions or percentages,
Q. McNemar, “Note on the sampling error of the difference between correlated proportions or percentages,”Psychometrika, vol. 12, no. 2, pp. 153–157, 1947
1947
-
[25]
A fingerprint for large language models,
Z. Yang and H. Wu, “A fingerprint for large language models,”arXiv preprint arXiv:2407.01235, 2024
-
[26]
Robust llm fingerprinting via domain-specific watermarks,
T. Gloaguen, R. Staab, N. Jovanovi ´c, and M. Vechev, “Robust llm fingerprinting via domain-specific watermarks,” inICML 2025 Workshop on Reliable and Responsible Foundation Models, 2025
2025
-
[27]
Evertracer: Hunting stolen large language models via stealthy and robust probabilistic fingerprint,
Z. Xu, M. Han, and W. Xing, “Evertracer: Hunting stolen large language models via stealthy and robust probabilistic fingerprint,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 7019–7042
2025
-
[28]
AttnDiff: Attention-based Differential Fingerprinting for Large Language Models
H. Zhang, Z. Xu, J. Li, S. Sheng, D. Kong, and M. Han, “Attndiff: Attention-based differential fingerprinting for large language models,” arXiv preprint arXiv:2604.05502, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Gradient-based model fingerprinting for llm similarity detection and family classification,
Z. Wu, Y . Zhao, and H. Wang, “Gradient-based model fingerprinting for llm similarity detection and family classification,”arXiv preprint arXiv:2506.01631, 2025
-
[30]
Every language model has a forgery-resistant signature,
M. Finlayson, X. Ren, and S. Swayamdipta, “Every language model has a forgery-resistant signature,”arXiv preprint arXiv:2510.14086, 2025
-
[31]
A watermark for large language models,
J. Kirchenbauer, J. Geiping, Y . Wen, J. Katz, I. Miers, and T. Goldstein, “A watermark for large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 17 061–17 084
2023
-
[32]
Scalable watermarking for identifying large language model outputs,
S. Dathathri, A. See, S. Ghaisas, P.-S. Huang, R. McAdam, J. Welbl, V . Bachani, A. Kaskasoli, R. Stanforth, T. Matejovicovaet al., “Scalable watermarking for identifying large language model outputs,” Nature, vol. 634, no. 8035, pp. 818–823, 2024. 18
2024
-
[33]
Semstamp: A semantic watermark with paraphrastic robustness for text generation,
A. Hou, J. Zhang, T. He, Y . Wang, Y .-S. Chuang, H. Wang, L. Shen, B. Van Durme, D. Khashabi, and Y . Tsvetkov, “Semstamp: A semantic watermark with paraphrastic robustness for text generation,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long ...
2024
-
[34]
Pmark: Towards robust and distortion-free semantic-level watermark- ing with channel constraints,
J. Huo, S. Liu, B. Wang, J. Zhang, Y . Yan, A. Liu, X. Hu, and M. Zhou, “Pmark: Towards robust and distortion-free semantic-level watermark- ing with channel constraints,”arXiv preprint arXiv:2509.21057, 2025
-
[35]
Your Agent Is Mine: Measuring Malicious Intermediary Attacks on the LLM Supply Chain
H. Liu, C. Shou, H. Wen, Y . Chen, R. J. Fang, and Y . Feng, “Your agent is mine: Measuring malicious intermediary attacks on the llm supply chain,”arXiv preprint arXiv:2604.08407, 2026. Appendix A. Experimental Setup This appendix records the request-side configuration used in the KBF pipeline. We focus on the parameters that affect probe content and aud...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Appendix C
We follow the public implementation and use Euclidean distance for the ranking computation. Appendix C. Shadow API Platform Mapping The box below lists the mapping from the shortened identifiers used in Section 4.7 to their salted SHA-256 digests. Shadow API platform mapping •Platform 1↔SH-87b19c56 •Platform 2↔SH-3c82a49c •Platform 3↔SH-4f754cc3 •Platform...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.