GUITestScape: Towards Open-set Evaluation on Exploratory GUI Testing
Pith reviewed 2026-06-29 06:46 UTC · model grok-4.3
The pith
GUIJudge decomposes exploratory GUI testing trajectories into diagnosable capabilities for open-set evaluation that outperforms annotation-bound methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
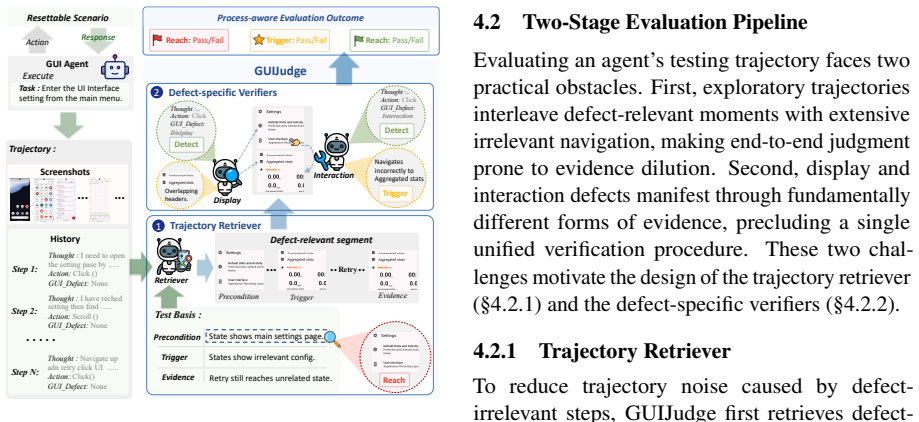
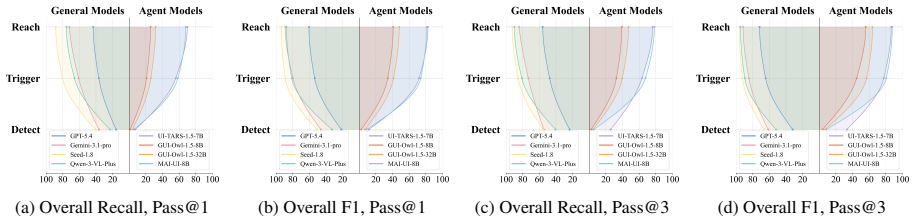
GUIJudge achieves reliable process-aware evaluation beyond predefined annotations, substantially outperforming all baselines. Benchmarking on GUITestScape reveals that detection remains the critical bottleneck for existing models across both defect types, and that integrating GUIJudge's verifiers into existing agents significantly boosts their detection performance without retraining.
What carries the argument
GUIJudge, an open-set evaluator that decomposes an agent's testing trajectory into independently diagnosable capabilities
If this is right
- Detection is the primary performance limiter for current models on both interaction and display defects.
- Adding GUIJudge verifiers raises detection performance of existing agents without any retraining.
- Evaluation can separate qualitatively different failure modes instead of reducing testing to a single end-state score.
- Benchmarks must include display defects alongside interaction defects to reflect realistic exploratory testing.
Where Pith is reading between the lines
- Similar trajectory decomposition could apply to other agent evaluation settings where intermediate steps matter more than final outcomes.
- Future work might test whether the same verifiers improve agents on entirely new application domains not seen in the 61-app set.
- Agents could be trained to internalize these capability checks rather than relying on post-hoc addition.
Load-bearing premise
The 508 preset defects across the 61 apps and the capability decomposition performed by GUIJudge are representative of real exploratory testing behavior and do not introduce selection bias that would make the reported gains specific to this benchmark.
What would settle it
A new collection of apps and defects outside the 508 presets on which GUIJudge's advantage shrinks or disappears, or on which adding its verifiers fails to improve agent detection rates.
Figures


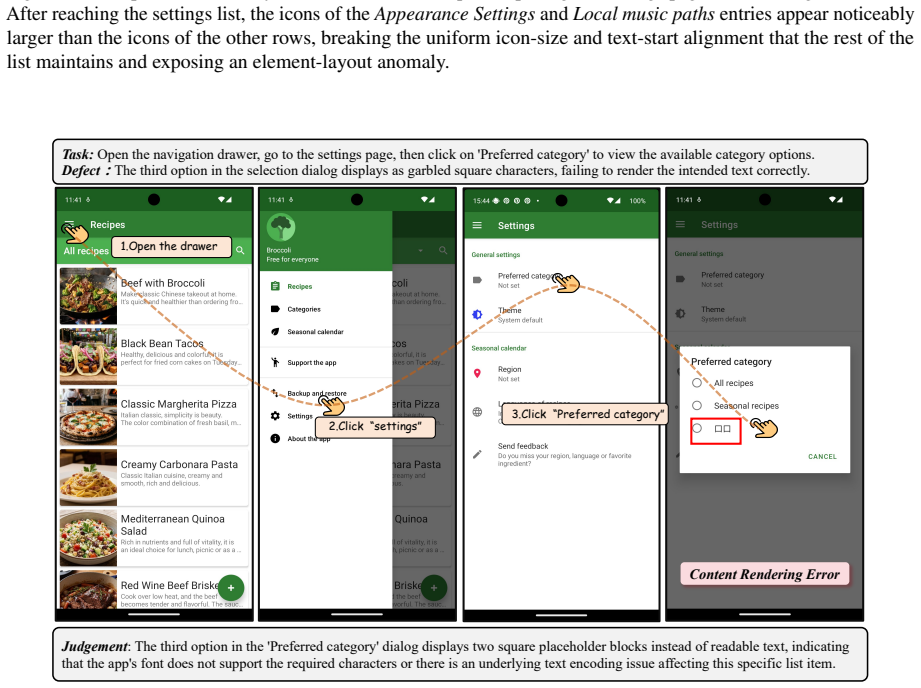
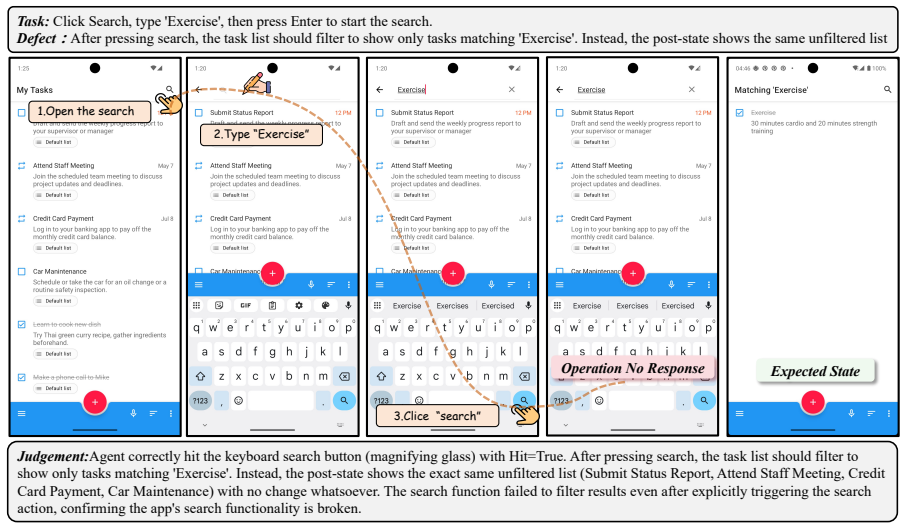

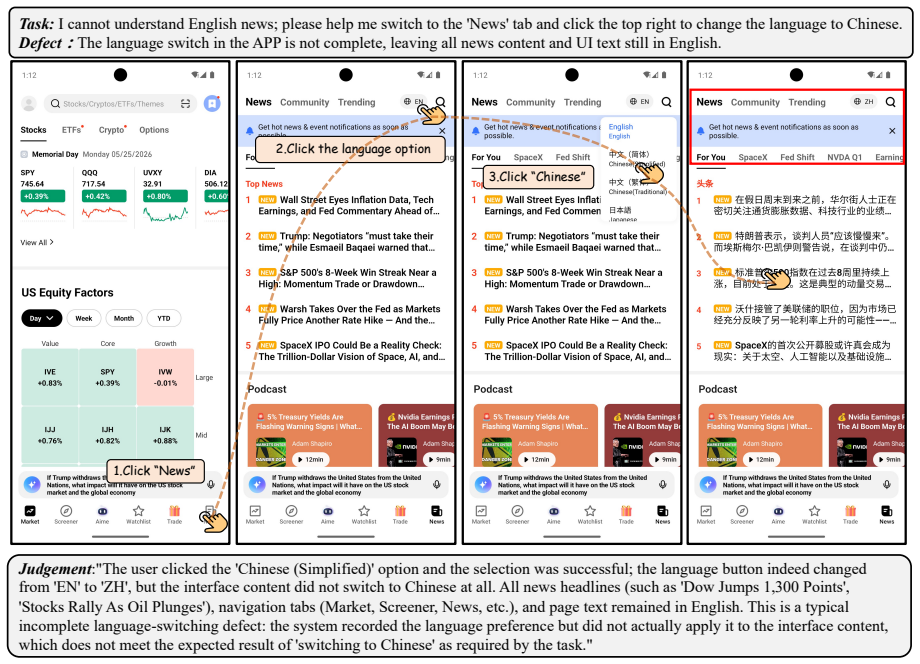
read the original abstract
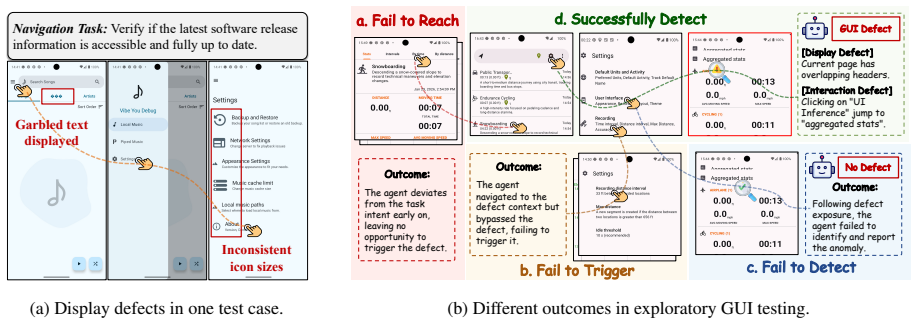
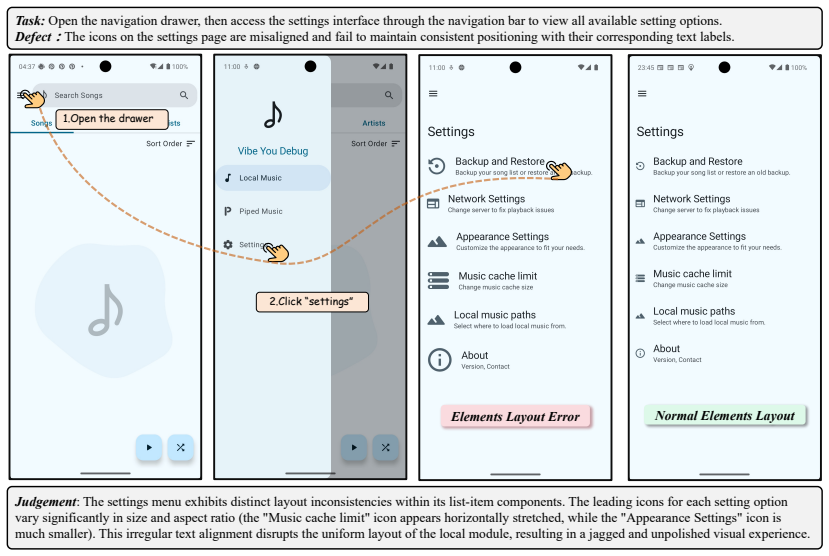
Exploratory GUI testing is a particularly demanding setting for MLLM agents: without predefined test scripts, an agent must autonomously navigate an application and discover defects through its own interaction. However, current evaluation falls short on two fronts. First, existing benchmarks focus almost exclusively on interaction defects, leaving display defects outside the evaluation frame. Second, evaluation protocols are bound to predefined defect annotations, collapsing the testing process into a single end-state judgment that conflates qualitatively distinct failure modes. To address these challenges, we present GUITestScape, an interactive benchmark covering 61 real-world Android applications and 508 preset defects spanning interaction and display types, and introduce GUIJudge, an open-set evaluator that decomposes an agent's testing trajectory into independently diagnosable capabilities. Experimental results demonstrate that GUIJudge achieves reliable process-aware evaluation beyond predefined annotations, substantially outperforming all baselines. Benchmarking on GUITestScape further reveals that detection remains the critical bottleneck for existing models across both defect types, and that integrating GUIJudge's verifiers into existing agents significantly boosts their detection performance without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GUITestScape, an interactive benchmark spanning 61 real-world Android applications and 508 preset defects of both interaction and display types, along with GUIJudge, an open-set evaluator that decomposes agent trajectories into independently diagnosable capabilities. It claims that GUIJudge enables reliable process-aware evaluation beyond predefined annotations and substantially outperforms baselines; benchmarking further shows detection as the critical bottleneck across defect types and that integrating GUIJudge verifiers boosts existing agents' detection performance without retraining.
Significance. If the experimental claims hold under rigorous validation, the work would advance evaluation methodology for MLLM agents in exploratory GUI testing by expanding beyond interaction-only and annotation-bound protocols, while offering a practical no-retraining improvement path. The identification of detection as bottleneck could usefully direct future agent development.
major comments (2)
- [Abstract / §3] Abstract and benchmark construction (likely §3): the central claims of reliable open-set evaluation, outperformance, detection bottleneck, and no-retraining gains rest on the assumption that the 508 preset defects and GUIJudge's capability decomposition are representative of real exploratory testing behavior; no independent validation, inter-rater agreement, or comparison to naturally occurring defects is described, leaving open the possibility that reported gains are benchmark-specific.
- [Abstract / §4] Experimental results (likely §4 and §5): the abstract asserts experimental superiority and bottleneck findings but the provided text supplies no information on experimental setup details, choice of baselines, statistical tests, variance across runs, or how the 508 defects were sampled/verified, preventing assessment of whether the support for the claims is adequate.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional rigor and clarity would strengthen the manuscript. We respond to each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and benchmark construction (likely §3): the central claims of reliable open-set evaluation, outperformance, detection bottleneck, and no-retraining gains rest on the assumption that the 508 preset defects and GUIJudge's capability decomposition are representative of real exploratory testing behavior; no independent validation, inter-rater agreement, or comparison to naturally occurring defects is described, leaving open the possibility that reported gains are benchmark-specific.
Authors: We agree that explicit validation of representativeness would strengthen the claims. Section 3 describes the curation of the 508 defects from 61 real-world Android apps, drawing on documented common defect patterns for both interaction and display types. However, no formal inter-rater agreement study or direct comparison against a corpus of naturally occurring defects was performed in the submitted version. In revision we will add a subsection detailing the multi-author verification process used during defect creation and will include a limited post-hoc comparison against a small set of real user-reported defects where feasible. The open-set design of GUIJudge is intended to mitigate benchmark-specificity by evaluating capability decomposition independently of the presets; the reported outperformance is measured on held-out trajectories within GUITestScape. revision: partial
-
Referee: [Abstract / §4] Experimental results (likely §4 and §5): the abstract asserts experimental superiority and bottleneck findings but the provided text supplies no information on experimental setup details, choice of baselines, statistical tests, variance across runs, or how the 508 defects were sampled/verified, preventing assessment of whether the support for the claims is adequate.
Authors: The reviewed version omitted explicit experimental details. The complete manuscript in Sections 4 and 5 specifies the baselines (standard MLLM agents plus rule-based and annotation-bound evaluators), reports results across multiple independent runs with variance, applies statistical significance testing, and states that all 508 defects were exhaustively included rather than sampled. We will expand the experimental setup subsection to present these elements clearly and comprehensively in the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a new benchmark (GUITestScape with 61 apps and 508 preset defects) and an evaluator (GUIJudge) that decomposes trajectories into capabilities. No equations, fitted parameters, predictions, or self-citations appear in the provided text that reduce any central claim to its own inputs by construction. Claims of outperformance and detection bottlenecks rest on experimental comparisons to baselines on the introduced benchmark, which is a standard non-circular approach for new evaluation frameworks. The representativeness concern is an external validity issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mind2Web: Towards a Generalist Agent for the Web
Mind2web: Towards a generalist agent for the web.Preprint, arXiv:2306.06070. Yifei Gao, Jiang Wu, Xiaoyi Chen, Yifan Yang, Zhe Cui, Tianyi Ma, Jiaming Zhang, and Jitao Sang. 2026a. Guitester: Enabling gui agents for exploratory defect discovery.Preprint, arXiv:2601.04500. Yifei Gao, Jiang Wu, Xiaoyi Chen, Yifan Yang, Zhe Cui, Tianyi Ma, Jiaming Zhang, and...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Ui-tars: Pioneering automated gui interac- tion with native agents, 2025.URL https://arxiv. org/abs/2501.12326. Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice 9 Li, William Bishop, Wei Li, Folawiyo Campbell- Ajala, Daniel Toyama, Robert Berry, Divya Tya- magundlu, Timothy Lillicrap, and Oriana Riva
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Androidworld: A dynamic benchmarking environment for autonomous agents.Preprint, arXiv:2405.14573. Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell- Ajala, and 1 others. Androidworld: A dynamic benchmarking environment for autonomous agents, 2024.URL ht...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
- Historical content serves as context only; old issues from previous steps must not be directly treated as defects of the current step
Judge only thecurrent step. - Historical content serves as context only; old issues from previous steps must not be directly treated as defects of the current step. - A defect can be attributed to the current step only when this step clearly caused, propagated and exposed, or reconfirmed the issue
-
[5]
Do not classify agent mistakes as app defects. - Clicking the wrong target, hit=false, input that does not satisfy the task requirements, missing required steps, misunderstanding the task, or never actually reaching the intended control is typicallynotan app interaction defect. - A defect can be assigned only when evidence shows thateven though the curren...
-
[6]
has_defect
Decide strictly based on evidence. - Use only the provided textual trace and the current step’spre/postscreenshots. - Do not speculate about hidden flows, background states, undisplayed toasts, or network results that were not provided. Step Number Rules - If a defect is identified,stepmust be the step number of the current step under verification. - If n...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.