SCOPE: A Lightweight-training LLM Framework for Air Traffic Control Readback Monitoring
Pith reviewed 2026-06-29 08:43 UTC · model grok-4.3
The pith
A frozen LLM with plug-in classifier detects ATC readback anomalies at 91% accuracy in few-shot settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
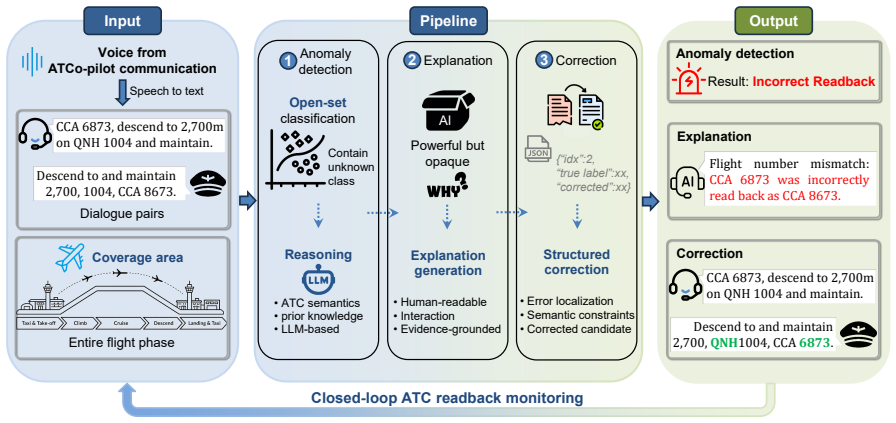
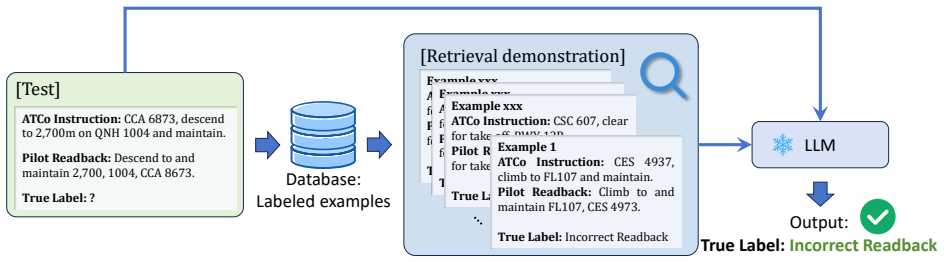
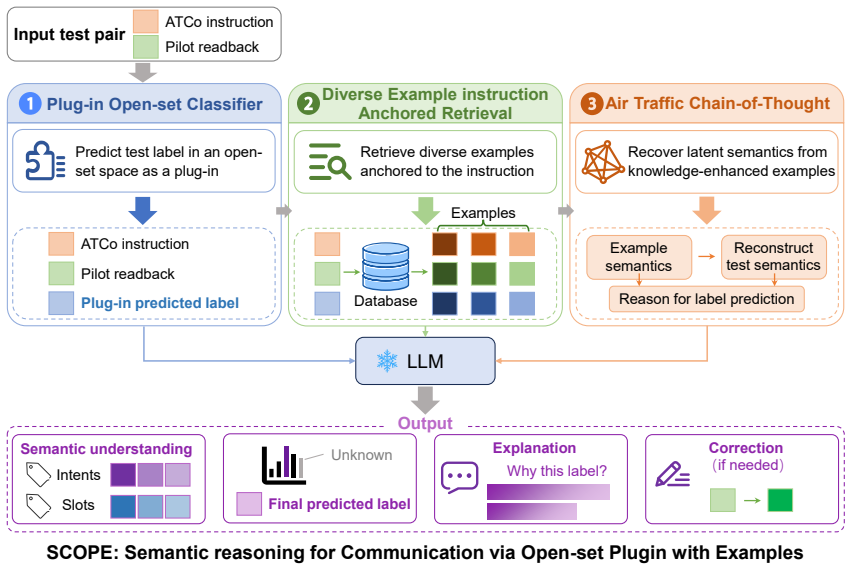
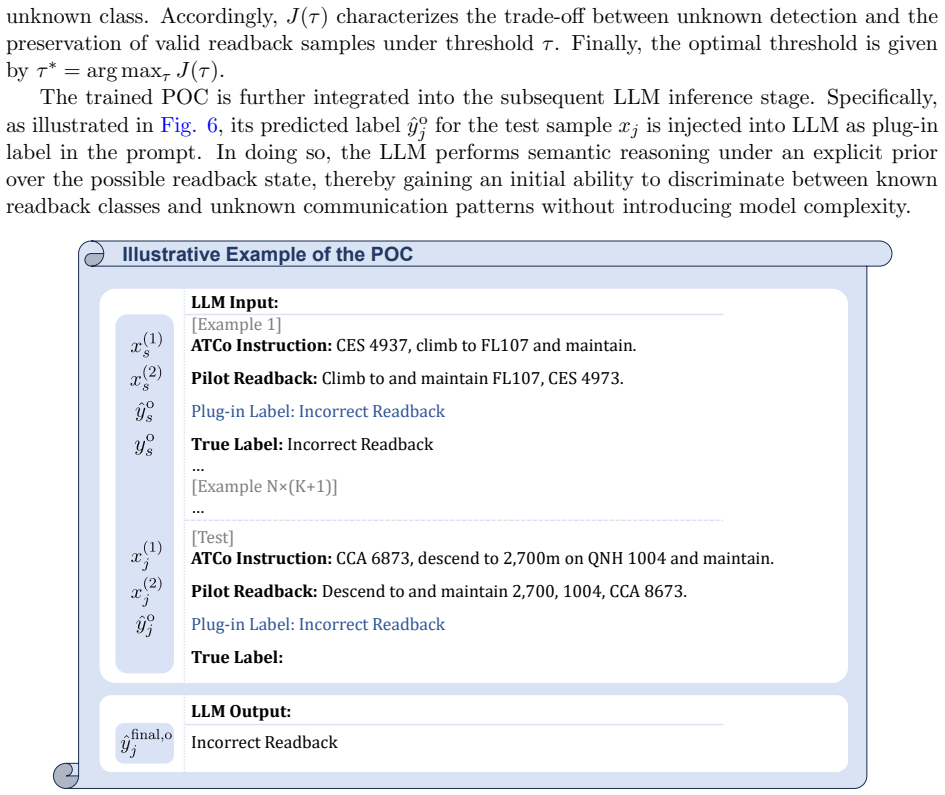
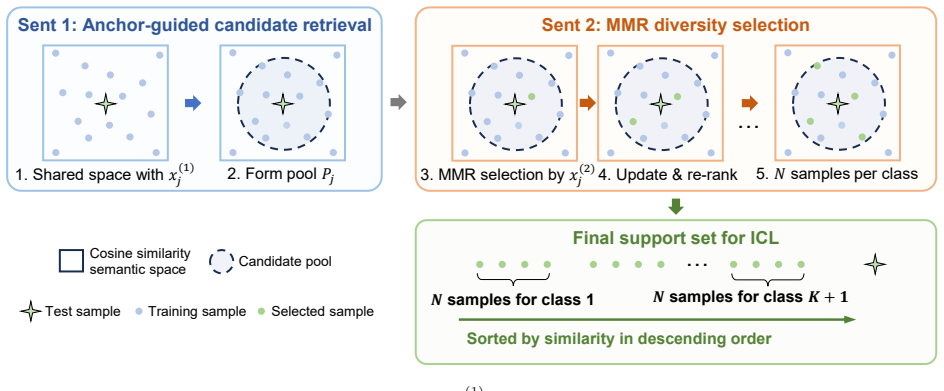
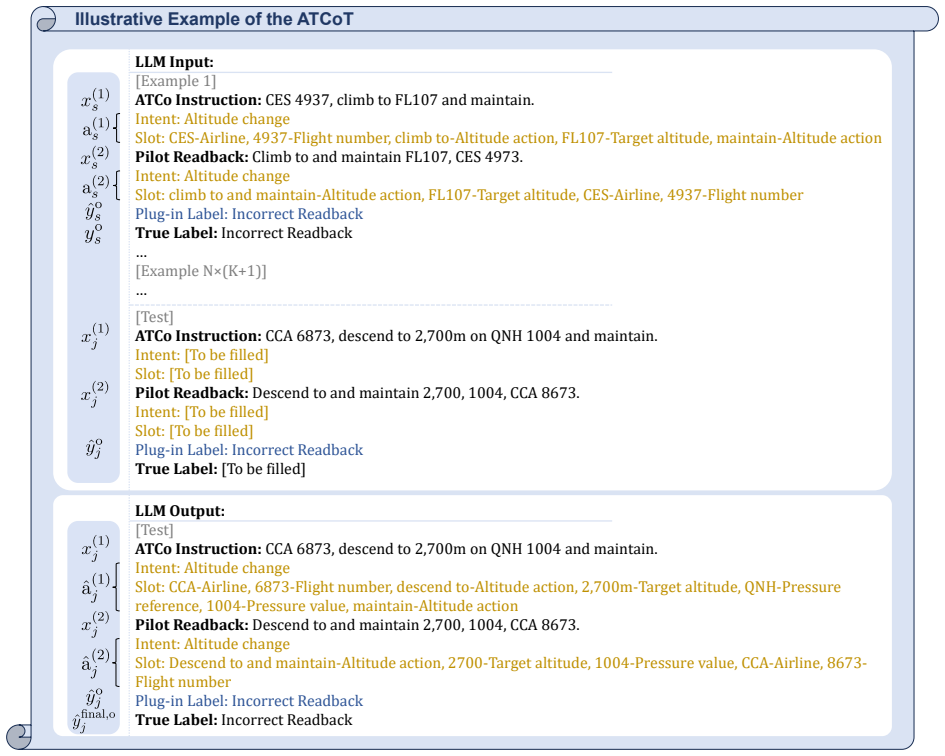
SCOPE advances machine-based ATC readback monitoring by coupling a plug-in open-set classifier with a carefully designed in-context learning mechanism on top of a frozen LLM. On the semi-synthetic communication dataset, it reaches 91.05% accuracy in open-set detection and corrects 96.63% of anomalous readbacks under few-shot conditions, outperforming the strongest baselines while supplying explanations for its outputs.
What carries the argument
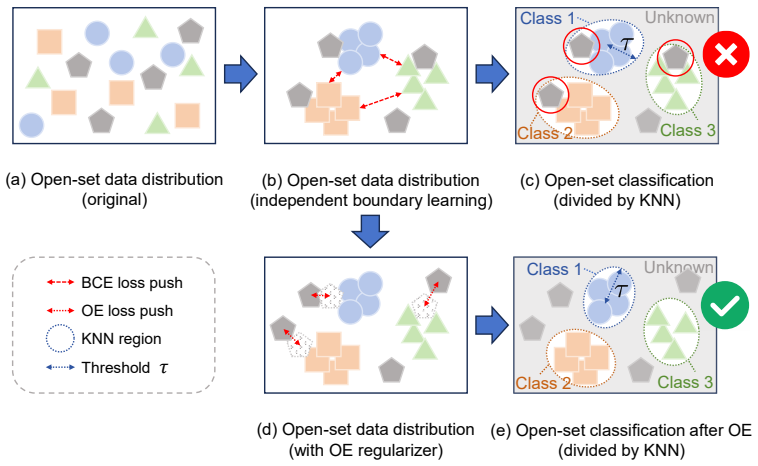
The plug-in open-set classifier paired with in-context learning on a frozen LLM, which handles anomaly detection and correction without updating model weights.
If this is right
- The framework delivers low-latency responses required for operational ATC environments.
- It supplies explanations alongside each detection and correction decision.
- It generalizes across evolving phraseology better than rule-based or traditional machine learning methods.
- It offers a practical route to interpretable and controllable readback monitoring systems.
Where Pith is reading between the lines
- Real-time integration with voice transcription could enable immediate alerts during live controller-pilot exchanges.
- Dynamic updating of the in-context examples might let the system track new phraseology without any retraining step.
- The same plug-in pattern could transfer to other high-stakes spoken communication domains that need open-set anomaly handling.
- Performance on live operational logs would directly test whether the reported rates reduce actual miscommunication incidents.
Load-bearing premise
The semi-synthetic communication dataset accurately captures the variability, phraseology, and anomaly patterns of real-world air traffic controller-pilot voice communications so that performance on it predicts operational effectiveness.
What would settle it
Running the same few-shot evaluation on a collection of actual recorded and transcribed ATC communications and measuring detection accuracy well below 91% or correction rates well below 96%.
Figures




read the original abstract
Pilot readback of Air Traffic Control (ATC) voice instructions is a primary safeguard against miscommunication in air transportation. However, readback anomalies remain implicated in approximately 80% of aviation incidents. This vulnerability is further exacerbated by rising traffic volume and elevated cognitive workload, thereby motivating automated readback monitoring by machine. Traditional rule-based and machine learning approaches struggle to generalize across the highly variable and evolving phraseology of air traffic controller-pilot communications. While Large Language Models (LLMs) have opened a new avenue through their strong reasoning and generalization capabilities, existing approaches still face deployment and computational barriers in practice. In this work, we propose Semantic reasoning for Communication via Open-set Plug-in with Examples (SCOPE), a novel lightweight-training LLM framework that advances both the efficiency and accuracy of machine-based ATC readback monitoring. The core idea is to couple a plug-in open-set classifier with a carefully designed in-context learning mechanism on top of a frozen LLM. Extensive experiments on the semi-synthetic communication dataset show that SCOPE attains superior accuracy while delivering the low-latency response required for operational environments. Under a few-shot setting, SCOPE achieves 91.05% accuracy in open-set detection and corrects 96.63% of anomalous readbacks, thereby outperforming the strongest available baselines while providing explanations for its decisions. These findings demonstrate the potential of our framework as a practical pathway toward interpretable and controllable ATC readback monitoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SCOPE, a lightweight-training LLM framework for ATC readback monitoring that couples a plug-in open-set classifier with in-context learning on a frozen LLM. It reports that, on a semi-synthetic communication dataset under few-shot settings, SCOPE achieves 91.05% accuracy in open-set detection and corrects 96.63% of anomalous readbacks while outperforming baselines and providing decision explanations, positioning the approach as a practical pathway toward interpretable ATC monitoring.
Significance. If the semi-synthetic results hold under real operational conditions, the framework could meaningfully advance automated safeguards against the miscommunications implicated in ~80% of aviation incidents by combining LLM generalization with low-latency, explainable inference and minimal training overhead.
major comments (2)
- [Abstract] Abstract: The headline performance figures (91.05% open-set accuracy, 96.63% anomaly correction) are obtained exclusively on a semi-synthetic dataset, yet the manuscript provides no description of the generation process, the distribution of phraseology, prosody, accents, noise, or anomaly types, nor any statistical validation against real ATC recordings. Because the central operational claim—that the framework offers a 'practical pathway'—rests on the assumption that this dataset reproduces live controller-pilot variability, the absence of such details renders the transferability of the reported metrics unassessable.
- [Abstract] Abstract / motivation section: The paper acknowledges that real ATC phraseology is 'highly variable and evolving,' yet the experimental claims are framed as direct evidence of operational readiness without any real-data validation, cross-domain testing, or sensitivity analysis to dataset-construction choices. This gap directly affects the strength of the generalization and practicality assertions.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency on the semi-synthetic dataset and for cautioning against overstatement of operational readiness. We will revise the manuscript to supply the requested dataset details and to moderate the generalization claims accordingly. The core technical contribution of the SCOPE framework remains intact, but we accept that the current presentation requires clarification on these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance figures (91.05% open-set accuracy, 96.63% anomaly correction) are obtained exclusively on a semi-synthetic dataset, yet the manuscript provides no description of the generation process, the distribution of phraseology, prosody, accents, noise, or anomaly types, nor any statistical validation against real ATC recordings. Because the central operational claim—that the framework offers a 'practical pathway'—rests on the assumption that this dataset reproduces live controller-pilot variability, the absence of such details renders the transferability of the reported metrics unassessable.
Authors: We agree that a detailed description of the semi-synthetic dataset construction is missing and should be added. In the revised manuscript we will insert a dedicated subsection (likely in Section 3 or 4) that specifies: (i) the rule-based and LLM-assisted generation pipeline, (ii) the phraseology templates drawn from ICAO Doc 4444 and regional variations, (iii) the controlled injection of prosody, accent, and background noise models, (iv) the taxonomy and frequency distribution of anomaly types, and (v) any quantitative alignment statistics computed against a small held-out set of real ATC recordings. These additions will enable readers to evaluate transferability directly. We do not claim the semi-synthetic data fully substitutes for live operational data; the revision will make this explicit. revision: yes
-
Referee: [Abstract] Abstract / motivation section: The paper acknowledges that real ATC phraseology is 'highly variable and evolving,' yet the experimental claims are framed as direct evidence of operational readiness without any real-data validation, cross-domain testing, or sensitivity analysis to dataset-construction choices. This gap directly affects the strength of the generalization and practicality assertions.
Authors: We accept the criticism that the current wording in the abstract and motivation section overstates the immediate operational implications. In revision we will (a) replace phrases such as “practical pathway toward interpretable and controllable ATC readback monitoring” with more qualified language that ties the reported metrics explicitly to the semi-synthetic regime, (b) add a paragraph in the discussion section that outlines the limitations of semi-synthetic evaluation and the necessity of future real-data and cross-domain studies, and (c) include a brief sensitivity analysis (varying anomaly injection rates and noise levels) to demonstrate robustness to dataset-construction choices. These changes will align the claims with the evidence presented. revision: partial
Circularity Check
No circularity: empirical results on semi-synthetic data with no derivations or self-referential constructions
full rationale
The paper reports experimental accuracy metrics (91.05% open-set detection, 96.63% anomaly correction) as direct outcomes of applying the SCOPE framework to a semi-synthetic dataset. No equations, derivations, or parameter-fitting steps are described that reduce to the inputs by construction. The abstract and provided text contain no self-definitional claims, fitted-input predictions, or load-bearing self-citations that would create circularity. The dataset representativeness is an external assumption (not a definitional loop), so the reported numbers do not qualify as circular under the enumerated patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
SCOPE framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abdin, M., Aneja, J., Behl, H., Bubeck, S., Eldan, R., Gunasekar, S., Harrison, M., Hewett, R. J., Javaheripi, M., Kauffmann, P. et al. (2024). Phi-4 technical report. arXiv:2412.08905. Amodei, D., Ananthanarayanan, S., Anubhai, R., Bai, J., Battenberg, E., Case, C., Casper, J., Catanzaro, B., Cheng, Q., Chen, G. et al. (2016). Deep speech 2: End-to-end s...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Bendale, A., & Boult, T. E. (2016). Towards open set deep networks. InProceedings of the IEEE conference on computer vision and pattern recognition(pp. 1563–1572). Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R....
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019). BERT: pre-training of deep bidirectional transformers for language understanding. In J. Burstein, C. Doran, & T. Solorio (Eds.),Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, ...
2019
-
[4]
S., Prasad, A., Motlicek, P., Vesel` y, K
Helmke, H., Kleinert, M., Shetty, S., Ohneiser, O., Ehr, H., Aril´ ıusson, H., Simiganoschi, T. S., Prasad, A., Motlicek, P., Vesel` y, K. et al. (2021). Readback error detection by automatic speech recognition to increase atm safety. In Proceedings of the fourteenth USA/Europe air traffic management research and development seminar (ATM2021), virtual eve...
2021
-
[5]
A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
Morgan Kaufmann. Hendrycks, D., & Gimpel, K. (2016). A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv:1610.02136. Hendrycks, D., Mazeika, M., & Dietterich, T. G. (2019). Deep anomaly detection with outlier exposure. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA,...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Hui, Y., Yang, Y., Qian, S., & Cai, K
OpenReview.net. Hui, Y., Yang, Y., Qian, S., & Cai, K. (2025). Knowledge-augmented encoder for few-shot deep intent recognition in air traffic control.Knowledge-Based Systems,320, 113524. International Civil Aviation Organization (1998).Human Factors Training Manual. International Civil Aviation Organization (1st ed.). ICAO Doc 9683 AN/950. International ...
2025
-
[7]
Decoupled Weight Decay Regularization
International Civil Aviation Organization (2016).Procedures for Air Navigation Services — Air Traffic Manage- ment (PANS-ATM). ICAO Doc 4444, 16th Edition ICAO Montr´ eal, Canada.https://store.icao.int/en/ procedures-for-air-navigation-services-air-traffic-management-doc-4444. International Civil Aviation Organization (2021).Airborne Collision Avoidance S...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[8]
Nielsen, D., Clarke, S
Technical Report DCA25MA108 National Transportation Safety Board. Nielsen, D., Clarke, S. S., & Kalyanam, K. M. (2024). Towards an aviation large language model by fine-tuning and evaluating transformers. In2024 AIAA DATC/IEEE 43rd Digital Avionics Systems Conference (DASC)(pp. 1–5). IEEE. OpenAI (2026). Gpt-5.3 instant system card. Published March 3, 202...
2024
-
[9]
33 Panayotov, V., Chen, G., Povey, D., & Khudanpur, S. (2015). Librispeech: an asr corpus based on public domain audio books. In2015 IEEE international conference on acoustics, speech and signal processing (ICASSP)(pp. 5206–5210). IEEE. Pang, Y., Paul Kendall, A., Porcayo, A., Barsotti, M., Jain, A., & Clarke, J.-P. (2026). From voice to safety: Lan- guag...
-
[10]
Wu, Q., Molesworth, B. R., & Estival, D. (2019). An investigation into the factors that affect miscommunication between pilots and air traffic controllers in commercial aviation.The international journal of aerospace psychology, 29, 53–63. Xu, C., Xu, Y., Wang, S., Liu, Y., Zhu, C., & McAuley, J. J. (2024). Small models are valuable plug-ins for large lan...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[11]
Youden, W. J. (1950). Index for rating diagnostic tests.Cancer,3, 32–35. Zhang, J., Zhang, P., Guo, D., Zhou, Y., Wu, Y., Yang, B., & Lin, Y. (2022). Automatic repetition instruction generation for air traffic control training using multi-task learning with an improved copy network.Knowledge- Based Systems,241, 108232. Zhang, M., Yang, Y., Qian, S., Deng,...
1950
-
[12]
Zhu, Z., Huang, P., Huang, H., Xu, Y., Lin, P., Lao, L., Chen, S., Xie, H., & Yin, S. (2024b). ELSF: entity-level slot filling framework for joint multiple intent detection and slot filling.IEEE ACM Trans. Audio Speech Lang. Process.,32, 4880–4893. Zuluaga-Gomez, J., Nigmatulina, I., Prasad, A., Motlicek, P., Khalil, D., Madikeri, S., Tart, A., Szoke, I.,...
2023
-
[13]
Zuluaga-Gomez, J., Vesel` y, K., Sz¨ oke, I., Blatt, A., Motlicek, P., Kocour, M., Rigault, M., Choukri, K., Prasad, A., Sarfjoo, S. S. et al. (2022). Atco2 corpus: A large-scale dataset for research on automatic speech recognition and natural language understanding of air traffic control communications. arXiv:2211.04054. 35
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.