SuperVoxelGPT: Adaptive and Ordered 3D Tokenization for Autoregressive Shape Generation
Pith reviewed 2026-06-29 08:49 UTC · model grok-4.3
The pith
Adaptive supervoxel tokenization cuts 3D sequence lengths to 12.8% of uniform voxels for autoregressive generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
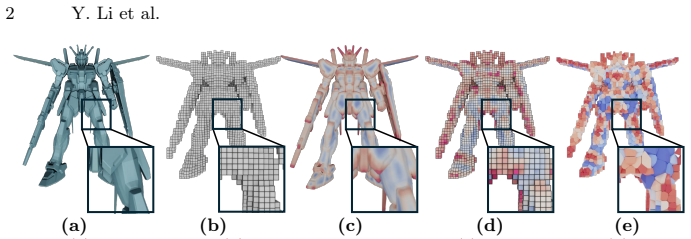
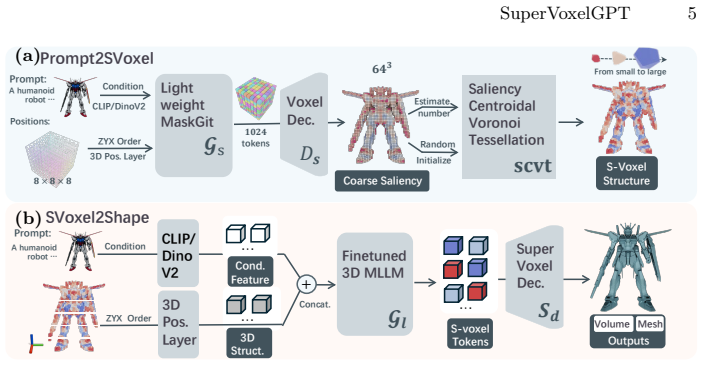
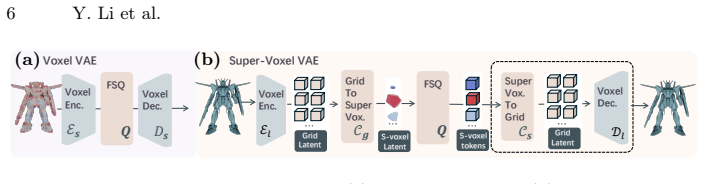
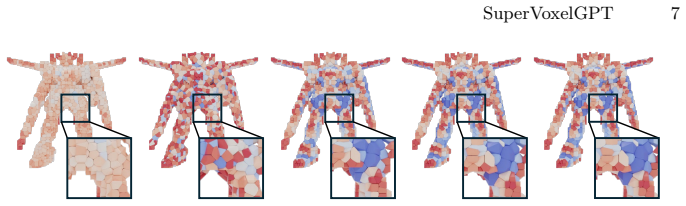
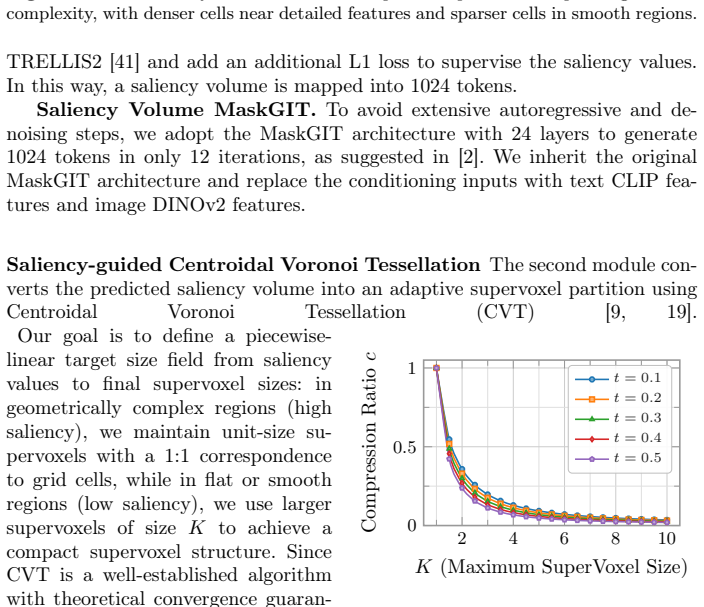
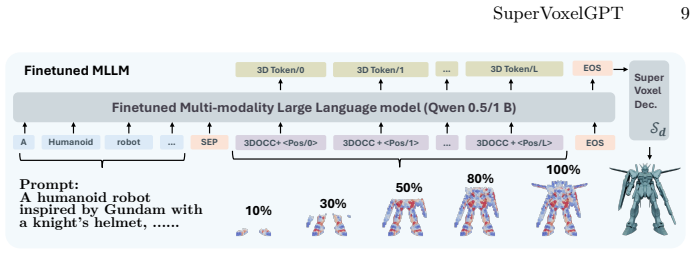
SuperVoxelGPT resolves the structural trade-off between set-based and grid-based 3D tokenizations through adaptive and deterministically ordered supervoxel tokenization. Given a prompt, a coarse geometric saliency distribution is predicted and used to drive saliency-guided centroidal Voronoi tessellation that allocates fine-grained cells to complex regions and larger cells to smooth regions. The resulting compact, ordered supervoxel layout is encoded by a SuperVoxelVAE and generated autoregressively by a fine-tuned pretrained MLLM.
What carries the argument
saliency-guided centroidal Voronoi tessellation that produces shape-adaptive supervoxel partitions with deterministic ordering
If this is right
- Token sequence length is reduced to 12.8% of uniform voxel tokenization
- State-of-the-art generation quality is achieved on Trellis-500K
- An average 10x speedup is obtained over prior methods
- Autoregressive prediction proceeds stably without ordering ambiguities
Where Pith is reading between the lines
- The same adaptive partitioning could be applied to point-cloud or mesh inputs to test whether sequence-length reductions transfer to other 3D modalities.
- Replacing the separate saliency-prediction stage with a fully end-to-end learned module might further reduce preprocessing overhead.
- The fixed ordering property could support direct concatenation of supervoxel sequences with 2D image token streams for joint multimodal training.
Load-bearing premise
That a coarse geometric saliency distribution predicted from the prompt can be used to drive centroidal Voronoi tessellation into a shape-adaptive supervoxel partition whose resulting token sequence is both compact and deterministically ordered enough for stable autoregressive prediction without introducing new ambiguities.
What would settle it
If autoregressive models trained on the resulting supervoxel sequences exhibit higher inconsistency or lower shape quality than equivalent models trained on uniform voxel sequences, the claim that the adaptive partitions preserve sufficient structure would be refuted.
Figures


read the original abstract
Autoregressive multimodal large language models (MLLMs) enable 3D generation but struggle to scale to high-resolution shapes due to inadequate 3D tokenizations. Compact set-based representations discard deterministic spatial ordering, leading to ambiguous sequence prediction, while uniform or octree-based voxel grids preserve ordering at the cost of severe redundancy and excessively long sequences. This structural trade-off limits stable and efficient autoregressive 3D generation. We present SuperVoxelGPT, a representation-first framework that resolves this tension through adaptive and deterministically ordered supervoxel tokenization. Given a prompt, we first predict a coarse geometric saliency distribution and construct a shape-adaptive supervoxel partition using saliency-guided centroidal Voronoi tessellation, allocating fine-grained cells to complex regions and larger cells to smooth regions. Conditioned on the text and ordered supervoxel layout, we introduce a SuperVoxelVAE and fine-tune a pretrained MLLM to autoregressively generate supervoxel tokens. Experiments on Trellis-500K show that SuperVoxelGPT reduces token sequence length to 12.8% of uniform voxel tokenization while achieving state-of-the-art generation quality and an average 10$\times$ speedup over prior methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SuperVoxelGPT, a framework for 3D shape generation that addresses limitations in existing tokenizations for autoregressive MLLMs. It predicts a coarse geometric saliency from the prompt, uses saliency-guided centroidal Voronoi tessellation to create adaptive supervoxels (finer in complex regions), imposes a deterministic order on the cells, and then uses a SuperVoxelVAE and fine-tuned MLLM to generate the token sequence autoregressively. On the Trellis-500K dataset, it claims a reduction in token sequence length to 12.8% of uniform voxel tokenization, state-of-the-art generation quality, and an average 10x speedup.
Significance. If the results are substantiated, this approach could significantly improve the scalability of autoregressive 3D generation by providing a compact yet ordered representation that avoids the ambiguities of set-based methods and the redundancy of grid-based ones. The adaptive allocation of resolution based on saliency is a promising direction for efficient high-resolution modeling.
major comments (2)
- [Abstract and Experiments] The quantitative claims (12.8% token length, SOTA quality, 10x speedup on Trellis-500K) are presented without any supporting tables, baseline comparisons, ablation studies, dataset statistics, or error bars, making it impossible to evaluate whether the data support the central claims.
- [Method (saliency-guided CVT and ordering)] The deterministic ordering of supervoxel tokens is derived from a learned saliency prediction followed by CVT; the manuscript provides no analysis, perturbation tests, or ablations demonstrating that the resulting sequence order is stable under small variations in the predicted saliency map. This stability is load-bearing for the claim that the representation avoids introducing new ambiguities for autoregressive prediction.
minor comments (1)
- [Abstract] The abstract refers to 'Trellis-500K' without a citation or brief description of the dataset.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and describe the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] The quantitative claims (12.8% token length, SOTA quality, 10x speedup on Trellis-500K) are presented without any supporting tables, baseline comparisons, ablation studies, dataset statistics, or error bars, making it impossible to evaluate whether the data support the central claims.
Authors: We agree that the abstract and current Experiments section do not include the detailed supporting evidence needed to substantiate the claims. In the revised manuscript we will expand the Experiments section to include full tables with baseline comparisons, ablation studies on key components, dataset statistics for Trellis-500K, and error bars computed over multiple runs, thereby providing the necessary quantitative support for the reported token-length reduction, generation quality, and speedup. revision: yes
-
Referee: [Method (saliency-guided CVT and ordering)] The deterministic ordering of supervoxel tokens is derived from a learned saliency prediction followed by CVT; the manuscript provides no analysis, perturbation tests, or ablations demonstrating that the resulting sequence order is stable under small variations in the predicted saliency map. This stability is load-bearing for the claim that the representation avoids introducing new ambiguities for autoregressive prediction.
Authors: We concur that empirical verification of ordering stability under saliency variations is important to support the autoregressive modeling claim. In the revision we will add a dedicated analysis subsection containing perturbation tests: small controlled variations will be introduced to the predicted saliency maps, after which we will quantify changes in the resulting CVT partitions and token sequences using appropriate stability metrics, together with qualitative examples. revision: yes
Circularity Check
No significant circularity; derivation is self-contained.
full rationale
The paper presents a new representation (saliency-guided CVT supervoxel partition + SuperVoxelVAE + MLLM fine-tuning) whose claimed benefits (shorter sequences, stable AR ordering, SOTA quality) are not shown to reduce by construction to fitted inputs or prior self-citations. The abstract and method description treat the tokenization as an independent design choice rather than a re-expression of existing quantities. No equations or steps equate the output ordering or performance to the input saliency prediction by definition. This is the expected non-finding for a representation-first paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- saliency prediction network parameters
axioms (1)
- domain assumption Centroidal Voronoi tessellation on a saliency field produces a deterministically ordered supervoxel layout suitable for autoregressive modeling
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.12451 (2024)
Caffagni, D., Cocchi, F., Barsellotti, L., Moratelli, N., Sarto, S., Baraldi, L., Cornia, M., Cucchiara, R.: The revolution of multimodal large language models: a survey. arXiv preprint arXiv:2402.12451 (2024)
-
[2]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chang, H., Zhang, H., Jiang, L., Liu, C., Freeman, W.T.: Maskgit: Masked genera- tive image transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11315–11325 (2022)
2022
-
[3]
arXiv preprint arXiv:2503.20519 (2025)
Chen, J., Zhu, L., Hu, Z., Qian, S., Chen, Y., Wang, X., Lee, G.H.: Mar-3d: Pro- gressive masked auto-regressor for high-resolution 3d generation. arXiv preprint arXiv:2503.20519 (2025)
-
[4]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, R., Zhang, J., Liang, Y., Luo, G., Li, W., Liu, J., Li, X., Long, X., Feng, J., Tan, P.: Dora: Sampling and benchmarking for 3d shape variational auto-encoders. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16251–16261 (2025)
2025
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Chen, Y., Wang, Y., Luo, Y., Wang, Z., Chen, Z., Zhu, J., Zhang, C., Lin, G.: Meshanything v2: Artist-created mesh generation with adjacent mesh tokenization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 13922–13931 (2025)
2025
-
[6]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, Y., Lan, Y., Zhou, S., Wang, T., Pan, X.: Sar3d: Autoregressive 3d object generation and understanding via multi-scale 3d vqvae. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 28371–28382 (2025)
2025
-
[7]
In: ICLR (2024)
Delétang, G., Ruoss, A., Duquenne, P.A., Catt, E., Genewein, T., Mattern, C., Grau-Moya, J., Wenliang, L.K., Aitchison, M., Orseau, L., Hutter, M., Veness, J.: Language modeling is compression. In: ICLR (2024)
2024
-
[8]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Deng, K., Liu, H.T.D., Zhu, Y., Sun, X., Shang, C., Bhat, K.S., Ramanan, D., Zhu, J.Y., Agrawala, M., Zhou, T.: Efficient autoregressive shape generation via octree-based adaptive tokenization. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 11685–11696 (2025)
2025
-
[9]
SIAM review41(4), 637–676 (1999)
Du, Q., Faber, V., Gunzburger, M.: Centroidal voronoi tessellations: Applications and algorithms. SIAM review41(4), 637–676 (1999)
1999
-
[10]
Numerical Mathematics: Theory, Methods and Applications 3(2), 119–142 (2010)
Du, Q., Gunzburger, M., Ju, L.: Advances in studies and applications of centroidal voronoi tessellations. Numerical Mathematics: Theory, Methods and Applications 3(2), 119–142 (2010)
2010
-
[11]
Fan, H., Su, H., Guibas, L.J.: A point set generation network for 3d object recon- structionfromasingleimage.In:ProceedingsoftheIEEEConferenceonComputer Vision and Pattern Recognition. pp. 605–613 (2017)
2017
-
[12]
arXiv preprint arXiv:2503.21732 (2025)
He, X., Zou, Z.X., Chen, C.H., Guo, Y.C., Liang, D., Yuan, C., Ouyang, W., Cao, Y.P., Li, Y.: Sparseflex: High-resolution and arbitrary-topology 3d shape modeling. arXiv preprint arXiv:2503.21732 (2025)
-
[13]
arXiv preprint arXiv:2511.00763 (2025)
Hou, W., Zhou, L., Hu, H.Y., Chen, Y., You, Y.Z., Qi, X.L.: How focused are llms? a quantitative study via repetitive deterministic prediction tasks. arXiv preprint arXiv:2511.00763 (2025)
-
[14]
Qwen2.5-Coder Technical Report
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al.: Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
arxiv preprint arXiv:2512.21185 (2025) 16 Y
Jia, T., Yan, D., Hao, D., Li, Y., Zhang, K., He, X., Li, L., Chen, J., Jiang, L., Yin, Q., Quan, L., Chen, Y.C., Yuan, L.: Ultrashape 1.0: High-fidelity 3d shape gener- ation via scalable geometric refinement. arxiv preprint arXiv:2512.21185 (2025) 16 Y. Li et al
-
[16]
low-resource
Jiang, Z., Yang, M., Tsirlin, M., Tang, R., Dai, Y., Lin, J.: “low-resource” text classification: A parameter-free classification method with compressors. In: Find- ings of the Association for Computational Linguistics: ACL 2023. pp. 6810–6828. Association for Computational Linguistics (2023)
2023
-
[17]
Hunyuan3D 2.5: Towards High-Fidelity 3D Assets Generation with Ultimate Details
Lai, Z., Zhao, Y., Liu, H., Zhao, Z., Lin, Q., Shi, H., Yang, X., Yang, M., Yang, S., Feng, Y., et al.: Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details. arXiv preprint arXiv:2506.16504 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
In: ACM SIGGRAPH 2005 Papers, pp
Lee, C.H., Varshney, A., Jacobs, D.W.: Mesh saliency. In: ACM SIGGRAPH 2005 Papers, pp. 659–666 (2005)
2005
-
[19]
ACM Transactions on Graphics (TOG)29(4), 1–11 (2010)
Lévy, B., Liu, Y.: L p centroidal voronoi tessellation and its applications. ACM Transactions on Graphics (TOG)29(4), 1–11 (2010)
2010
-
[20]
arXiv preprint arXiv:2405.14979 (2024)
Li, W., Peng, J., Chen, H., Gu, L., Wang, Q.: Craftsman: High-fidelity mesh gen- eration with 3d native generation and interactive geometry refiner. arXiv preprint arXiv:2405.14979 (2024)
-
[21]
arXiv preprint arXiv:2505.14521 (2025)
Li, Z., Wang, Y., Zheng, H., Luo, Y., Wen, B.: Sparc3d: Sparse representa- tion and construction for high-resolution 3d shapes modeling. arXiv preprint arXiv:2505.14521 (2025)
-
[22]
arXiv preprint arXiv:2505.19901 (2025)
Liu, P., Ren, X., Liu, F., Xie, Q., Zheng, Q., Zhang, Y., Lu, H., Yang, Y.: Dynamic-i2v: Exploring image-to-video generation models via multimodal llm. arXiv preprint arXiv:2505.19901 (2025)
-
[23]
arXiv preprint arXiv:2309.13638 (2023)
McCoy, R.T., Yao, S., Friedman, D., Hardy, M., Griffiths, T.L.: Embers of au- toregression: Understanding large language models through the problem they are trained to solve. arXiv preprint arXiv:2309.13638 (2023)
-
[24]
Finite Scalar Quantization: VQ-VAE Made Simple
Mentzer, F., Minnen, D., Agustsson, E., Tschannen, M.: Finite scalar quantization: Vq-vae made simple. arXiv preprint arXiv:2309.15505 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Visualization and Mathematics III pp
Meyer, M., Desbrun, M., Schröder, P., Barr, A.H.: Discrete differential-geometry operators for triangulated 2-manifolds. Visualization and Mathematics III pp. 35– 57 (2003)
2003
-
[26]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Pun, A., Deng, K., Liu, R., Ramanan, D., Liu, C., Zhu, J.Y.: Generating physically stable and buildable brick structures from text. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14798–14809 (2025)
2025
-
[27]
In: SIGGRAPH Asia 2020 Courses (2020)
Ravi,N.,Reizenstein,J.,Novotny,D.,Gordon,T.,Lo,W.Y.,Johnson,J.,Gkioxari, G.: Accelerating 3d deep learning with pytorch3d. In: SIGGRAPH Asia 2020 Courses (2020)
2020
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ren, X., Huang, J., Zeng, X., Museth, K., Fidler, S., Williams, F.: Xcube: Large- scale 3d generative modeling using sparse voxel hierarchies. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4209–4219 (2024)
2024
-
[29]
In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Santilli, A., Severino, S., Postolache, E., Maiorca, V., Mancusi, M., Marin, R., Rodolà, E.: Accelerating transformer inference for translation via parallel decoding. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 12336–12355 (2023)
2023
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Siddiqui, Y., Alliegro, A., Artemov, A., Tommasi, T., Sirigatti, D., Rosov, V., Dai, A., Nießner, M.: Meshgpt: Generating triangle meshes with decoder-only trans- formers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19615–19625 (2024)
2024
-
[31]
arXiv preprint arXiv:2507.02477 (2025)
Song, G., Zhao, Z., Weng, H., Zeng, J., Jia, R., Gao, S.: Mesh silksong: Auto- regressive mesh generation as weaving silk. arXiv preprint arXiv:2507.02477 (2025)
-
[32]
ACM Transactions On Graphics (TOG)33(1), 1–17 (2014) SuperVoxelGPT 17
Song, R., Liu, Y., Martin, R.R., Rosin, P.L.: Mesh saliency via spectral processing. ACM Transactions On Graphics (TOG)33(1), 1–17 (2014) SuperVoxelGPT 17
2014
-
[33]
arXiv preprint arXiv:2409.18114 (2024)
Tang, J., Li, Z., Hao, Z., Liu, X., Zeng, G., Liu, M.Y., Zhang, Q.: Edgerun- ner: Auto-regressive auto-encoder for artistic mesh generation. arXiv preprint arXiv:2409.18114 (2024)
-
[34]
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scalableimagegenerationvianext-scaleprediction.Advancesinneuralinformation processing systems37, 84839–84865 (2024)
2024
-
[35]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[36]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Wang, Z., Wang, L., Zhao, Z., Wu, M., Lyu, C., Li, H., Cai, D., Zhou, L., Shi, S., Tu, Z.: Gpt4video: A unified multimodal large language model for lnstruction- followed understanding and safety-aware generation. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 3907–3916 (2024)
2024
-
[37]
arXiv preprint arXiv:2406.12998 (2024)
Wang, Z., Guo, J., Chen, Z., Zhu, J., Zhang, C.: Llama-mesh: Unifying 3d mesh generation with language models. arXiv preprint arXiv:2406.12998 (2024)
-
[38]
In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Confer- ence Conference Papers
Wei, S.T., Wang, R.H., Zhou, C.Z., Chen, B., Wang, P.S.: Octgpt: Octree-based multiscale autoregressive models for 3d shape generation. In: Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Confer- ence Conference Papers. pp. 1–11 (2025)
2025
-
[39]
arXiv preprint arXiv:2505.17412 (2025)
Wu, S., Lin, Y., Zhang, F., Zeng, Y., Yang, Y., Bao, Y., Qian, J., Zhu, S., Cao, X., Torr, P., et al.: Direct3d-s2: Gigascale 3d generation made easy with spatial sparse attention. arXiv preprint arXiv:2505.17412 (2025)
-
[40]
Advances in Neural Information Processing Systems35, 33330–33342 (2022)
Wu, X., Lao, Y., Jiang, L., Liu, X., Zhao, H.: Point transformer v2: Grouped vector attention and partition-based pooling. Advances in Neural Information Processing Systems35, 33330–33342 (2022)
2022
-
[41]
Native and Compact Structured Latents for 3D Generation
Xiang, J., Chen, X., Xu, S., Wang, R., Lv, Z., Deng, Y., Zhu, H., Dong, Y., Zhao, H., Yuan, N.J., et al.: Native and compact structured latents for 3d generation. arXiv preprint arXiv:2512.14692 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Structured 3D Latents for Scalable and Versatile 3D Generation
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. arXiv preprint arXiv:2412.01506 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
arXiv preprint arXiv:2305.08275 (2024)
Xue, L., Yu, N., Zhang, S., Panagopoulou, A., Li, J., Martín-Martín, R., Wu, J., Xiong, C., Xu, R., Niebles, J.C., et al.: Ulip-2: Towards scalable multimodal pre- training for 3d understanding. arXiv preprint arXiv:2305.08275 (2024)
-
[44]
National Science Review11(12), nwae403 (2024)
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12), nwae403 (2024)
2024
-
[45]
Zhang, B., Tang, J., Nießner, M., Wonka, P.: 3dshape2vecset: A 3d shape repre- sentation for neural fields and generative diffusion models. ACM Trans. Graph. 42(4) (jul 2023).https://doi.org/10.1145/3592442,https://doi.org/10. 1145/3592442
-
[46]
arXiv preprint arXiv:2505.18947 (2025)
Zhang, Z., Shi, Y., Yang, L., Ni, S., Ye, Q., Wang, J.: Openhoi: Open-world hand- object interaction synthesis with multimodal large language model. arXiv preprint arXiv:2505.18947 (2025)
-
[47]
In: Symposium on interactive 3D graphics and games
Zheng, J., Tan, T.S.: Computing centroidal voronoi tessellation using the gpu. In: Symposium on interactive 3D graphics and games. pp. 1–9 (2020)
2020
-
[48]
In: European conference on computer vision
Zhou, Q.Y., Park, J., Koltun, V.: Fast global registration. In: European conference on computer vision. pp. 766–782. Springer (2016)
2016
-
[49]
IEEE Transactions on Information Theory23(3), 337–343 (1977) 18 Y
Ziv, J., Lempel, A.: A universal algorithm for sequential data compression. IEEE Transactions on Information Theory23(3), 337–343 (1977) 18 Y. Li et al. SuperVoxelGPT: Supplementary Material A Metrics Calculation We provide detailed definitions of the evaluation metrics used in the main paper. We first describe the shape alignment procedure (Sec. A.1), wh...
1977
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.