Evolve as a Team: Collaborative Self-Evolution for LLM-based Multi-Agent Systems
Pith reviewed 2026-06-29 00:03 UTC · model grok-4.3
The pith
Meta-Team lets multi-agent LLM systems improve through collaborative self-evolution from their execution experience.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
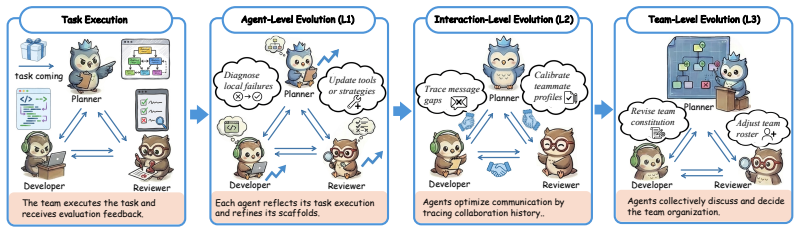
Meta-Team is an experience-driven MAS evolution framework based on collaborative self-evolution that preserves the execution context of each agent and coordinates post-task communication, enabling agents to exchange distributed evidence for evolution and conducting multi-scale self-evolution to transform execution experience into reusable improvements to agent behaviors, inter-agent coordination, and team-level organization.
What carries the argument
The collaborative self-evolution process that relies on context preservation and post-task communication coordination to turn intricate MAS execution experience into multi-scale improvements.
If this is right
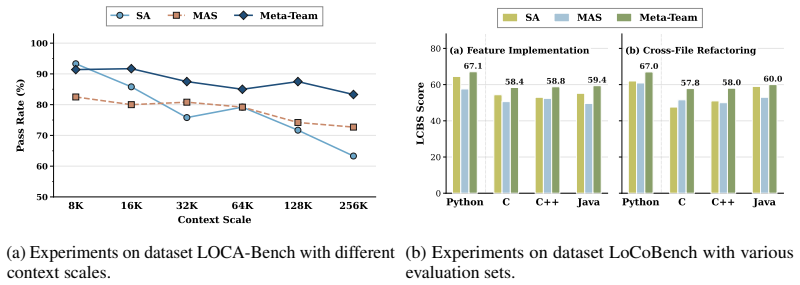
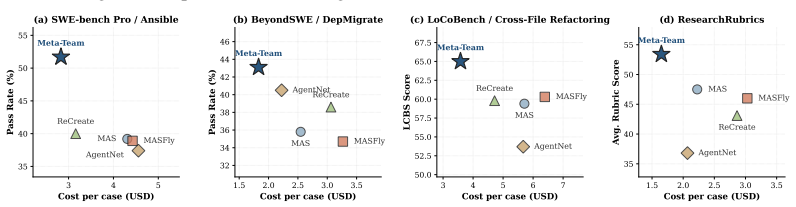
- Meta-Team consistently outperforms single-agent systems, hand-crafted MAS, and prior MAS evolution methods across six long-horizon agent benchmarks.
- Further analyses show that Meta-Team enables more reliable and scalable MAS self-evolution.
- Execution experience that interleaves multiple agents' chains and messages can be transformed into reusable improvements at multiple scales.
- The design addresses the difficulty of identifying what should be improved in prolonged and intricate MAS experience.
Where Pith is reading between the lines
- Over repeated tasks, the team organization improvements could lead to emergent division of labor among agents.
- The method might extend to non-LLM agent systems if they can generate similar execution traces.
- Reducing reliance on hand-crafted MAS designs could accelerate deployment in dynamic environments.
Load-bearing premise
That preserving each agent's execution context and coordinating post-task communication will allow agents to exchange distributed evidence in a way that produces effective multi-scale improvements.
What would settle it
A controlled experiment on the six benchmarks where Meta-Team shows no performance gain over baselines, or where disabling the post-task communication coordination removes all observed benefits.
Figures
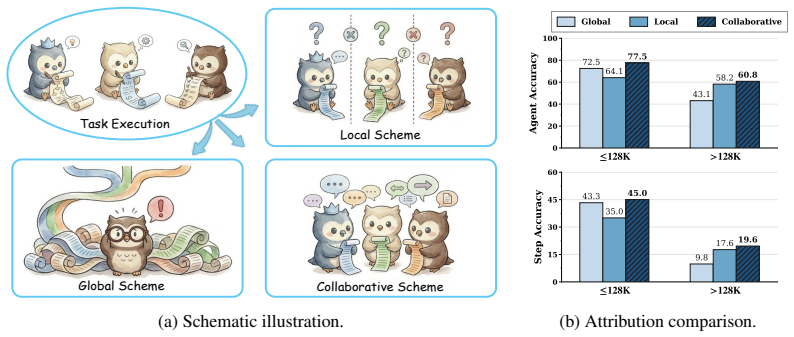
read the original abstract
LLM-based multi-agent systems (MAS) have emerged as an effective paradigm for complex and long-horizon tasks. However, in real-world tasks, MAS often exhibit various failures during execution and such failures are difficult to eliminate during design. This motivates experience-driven MAS evolution, where a system improves based on its own execution experience. Yet such evolution is challenging because MAS experience is prolonged and intricate, interleaving multiple agents' execution chains and communication messages, which makes it difficult to identify what should be improved. To address this challenge, we propose Meta-Team, an experience-driven MAS evolution framework based on collaborative self-evolution. Meta-Team preserves the execution context of each agent and coordinates post-task communication, enabling agents to exchange distributed evidence for evolution. Building on this design, Meta-Team conducts multi-scale self-evolution, transforming execution experience into reusable improvements to agent behaviors, inter-agent coordination, and team-level organization. Across six long-horizon agent benchmarks, Meta-Team consistently outperforms single-agent systems, hand-crafted MAS, and prior MAS evolution methods; further analyses demonstrate that Meta-Team enables more reliable and scalable MAS self-evolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Meta-Team, an experience-driven evolution framework for LLM-based multi-agent systems (MAS). It preserves each agent's execution context and coordinates post-task communication so that agents can exchange distributed evidence from intricate interleaved execution chains. This design supports multi-scale self-evolution that produces reusable improvements to individual agent behaviors, inter-agent coordination, and team-level organization. The framework is evaluated on six long-horizon agent benchmarks and is reported to outperform single-agent baselines, hand-crafted MAS, and prior MAS evolution methods.
Significance. If the reported gains are robust and attributable to the collaborative mechanism, the work would offer a practical route to scalable, experience-driven improvement of MAS without requiring extensive manual redesign. The multi-scale framing (behavior, coordination, organization) directly targets a recognized difficulty in long-horizon MAS and could influence subsequent research on self-improving agent teams.
major comments (3)
- [Section 3] Section 3 (Meta-Team framework): The central claim that preserving execution context plus coordinated post-task communication enables agents to extract reusable improvements from interleaved chains is load-bearing, yet the manuscript provides no concrete algorithm, pseudocode, or worked example showing how agents identify and distill distributed evidence into multi-scale updates rather than simply producing additional prompts. Without this, attribution of benchmark gains to the collaborative mechanism remains unverified.
- [Section 4] Section 4 (Experiments): The abstract states consistent outperformance across six benchmarks, but the manuscript does not report ablation variants that disable post-task communication while keeping other components fixed. Such an ablation is required to test whether the identification problem is actually mitigated by the proposed coordination step.
- [Section 4.3] Section 4.3 (Analysis): The claim of more reliable and scalable self-evolution is supported only by aggregate success rates; no per-benchmark breakdown of failure modes before versus after evolution, nor any measure of how often post-task messages actually surface actionable improvements, is provided.
minor comments (2)
- Notation for the three evolution scales (agent, coordination, organization) is introduced without a compact summary table; adding one would improve readability.
- The related-work section cites prior MAS evolution methods but does not explicitly contrast the post-task communication design with the communication protocols used in those baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of Meta-Team. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Meta-Team framework): The central claim that preserving execution context plus coordinated post-task communication enables agents to extract reusable improvements from interleaved chains is load-bearing, yet the manuscript provides no concrete algorithm, pseudocode, or worked example showing how agents identify and distill distributed evidence into multi-scale updates rather than simply producing additional prompts. Without this, attribution of benchmark gains to the collaborative mechanism remains unverified.
Authors: We agree that Section 3 would benefit from greater concreteness. While the section describes the preservation of execution context and the coordination of post-task communication at a conceptual level, it does not include pseudocode or a worked example of the distillation process. We will add both an algorithm box outlining the multi-scale update procedure and a detailed worked example from one benchmark to illustrate how distributed evidence is identified and transformed into reusable improvements at each scale. revision: yes
-
Referee: [Section 4] Section 4 (Experiments): The abstract states consistent outperformance across six benchmarks, but the manuscript does not report ablation variants that disable post-task communication while keeping other components fixed. Such an ablation is required to test whether the identification problem is actually mitigated by the proposed coordination step.
Authors: We concur that an ablation isolating the post-task communication component is necessary to attribute gains specifically to the collaborative mechanism. We will add this ablation (disabling coordinated post-task messages while retaining context preservation and the evolution pipeline) and report the resulting performance on the six benchmarks in the revised experiments section. revision: yes
-
Referee: [Section 4.3] Section 4.3 (Analysis): The claim of more reliable and scalable self-evolution is supported only by aggregate success rates; no per-benchmark breakdown of failure modes before versus after evolution, nor any measure of how often post-task messages actually surface actionable improvements, is provided.
Authors: We acknowledge the limitation in the current analysis. We will expand Section 4.3 to include (i) per-benchmark tables or figures showing failure-mode distributions before and after evolution and (ii) statistics on the frequency and actionability of improvements derived from post-task messages. These additions will provide more granular support for the reliability and scalability claims. revision: yes
Circularity Check
No circularity: framework design with no equations or fitted predictions
full rationale
The paper describes a proposed MAS evolution framework (Meta-Team) that preserves execution context and uses post-task communication for multi-scale improvements. No equations, parameters, or quantitative derivations appear in the provided text. The central claims rest on the design choices and empirical benchmark results rather than any self-definitional loop, fitted-input prediction, or load-bearing self-citation chain. The absence of mathematical structure means none of the enumerated circularity patterns can be exhibited by direct quote and reduction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
The Pitfall of Scaling Up: Uncovering and Mitigating Popularity Bias Amplification in Scaling Transformer-based Recommenders
Transformer recommenders amplify popularity bias via spectral collapse when scaled; SPRINT constrains attention column-sums and feed-forward spectral norms to improve fairness and scaling behavior.
Reference graph
Works this paper leans on
-
[1]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Why does the effective context length of llms fall short? InICLR, 2025
Chenxin An, Jun Zhang, Ming Zhong, Lei Li, Shansan Gong, Yao Luo, Jingjing Xu, and Lingpeng Kong. Why does the effective context length of llms fall short? InICLR, 2025
2025
-
[3]
How we built our multi-agent research system, 2025
Anthropic. How we built our multi-agent research system, 2025. https://www.anthropic. com/engineering/built-multi-agent-research-system
2025
-
[4]
Introducing claude opus 4.6
Anthropic. Introducing claude opus 4.6. https://www.anthropic.com/news/ claude-opus-4-6, 2026
2026
-
[5]
Orchestrate teams of Claude Code sessions
Anthropic. Orchestrate teams of Claude Code sessions. https://code.claude.com/docs/ en/agent-teams, 2026
2026
-
[6]
Claude Code Overview
Anthropic. Claude Code Overview. https://code.claude.com/docs/en/overview, 2026
2026
-
[7]
Introducing claude sonnet 4.6
Anthropic. Introducing claude sonnet 4.6. https://www.anthropic.com/news/ claude-sonnet-4-6, 2026
2026
-
[8]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Where did it all go wrong? a hierarchical look into multi-agent error attribution
Adi Banerjee, Anirudh Nair, and Tarik Borogovac. Where did it all go wrong? a hierarchical look into multi-agent error attribution. InNeurIPS Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling, 2025
2025
-
[10]
Why do multi- agent llm systems fail? InNeurIPS Datasets and Benchmarks Track, 2025
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi- agent llm systems fail? InNeurIPS Datasets and Benchmarks Track, 2025
2025
-
[11]
BeyondSWE: Can Current Code Agent Survive Beyond Single-Repo Bug Fixing?
Guoxin Chen, Fanzhe Meng, Jiale Zhao, Minghao Li, Daixuan Cheng, Huatong Song, Jie Chen, Yuzhi Lin, Hui Chen, Xin Zhao, et al. Beyondswe: Can current code agent survive beyond single-repo bug fixing?arXiv preprint arXiv:2603.03194, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Hongjiang Chen, Xin Zheng, Yixin Liu, Pengfei Jiao, Shiyuan Li, Huan Liu, Zhidong Zhao, Ziqi Xu, Ibrahim Khalil, and Shirui Pan. Goagent: Group-of-agents communication topology generation for llm-based multi-agent systems.arXiv preprint arXiv:2603.19677, 2026
-
[13]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Seeing the Whole Elephant: A Benchmark for Failure Attribution in LLM-based Multi-Agent Systems
Mengzhuo Chen, Junjie Wang, Fangwen Mu, Yawen Wang, Zhe Liu, Huanxiang Feng, and Qing Wang. Seeing the whole elephant: A benchmark for failure attribution in llm-based multi-agent systems.arXiv preprint arXiv:2604.22708, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Zhijun Chen, Zeyu Ji, Qianren Mao, Hao Wu, Junhang Cheng, Bangjie Qin, Zhuoran Li, Jingzheng Li, Kai Sun, Zizhe Wang, et al. Scoring, reasoning, and selecting the best! ensembling large language models via a peer-review process.arXiv preprint arXiv:2512.23213, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Adam Fourney, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Friederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Gerrits, Jacob Alber, et al. Magentic-one: A generalist multi-agent system for solving complex tasks.arXiv preprint arXiv:2411.04468, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Flowreasoner: Reinforcing query-level meta-agents.arXiv preprint arXiv:2504.15257, 2025
Hongcheng Gao, Yue Liu, Yufei He, Longxu Dou, Chao Du, Zhijie Deng, Bryan Hooi, Min Lin, and Tianyu Pang. Flowreasoner: Reinforcing query-level meta-agents.arXiv preprint arXiv:2504.15257, 2025
-
[20]
A new era of intelligence with gemini 3
Google. A new era of intelligence with gemini 3. https://blog.google/products/ gemini/gemini-3/, 2025
2025
-
[21]
Large language model based multi-agents: A survey of progress and challenges
T Guo, X Chen, Y Wang, R Chang, S Pei, NV Chawla, O Wiest, and X Zhang. Large language model based multi-agents: A survey of progress and challenges. In33rd International Joint Conference on Artificial Intelligence (IJCAI 2024). IJCAI; Cornell arxiv, 2024
2024
-
[22]
ReCreate: Reasoning and Creating Domain Agents Driven by Experience
Zhezheng Hao, Hong Wang, Jian Luo, Jianqing Zhang, Yuyan Zhou, Qiang Lin, Can Wang, Hande Dong, and Jiawei Chen. Recreate: Reasoning and creating domain agents driven by experience.arXiv preprint arXiv:2601.11100, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021
2021
-
[24]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[25]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. InICLR, 2024
2024
-
[26]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Owl: Optimized workforce learning for general multi-agent assistance in real-world task automation
Mengkang Hu, Yuhang Zhou, Wendong Fan, Yuzhou Nie, Ziyu Ye, Bowei Xia, Tao Sun, Zhaoxuan Jin, Yingru Li, Zeyu Zhang, et al. Owl: Optimized workforce learning for general multi-agent assistance in real-world task automation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[28]
Automated design of agentic systems
Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems. InICLR, 2025
2025
-
[29]
EvoMAS: Evolutionary Generation of Multi-Agent Systems
Yuntong Hu, Matthew Trager, Yuting Zhang, Yi Zhang, Shuo Yang, Wei Xia, and Stefano Soatto. Evolutionary generation of multi-agent systems.arXiv preprint arXiv:2602.06511, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Yeonjun In, Mehrab Tanjim, Jayakumar Subramanian, Sungchul Kim, Uttaran Bhattacharya, Wonjoong Kim, Sangwu Park, Somdeb Sarkhel, and Chanyoung Park. Rethinking failure attribution in multi-agent systems: A multi-perspective benchmark and evaluation.arXiv preprint arXiv:2603.25001, 2026
-
[31]
Aegis: Automated Error Generation and Attribution for Multi-Agent Systems
Fanqi Kong, Ruijie Zhang, Huaxiao Yin, Guibin Zhang, Xiaofei Zhang, Ziang Chen, Zhaowei Zhang, Xiaoyuan Zhang, Song-Chun Zhu, and Xue Feng. Aegis: Automated error generation and attribution for multi-agent systems.arXiv preprint arXiv:2509.14295, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Mingze Kong, Zikun Qu, Zhongquan Zhou, Pengyu Liang, Xiang Li, Zhiwei Shang, Zhi Hong, Kaiyu Huang, Zhiyong Wang, and Zhongxiang Dai. Workflow-r1: Group sub-sequence policy optimization for multi-turn workflow construction.arXiv preprint arXiv:2602.01202, 2026
-
[33]
Agentic Aggregation for Parallel Scaling of Long-Horizon Agentic Tasks
Yoonsang Lee, Howard Yen, Xi Ye, and Danqi Chen. Agentic aggregation for parallel scaling of long-horizon agentic tasks.arXiv preprint arXiv:2604.11753, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society.Advances in neural information processing systems, 36:51991–52008, 2023
2023
-
[35]
Towards Self-Improving Error Diagnosis in Multi-Agent Systems
Jiazheng Li, Emine Yilmaz, Bei Chen, and Dieu-Thu Le. Towards self-improving error diagnosis in multi-agent systems.arXiv preprint arXiv:2604.17658, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
Keyu Li, Junhao Shi, Yang Xiao, Mohan Jiang, Jie Sun, Yunze Wu, Dayuan Fu, Shijie Xia, Xiaojie Cai, Tianze Xu, et al. Agencybench: Benchmarking the frontiers of autonomous agents in 1m-token real-world contexts.arXiv preprint arXiv:2601.11044, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
Assemble your crew: Automatic multi-agent communication topology design via autoregressive graph generation
Shiyuan Li, Yixin Liu, Qingsong Wen, Chengqi Zhang, and Shirui Pan. Assemble your crew: Automatic multi-agent communication topology design via autoregressive graph generation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 23142–23150, 2026
2026
-
[38]
A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024
2024
-
[39]
Yilong Li, Chen Qian, Yu Xia, Ruijie Shi, Yufan Dang, Zihao Xie, Ziming You, Weize Chen, Cheng Yang, Weichuan Liu, et al. Cross-task experiential learning on llm-based multi-agent collaboration.arXiv preprint arXiv:2505.23187, 2025
-
[40]
Yu Li, Lehui Li, Zhihao Wu, Qingmin Liao, Jianye Hao, Kun Shao, Fengli Xu, and Yong Li. Agentswift: Efficient llm agent design via value-guided hierarchical search.arXiv preprint arXiv:2506.06017, 2025
-
[41]
Openmanus: An open-source framework for building general ai agents, 2025
Xinbin Liang, Jinyu Xiang, Zhaoyang Yu, Jiayi Zhang, Sirui Hong, Sheng Fan, Xiao Tang, Bang Liu, Yuyu Luo, and Chenglin Wu. Openmanus: An open-source framework for building general ai agents, 2025. URLhttps://doi.org/10.5281/zenodo.15186407
-
[42]
Agentask: Multi-agent systems need to ask.arXiv preprint arXiv:2510.07593, 2025
Bohan Lin, Kuo Yang, Zelin Tan, Yingchuan Lai, Chen Zhang, Guibin Zhang, Xinlei Yu, Miao Yu, Xu Wang, Yudong Zhang, et al. Agentask: Multi-agent systems need to ask.arXiv preprint arXiv:2510.07593, 2025
-
[43]
Jiaye Lin, Yifu Guo, Yuzhen Han, Sen Hu, Ziyi Ni, Licheng Wang, Mingguang Chen, Hongzhang Liu, Ronghao Chen, Yangfan He, et al. Se-agent: Self-evolution trajectory op- timization in multi-step reasoning with llm-based agents.arXiv preprint arXiv:2508.02085, 2025
-
[44]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Guangyi Liu, Haojun Lin, Huan Zeng, Heng Wang, and Quanming Yao. Mas-on-the- fly: Dynamic adaptation of llm-based multi-agent systems at test time.arXiv preprint arXiv:2602.13671, 2026
-
[46]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[47]
Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
2023
-
[48]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[49]
Introducing gpt-5.4
Open AI. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4 , 2026. 12
2026
-
[50]
Multi-Agent Teams Hold Experts Back
Aneesh Pappu, Batu El, Hancheng Cao, Carmelo di Nolfo, Yanchao Sun, Meng Cao, and James Zou. Multi-agent teams hold experts back.arXiv preprint arXiv:2602.01011, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Multi-agent coordination patterns: Five approaches and when to use them
Cara Phillips. Multi-agent coordination patterns: Five approaches and when to use them. https://claude.com/blog/multi-agent-coordination-patterns , April 2026. An- thropic Blog, Accessed: 2026-05-05
2026
-
[52]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174–15186, 2024
2024
-
[53]
Jielin Qiu, Zuxin Liu, Zhiwei Liu, Rithesh Murthy, Jianguo Zhang, Haolin Chen, Shiyu Wang, Ming Zhu, Liangwei Yang, Juntao Tan, et al. Locobench: A benchmark for long-context large language models in complex software engineering.arXiv preprint arXiv:2509.09614, 2025
-
[54]
Solving general arithmetic word problems
Subhro Roy and Dan Roth. Solving general arithmetic word problems. InProceedings of the 2015 conference on empirical methods in natural language processing, pages 1743–1752, 2015
2015
-
[55]
Jianhao Ruan, Zhihao Xu, Yiran Peng, Fashen Ren, Zhaoyang Yu, Xinbing Liang, Jinyu Xiang, Yongru Chen, Bang Liu, Chenglin Wu, et al. Aorchestra: Automating sub-agent creation for agentic orchestration.arXiv preprint arXiv:2602.03786, 2026
-
[56]
Team reflexivity and innovation: The moderating role of team context.Journal of Management, 41(3):769–788, 2015
Michaéla C Schippers, Michael A West, and Jeremy F Dawson. Team reflexivity and innovation: The moderating role of team context.Journal of Management, 41(3):769–788, 2015
2015
-
[57]
United Minds or Isolated Agents? Exploring Coordination of LLMs under Cognitive Load Theory
HaoYang Shang, Xuan Liu, Zi Liang, Jie Zhang, Haibo Hu, and Song Guo. United minds or isolated agents? exploring coordination of llms under cognitive load theory.arXiv preprint arXiv:2506.06843, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Agentsquare: Automatic llm agent search in modular design space
Yu Shang, Yu Li, Keyu Zhao, Likai Ma, Jiahe Liu, Fengli Xu, and Yong Li. Agentsquare: Automatic llm agent search in modular design space. InICLR, 2025
2025
-
[59]
Hendryx, Brad Kenstler, and Bing Liu
Manasi Sharma, Chen Bo Calvin Zhang, Chaithanya Bandi, Clinton Wang, Ankit Aich, Huy Nghiem, Tahseen Rabbani, Ye Htet, Brian Jang, Sumana Basu, et al. Researchrubrics: A benchmark of prompts and rubrics for evaluating deep research agents.arXiv preprint arXiv:2511.07685, 2025
-
[60]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[61]
Linxin Song, Jiale Liu, Jieyu Zhang, Shaokun Zhang, Ao Luo, Shijian Wang, Qingyun Wu, and Chi Wang. Adaptive in-conversation team building for language model agents.arXiv preprint arXiv:2405.19425, 2024
-
[62]
Coact-1: Computer-using agents with coding as actions
Linxin Song, Yutong Dai, Viraj Prabhu, Jieyu Zhang, Taiwei Shi, Li Li, Junnan Li, Silvio Savarese, Zeyuan Chen, Jieyu Zhao, et al. Coact-1: Computer-using agents with coding as actions. InICLR, 2026
2026
-
[63]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[64]
Dat Tran and Douwe Kiela. Single-agent llms outperform multi-agent systems on multi-hop reasoning under equal thinking token budgets.arXiv preprint arXiv:2604.02460, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Automated stateful specialization for adaptive agent systems
Myan Vu, Harrish Ayyanar, PANG JIANG, Anwiketh Reddy, and Mayank Goel. Automated stateful specialization for adaptive agent systems. InICLR, 2026
2026
-
[66]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741, 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Yinjie Wang, Ling Yang, Guohao Li, Mengdi Wang, and Bryon Aragam. Scoreflow: Mastering llm agent workflows via score-based preference optimization.arXiv preprint arXiv:2502.04306, 2025
-
[68]
Reflexivity and work group effectiveness: A conceptual integration
Michael West. Reflexivity and work group effectiveness: A conceptual integration. InThe handbook of work group psychology, pages 555–579. John Wiley & Sons, Ltd, 1996
1996
-
[69]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. InFirst conference on language modeling, 2024
2024
-
[70]
Prompt optimization with ease? efficient ordering-aware automated selection of exemplars.Advances in Neural Information Processing Systems, 37: 122706–122740, 2024
Zhaoxuan Wu, Xiaoqiang Lin, Zhongxiang Dai, Wenyang Hu, Yao Shu, See-Kiong Ng, Patrick Jaillet, and Bryan Kian Hsiang Low. Prompt optimization with ease? efficient ordering-aware automated selection of exemplars.Advances in Neural Information Processing Systems, 37: 122706–122740, 2024
2024
-
[71]
When does divide and conquer work for long context llm? a noise decomposition framework
Zhen Xu, Shang Zhu, Jue Wang, Junlin Wang, Ben Athiwaratkun, Chi Wang, James Zou, and Ce Zhang. When does divide and conquer work for long context llm? a noise decomposition framework. InICLR, 2026
2026
-
[72]
Don’t build multi-agents
Walden Yan. Don’t build multi-agents. https://cognition.ai/blog/ dont-build-multi-agents, June 2025. Cognition AI Blog, Accessed: 2026-05-05
2025
-
[73]
Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[74]
Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems,
Yingxuan Yang, Huacan Chai, Shuai Shao, Yuanyi Song, Siyuan Qi, Renting Rui, and Weinan Zhang. Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems,
- [75]
-
[76]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[77]
Masrouter: Learning to route llms for multi-agent systems
Yanwei Yue, Guibin Zhang, Boyang Liu, Guancheng Wan, Kun Wang, Dawei Cheng, and Yiyan Qi. Masrouter: Learning to route llms for multi-agent systems. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15549–15572, 2025
2025
-
[78]
Weihao Zeng, Yuzhen Huang, and Junxian He. Loca-bench: Benchmarking language agents under controllable and extreme context growth.arXiv preprint arXiv:2602.07962, 2026
-
[79]
Multi-agent architecture search via agentic supernet
Guibin Zhang, Luyang Niu, Junfeng Fang, Kun Wang, Lei Bai, and Xiang Wang. Multi-agent architecture search via agentic supernet. InInternational Conference on Machine Learning, pages 75834–75852. PMLR, 2025
2025
-
[80]
Agentracer: Who is inducing failure in the llm agentic systems?arXiv preprint arXiv:2509.03312, 2025
Guibin Zhang, Junhao Wang, Junjie Chen, Wangchunshu Zhou, Kun Wang, and Shuicheng Yan. Agentracer: Who is inducing failure in the llm agentic systems?arXiv preprint arXiv:2509.03312, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.