PRAIB: Peer Review AI Benchmark of Behaviour of LLM-Assisted Reviewing
Pith reviewed 2026-06-29 07:14 UTC · model grok-4.3
The pith
LLM peer reviews show less variable ratings, positive bias, overconfidence, and miss human-noted weaknesses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
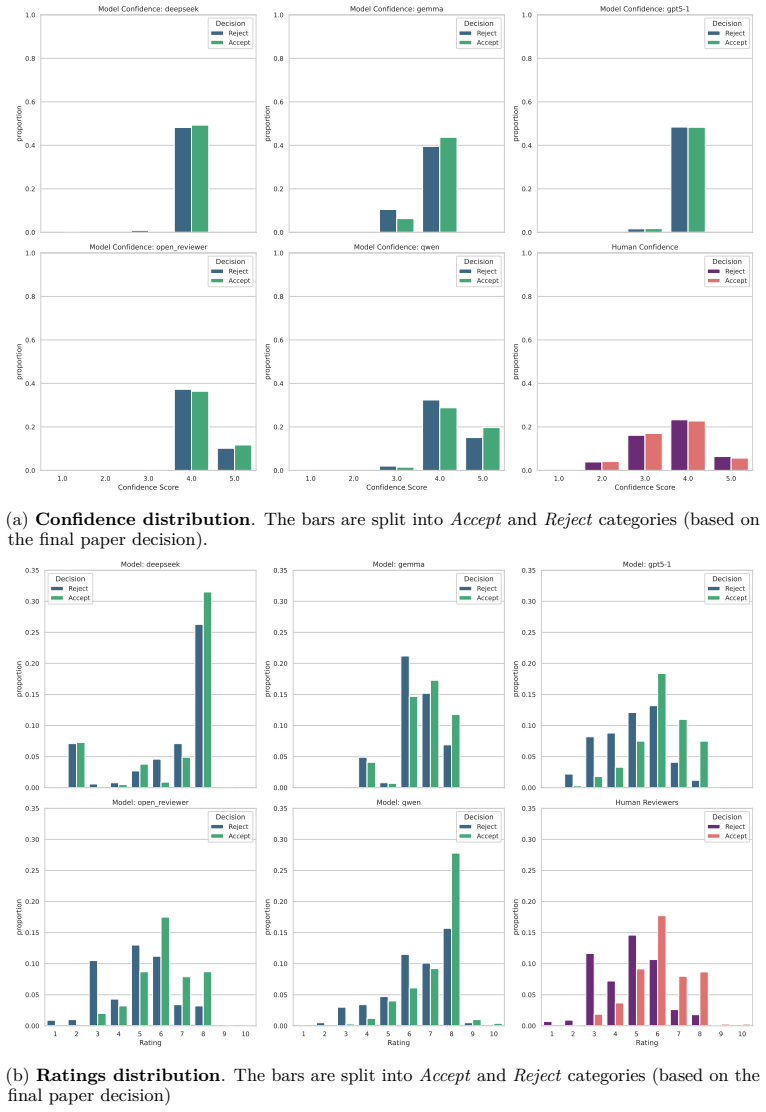
PRAIB measures review specificity, style, and engagement and shows that LLM-generated reviews diverge from human norms: ratings exhibit less variability, positive bias, and overconfidence; cross-reference patterns depend on the model and differ from human patterns; generated reviews are longer and more complex yet overlook atomic weaknesses identified by human reviewers.
What carries the argument
The PRAIB benchmark framework of metrics for review specificity, style, and behavior of engagement, used to compare LLM outputs against human reviews across prompting strategies.
If this is right
- LLMs cannot yet serve as standalone detectors of paper weaknesses without additional safeguards.
- Rating outputs from LLMs require calibration to restore human-like variability.
- Choice of model and prompt shapes review patterns, so consistency depends on controlling these factors.
- Length and complexity of LLM reviews do not guarantee coverage of the issues humans flag.
- PRAIB supplies concrete diagnostics for deciding which review tasks can be delegated to LLMs now.
Where Pith is reading between the lines
- Hybrid workflows could route initial summarization to LLMs and weakness detection to humans.
- Fine-tuning on human review data might reduce the observed overconfidence and omissions.
- The benchmark could be extended to track whether newer models close the gap on atomic flaw detection.
- Conference organizers might use PRAIB scores to decide whether to accept LLM-assisted reviews in specific roles.
Load-bearing premise
The 1,000 papers and five models with varied prompts form a representative enough sample to reveal systematic behavioral differences from human reviewer norms.
What would settle it
A replication study on a fresh set of papers and models that finds LLM ratings matching human variability levels and catching the same atomic weaknesses would falsify the claimed divergences.
Figures
read the original abstract
The growing number of submitted papers has motivated the exploration of Large Language Models (LLMs) as a means to support and augment the peer review process, particularly in terms of improving its speed and scalability. Yet, it remains unknown whether LLMs engage with scientific manuscripts in the same manner as human reviewers, or whether they merely produce review-looking text. To address this, we introduce the Peer Review AI Benchmark (PRAIB), a novel framework comprising thoroughly defined metrics that measure review specificity, style, and behavior of engagement. To complement the PRAIB framework, we conduct a large-scale empirical study leveraging a dataset of 11,000 reviews generated by five proprietary and open-source models for 1,000 ICLR and NeurIPS papers. Spanning the 2021--2025 period, these machine-generated reviews are compared against original human feedback across diverse prompting strategies to identify systematic behavioral divergences. Our analysis reveals that the generated reviews diverge significantly from feedback provided by human reviewers: LLM ratings are less variable, positively biased, and overconfident, and their cross-reference patterns are model-dependent and distinct from human norms. Furthermore, when evaluated through PRAIB, we observe that LLMs tend to generate longer, more complex reviews, yet frequently overlook the atomic weaknesses noted by human reviewers. By characterizing where and how LLMs reviewing behavior departs from human norms, PRAIB provides the community with a diagnostic tool for identifying which aspects of the review process LLMs can reliably support today and which require further development before deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Peer Review AI Benchmark (PRAIB), a framework defining metrics for review specificity, style, and behavioral engagement. It reports a large-scale empirical comparison of 11,000 LLM-generated reviews (five models, diverse prompts) against human reviews for 1,000 ICLR/NeurIPS papers (2021–2025), claiming that LLM ratings exhibit lower variability, positive bias, and overconfidence; cross-reference patterns are model-dependent and diverge from human norms; and LLM reviews are longer/more complex yet frequently overlook atomic weaknesses identified by humans.
Significance. If the reported divergences are robust, PRAIB supplies a concrete diagnostic instrument for determining which review tasks LLMs can currently augment and which remain unreliable. The scale of the study (11,000 reviews) and the explicit metric definitions constitute a reusable resource that can guide subsequent empirical work on LLM-assisted reviewing.
major comments (2)
- [§3 and §5] §3 (Dataset Construction) and §5 (Results): the central claim that LLM reviewing behavior exhibits systematic, generalizable divergences from human norms rests on the representativeness of the 1,000 ICLR/NeurIPS papers and five models. The paper must either qualify all generalizations to this specific corpus and model set or supply evidence (e.g., sensitivity checks on additional venues or models) that the observed patterns in rating variance, bias, and missed atomic points are not artifacts of the chosen high-stakes ML venues.
- [§4.3] §4.3 (Atomic Weakness Metric): the operational definition of “atomic weaknesses” and the matching procedure between human-identified points and LLM omissions must be stated with sufficient precision (including inter-annotator agreement or automated extraction rules) for the reported frequency difference to be reproducible and load-bearing for the claim that LLMs “frequently overlook” such points.
minor comments (2)
- [Table 2, Figure 4] Table 2 and Figure 4: axis labels and legend entries for rating distributions and cross-reference counts should be expanded to include exact metric formulas or references to the defining equations in §4.
- [§2] §2 (Related Work): a brief discussion of how PRAIB metrics relate to or extend existing automated review-quality measures would improve context without altering the central contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point-by-point below and will revise the manuscript to improve precision and scope qualification.
read point-by-point responses
-
Referee: [§3 and §5] §3 (Dataset Construction) and §5 (Results): the central claim that LLM reviewing behavior exhibits systematic, generalizable divergences from human norms rests on the representativeness of the 1,000 ICLR/NeurIPS papers and five models. The paper must either qualify all generalizations to this specific corpus and model set or supply evidence (e.g., sensitivity checks on additional venues or models) that the observed patterns in rating variance, bias, and missed atomic points are not artifacts of the chosen high-stakes ML venues.
Authors: We agree that our empirical findings are tied to the 1,000 ICLR/NeurIPS papers (2021–2025) and the five models evaluated. In the revision we will explicitly qualify all generalizations to this corpus and model set, adding clear scope statements in the abstract, §5 (Results), and §6 (Discussion/Limitations). We will not claim broader generalizability without further evidence and will frame the results as diagnostic for these high-stakes ML venues. revision: yes
-
Referee: [§4.3] §4.3 (Atomic Weakness Metric): the operational definition of “atomic weaknesses” and the matching procedure between human-identified points and LLM omissions must be stated with sufficient precision (including inter-annotator agreement or automated extraction rules) for the reported frequency difference to be reproducible and load-bearing for the claim that LLMs “frequently overlook” such points.
Authors: We will revise §4.3 to include a precise operational definition of atomic weaknesses, the exact automated extraction rules, the matching procedure between human points and LLM text, and any inter-annotator agreement statistics from the annotation process. These additions will ensure the frequency-difference claim is fully reproducible. revision: yes
Circularity Check
No significant circularity in empirical benchmark study
full rationale
The paper presents PRAIB as a set of defined metrics for comparing LLM-generated reviews against human reviews on an external dataset of 1000 ICLR/NeurIPS papers. It contains no derivations, equations, fitted parameters, or self-referential constructions; all claims rest on direct empirical contrasts to independent human feedback data. No load-bearing steps reduce to the paper's own inputs by definition or self-citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lutz Bornmann, Rüdiger Mutz, and Hans-Dieter Daniel. A reliability-generalization study of journal peer reviews: a multilevel meta-analysis of inter-rater reliability and its determinants. PloS one, 5(12):e14331, 2010. doi: 10.1371/journal.pone.0014331
-
[2]
In Findings of the Association for Computational Lin- guistics: EMNLP 2025
Nicolas Bougie and Narimawa Watanabe. Generative reviewer agents: Scalable simu- lacra of peer review. In Saloni Potdar, Lina Rojas-Barahona, and Sebastien Montella, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 98–116, Suzhou (China), November 2025. Associa- tion for Computational L...
-
[3]
Deepseek-v3 technical report, 2024
DeepSeek-AI. Deepseek-v3 technical report, 2024. URLhttps://arxiv.org/abs/2412. 19437
2024
-
[4]
Luca Demetrio, Giovanni Apruzzese, Kathrin Grosse, Pavel Laskov, Emil Lupu, Vera Rimmer, and Philine Widmer. Gen-review: A large-scale dataset of ai-generated (and human-written) peer reviews.arXiv preprint arXiv:2510.21192, 2025
-
[5]
Llms assist nlp researchers: Critique paper (meta-) reviewing
Jiangshu Du, Yibo Wang, Wenting Zhao, Zhongfen Deng, Shuaiqi Liu, Renze Lou, Henry Peng Zou, Pranav Narayanan Venkit, Nan Zhang, Mukund Srinath, et al. Llms assist nlp researchers: Critique paper (meta-) reviewing. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 5081–5099, 2024
2024
-
[6]
A new readability yardstick.Journal of applied psychology, 32(3):221, 1948
Rudolph Flesch. A new readability yardstick.Journal of applied psychology, 32(3):221, 1948. 10
1948
-
[7]
Xian Gao, Jiacheng Ruan, Zongyun Zhang, Jingsheng Gao, Ting Liu, and Yuzhuo Fu. Reviewagents: Bridging the gap between human and ai-generated paper reviews.arXiv preprint arXiv:2503.08506, 2025
-
[8]
ReviewEval: An evaluation framework for AI-generated reviews
Madhav Krishan Garg, Tejash Prasad, Tanmay Singhal, Chhavi Kirtani, Murari Mandal, and Dhruv Kumar. ReviewEval: An evaluation framework for AI-generated reviews. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computational Linguistics: EMNLP 2025, pages 20542–20564, Suzhou, China...
-
[9]
Gemma Team. Gemma 3. 2025. URLhttps://arxiv.org/abs/2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Andrew Gray. Chatgpt" contamination": estimating the prevalence of llms in the scholarly literature.arXiv preprint arXiv:2403.16887, 2024
-
[11]
OpenReviewer: A specialized large language model for generating critical scientific paper reviews
Maximilian Idahl and Zahra Ahmadi. OpenReviewer: A specialized large language model for generating critical scientific paper reviews. In Nouha Dziri, Sean (Xiang) Ren, and Shizhe Diao, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System Demo...
2025
-
[12]
ISBN 979-8-89176-191-9
Association for Computational Linguistics. ISBN 979-8-89176-191-9. doi: 10.18653/ v1/2025.naacl-demo.44. URL https://aclanthology.org/2025.naacl-demo.44/
2025
-
[13]
Agentreview: Exploring peer review dynamics with llm agents
Yiqiao Jin, Qinlin Zhao, Yiyang Wang, Hao Chen, Kaijie Zhu, Yijia Xiao, and Jindong Wang. Agentreview: Exploring peer review dynamics with llm agents. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1208–1226, 2024
2024
-
[14]
What drives pa- per acceptance? a process-centric analysis of modern peer review
Sangkeun Jung, Goun Pyeon, Inbum Heo, and Hyungjin Ahn. What drives pa- per acceptance? a process-centric analysis of modern peer review. arXiv preprint arXiv:2509.25701, 2025
-
[15]
Insights from the iclr peer review and rebuttal process.arXiv preprint arXiv:2511.15462, 2025
Amir Hossein Kargaran, Nafiseh Nikeghbal, Jing Yang, and Nedjma Ousidhoum. Insights from the iclr peer review and rebuttal process.arXiv preprint arXiv:2511.15462, 2025
-
[16]
Derivation of new readability formulas (automated readability index, fog count and flesch reading ease formula) for navy enlisted personnel
J Peter Kincaid, Robert P Fishburne Jr, Richard L Rogers, and Brad S Chissom. Derivation of new readability formulas (automated readability index, fog count and flesch reading ease formula) for navy enlisted personnel. Technical report, 1975
1975
-
[17]
Delving into llm-assisted writing in biomedical publications through excess vocabulary.Science Advances, 11(27):eadt3813, 2025
Dmitry Kobak, Rita González-Márquez, Emőke-Ágnes Horvát, and Jan Lause. Delving into llm-assisted writing in biomedical publications through excess vocabulary.Science Advances, 11(27):eadt3813, 2025
2025
-
[18]
Computing krippendorff’s alpha-reliability
Klaus Krippendorff. Computing krippendorff’s alpha-reliability. 2011. URLhttps: //api.semanticscholar.org/CorpusID:59901023
2011
-
[19]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[20]
Weixin Liang, Zachary Izzo, Yaohui Zhang, Haley Lepp, Hancheng Cao, Xuandong Zhao, Lingjiao Chen, Haotian Ye, Sheng Liu, Zhi Huang, et al. Monitoring ai-modified content at scale: A case study on the impact of chatgpt on ai conference peer reviews. arXiv preprint arXiv:2403.07183, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Towards multimodal data-driven scientific discovery powered by llm agents
Fan Liu, Xiaozhao Zeng, and Hao Liu. Towards multimodal data-driven scientific discovery powered by llm agents. In The Fourteenth International Conference on Learning Representations, 2026. 11
2026
-
[22]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Agent reviewers: Domain-specific multimodal agents with shared memory for paper review
Kai Lu, Shixiong Xu, Jinqiu Li, Kun Ding, and Gaofeng Meng. Agent reviewers: Domain-specific multimodal agents with shared memory for paper review. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learning, volu...
2025
-
[24]
pypdfium2
pypdfium2 team. pypdfium2. https://github.com/pypdfium2-team/pypdfium2, 2026
2026
-
[25]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https://qwen.ai/blog?id=qwen3.5
2026
-
[26]
The good, the bad and the constructive: Automatically measuring peer review’s utility for authors
Abdelrahman Sadallah, Tim Baumgärtner, Iryna Gurevych, and Ted Briscoe. The good, the bad and the constructive: Automatically measuring peer review’s utility for authors. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 28979–29009, 2025
2025
-
[27]
Gaurav Sahu, Hugo Larochelle, Laurent Charlin, and Christopher Pal. Reviewertoo: Should ai join the program committee? a look at the future of peer review.arXiv preprint arXiv:2510.08867, 2025
-
[28]
C. Shannon, B. C. Millar, and J. E. Moore. Improving biomedical science literacy and patient-directed knowledge of tuberculosis (tb): A cross-sectional infodemiology study examining readability of patient-facing tb information.British Journal of Biomedical Science, 81:13566, Oct 2024. doi: 10.3389/bjbs.2024.13566
-
[29]
Peer review as a multi-turn and long-context dialogue with role-based interactions
Cheng Tan, Dongxin Lyu, Siyuan Li, Zhangyang Gao, Jingxuan Wei, Siqi Ma, Zicheng Liu, and Stan Z Li. Peer review as a multi-turn and long-context dialogue with role-based interactions. arXiv preprint arXiv:2406.05688, 2024
-
[30]
DeepSeek-OCR: Contexts Optical Compression
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression. arXiv preprint arXiv:2510.18234, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Iclr statistics, 2025
Jing Yang. Iclr statistics, 2025. URL https://papercopilot.com/statistics/ iclr-statistics
2025
-
[32]
Neurips statistics, 2025
Jing Yang. Neurips statistics, 2025. URLhttps://papercopilot.com/statistics/ neurips-statistics
2025
-
[33]
Sungduk Yu, Man Luo, Avinash Madusu, Vasudev Lal, and Phillip Howard. Is your paper being reviewed by an llm? benchmarking ai text detection in peer review.arXiv preprint arXiv:2502.19614, 2025
-
[34]
arXiv preprint arXiv:2505.07920
Daoze Zhang, Zhijian Bao, Sihang Du, Zhiyi Zhao, Kuangling Zhang, Dezheng Bao, and Yang Yang. Re2: A consistency-ensured dataset for full-stage peer review and multi-turn rebuttal discussions.arXiv preprint arXiv:2505.07920, 2025. 12 Table 3:Dataset statistics for ICLR and NeurIPS.The collected counts closely match external reports [30, 31]. Note that due...
-
[35]
** A t o m i z a t i o n :** Split each section into a JSON array of i n d i v i d u a l points , split it into se par at e entries based on logical a r g u m e n t s
-
[36]
filler
** Ve rb ati m Fi de li ty (1:1) :** Copy the text exactly . Do NOT paraphrase , do NOT fix typos , and do NOT remove any " filler " words
-
[37]
** F o r m a t t i n g :** P res er ve all LaTeX ( e . g . , O(n2)) and M ark do wn f o r m a t t i n g
-
[38]
S t r e n g t h s
** Output :** Return ONLY a valid JSON object . No pr ea mbl e or p o s t s c r i p t .\ n \ nReview text :\ n { context } Listing 3: Prompt for extracting atomic strengths and weaknesses from generated reviews. Atomic Extraction Prompt (Human): You are a precise s c i e n t i f i c data e x t r a c t i o n engine . Your task is to parse c o n f e r e n c...
-
[39]
however
** A t o m i c i t y & Self - C o n t a i n e d n e s s :** Each entry must express one complete , self - c o n t a i n e d unit of i n f o r m a t i o n - meaning it in cl ude s both the claim AND its s u p p o r t i n g reasoning , evidence , or q u a l i f i c a t i o n as stated by the rev ie wer . Apply the f o l l o w i n g tests before s p l i t t ...
-
[40]
While the method is elegant , [ we akn es s ]
** Near - Ve rb ati m :** Copy the reviewe r ’s wording as closely as po ssi bl e . You MAY : - Trim pure filler praise at the start ( e . g . " While the method is elegant , [ we akn es s ]" →keep only the w ea kne ss clause ) . - Remove t r a n s i t i o n a l openers that r e f e r e n c e prior entries ( e . g . " Additionally ," " Furthermore ,") whe...
-
[41]
** F o r m a t t i n g :** P res er ve all LaTeX ( e . g . , O(n2)) and M ark do wn exactly as written
-
[42]
X is good , but Y is lacking
** C l a s s i f i c a t i o n :** When a s t a t e m e n t c on tai ns both a po sit iv e and a ne gat iv e aspect joined by co nt ras t ( e . g . " X is good , but Y is lacking ") , split on the c ont ra st and assign each clause to its correct list . If a s t a t e m e n t is g e n u i n e l y a m b i g u o u s in polarity , place it in " w e a k n e s s e s "
-
[43]
s t r e n g t h s
** Output :** Return ONLY a valid JSON object with exactly two keys : ‘" s t r e n g t h s " ‘ and ‘" w e a k n e s s e s " ‘ , each c o n t a i n i n g an array of strings . No preamble , postscript , or ma rk dow n code fences . \ n \ nReview text :\ n { context } Listing 4: Prompt for extracting atomic strengths and weaknesses from human reviews. I.1 H...
2025
-
[44]
Be sure to give y ou rse lf s u f f i c i e n t time for this step
Read the paper : It ’s i m p o r t a n t to c a r e f u l l y read through the entire paper , and to look up any related work and c i t a t i o n s that will help you c o m p r e h e n s i v e l y eva lu ate it . Be sure to give y ou rse lf s u f f i c i e n t time for this step
-
[45]
- Strong points : is the s u b m i s s i o n clear , t e c h n i c a l l y correct , e x p e r i m e n t a l l y rigorous , reproducible , does it present novel fi nd ing s ( e
While reading , c ons id er the f o l l o w i n g : - O b j e c t i v e of the work : What is the goal of the paper ? Is it to better address a known a p p l i c a t i o n or problem , draw a t t e n t i o n to a new a p p l i c a t i o n or problem , or to i n t r o d u c e and / or explain a new t h e o r e t i c a l finding ? A c o m b i n a t i o n of...
-
[46]
Answer four key q u e s t i o n s for yourself , to make a r e c o m m e n d a t i o n to Accept or Reject : - What is the sp eci fi c qu es tio n and / or problem tackled by the paper ? - Is the a pp roa ch well motivated , i n c l u d i n g being well - placed in the l i t e r a t u r e ? - Does the paper support the claims ? This in clu de s d e t e r ...
-
[47]
S t r e n g t h s
Write your review i n c l u d i n g the f o l l o w i n g i n f o r m a t i o n : - S u m m a r i z e what the paper claims to c o n t r i b u t e . Be p osi ti ve and c o n s t r u c t i v e . - List strong and weak points of the paper . Be as c o m p r e h e n s i v e as pos si ble . - Clearly state your initial r e c o m m e n d a t i o n ( accept or r...
2025
-
[48]
Dataset Bias Mitigation: How might the method be adapted to minimize the impact of dataset bias on the discovered discriminative features? Could domain-specific constraints be incorporated? - *Score Impact*: A compelling answer could increase confidence in the method’s robustness. 2.Scalability: How does the method scale with higher-resolution images or l...
-
[49]
visual algebraic conditioning
Could you provide a more detailed explanation of how the "visual algebraic conditioning" works in practice, including the specific formula used for calculating the direction∆c? What are the limitations of this approach, and are there alternative methods for deriving this direction that could be explored? *Increased confidence would come from a more detail...
-
[50]
A clear statement of which components were tuned for which methods would strengthen fairness
Domain tuning and baseline parity: Did you allow comparable domain adaptation (e.g., LoRA or analogous adapters) for the baselines, especially TI + EF-DDPM and Concept Sliders? If not, please provide results with matched adaptation or justify why this is infeasible. A clear statement of which components were tuned for which methods would strengthen fairness
-
[51]
Embedding and inversion details: Which CLIP (or CLIP-like) image encoder variant backs the diffusion decoder (e.g., ViT-B/16/32, training dataset)? What CFG scales and inversion hyperparameters were used per dataset? How sensitive are results to these choices? Providing a small ablation or ranges would help
-
[52]
where the change occurred,
Success Ratio validity: How often do counterfactuals achieve classifier flips via background/context changes rather than core object features? Beyond the qualitative bias examples, can you quantify this (e.g., with a simple foreground mask analysis, human ratings of “where the change occurred,” or testing on debiased splits)?
-
[53]
Baseline completeness: Could you include an image-prompt adapter baseline (e.g., IP-Adapter-style conditioning) and a recent prompt-to-prompt edit method configured for image guidance to better match your modality? Even a small-scale comparison on scientific datasets would make the empirical case stronger
-
[54]
We manipulate the conditioning space using Equation 5, adjusting the manipulation guidance scale per dataset
User study details and robustness: Please clarify recruitment, compensation, randomization, exclusion criteria (if any), and the exact statistical tests used (including effect sizes). Would the results hold with longer study time, more participants, or retention tests (delayed post-test) to measure knowledge transfer/durability? If the authors can (i) equ...
2022
-
[55]
Teaching Humans Subtle Differences with DIFFusion
There is an issue with paper duplication. The author submitted two nearly identical papers. I am reviewing Paper 1: Paper titled "Teaching Humans Subtle Differences with DIFFusion" with Paper ID 8917
-
[56]
For instance, the first two sentences of the abstract are nearly identical
Many details indicate this paper was written hastily. For instance, the first two sentences of the abstract are nearly identical
-
[57]
Learning to Teach by Learning
Related work is lacking in machine teaching, which is the most relevant field. Relevant works include: "Learning to Teach by Learning" (2021), "Machine Teaching Optimized by Human Feedback" (2022), and "Deep Learning Examples for Visual Classification" (2023)
2021
-
[58]
As of now, it only shows three real images, making it difficult to comprehend
The teaser figure is confusing. As of now, it only shows three real images, making it difficult to comprehend. In my opinion, the authors intended to use an innovative concept image, but the implementation didn’t turn out well. Therefore, I suggest removing this figure
-
[59]
Scientific Datasets
Is it reasonable to have both "Scientific Datasets" and "Regular Datasets" as separate sections in Table 2? I think these are only used during training, so they shouldn’t appear in separate sections in Table 2. Moreover, the LPIPS values in Table 2 differ significantly. This metric should not be used as a comparison for this method
-
[60]
baselines
In Lines 296-307, seven "baselines" are discussed, but only the best one is implemented. I find the authors’ approach respectable, as they attempt to assess the baseline’s 95% confidence intervals in Table 3. However, I believe they are overestimating their baselines. Their baseline shows a much higher improvement, suggesting that it may be poorly chosen
-
[61]
There is no need for a description in the Method section
Domain tuning is a well-studied method. There is no need for a description in the Method section. Therefore, I recommend removing this part
-
[62]
Since this method requires domain tuning on each specific dataset, it cannot be generalized and remains a domain-specific method, which is a significant drawback
-
[63]
Interpolation
How are the "Interpolation" values determined? In Figure 5,∆c can be interpreted as the distance between two different classification categories. By varyingw, you get different distances between the two categories. Therefore, I believe the w = 0 condition is crucial. I don’t think the authors should hide it
-
[64]
Given that there was domain adaptation, I expected the authors to demonstrate clear differences
In Figure 7, I didn’t see any noticeable differences between the two categories. Given that there was domain adaptation, I expected the authors to demonstrate clear differences. However, I observed very similar spotty patterns between the two categories. Therefore, I do not believe the method is valid. For instance, the authors’ own cited image shows clea...
-
[65]
This idea is interesting
This paper presents a novel visual teaching method, utilizing counterfactuals. This idea is interesting
-
[66]
The combination of∆c and z is reasonable
-
[67]
51 ## Weaknesses
The written expression is good with strong cohesion, making this paper easy to read. 51 ## Weaknesses
-
[68]
Baseline performance is too weak, and domain adaptation is required, making this paper somewhat hard to read
-
[69]
## Questions
The authors’ explanation for differentiation is somewhat insufficient and requires further improvement. ## Questions
-
[70]
Is that necessary?
The authors have included so many URLs in the paper, which could potentially expose their identities. Is that necessary?
-
[71]
Does LoRA have information leakage issues? Discussing this would be better
-
[72]
In my opinion, the baselines are too weak, making it difficult to compare their method with this baseline
There are many ambiguities in the baselines. In my opinion, the baselines are too weak, making it difficult to compare their method with this baseline. I think the authors aim to confuse reviewers into thinking their method is strong just because the baseline is weak. ## Limitations
-
[73]
This method requires domain adaptation and corresponding training
-
[74]
The baseline performance is too poor, making it difficult to compare with this method
-
[75]
structurally-induced dependence between labels and features: the dependence created by the structure is much stronger than the dependence generated by noise
There are potential information leakage issues in the baseline. Overall, I believe the authors will completely rewrite this paper. The current version has many drawbacks. Therefore, I recommend rejecting this paper. If the authors address my questions, I might increase my score. However, the fundamental improvements required for this paper may go beyond t...
-
[76]
perfect reconstruction
Data Availability:Regarding Checklist Q5, you have marked [Yes] but admit the Black Hole dataset is restricted. What specific conditions allow other researchers to access the Black Hole data? Will the reviewers have access to reproduce these results on this specific dataset? 2.User Study Methodology:The user study is conducted visually via video transitio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.