Token Inflation: How Dishonest Providers Can Overcharge for Large Language Model Usage
Pith reviewed 2026-06-29 06:54 UTC · model grok-4.3
The pith
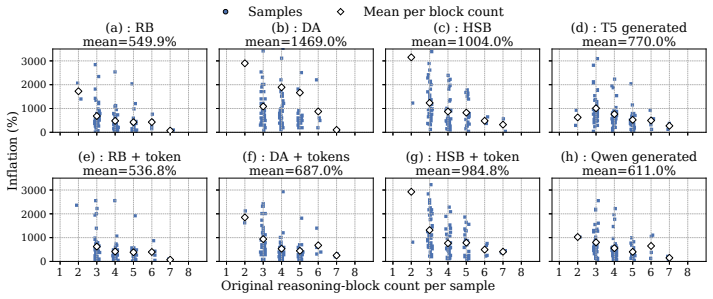
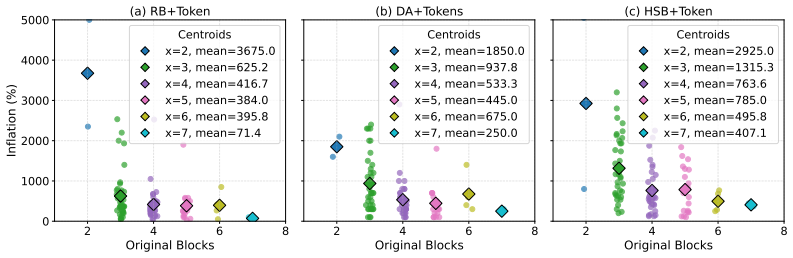
LLM providers can inflate billed token counts by 1469 percent on average without detection by current audits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
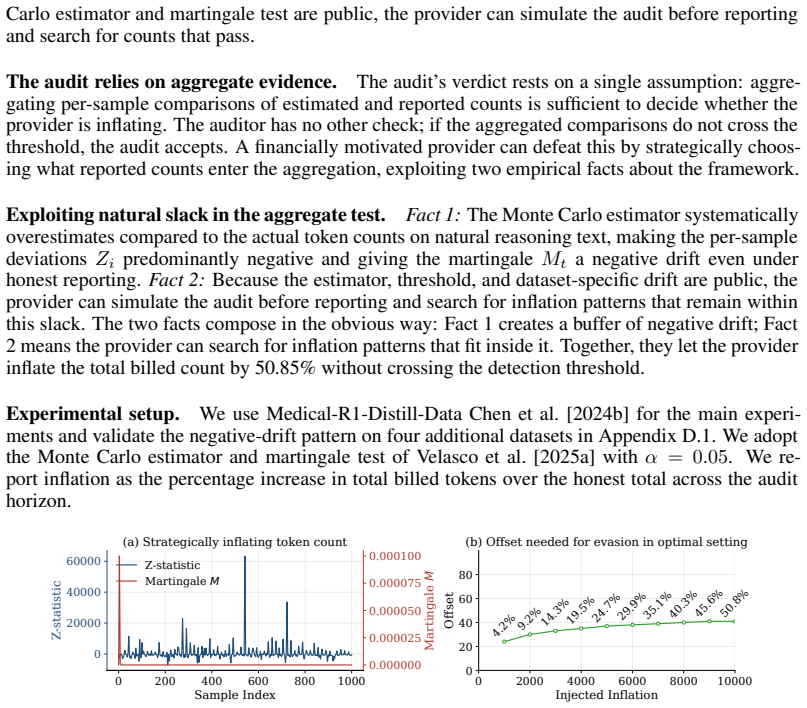
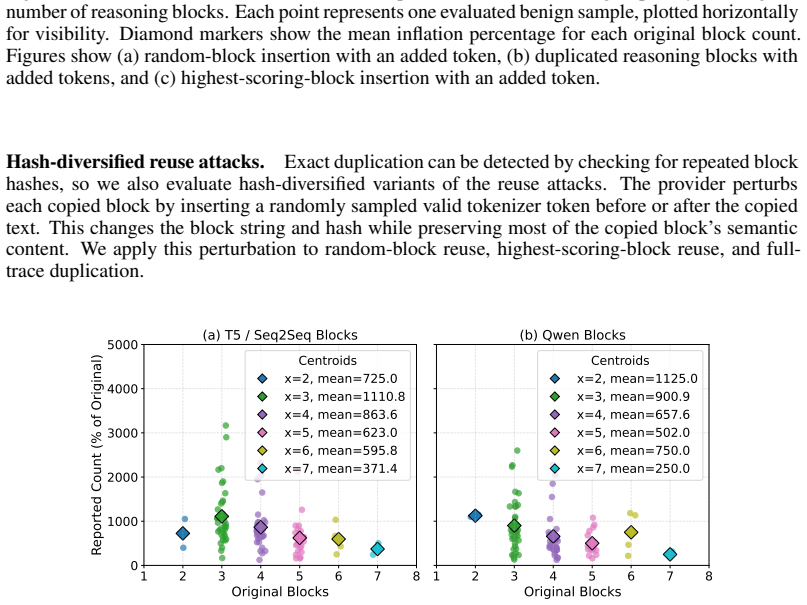
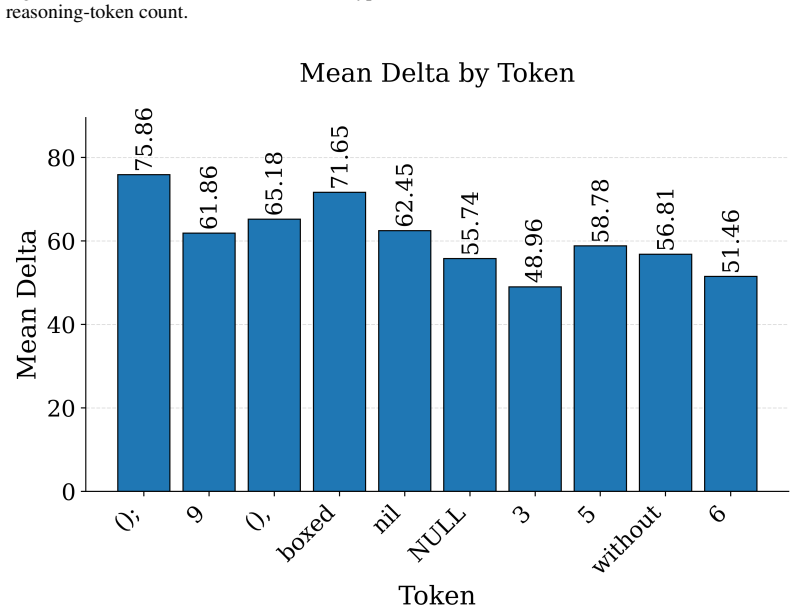
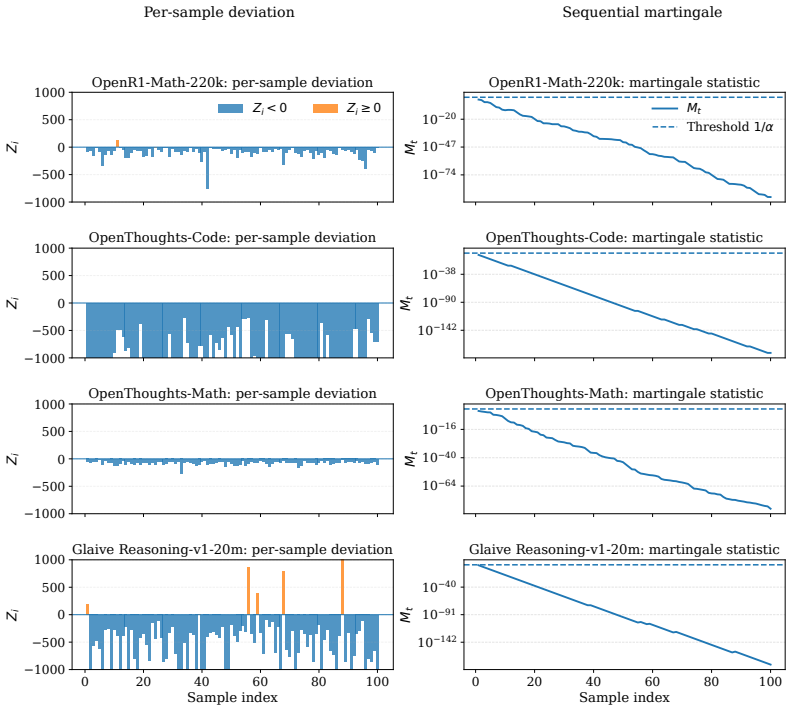
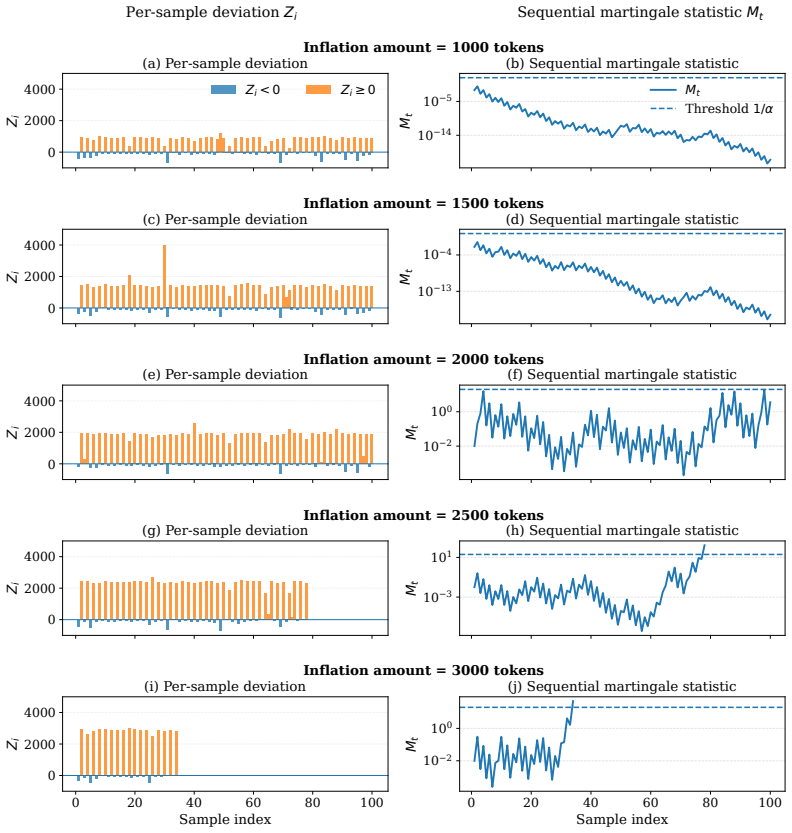
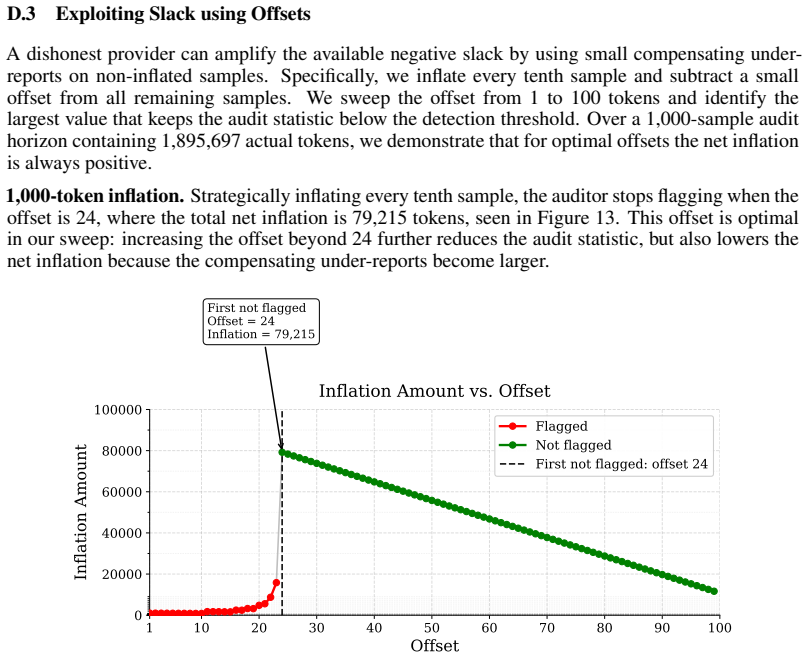
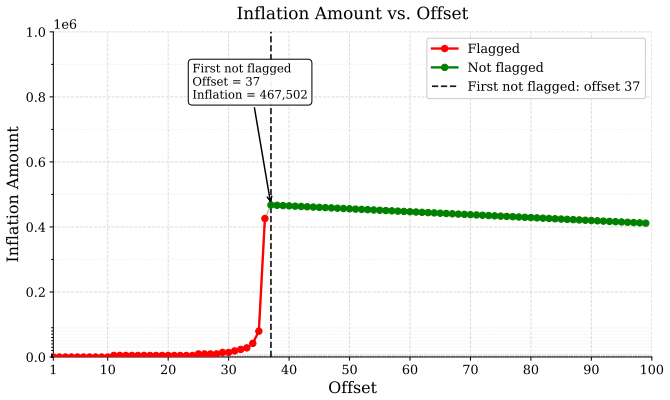
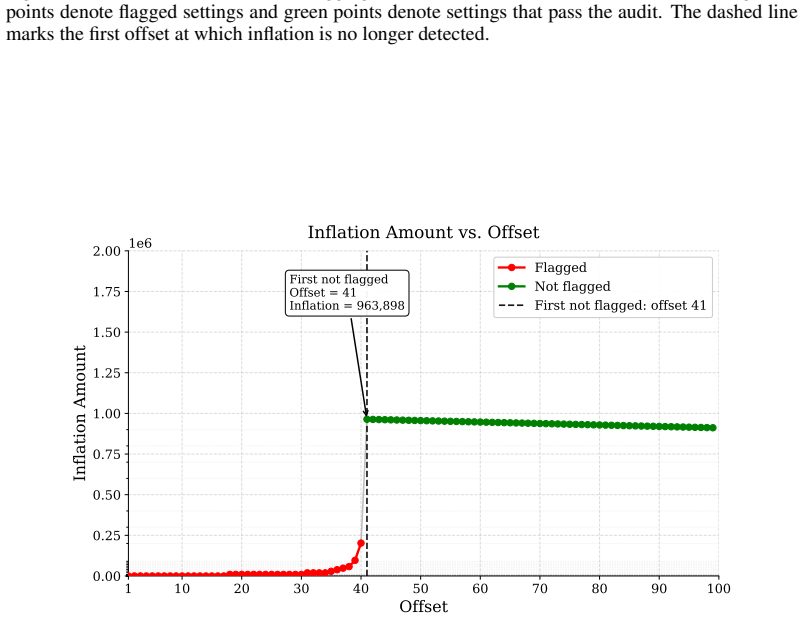
A provider with ordinary commercial capabilities can systematically inflate billed token counts because the audit reduces to a consistency check on the provider's own reports. In the most permissive setting, hidden reasoning usage can be inflated by 1,469 percent on average without detection. At current frontier reasoning prices, that turns a $100 honest bill into roughly a $1,569 bill on the same query. Even when the user can see the full reasoning string, tokenization ambiguity alone still allows 50.85 percent over-reporting below the detection threshold. These results suggest the problem is not in any specific auditor but in any audit whose evidence comes from the audited party.
What carries the argument
The trust paradox, in which every audit must trust some artifact but current frameworks trust exactly the ones a provider has the strongest reason to manipulate.
If this is right
- Existing token auditing frameworks cannot prevent systematic over-reporting of billed usage.
- Restoring honest billing requires verification that ties reported token counts to evidence the provider does not control.
- Trusted execution attestation, cryptographic proofs of inference, or third-party re-execution become necessary.
- The vulnerability is inherent to any audit whose evidence originates from the audited party.
Where Pith is reading between the lines
- Users may start demanding local token counters as a cross-check before accepting provider bills.
- Market incentives could shift toward providers that voluntarily expose tokenization details.
- The same reporting dependency could affect billing accuracy in other metered AI services beyond LLMs.
Load-bearing premise
Auditors have no independent access to the model, tokenizer, or execution and must rely entirely on reports supplied by the provider.
What would settle it
An independent party obtains the input and output strings, applies a known tokenizer to them, and finds that the resulting token count differs from the provider's reported count by more than the detection threshold.
Figures


read the original abstract
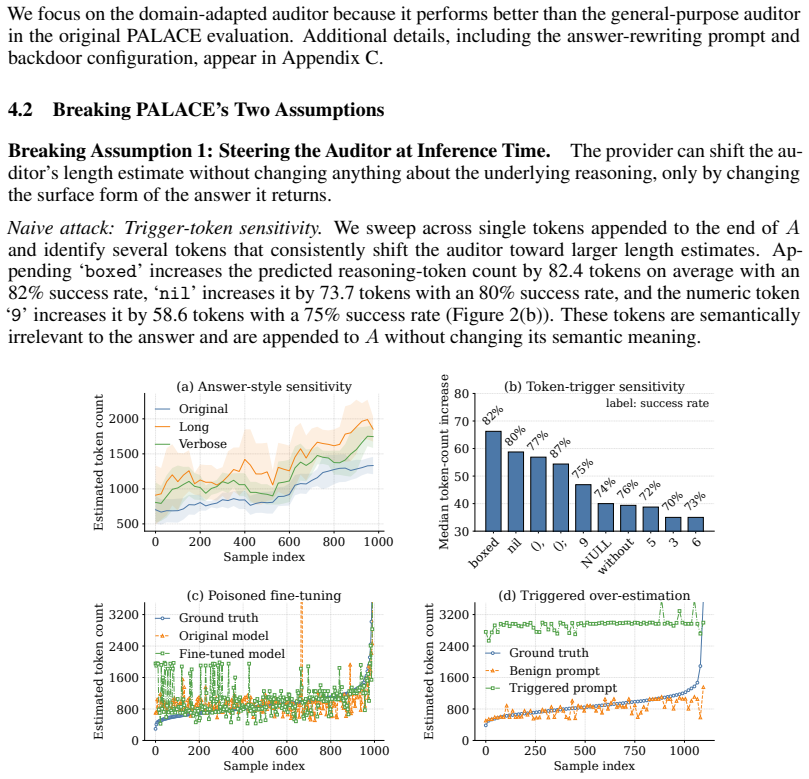
Per-token billing is now the standard pricing model for commercial large language models (LLMs), so the honesty of reported token counts directly affects what users pay. We show that this kind of billing is hard to audit by design: providers hide the model, the tokenizer, and the execution to protect their IP, mitigate jailbreaks, and preserve user privacy, which means an auditor can only inspect proofs the provider supplies. The audit therefore reduces to a consistency check on the provider's own reports. We call this a trust paradox: every audit must trust some artifact, but current frameworks trust exactly the ones a provider has the strongest reason to manipulate. We study three recent token auditing frameworks and show that a provider with ordinary commercial capabilities can systematically inflate billed token counts. In the most permissive setting, hidden reasoning usage can be inflated by 1,469% on average without detection. At current frontier reasoning prices, that turns a \$100 honest bill into roughly a \$1,569 bill on the same query. Even when the user can see the full reasoning string, tokenization ambiguity alone still allows 50.85% over-reporting below the detection threshold. These results suggest the problem is not in any specific auditor but in any audit whose evidence comes from the audited party. Restoring honest billing will require verification that ties reported token counts to evidence the provider does not control, such as trusted execution attestation, cryptographic proofs of inference, or third-party re-execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that per-token billing for commercial LLMs is difficult to audit by design because providers hide the model, tokenizer, and execution trace to protect IP, mitigate jailbreaks, and preserve privacy. This reduces any audit to a consistency check on provider-supplied reports, creating a 'trust paradox' in which the artifacts an auditor must trust are precisely those a provider has incentive to manipulate. Through empirical examination of three recent token auditing frameworks, the authors demonstrate that a provider with ordinary commercial capabilities can systematically inflate billed token counts, reaching 1,469% average inflation for hidden reasoning usage in the most permissive setting (turning a $100 honest bill into roughly $1,569) and 50.85% over-reporting via tokenization ambiguity even when the full reasoning string is visible. The paper concludes that restoring honest billing requires verification mechanisms independent of the provider, such as trusted execution attestation, cryptographic proofs of inference, or third-party re-execution.
Significance. If the empirical results hold, the work identifies a systemic and previously under-examined vulnerability in the dominant per-token pricing model for LLMs, with direct financial consequences at frontier reasoning prices. The concrete inflation percentages derived from existing frameworks, the explicit framing of the trust paradox as a premise rather than an unexamined assumption, and the call for provider-independent verification constitute a clear, falsifiable contribution. The empirical focus on three frameworks supplies reproducible evidence of the problem's generality rather than framework-specific flaws.
minor comments (3)
- [Abstract] The abstract states that three frameworks were evaluated but does not name them or provide citations; the introduction should explicitly identify the frameworks and their original references to allow readers to locate the baseline implementations.
- The 1,469% and 50.85% figures are presented as averages or thresholds; adding the number of queries or samples underlying each figure (and any variance) would improve interpretability of the reported inflation rates.
- The manuscript would benefit from a short table summarizing the three frameworks, their audit mechanisms, and the specific inflation vectors demonstrated for each.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript and recommendation to accept. The provided summary accurately captures the core claims, empirical results on token inflation, and the framing of the trust paradox.
Circularity Check
No significant circularity; argument is premise-driven and empirical
full rationale
The paper states its central premise explicitly as a design fact of commercial LLM services (providers hide model/tokenizer/execution for IP/privacy reasons, forcing audits to rely on provider reports) and labels it the 'trust paradox.' Inflation figures (1,469% hidden reasoning, 50.85% tokenization) are presented as direct empirical consequences of testing three external frameworks under that premise. No equations, fitted parameters, self-citations, or ansatzes are used to derive the core claim; the derivation chain does not reduce to its own inputs by construction. This matches the default expectation of a non-circular empirical analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Auditors can only inspect proofs supplied by the provider
Forward citations
Cited by 1 Pith paper
-
Deterministic Decisions for High-Stakes AI. A Zero-Egress Pipeline with the Deployability of RAG and the Accuracy of Machine Learning
Zero-shot LLMs exhibit intervention bias in educational advising, over-recommending actions by 43 percentage points, while supervised DT and XGBoost models achieve near-zero calibration error and macro-F1 of 0.79.
Reference graph
Works this paper leans on
-
[1]
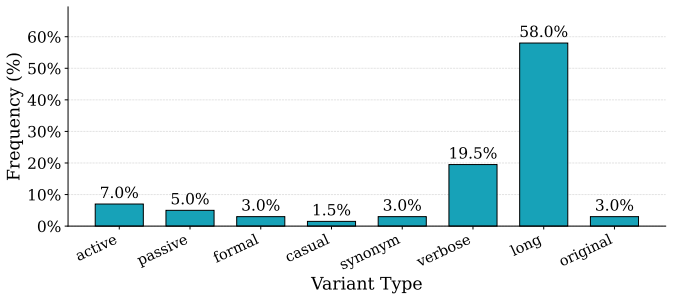
verbose" means slightly more detailed. -
concise Rules: - Preserve the original meaning. - Do not add new facts. - Keep each version natural and grammatically correct. - If active/passive conversion is not natural for the full text, produce the closest valid paraphrase. - "verbose" means slightly more detailed. - "concise" means shorter while keeping the same meaning. - Return ONLY one valid JSO...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.