FakeVLM-R1: Internalizing Physical Laws via CoT for Synthetic Image Detection
Pith reviewed 2026-06-29 07:57 UTC · model grok-4.3
The pith
FakeVLM-R1 uses critical chain-of-thought reasoning anchored in physical laws to detect synthetic images with causal understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
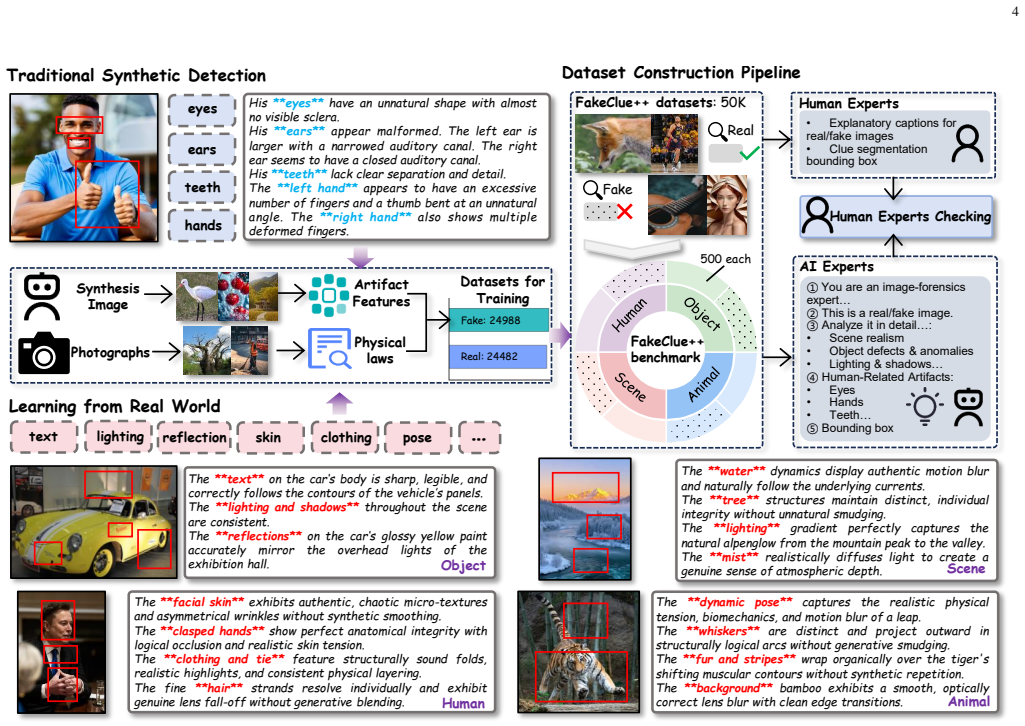
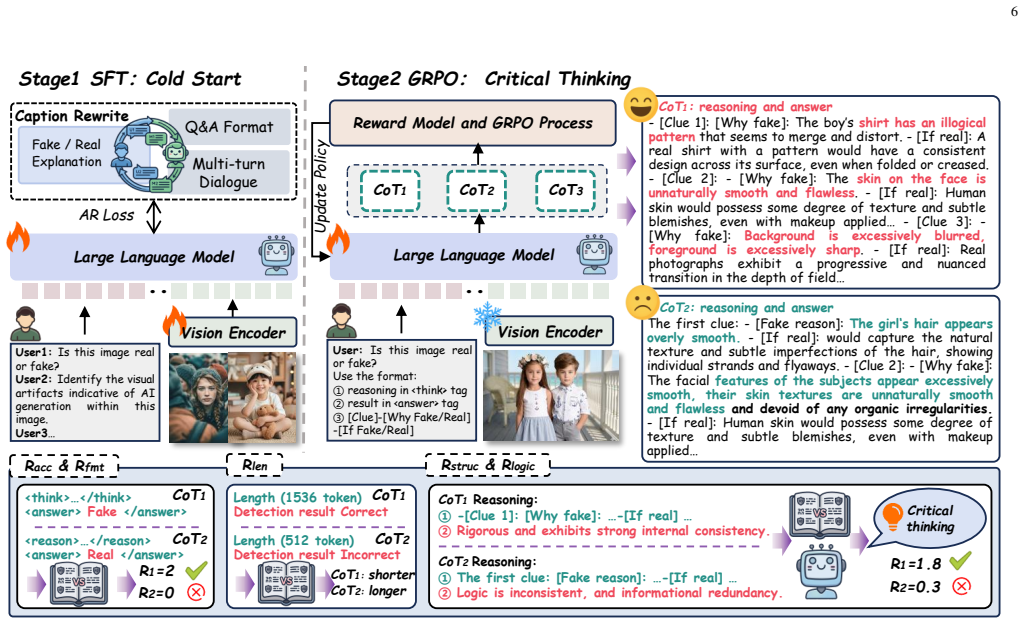
FakeVLM-R1 internalizes physical laws by executing bidirectional dialectical reasoning in its critical thinking CoT, where it proposes forgery hypotheses while invoking physical commonsense to build authenticity counter-proofs, trained via GRPO on the FakeClue++ dataset that provides unified authenticity anchors from physical laws of authentic images.
What carries the argument
The Critical Thinking Chain-of-Thought mechanism, which enforces bidirectional dialectical reasoning by requiring both forgery hypothesis and physical authenticity counter-proof.
If this is right
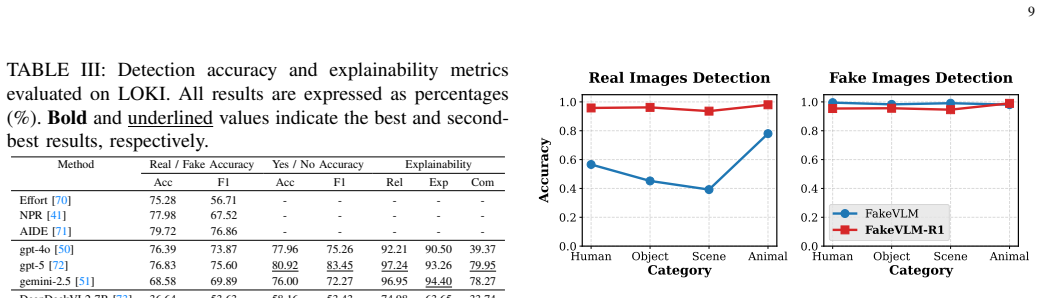
- It achieves state-of-the-art performance across multiple benchmarks for synthetic image detection.
- The detection becomes high-precision and logically interpretable.
- It resolves the over-rejection bias of existing methods against real images.
- It demonstrates improved generalization and robustness against perturbations.
Where Pith is reading between the lines
- If the physical anchors work as intended, similar CoT structures could be applied to other tasks where causal physical reasoning is needed, such as video forgery detection.
- The approach might help mitigate explanatory hallucinations in multimodal models more broadly by enforcing counter-proof reasoning.
- Further tests on datasets without explicit physical annotations could reveal how much the training transfers the internalized laws.
Load-bearing premise
The annotations guided by physical laws in the dataset provide a genuine causal anchor that enables the model to internalize physical commonsense rather than just improving statistical pattern matching.
What would settle it
An experiment comparing the model's performance on physical reasoning tasks with and without the physical laws annotations in training, measuring if the causal counter-proof capability disappears when annotations are removed.
Figures



read the original abstract
The development of generative artificial intelligence technologies has propelled the visual realism of synthetic images to an unprecedented level. Although current interpretable detection methods based on Large Multimodal Models (LMMs) have made certain progress, they still rely on imitation learning derived from massive volumes of forged data. Consequently, they lack genuine causal reasoning capabilities and are prone to explanatory hallucinations. To overcome this bottleneck, we propose FakeVLM-R1, aiming to endow the model with human-like critical thinking capabilities when performing synthetic detection tasks. Building upon Supervised Fine-Tuning (SFT), this framework integrates Group Relative Policy Optimization (GRPO) with a Critical Thinking Chain-of-Thought (CoT) mechanism. During the inference phase, the model executes a "bidirectional dialectical reasoning" process: while proposing a forgery hypothesis, it must simultaneously invoke physical commonsense to construct an authenticity counter-proof. Furthermore, we constructed the FakeClue++ dataset with high-quality samples, which extensively introduces annotations guided by the physical laws of authentic images, providing a unified authenticity anchor for the model. Experiments confirm that FakeVLM-R1 achieves SOTA performance the evaluated models across multiple benchmarks. It not only achieves high-precision, logically interpretable detection but also resolves the over-rejection bias of existing methods against real images, demonstrating generalization and robustness against perturbations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FakeVLM-R1, which augments supervised fine-tuning with Group Relative Policy Optimization and a Critical Thinking Chain-of-Thought mechanism that performs bidirectional dialectical reasoning (forgery hypothesis plus physical-commonsense counter-proof). It introduces the FakeClue++ dataset containing physical-law annotations on authentic images to serve as a unified authenticity anchor. The central claims are that this framework yields SOTA detection performance across benchmarks, produces logically interpretable outputs, resolves over-rejection bias against real images, and demonstrates generalization and robustness to perturbations.
Significance. If the reported performance gains and bias-resolution claims are substantiated by rigorous experiments and ablations, the approach could advance interpretable synthetic-image detection by shifting from pure imitation learning toward models that internalize physical constraints, a direction with potential value for forensic and content-authenticity applications.
major comments (3)
- [Abstract] Abstract: the claim that FakeVLM-R1 'achieves SOTA performance the evaluated models across multiple benchmarks' is unsupported by any reported baselines, metrics, error bars, dataset sizes, or statistical tests, so the central empirical claim cannot be evaluated.
- [Abstract] Abstract (paragraph on dataset construction): no ablation that removes the physical-laws annotations, no analysis of whether generated counter-proofs actually reference those annotations, and no counterfactual replacing physical guidance with generic captions are described, leaving the causal mechanism (internalization versus improved pattern matching) untested.
- [Abstract] Abstract: the assertion that the method 'resolves the over-rejection bias of existing methods against real images' is presented without quantitative evidence (e.g., false-positive rates on real-image test sets or comparison tables), making the bias-resolution claim load-bearing yet unevaluable.
minor comments (1)
- [Abstract] Abstract: the sentence 'achieves SOTA performance the evaluated models' is missing a preposition such as 'among'.
Simulated Author's Rebuttal
We thank the referee for these focused comments on the abstract. Each point identifies a legitimate gap in how claims are presented, and we will revise the manuscript to address them directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that FakeVLM-R1 'achieves SOTA performance the evaluated models across multiple benchmarks' is unsupported by any reported baselines, metrics, error bars, dataset sizes, or statistical tests, so the central empirical claim cannot be evaluated.
Authors: We agree that the abstract as written does not contain the supporting quantitative details. The experiments section of the manuscript reports the relevant comparisons, but the abstract itself must be self-contained. We will revise the abstract to include the key metrics, baseline names, dataset sizes, error bars, and statistical test results that substantiate the SOTA claim. revision: yes
-
Referee: [Abstract] Abstract (paragraph on dataset construction): no ablation that removes the physical-laws annotations, no analysis of whether generated counter-proofs actually reference those annotations, and no counterfactual replacing physical guidance with generic captions are described, leaving the causal mechanism (internalization versus improved pattern matching) untested.
Authors: The current manuscript does not contain the requested ablations or counterfactual analyses. We will add them in the revision: (1) an ablation that removes the physical-law annotations, (2) explicit tracing of whether generated counter-proofs cite the annotations, and (3) a control condition that replaces physical guidance with generic captions. These additions will directly test the claimed causal mechanism. revision: yes
-
Referee: [Abstract] Abstract: the assertion that the method 'resolves the over-rejection bias of existing methods against real images' is presented without quantitative evidence (e.g., false-positive rates on real-image test sets or comparison tables), making the bias-resolution claim load-bearing yet unevaluable.
Authors: We agree that the abstract currently offers no quantitative support for the bias-resolution claim. We will revise the abstract to report false-positive rates on real-image test sets for FakeVLM-R1 versus the compared methods, along with the relevant comparison table or numbers. revision: yes
Circularity Check
No circularity: empirical ML framework with no derivation chain or self-referential equations
full rationale
The provided abstract and description contain no equations, formal derivations, or load-bearing mathematical steps. The paper describes an SFT+GRPO training process on a new dataset (FakeClue++) and reports experimental SOTA results; these are empirical claims whose validity depends on ablations and benchmarks rather than any quantity reducing to its own inputs by construction. No self-citations, ansatzes, or uniqueness theorems are invoked in a way that collapses the central claim. This is the common case of a non-circular empirical paper; the reader's noted assumption about causal internalization is a question of experimental evidence, not circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Generative adversarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014
2014
-
[2]
Denoising Diffusion Probabilistic Models
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” 2020. [Online]. Available: https://arxiv.org/abs/2006.11239
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Improving image generation with better captions,
J. Betker, G. Goh, L. Jing, T. Brooks, J. Wang, L. Li, L. Ouyang, J. Zhuang, J. Lee, Y . Guoet al., “Improving image generation with better captions,”Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, vol. 2, no. 3, p. 8, 2023
2023
-
[4]
Z-image: An efficient image generation foundation model with single-stream diffusion transformer,
I. Team, H. Cai, S. Cao, R. Du, P. Gao, S. Hoi, Z. Hou, S. Huang, D. Jiang, X. Jin, L. Li, Z. Li, Z.-Y . Li, D. Liu, D. Liu, J. Shi, Q. Wu, F. Yu, C. Zhang, S. Zhang, and S. Zhou, “Z-image: An efficient image generation foundation model with single-stream diffusion transformer,”
-
[5]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
[Online]. Available: https://arxiv.org/abs/2511.22699
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”Advances in neural information processing systems, vol. 34, pp. 8780–8794, 2021
2021
-
[7]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[8]
Diffusion models in vision: A survey,
F.-A. Croitoru, V . Hondru, R. T. Ionescu, and M. Shah, “Diffusion models in vision: A survey,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 9, pp. 10 850–10 869, 2023
2023
-
[9]
J. Ye, L. Zhu, Y . Guo, D. Jiang, Z. Huang, Y . Zhang, Z. Yan, H. Fu, C. He, and W. Li, “Realgen: Photorealistic text-to-image generation via detector-guided rewards,”arXiv preprint arXiv:2512.00473, 2025
-
[10]
Mmfakebench: A mixed-source multimodal misinformation detection benchmark for lvlms,
X. Liu, Z. Li, P. Li, H. Huang, S. Xia, X. Cui, L. Huang, W. Deng, and Z. He, “Mmfakebench: A mixed-source multimodal misinformation detection benchmark for lvlms,”arXiv preprint arXiv:2406.08772, 2024
-
[11]
Deepfakes: Deceptions, mitigations, and opportunities,
M. Mustak, J. Salminen, M. Mäntymäki, A. Rahman, and Y . K. Dwivedi, “Deepfakes: Deceptions, mitigations, and opportunities,”Journal of Business Research, vol. 154, p. 113368, 2023
2023
-
[12]
Leveraging representations from intermediate encoder-blocks for synthetic image detection,
C. Koutlis and S. Papadopoulos, “Leveraging representations from intermediate encoder-blocks for synthetic image detection,” inEuropean Conference on computer vision. Springer, 2024, pp. 394–411
2024
-
[13]
Grpo-guard: Mitigating implicit over-optimization in flow matching via regulated clipping
K. Lin, Z. Yan, R. Chen, J. Ye, K.-Y . Zhang, Y . Zhou, P. Jin, B. Li, T. Yao, and S. Ding, “Seeing before reasoning: A unified framework for generalizable and explainable fake image detection,”arXiv preprint arXiv:2509.25502, 2025
-
[14]
Ivy-Fake: A Unified Explainable Framework and Benchmark for Image and Video AIGC Detection
C. Jiang, W. Dong, Z. Zhang, C. Si, F. Yu, W. Peng, X. Yuan, Y . Bi, M. Zhao, Z. Zhouet al., “Ivy-fake: A unified explainable framework and benchmark for image and video aigc detection,”arXiv preprint arXiv:2506.00979, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
OmniAID: Decoupling Semantic and Artifacts for Universal AI-Generated Image Detection in the Wild
Y . Guo, J. Ye, C. Zhang, H. Kang, H. Fu, C. He, and W. Li, “Omniaid: Decoupling semantic and artifacts for universal ai-generated image detection in the wild,”arXiv preprint arXiv:2511.08423, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Forgerynet: A versatile benchmark for comprehensive forgery analysis,
Y . He, B. Gan, S. Chen, Y . Zhou, G. Yin, L. Song, L. Sheng, J. Shao, and Z. Liu, “Forgerynet: A versatile benchmark for comprehensive forgery analysis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 4360–4369
2021
-
[17]
Genimage: A million-scale benchmark for detecting ai- generated image,
M. Zhu, H. Chen, Q. Yan, X. Huang, G. Lin, W. Li, Z. Tu, H. Hu, J. Hu, and Y . Wang, “Genimage: A million-scale benchmark for detecting ai- generated image,”Advances in neural information processing systems, vol. 36, pp. 77 771–77 782, 2023
2023
-
[18]
Drct: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images,
B. Chen, J. Zeng, J. Yang, and R. Yang, “Drct: Diffusion reconstruction contrastive training towards universal detection of diffusion generated images,” inForty-first International Conference on Machine Learning, 2024
2024
-
[19]
Wildfake: A large-scale and hierarchical dataset for ai-generated im- ages detection,
Y . Hong, J. Feng, H. Chen, J. Lan, H. Zhu, W. Wang, and J. Zhang, “Wildfake: A large-scale and hierarchical dataset for ai-generated im- ages detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 3500–3508
2025
-
[20]
Frepgan: robust deepfake detection using frequency-level perturbations,
Y . Jeong, D. Kim, Y . Ro, and J. Choi, “Frepgan: robust deepfake detection using frequency-level perturbations,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, no. 1, 2022, pp. 1060–1068
2022
-
[21]
A single simple patch is all you need for ai-generated image detection,
J. Chen, J. Yao, and L. Niu, “A single simple patch is all you need for ai-generated image detection,”arXiv preprint arXiv:2402.01123, 2024
-
[22]
Fakescope: Large multimodal expert model for transparent ai-generated image forensics,
Y . Li, Y . Tian, Y . Huang, W. Lu, S. Wang, W. Lin, and A. Rocha, “Fakescope: Large multimodal expert model for transparent ai-generated image forensics,” 2025. [Online]. Available: https: //arxiv.org/abs/2503.24267
-
[23]
Legion: Learning to ground and explain for synthetic image detection,
H. Kanget al., “Legion: Learning to ground and explain for synthetic image detection,” inProceedings of the IEEE/CVF International Con- ference on Computer Vision (ICCV), 2025
2025
-
[24]
Can chatgpt detect deepfakes? a study of using multimodal large language models for media forensics,
S. Jia, R. Lyu, K. Zhao, Y . Chen, Z. Yan, Y . Ju, C. Hu, X. Li, B. Wu, and S. Lyu, “Can chatgpt detect deepfakes? a study of using multimodal large language models for media forensics,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4324–4333
2024
- [25]
-
[26]
Fakebench: Probing explainable fake image detection via large mul- timodal models,
Y . Li, X. Liu, X. Wang, B. S. Lee, S. Wang, A. Rocha, and W. Lin, “Fakebench: Probing explainable fake image detection via large mul- timodal models,”IEEE Transactions on Information Forensics and Security, 2025
2025
-
[27]
X2-dfd: A framework for explainable and extendable deepfake detection,
Y . Chen, Z. Yan, G. Cheng, K. Zhao, S. Lyu, and B. Wu, “X2-dfd: A framework for explainable and extendable deepfake detection,”arXiv preprint arXiv:2410.06126, 2024
-
[28]
Aigi-holmes: Towards explainable and generalizable ai-generated image detection via multimodal large language models,
Z. Zhou, Y . Luo, Y . Wu, K. Sun, J. Ji, K. Yan, S. Ding, X. Sun, Y . Wu, and R. Ji, “Aigi-holmes: Towards explainable and generalizable ai-generated image detection via multimodal large language models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 18 746–18 758
2025
-
[29]
Spot the fake: Large multimodal model-based synthetic image detection with artifact explanation,
S. Wen, J. Ye, P. Feng, H. Kang, Z. Wen, Y . Chen, J. Wu, W. Wu, C. He, and W. Li, “Spot the fake: Large multimodal model-based synthetic image detection with artifact explanation,”arXiv preprint arXiv:2503.14905, 2025
-
[30]
Critique fine-tuning: Learning to cri- tique is more effective than learning to imitate, 2025,
Y . Wang, X. Yue, and W. Chen, “Critique fine-tuning: Learning to cri- tique is more effective than learning to imitate, 2025,”URL https://arxiv. org/abs/2501.17703
-
[31]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022. 14
2022
-
[32]
J. Ye, D. Jiang, Z. Wang, L. Zhu, Z. Hu, Z. Huang, J. He, Z. Yan, J. Yu, H. Liet al., “Echo-4o: Harnessing the power of gpt-4o synthetic images for improved image generation,”arXiv preprint arXiv:2508.09987, 2025
-
[33]
Gpt-imgeval: A comprehensive benchmark for diagnosing gpt4o in image generation,
Z. Yan, J. Ye, W. Li, Z. Huang, S. Yuan, X. He, K. Lin, J. He, C. He, and L. Yuan, “Gpt-imgeval: A comprehensive benchmark for diagnosing gpt4o in image generation,”arXiv preprint arXiv:2504.02782, 2025
-
[34]
J. He, J. Ye, Z. Huang, D. Jiang, C. Zhang, L. Zhu, R. Zhang, X. Zhang, and W. Li, “Mind-brush: Integrating agentic cognitive search and reasoning into image generation,”arXiv preprint arXiv:2602.01756, 2026
-
[35]
Cnn- generated images are surprisingly easy to spot... for now,
S.-Y . Wang, O. Wang, R. Zhang, A. Owens, and A. A. Efros, “Cnn- generated images are surprisingly easy to spot... for now,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 8695–8704
2020
-
[36]
Towards universal fake image detec- tors that generalize across generative models,
U. Ojha, Y . Li, and Y . J. Lee, “Towards universal fake image detec- tors that generalize across generative models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 24 480–24 489
2023
-
[37]
Detecting generated images by real images only,
X. Bi, B. Liu, F. Yang, B. Xiao, W. Li, G. Huang, and P. C. Cosman, “Detecting generated images by real images only,”arXiv preprint arXiv:2311.00962, 2023
-
[38]
Generative adversarial networks,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial networks,” Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020
2020
-
[39]
Rich and poor texture con- trast: A simple yet effective approach for ai-generated image detection,
N. Zhong, Y . Xu, Z. Qian, and X. Zhang, “Rich and poor texture con- trast: A simple yet effective approach for ai-generated image detection,” arXiv preprint arXiv:2311.12397, vol. 3, no. 6, p. 1, 2023
-
[40]
Fakecatcher: Detection of synthetic portrait videos using biological signals,
U. A. Ciftci, I. Demir, and L. Yin, “Fakecatcher: Detection of synthetic portrait videos using biological signals,”IEEE transactions on pattern analysis and machine intelligence, 2020
2020
-
[41]
Wavelet-packets for deepfake image analysis and detection,
M. Wolter, F. Blanke, R. Heese, and J. Garcke, “Wavelet-packets for deepfake image analysis and detection,”Machine Learning, vol. 111, no. 11, pp. 4295–4327, 2022
2022
-
[42]
Rethinking the up- sampling operations in cnn-based generative network for generalizable deepfake detection,
C. Tan, Y . Zhao, S. Wei, G. Gu, P. Liu, and Y . Wei, “Rethinking the up- sampling operations in cnn-based generative network for generalizable deepfake detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 28 130–28 139
2024
-
[43]
Visual veracity: Advancing ai-generated image detection with convolutional neural networks,
A. S. Gupta, K. P. Shreneter, and S. Sehgal, “Visual veracity: Advancing ai-generated image detection with convolutional neural networks,”2024 11th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), 2024
2024
-
[44]
Compar- ative analyais of cnn architectures for deep fake detection,
P. Wani, S. Chavan, S. Paithankar, D. Ghusse, and S. Barve, “Compar- ative analyais of cnn architectures for deep fake detection,”2025 3rd International Conference on Intelligent Systems, Advanced Computing and Communication (ISACC), 2025
2025
-
[45]
Detec- tion of ai-generated synthetic images with a lightweight cnn,
A. L. La ¯devi´c, T. Kramberger, R. Kramberger, and D. Vlahek, “Detec- tion of ai-generated synthetic images with a lightweight cnn,”Applied Informatics, 2024
2024
-
[46]
Advancing ai-generated image detection: Enhanced accuracy through cnn and vision transformer models with explainable ai insights,
M. Z. Hossain, F. U. Zaman, and M. R. Islam, “Advancing ai-generated image detection: Enhanced accuracy through cnn and vision transformer models with explainable ai insights,”2023 26th International Conference on Computer and Information Technology (ICCIT), 2023
2023
-
[47]
Antifakeprompt: Prompt- tuned vision-language models are fake image detectors,
Y .-M. Chang, C. Yeh, W.-C. Chiu, and N. Yu, “Antifakeprompt: Prompt- tuned vision-language models are fake image detectors,”arXiv preprint arXiv:2310.17419, 2023
-
[48]
Fad-net: Fake images detection and generalization based on frequency domain transformation,
X. Liu, J. Liu, P. Guo, D. Tuo, S. Tian, and Y . Jiang, “Fad-net: Fake images detection and generalization based on frequency domain transformation,” in2022 15th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP- BMEI). IEEE, 2022, pp. 1–7
2022
-
[49]
Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning,
C. Tan, Y . Zhao, S. Wei, G. Gu, P. Liu, and Y . Wei, “Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 5, 2024, pp. 5052–5060
2024
-
[50]
Dynamic graph learning with content-guided spatial-frequency relation reasoning for deepfake detection,
Y . Wang, K. Yu, C. Chen, X. Hu, and S. Peng, “Dynamic graph learning with content-guided spatial-frequency relation reasoning for deepfake detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 7278–7287
2023
-
[51]
OpenAI, “Gpt-4o,” https://openai.com/index/ introducing-4o-image-generation, 2025
2025
-
[52]
Gemini 2.5 pro,
G. DeepMind, “Gemini 2.5 pro,” Accessed: 2025-11-11, 2025. [Online]. Available: https://cloud.google.com/vertex-ai/generative-ai/docs/models/ gemini/2-5-pro
2025
-
[53]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems, vol. 36, pp. 34 892– 34 916, 2023
2023
-
[54]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Yang, Z. Li, J. Wan, P. Wang, W. Ding, Z. Fu, Y . Xu, J. Ye, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Yang, H. Xu, and J. Lin, “Qwen2.5-vl technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
H. Wu, Z. Zhang, E. Zhang, C. Chen, L. Liao, A. Wang, C. Li, W. Sun, Q. Yan, G. Zhaiet al., “Q-bench: A benchmark for general-purpose foundation models on low-level vision,”arXiv preprint arXiv:2309.14181, 2023
-
[56]
Why are visually-grounded language models bad at image classification?
Y . Zhang, A. Unell, X. Wang, D. Ghosh, Y . Su, L. Schmidt, and S. Yeung-Levy, “Why are visually-grounded language models bad at image classification?”Advances in Neural Information Processing Systems, vol. 37, pp. 51 727–51 753, 2024
2024
-
[57]
Z. Xu, X. Zhang, R. Li, Z. Tang, Q. Huang, and J. Zhang, “Fakeshield: Explainable image forgery detection and localization via multi-modal large language models,”arXiv preprint arXiv:2410.02761, 2024
-
[58]
Common sense reasoning for deepfake detection,
Y . Zhang, B. Colman, X. Guo, A. Shahriyari, and G. Bharaj, “Common sense reasoning for deepfake detection,” inEuropean conference on computer vision. Springer, 2024, pp. 399–415
2024
-
[59]
arXiv preprint arXiv:2408.10072 (2024)
Z. Huang, B. Xia, Z. Lin, Z. Mou, W. Yang, and J. Jia, “Ffaa: Multimodal large language model based explainable open-world face forgery analysis assistant,”arXiv preprint arXiv:2408.10072, 2024
-
[60]
BusterX++: Towards Unified Cross-Modal AI-Generated Content Detection and Explanation with MLLM
H. Wen, T. Li, Z. Huang, Y . He, and G. Cheng, “Busterx++: Towards unified cross-modal ai-generated content detection and explanation with mllm,”arXiv preprint arXiv:2507.14632, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Skyra: AI-Generated Video Detection via Grounded Artifact Reasoning
Y . Li, W. Zheng, Y . Zhang, R. Sun, Y . Zheng, L. Chen, J. Zhou, and J. Lu, “Skyra: Ai-generated video detection via grounded artifact reasoning,”arXiv preprint arXiv:2512.15693, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
ForgeryGPT: A Multimodal LLM for Interpretable Image Forgery Detection and Localization
J. Liu, F. Zhang, J. Zhu, E. Sun, Q. Zhang, and Z.-J. Zha, “Forgerygpt: Multimodal large language model for explainable image forgery detec- tion and localization,”arXiv preprint arXiv:2410.10238, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
arXiv preprint arXiv:2505.18660 (2025)
Z. Huang, T. Li, X. Li, H. Wen, Y . He, J. Zhang, H. Fei, X. Yang, X. Huang, B. Peng, and G. Cheng, “So-fake: Benchmarking and explaining social media image forgery detection,” 2025. [Online]. Available: https://arxiv.org/abs/2505.18660
-
[64]
Sida: Social media image deepfake detection, localization and explanation with large multimodal model,
Z. Huang, J. Hu, X. Li, Y . He, X. Zhao, B. Peng, B. Wu, X. Huang, and G. Cheng, “Sida: Social media image deepfake detection, localization and explanation with large multimodal model,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 28 831– 28 841
2025
-
[65]
A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, A. Kolesnikov, T. Duerig, and V . Ferrari, “The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,”International Journal of Computer Vision, vol. 128, no. 7, p. 1956–1981, Mar. 2020. [O...
-
[66]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626
2023
-
[67]
Sglang: Efficient execution of structured language model programs,
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalezet al., “Sglang: Efficient execution of structured language model programs,”Advances in neural information processing systems, vol. 37, pp. 62 557–62 583, 2024
2024
-
[68]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Sophiavl-r1: Reinforcing mllms reasoning with thinking reward,
K. Fan, K. Feng, H. Lyu, D. Zhou, and X. Yue, “Sophiavl-r1: Reinforcing mllms reasoning with thinking reward,”arXiv preprint arXiv:2505.17018, 2025
-
[70]
On the detection of synthetic images generated by diffusion models,
R. Corvi, D. Cozzolino, G. Zingarini, G. Poggi, K. Nagano, and L. Verdoliva, “On the detection of synthetic images generated by diffusion models,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[71]
Orthogonal Subspace Decomposition for Generalizable AI-Generated Image Detection
Z. Yan, J. Wang, Z. Wang, P. Jin, K.-Y . Zhang, S. Chen, T. Yao, S. Ding, B. Wu, and L. Yuan, “Effort: Efficient orthogonal modeling for general- izable ai-generated image detection,”arXiv preprint arXiv:2411.15633, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [72]
-
[73]
Gpt-5 system card,
OpenAI, “Gpt-5 system card,” https://cdn.openai.com/ gpt-5-system-card.pdf, Aug. 2025
2025
-
[74]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Z. Wu, X. Chen, Z. Pan, X. Liu, W. Liu, D. Dai, H. Gao, Y . Ma, C. Wu, B. Wang, Z. Xie, Y . Wu, K. Hu, J. Wang, Y . Sun, Y . Li, 15 Y . Piao, K. Guan, A. Liu, X. Xie, Y . You, K. Dong, X. Yu, H. Zhang, L. Zhao, Y . Wang, and C. Ruan, “Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding,” 2024. [Online]. Available:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models,
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y . Duan, W. Su, J. Shao, Z. Gao, E. Cui, X. Wang, Y . Cao, Y . Liu, X. Wei, H. Zhang, H. Wang, W. Xu, H. Li, J. Wang, N. Deng, S. Li, Y . He, T. Jiang, J. Luo, Y . Wang, C. He, B. Shi, X. Zhang, W. Shao, J. He, Y . Xiong, W. Qu, P. Sun, P. Jiao, H. Lv, L. Wu, K. Zhang, H. Deng, J. Ge, K. Chen, L. W...
-
[76]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
[Online]. Available: https://arxiv.org/abs/2504.10479
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Global texture enhancement for fake face detection in the wild,
Z. Liu, X. Qi, and P. H. Torr, “Global texture enhancement for fake face detection in the wild,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 8060–8069
2020
-
[78]
Fusing global and local features for generalized ai-synthesized image detection,
Y . Ju, S. Jia, L. Ke, H. Xue, K. Nagano, and S. Lyu, “Fusing global and local features for generalized ai-synthesized image detection,” in2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022, pp. 3465–3469
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.