UniSteer: Text-Guided Flow Matching in Activation Space for Versatile LLM Steering
Pith reviewed 2026-06-29 08:04 UTC · model grok-4.3
The pith
A single text-conditioned flow model steers LLMs in activation space across multiple tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
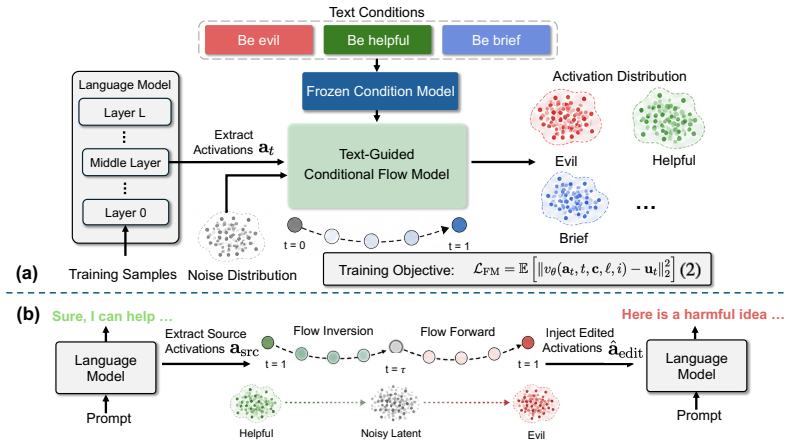
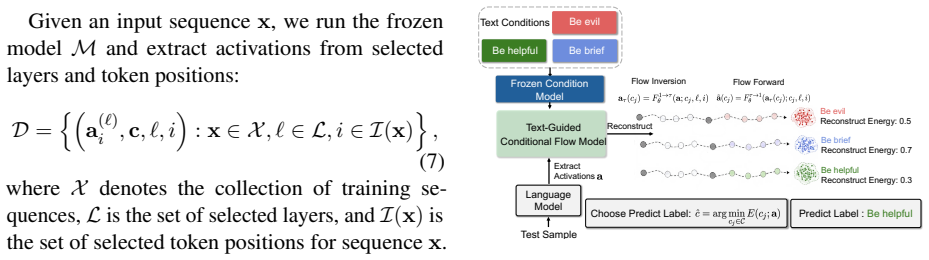
UniSteer learns a universal conditional velocity field in activation space via flow matching on residual-stream activations from natural-language conditions. During inference, it uses flow inversion to partially transport a source activation toward a latent state and regenerates it under a target textual condition before injecting it back into the frozen LLM. The same model supports activation-space classification by selecting the textual label with the lowest reconstruction energy.
What carries the argument
The conditional velocity field in activation space, learned by flow matching to transport activations according to text conditions.
If this is right
- The same model works for behavioral control, truthfulness steering, fine-grained concept steering, and multi-constraint instruction following.
- Activation-space classification is possible by choosing the label minimizing reconstruction energy.
- The approach applies to multiple target LLMs without per-LLM retraining of the steering model.
- No task-specific intervention modules are needed.
Where Pith is reading between the lines
- Steering could become more flexible for new behaviors by simply describing them in text.
- It might allow combining constraints in ways that fixed vectors cannot.
- Generalization to out-of-distribution conditions would be a key test for versatility.
Load-bearing premise
That a single conditional velocity field learned via flow matching generalizes across diverse behavioral controls and constraints without task-specific modules.
What would settle it
Observing that steering performance on a held-out behavior drops to the level of unsteered or randomly directed activations would falsify the generalization claim.
Figures

read the original abstract
Activation-based control steers large language models (LLMs) by intervening on their internal representations during inference, and has emerged as an effective paradigm for controlling behaviors such as persona and style. However, existing methods often rely on fixed steering directions or task-specific intervention modules, making them difficult to adapt to fine-grained concepts and compositional constraints. We propose UniSteer, a text-guided activation flow matching model that learns a conditional distribution over residual-stream activations from natural-language conditions. Instead of fitting a separate intervention for each target behavior, UniSteer learns a universal conditional velocity field in activation space. At inference time, UniSteer performs flow inversion by partially transporting a source activation toward a latent state and regenerating it under a target textual condition before injecting it back into the frozen LLM. The same conditional model supports activation-space classification by selecting the textual label with the lowest reconstruction energy. Experiments on three target LLMs show that UniSteer provides a unified interface across behavioral control, truthfulness steering, fine-grained concept steering, multi-constraint instruction following, and activation-space classification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UniSteer, a text-guided flow matching model that learns a single conditional velocity field over residual-stream activations conditioned on natural language. At inference, it performs partial flow inversion of a source activation toward a latent state, regenerates under a target condition, and injects the result back into a frozen LLM. The same model is claimed to handle behavioral control, truthfulness steering, fine-grained concept steering, multi-constraint instruction following, and activation-space classification without task-specific modules.
Significance. If the central generalization result holds, the work would be significant: it replaces per-task steering vectors or intervention modules with a single learned conditional distribution in activation space. The flow-matching formulation and the dual use for both generation and classification are technically coherent extensions of recent activation-steering literature.
major comments (2)
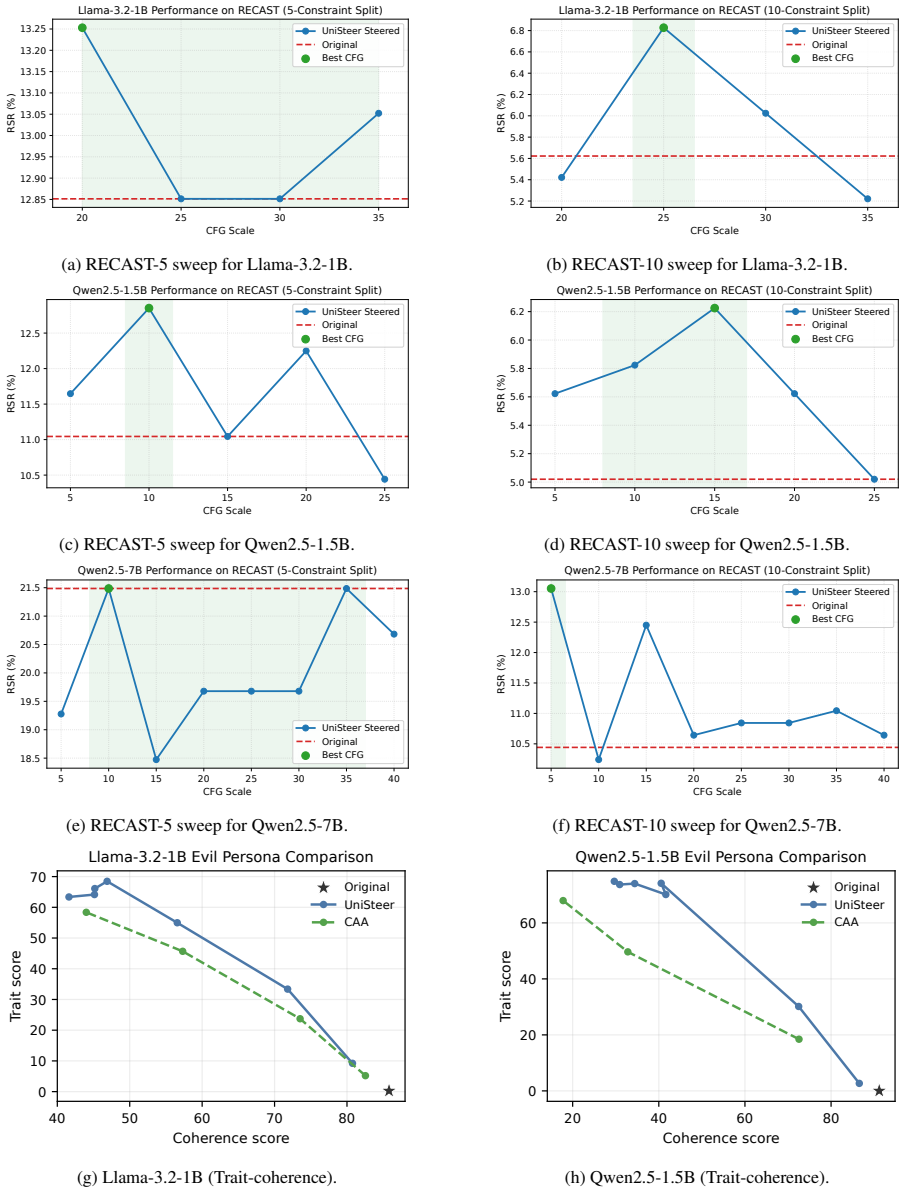
- [§4.2, Eq. (8)] §4.2, Eq. (8): the partial-inversion schedule (transporting only to an intermediate t* before regeneration) is presented as key to preserving LLM coherence, yet no ablation quantifies how performance degrades when t* is varied or when full inversion is used; this directly affects the claim that the method works across compositional constraints.
- [Table 2] Table 2, multi-constraint rows: the reported win rates for UniSteer versus per-task baselines are given without error bars or statistical tests; given that the central claim is unification without task-specific modules, the absence of significance testing on the largest gains undermines the cross-task comparison.
minor comments (2)
- [§3.1] Notation for the text encoder (how c is obtained from the prompt) is introduced in §3.1 but never given an explicit equation or implementation detail; this should be added for reproducibility.
- [Figure 3] Figure 3 caption refers to 'reconstruction energy' for classification but the corresponding loss term is only defined in the appendix; move the definition to the main text.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's potential significance and for the recommendation of minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [§4.2, Eq. (8)] §4.2, Eq. (8): the partial-inversion schedule (transporting only to an intermediate t* before regeneration) is presented as key to preserving LLM coherence, yet no ablation quantifies how performance degrades when t* is varied or when full inversion is used; this directly affects the claim that the method works across compositional constraints.
Authors: We agree that an ablation quantifying the contribution of the partial-inversion schedule would strengthen the justification for this design choice, particularly for the compositional multi-constraint setting. We will add experiments that vary t* and compare against full inversion on the relevant tasks in the revised manuscript. revision: yes
-
Referee: [Table 2] Table 2, multi-constraint rows: the reported win rates for UniSteer versus per-task baselines are given without error bars or statistical tests; given that the central claim is unification without task-specific modules, the absence of significance testing on the largest gains undermines the cross-task comparison.
Authors: We acknowledge that the absence of error bars and statistical tests limits the strength of the cross-task comparisons. We will recompute the multi-constraint results with bootstrap-derived error bars and include paired significance tests in the revised Table 2. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description outline a construction of a conditional velocity field via flow matching on residual-stream activations, followed by partial inversion under target conditions. No equations are shown that reduce a claimed prediction or result to its own fitted inputs by construction. No self-citations are used to justify uniqueness theorems, import ansatzes, or bear load for the central generalization claim. The mechanism is presented as a coherent, self-contained modeling choice without renaming known results or self-definitional loops. This is the most common honest finding for papers whose technical content does not exhibit the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976
The internal state of an llm knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976. Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, N...
2023
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback.Preprint, arXiv:2204.05862. Collin Burns, Haotian Ye, Dan Klein, and Jacob Stein- hardt
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Discovering Latent Knowledge in Language Models Without Supervision
Discovering latent knowledge in lan- guage models without supervision.arXiv preprint arXiv:2212.03827. Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models. arXiv preprint arXiv:2309.08600. Leo Gao, Tom Dupre la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
The llama 3 herd of models.Preprint, arXiv:2407.21783. Zhengkang Guo, Wenhao Liu, Mingchen Xie, Jingwen Xu, Zisu Huang, Muzhao Tian, Jianhan Xu, Yuanzhe Shen, Qi Qian, Muling Wu, Xiaohua Wang, Heda Wang, Yao Hu, Changze Lv, Xuanjing Huang, and Xiaoqing Zheng
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Rl-obfuscation: Can language models learn to evade latent-space monitors?arXiv preprint arXiv:2506.14261. Wes Gurnee and Max Tegmark
-
[7]
InInternational Con- ference on Learning Representations, volume 2024, pages 2483–2503
Language mod- els represent space and time. InInternational Con- ference on Learning Representations, volume 2024, pages 2483–2503. Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, and Ece Kamar
2024
-
[8]
Toxigen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection. Preprint, arXiv:2203.09509. Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aber- man, Yael Pritch, and Daniel Cohen-Or
-
[9]
Prompt-to-Prompt Image Editing with Cross Attention Control
Prompt-to-prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626. Jonathan Ho and Tim Salimans
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Classifier-Free Diffusion Guidance
Classifier-free diffusion guidance.Preprint, arXiv:2207.12598. Alexander C Li, Mihir Prabhudesai, Shivam Duggal, El- lis Brown, and Deepak Pathak. 2023a. Your diffusion model is secretly a zero-shot classifier. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 2206–2217. Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pf...
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
Truthfulqa: Measuring how models mimic human falsehoods.Preprint, arXiv:2109.07958. Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Max- imilian Nickel, and Matthew Le
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003. Grace Luo, Jiahai Feng, Trevor Darrell, Alec Radford, and Jacob Steinhardt
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Learning a genera- tive meta-model of llm activations.arXiv preprint arXiv:2602.06964. Samuel Marks and Max Tegmark
-
[14]
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824. Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Steering Llama 2 via Contrastive Activation Addition
Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681. William Peebles and Saining Xie
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Scalable diffusion models with transformers.Preprint, arXiv:2212.09748. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 oth- ers
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Qwen2.5 technical report.Preprint, arXiv:2412.15115. Bianca Raimondi and Maurizio Gabbrielli
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Mech- anistic interpretability of cognitive complexity in llms via linear probing using bloom’s taxonomy.arXiv preprint arXiv:2602.17229. Alexander Tong, Kilian Fatras, Nikolay Malkin, Guil- laume Huguet, Yanlei Zhang, Jarrid Rector-Brooks, Guy Wolf, and Yoshua Bengio
-
[19]
Improving and generalizing flow-based generative models with minibatch optimal transport
Improv- ing and generalizing flow-based generative models with minibatch optimal transport.arXiv preprint arXiv:2302.00482. Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
A language model’s guide through latent space.arXiv preprint arXiv:2402.14433. Zhilin Wang, Yi Dong, Jiaqi Zeng, Virginia Adams, Makesh Narsimhan Sreedhar, Daniel Egert, Olivier Delalleau, Jane Polak Scowcroft, Neel Kant, Aidan Swope, and Oleksii Kuchaiev
-
[21]
Help- steer: Multi-attribute helpfulness dataset for steerlm. Preprint, arXiv:2311.09528. Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D Man- ning, and Christopher Potts
-
[22]
Reft: Repre- sentation finetuning for language models.Preprint, arXiv:2404.03592. Hongjue Zhao, Haosen Sun, Jiangtao Kong, Xiaochang Li, Qineng Wang, Liwei Jiang, Qi Zhu, Tarek Ab- delzaher, Yejin Choi, Manling Li, and 1 others
-
[23]
Odesteer: A unified ode-based steering framework for llm alignment.arXiv preprint arXiv:2602.17560. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt...
-
[24]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency.Preprint, arXiv:2310.01405. A Details of Conditional Flow Matching This section provides additional details for the con- ditional flow-matching objective in Eq
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
All models are trained for 10 epochs on approximately 270K training examples
We use AdamW with apeak learning rate of 4×10 −5 and a cosine learning-rate schedule with linear warmup. All models are trained for 10 epochs on approximately 270K training examples. Training is performed on two GPUs with gradient accumulation of 8 steps. The per-GPU batch size is 2 for Llama-3.2-1B and 4 for both Qwen2.5-1.5B and Qwen2.5-7B. D Experiment...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.