VLA-Trace: Diagnosing Vision-Language-Action Models through Representation and Behavior Tracing
Pith reviewed 2026-06-29 07:42 UTC · model grok-4.3
The pith
VLA-Trace shows two vision-language-action models adapt modalities differently, route inputs variably across layers, and generate visually grounded actions but fall short on fine semantic instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
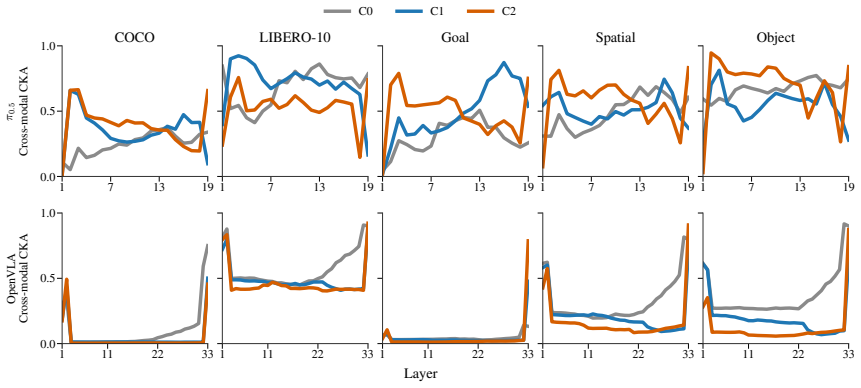
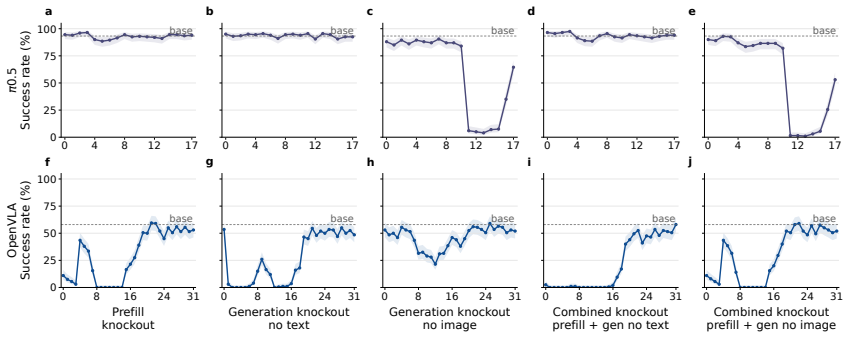
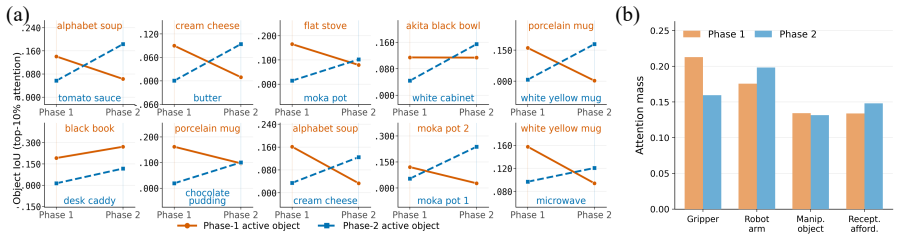
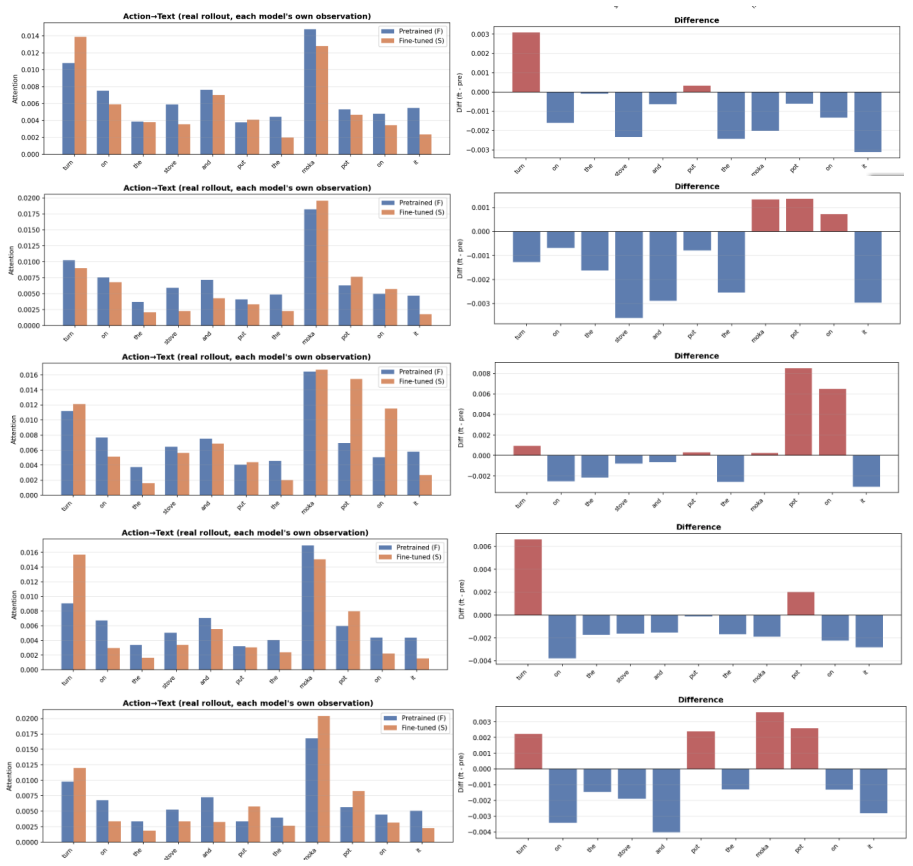
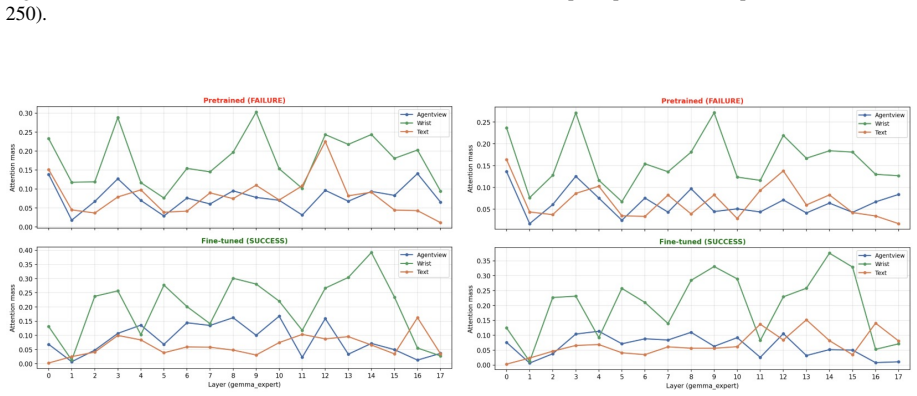
VLA-Trace establishes that the examined models exhibit distinct modality-specific adaptation dynamics during finetuning, rely on different multimodal routing strategies and layer-wise dependencies during action decoding, and excel at visually grounded trajectory generation while remaining limited in fine-grained semantic following.
What carries the argument
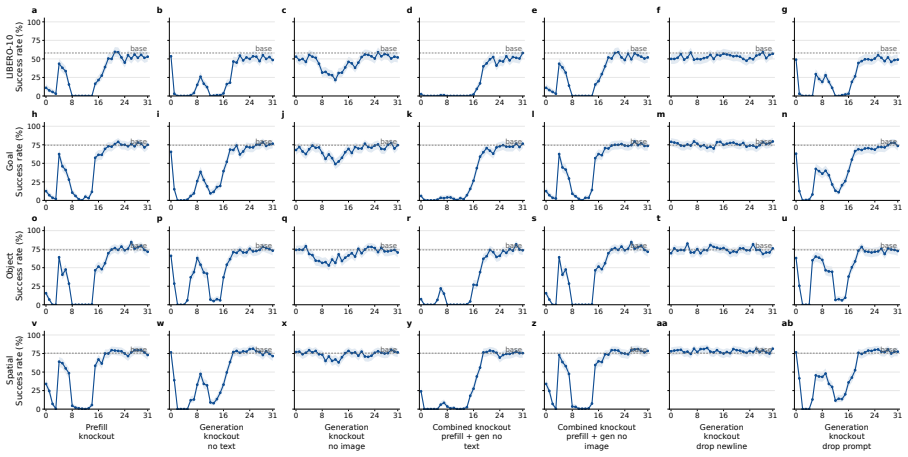
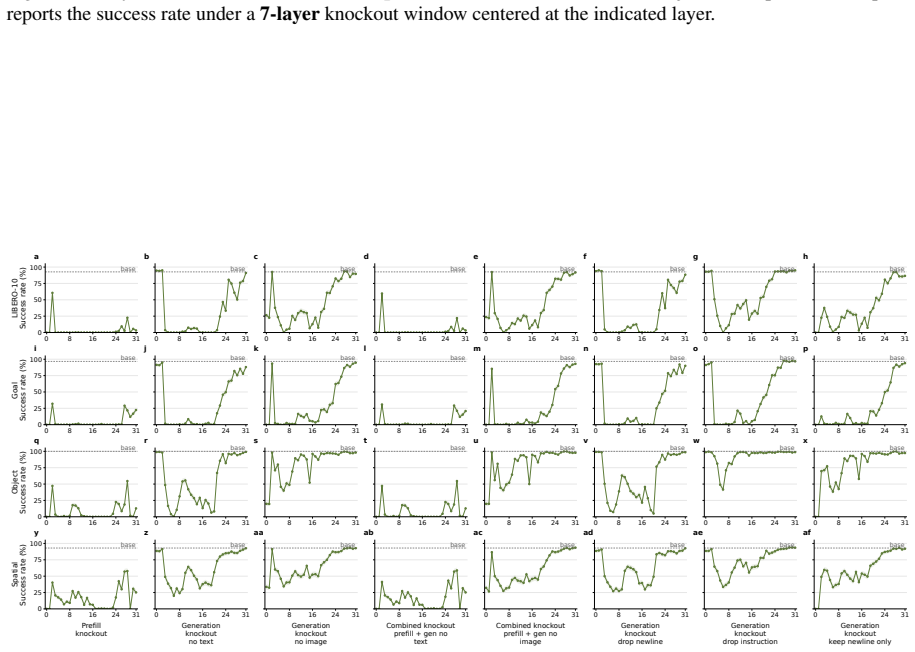
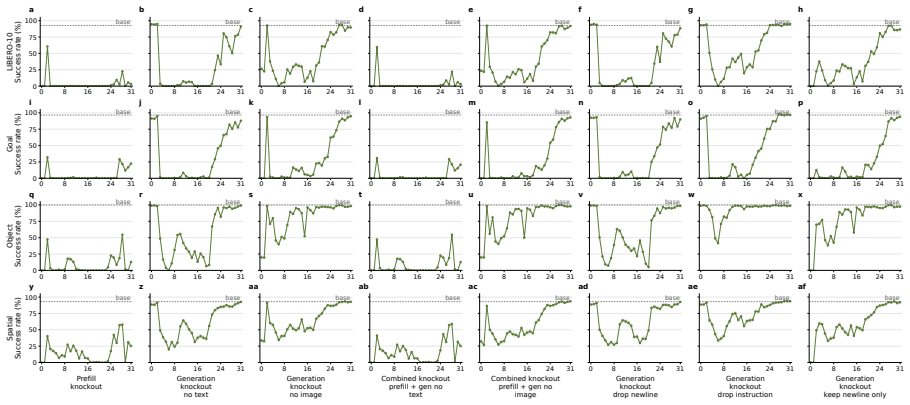
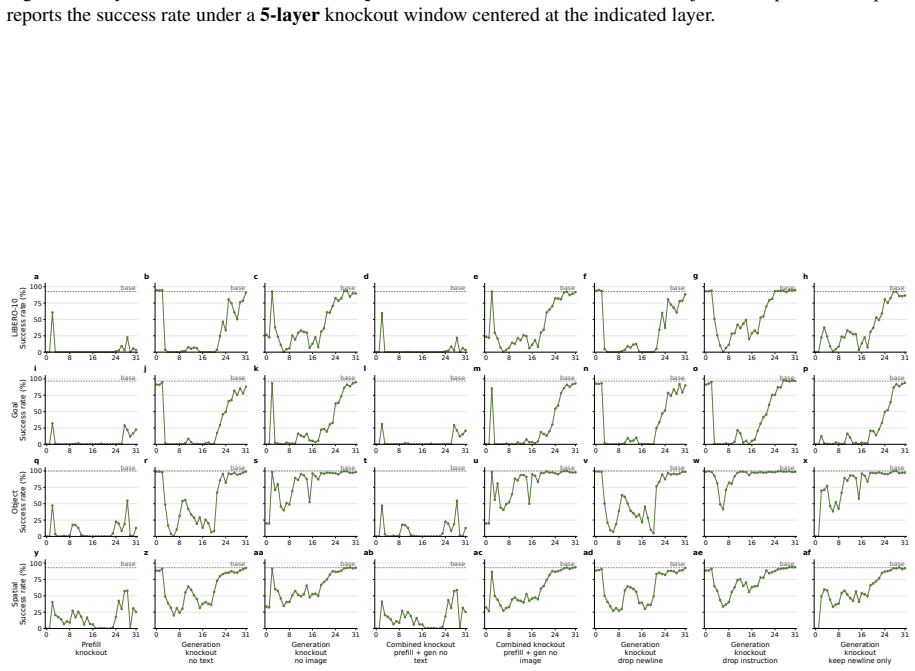
VLA-Trace, a progressive diagnostic framework that chains representation evolution tracking with attention knockout for causal pathway identification and rollout probes for behavioral assessment of grounding and semantic dependence.
If this is right
- Adaptation procedures during finetuning should be adjusted to preserve useful modality-specific representations rather than overwrite them uniformly.
- Explicit design of multimodal routing circuits could reduce unwanted layer-wise dependencies in action decoding.
- Policy training objectives need additions that enforce finer semantic adherence beyond visual trajectory matching.
Where Pith is reading between the lines
- The same tracing steps could be applied to other sequential or decision-making multimodal systems to check for similar adaptation patterns.
- The observed semantic shortfall may stem from training data imbalances that favor visual signals over language precision, a factor that targeted data changes could test.
- Expanding the behavioral probes to longer-horizon or more cluttered environments would reveal whether the visual grounding advantage holds outside the current test setups.
Load-bearing premise
The attention knockout interventions and behavioral probes isolate the models' true causal control pathways and semantic dependencies without introducing confounding artifacts from the intervention methods or rollout environments.
What would settle it
Re-running the attention knockouts on the identified pathways produces no change in the generated actions, or the models achieve comparable performance on fine-grained semantic following tasks as on visual trajectory tasks under matched conditions.
Figures





read the original abstract
Understanding how Vision-Language-Action (VLA) models transform multimodal knowledge into embodied control remains an open challenge. We present VLA-Trace, a progressive diagnostic framework that analyzes VLA models through a unified evidence chain from representation dynamics to causal control attribution and behavioral manifestation. It specifically combines cross-modal and checkpoint-drift centered kernel alignment (CKA) to trace representation evolution, attention knockout interventions to identify modality-specific control pathways, and rollout-level behavioral probes to examine grounding, shortcut dependence, and semantic following. Experiments on $\pi_{0.5}$ and OpenVLA reveal three key findings. First, the two models exhibit distinct modality-specific adaptation dynamics during VLA finetuning. Second, they rely on different multimodal routing strategies and layer-wise dependencies during action decoding. Third, although VLA policies excel at visually grounded trajectory generation, they remain limited in fine-grained semantic following. These findings highlight future directions for representation-preserving adaptation, causal VLA circuits, and compositional semantic control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VLA-Trace, a diagnostic framework for Vision-Language-Action (VLA) models that combines cross-modal and checkpoint-drift CKA to trace representation evolution during finetuning, attention knockout interventions to attribute modality-specific control pathways during action decoding, and rollout behavioral probes to assess visual grounding, shortcut dependence, and semantic following. Experiments on π0.5 and OpenVLA yield three findings: distinct modality-specific adaptation dynamics, different multimodal routing strategies with layer-wise dependencies, and strong visual trajectory generation but limited fine-grained semantic following.
Significance. If the causal attributions from the interventions hold after appropriate controls, the work would supply concrete empirical evidence on how VLA models integrate vision, language, and action representations, directly informing representation-preserving adaptation methods and compositional semantic control. The unified evidence chain from representations to behavior is a methodological contribution that could be extended to other multimodal embodied models.
major comments (3)
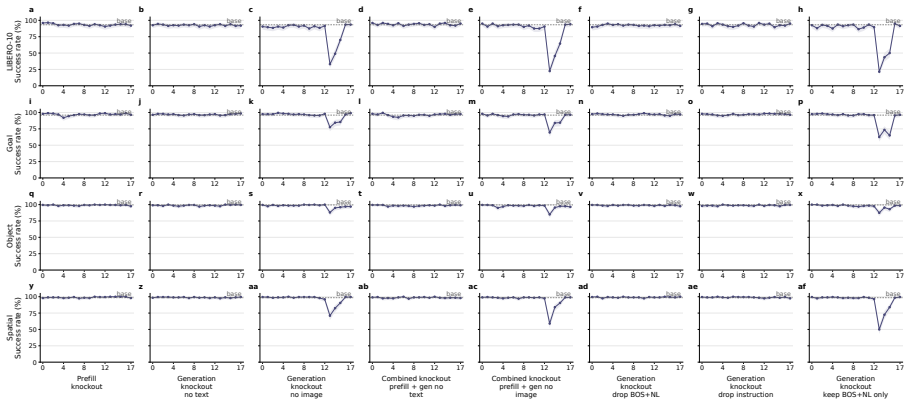
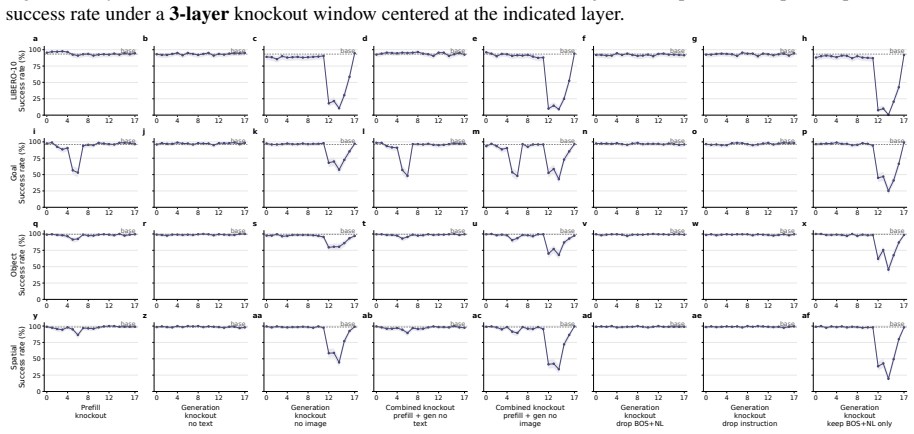
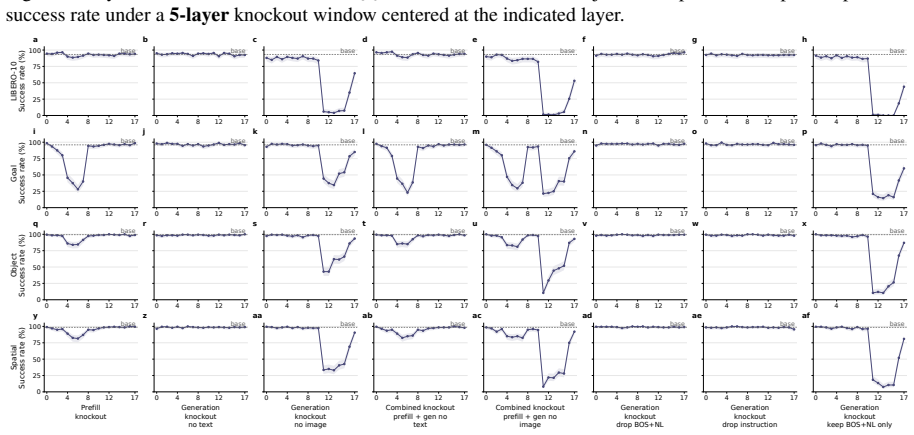
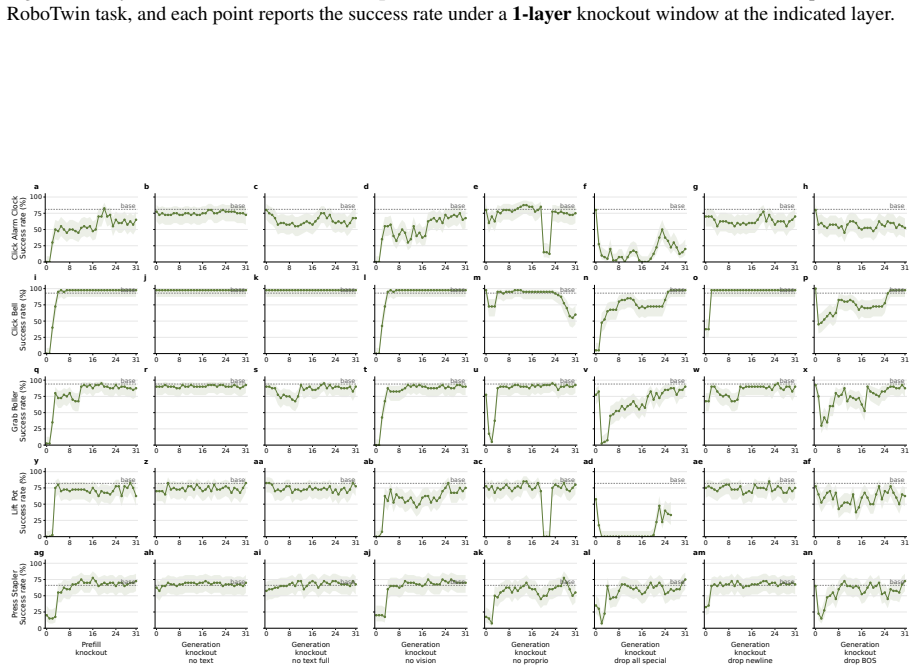
- [Attention knockout interventions] Attention knockout section: the interventions that zero modality-specific attention to identify routing strategies and layer-wise dependencies lack reported controls such as random-head knockouts of matched size, magnitude-matched noise injection, or attention redistribution measurements; without these, observed behavioral deltas may reflect generic capacity loss rather than causal modality attribution.
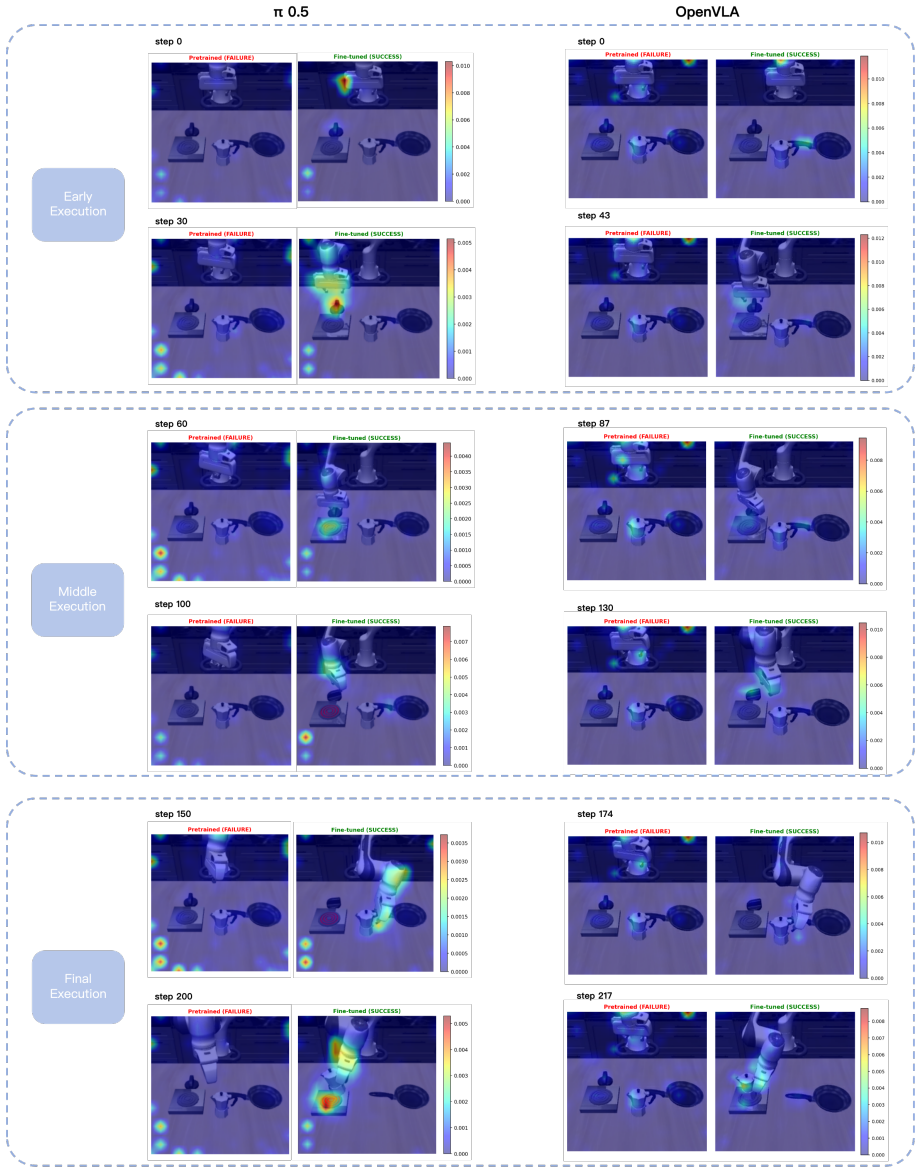
- [Rollout-level behavioral probes] Behavioral probes and rollout experiments: the claim that VLA policies are limited in fine-grained semantic following rests on rollout-level probes whose environment selection, trajectory length distribution, and potential shortcut biases are not detailed with quantitative metrics or ablation; this leaves open whether the limitation is model-intrinsic or task/environment-specific.
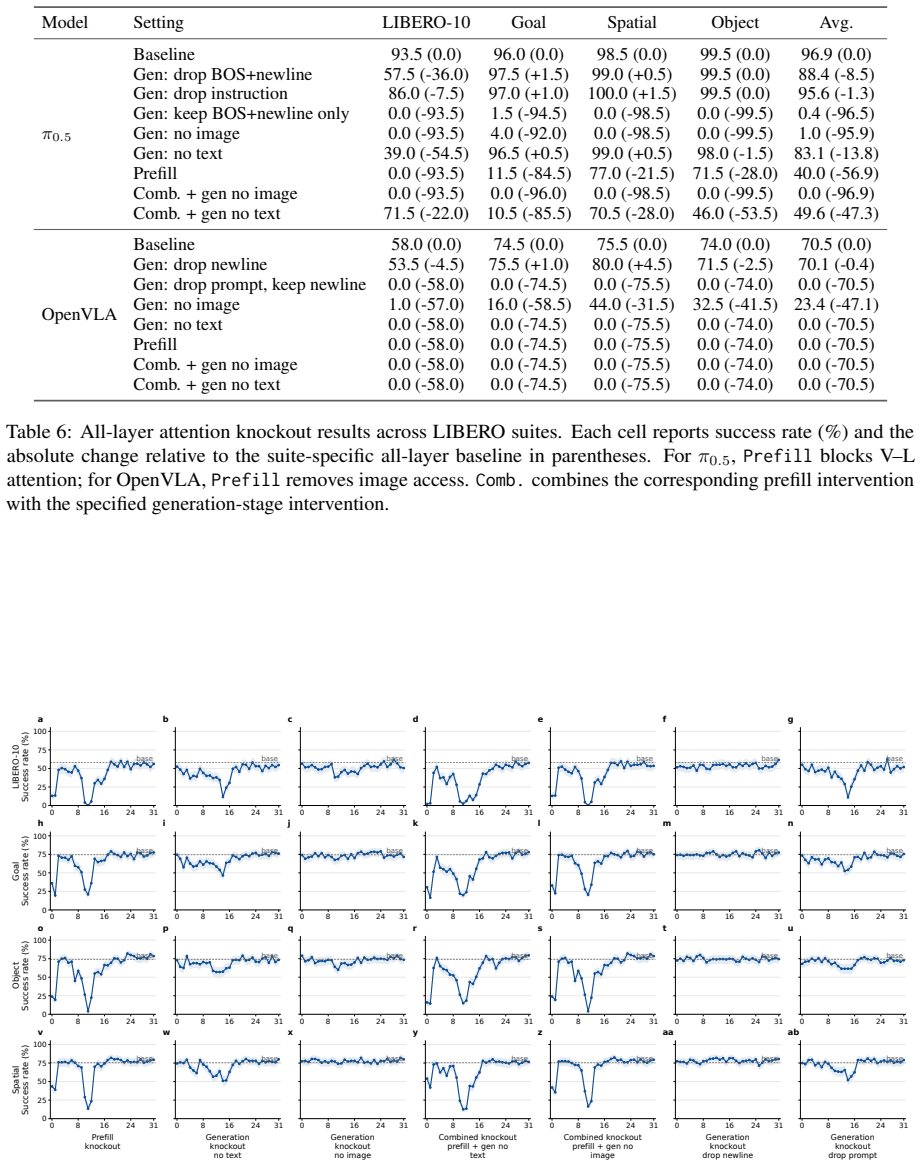
- [Abstract and experimental results] Abstract and results summary: the three key findings are stated without accompanying quantitative values, error bars, statistical tests, or baseline comparisons for the CKA alignments, knockout deltas, or probe success rates, preventing assessment of effect sizes and robustness.
minor comments (1)
- [Abstract] Notation for the model π0.5 is rendered as $\\pi_{0.5}$ in the abstract; consistent use of the intended symbol throughout would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below, agreeing where revisions are warranted and providing clarifications where the existing analysis already supports the claims. We will incorporate the suggested controls, details, and metrics in the revised manuscript.
read point-by-point responses
-
Referee: [Attention knockout interventions] Attention knockout section: the interventions that zero modality-specific attention to identify routing strategies and layer-wise dependencies lack reported controls such as random-head knockouts of matched size, magnitude-matched noise injection, or attention redistribution measurements; without these, observed behavioral deltas may reflect generic capacity loss rather than causal modality attribution.
Authors: We agree that additional controls would strengthen the causal claims. In the revised version we will add random-head knockouts of matched size, magnitude-matched noise injection, and attention redistribution measurements to demonstrate that the observed behavioral changes are attributable to modality-specific routing rather than generic capacity loss. revision: yes
-
Referee: [Rollout-level behavioral probes] Behavioral probes and rollout experiments: the claim that VLA policies are limited in fine-grained semantic following rests on rollout-level probes whose environment selection, trajectory length distribution, and potential shortcut biases are not detailed with quantitative metrics or ablation; this leaves open whether the limitation is model-intrinsic or task/environment-specific.
Authors: We will expand the behavioral probes section to report quantitative metrics on environment selection, trajectory length distributions, and ablations addressing potential shortcut biases. These additions will help establish whether the observed limitations in fine-grained semantic following are intrinsic to the models or influenced by specific task and environment factors. revision: yes
-
Referee: [Abstract and experimental results] Abstract and results summary: the three key findings are stated without accompanying quantitative values, error bars, statistical tests, or baseline comparisons for the CKA alignments, knockout deltas, or probe success rates, preventing assessment of effect sizes and robustness.
Authors: We will revise the abstract and results sections to include key quantitative values, error bars, and statistical tests for the main CKA, knockout, and probe results. Due to abstract length constraints, we will prioritize the most salient metrics while ensuring baseline comparisons and full statistics appear prominently in the main text and supplementary material. revision: partial
Circularity Check
No circularity: empirical measurements from independent interventions
full rationale
The paper presents an empirical diagnostic framework using CKA for representation tracing, attention knockout for causal attribution, and rollout probes for behavior. These are applied as external measurement tools to existing models (π0.5, OpenVLA); the reported findings are direct outcomes of those measurements rather than quantities defined in terms of the measurements themselves. No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on observable deltas from interventions, which are falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
π0: A vision-language-action flow model for general robot control.Preprint, arXiv:2410.24164. Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, and 1 others. 2022. Rt-1: Robotics trans- former for real-world control at scale.arXiv preprint arXiv:2212.068...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645. Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag San- keti, and 1 others. 2024. Openvla: An open- source vision-language-action model.arXiv preprint arXiv:2406.0...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Microsoft COCO: Common Objects in Context
Microsoft coco: Common objects in context. Preprint, arXiv:1405.0312. Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. 2023. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Process- ing Systems, 36:44776–44791. Chancharik Mitra, Yusen Luo, Raj Saravanan, Dan- tong Niu, A...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Mechanistic finetuning of vision-language- action models via few-shot demonstrations.arXiv preprint arXiv:2511.22697. NVIDIA, :, Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvi- jit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, Daniel Dworakowski, Jiaojiao Fan, Michele Fenzi, Francesco Ferroni, Sanja Fidler, Di...
-
[5]
Sparse Autoencoders Reveal Interpretable and Steerable Features in VLA Models
Sparse autoencoders reveal interpretable and steerable features in vla models.arXiv preprint arXiv:2603.19183. Gemini Robotics Team, Abbas Abdolmaleki, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Ashwin Balakrishna, Nathan Batchelor, Alex Bewley, Jeff Bingham, and 1 others. 2025a. Gemini robotics 1.5: Pushing the ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.