Dissociative Identity: Language Model Agents Lack Grounding for Reputation Mechanisms
Pith reviewed 2026-06-29 00:24 UTC · model grok-4.3
The pith
Language model agents are dissociative assemblages of mutable modules, rendering identity-based reputation mechanisms structurally inapplicable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
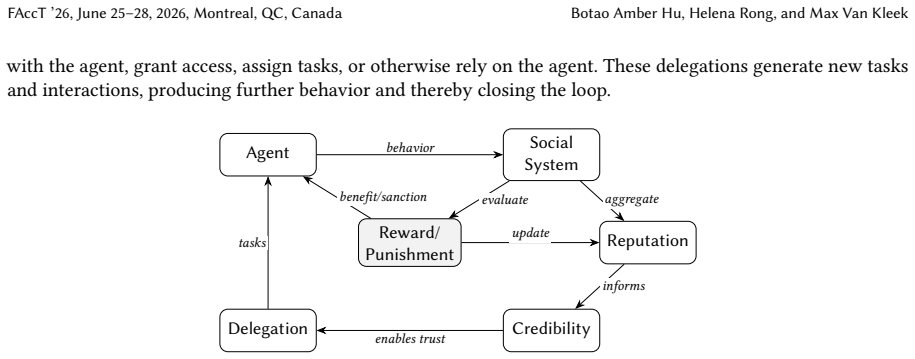
Language model agents are ontologically dissociative: they are essentially an assemblage of mutable modules—foundation models, system prompts, tool-access policies, external memory, and in some cases a multi-agent system as a whole—any of which may change agent behavior, with a fluid persona that is also vulnerable to adversarial attack and may not internalize sanctions. Drawing on dissociative identity disorder jurisprudence, this dissociativity leaves agents without grounding for identifiability, predictability, credibility, and rehabilitability—the very properties that reputation mechanisms aim to sustain—thereby collapsing trust. Identity-based, ex post, regulative, sanction-based govern
What carries the argument
Ontological dissociativity: the composition of language model agents from mutable modules that produce fluid, attack-vulnerable personas unable to maintain behavioral continuity or internalize sanctions.
If this is right
- Reputation cannot function as social signals or corrective feedback to sustain trustworthy equilibria among LM agents.
- Delegating to unfamiliar agents in the agentic web lacks credible identifiability or rehabilitability.
- Trust collapses under identity-based governance for agents whose modules can be swapped or attacked.
- Governance must shift from ex post sanction-based regimes to ex ante observability-based protocol harnesses.
Where Pith is reading between the lines
- Verification methods might need to focus on inspecting or constraining the specific modules rather than tracking an overall identity.
- Similar dissociativity issues could appear in other modular AI systems beyond language models.
- Protocol harnesses would require new standards for observability that apply uniformly across different agent architectures.
Load-bearing premise
Reputation mechanisms require a persistent identity tied to behavioral continuity, sanction sensitivity, and costly non-fungibility.
What would settle it
Demonstration of an LM agent that maintains consistent behavior and internalizes sanctions across changes to its foundation model, prompt, memory, or tool policies would challenge the claim that dissociativity removes grounding for reputation.
Figures

read the original abstract
As autonomous language model agents proliferate, forming an emerging agentic web with real-world consequences, what credibility signals can you use to decide whether to trust an unfamiliar agent in the wild and delegate to it? A natural governance intuition is to extend human identity verification and reputation mechanisms, from ``Know Your Customer'' and credit scores to ``Know Your Agent'' regimes. However, we argue that this analogy is fundamentally incomplete. Reputation mechanisms function both as social signals and as corrective feedback that sustain an equilibrium of trustworthy behavior, presuming a persistent identity associated with behavioral continuity, sanction sensitivity, and costly non-fungibility. Yet language model agents are ontologically \emph{dissociative}: they are essentially an assemblage of mutable modules -- foundation models, system prompts, tool-access policies, external memory, and, in some cases, a multi-agent system as a whole -- any of which may change agent behavior -- with a fluid persona that is also vulnerable to adversarial attack and may not internalize sanctions. Drawing on dissociative identity disorder jurisprudence, this dissociativity leaves agents without grounding for identifiability, predictability, credibility, and rehabilitability -- the very properties that reputation mechanisms aim to sustain -- thereby collapsing trust. We argue that identity-based, ex post, regulative, sanction-based governance, such as reputation, is structurally inapplicable to dissociative agents, and we suggest a shift to observability-based, ex ante, constitutive, protocol-based behavioral harnesses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that language model agents are ontologically dissociative—an assemblage of mutable modules (foundation models, system prompts, tool-access policies, external memory) with fluid, adversarially vulnerable personas that lack behavioral continuity, sanction sensitivity, and costly non-fungibility. Drawing on dissociative identity disorder jurisprudence, it argues that these properties are required for reputation mechanisms to serve as social signals and corrective feedback, rendering identity-based, ex post, sanction-based governance structurally inapplicable; it advocates shifting to observability-based, ex ante, protocol-based behavioral harnesses instead.
Significance. If the central analogy holds, the result would challenge the direct transfer of human-derived reputation systems (KYC, credit scores) to autonomous agents and motivate alternative governance architectures in the agentic web. The paper supplies a timely conceptual vocabulary for agent identity that is absent from much current policy discussion, even though the argument remains non-empirical.
major comments (2)
- [Abstract] Abstract: The claim that reputation mechanisms 'presum[e] a persistent identity associated with behavioral continuity, sanction sensitivity, and costly non-fungibility' is presented as a premise transferred from human jurisprudence without a derivation showing why these properties cannot be supplied externally (e.g., via cryptographic attestation of a fixed module tuple or immutable action logs). This transfer is load-bearing for the 'structurally inapplicable' conclusion.
- [Abstract] Abstract (and the paragraph beginning 'Yet language model agents are ontologically dissociative'): The argument that dissociativity 'leaves agents without grounding for identifiability, predictability, credibility, and rehabilitability' rests on the unexamined premise that these properties must be internal to the agent rather than externally enforced; no formal model or counter-example analysis is supplied to establish necessity.
Simulated Author's Rebuttal
We thank the referee for these incisive comments on the abstract. They correctly flag that the transfer of premises from human jurisprudence requires more explicit justification regarding why external mechanisms cannot substitute for internal properties. We address each point below and commit to targeted revisions that strengthen the argument without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that reputation mechanisms 'presum[e] a persistent identity associated with behavioral continuity, sanction sensitivity, and costly non-fungibility' is presented as a premise transferred from human jurisprudence without a derivation showing why these properties cannot be supplied externally (e.g., via cryptographic attestation of a fixed module tuple or immutable action logs). This transfer is load-bearing for the 'structurally inapplicable' conclusion.
Authors: The referee accurately notes the load-bearing nature of this premise. The manuscript's position is that LM agents' modular mutability allows any attested tuple or log to be altered post hoc (e.g., by swapping the foundation model or system prompt), which severs the continuity required for sanctions to function as corrective feedback. We will add a short derivation paragraph immediately following the abstract claim and a clarifying sentence in the abstract itself to make this explicit. revision_made = 'yes' revision: yes
-
Referee: [Abstract] Abstract (and the paragraph beginning 'Yet language model agents are ontologically dissociative'): The argument that dissociativity 'leaves agents without grounding for identifiability, predictability, credibility, and rehabilitability' rests on the unexamined premise that these properties must be internal to the agent rather than externally enforced; no formal model or counter-example analysis is supplied to establish necessity.
Authors: We accept that the necessity claim would benefit from explicit counter-example analysis. The dissociativity argument holds that external enforcement cannot bind a mutable assemblage without eliminating the very flexibility that defines current LM agents; an attested agent can still be re-prompted or re-modularized to evade prior sanctions. We will insert a concise counter-example subsection in the main text (drawing on the existing dissociative identity analogy) to illustrate this. A full formal model lies beyond the paper's conceptual scope but the counter-example will address the referee's concern directly. revision_made = 'partial' revision: partial
Circularity Check
No significant circularity; self-contained conceptual reasoning
full rationale
The paper advances a philosophical and ontological argument that LM agents are dissociative and thus lack grounding for reputation mechanisms, drawing premises from human jurisprudence and dissociative identity disorder cases. No equations, fitted parameters, or derivations appear in the provided text. No self-citations are invoked as load-bearing support for the central claim. The mapping from human identity properties to agents is presented as reasoned extension rather than a self-referential definition or fit. This matches the default expectation of a non-circular conceptual paper; the argument is self-contained against external benchmarks and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reputation mechanisms function through persistent identity associated with behavioral continuity, sanction sensitivity, and costly non-fungibility.
Reference graph
Works this paper leans on
-
[1]
Ryan Abbott and Alex Sarch. 2020. Punishing Artificial Intelligence: Legal Fiction or Science Fiction. InIs Law Computable?Hart Publishing. doi:10.5040/9781509937097.ch-008
-
[2]
Marwa Abdulhai, Ryan Cheng, Donovan Clay, Tim Althoff, Sergey Levine, and Natasha Jaques. 2025. Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning. doi:10.48550/arXiv.2511.00222
-
[3]
Deepak Bhaskar Acharya, Karthigeyan Kuppan, and B. Divya. 2025. Agentic AI: Autonomous Intelligence for Complex Goals—A Comprehensive Survey.IEEE Access13 (2025), 18912–18936. doi:10.1109/ACCESS.2025.3532853
-
[4]
Elif Akata, Lion Schulz, Julian Coda-Forno, Seong Joon Oh, Matthias Bethge, and Eric Schulz. 2025. Playing repeated games with large language models.Nature Human Behaviour9, 7 (May 2025), 1380–1390. doi:10.1038/s41562-025-02172-y
-
[5]
2013.Diagnostic and Statistical Manual of Mental Disorders
American Psychiatric Association. 2013.Diagnostic and Statistical Manual of Mental Disorders. American Psychiatric Association. doi:10.1176/appi.books.9780890425596
-
[6]
Maksym Andriushchenko, Francesco Croce, and Nicolas Flammarion. 2025. Jailbreaking Leading Safety-Aligned LLMs with Simple Adaptive Attacks. InProceedings of the 13th International Conference on Learning Representations (ICLR). doi:10.48550/arXiv.2404.02151
-
[7]
Usman Anwar, Abulhair Saparov, Javier Rando, Daniel Paleka, Miles Turpin, Peter Hase, Ekdeep Singh Lubana, Erik Jenner, Stephen Casper, Oliver Sourbut, Benjamin L. Edelman, Zhaowei Zhang, Mario Günther, Anton Korinek, Jose Hernandez-Orallo, Lewis Hammond, Eric Bigelow, Alexander Pan, Lauro Langosco, Tomasz Korbak, Heidi Zhang, Ruiqi Zhong, Seán Ó hÉigeart...
-
[8]
Arbel, Simon Goldstein, and Peter Salib
Yonathan A. Arbel, Simon Goldstein, and Peter Salib. 2026. How to Count AIs: Individuation and Liability for AI Agents.SSRN Electronic Journal(2026). doi:10.2139/ssrn.6273198
-
[9]
1984.The Evolution of Cooperation
Robert Axelrod. 1984.The Evolution of Cooperation. Basic Books
1984
-
[10]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.08073 2022
-
[11]
Annette Baier. 1986. Trust and Antitrust.Ethics96, 2 (Jan. 1986), 231–260. doi:10.1086/292745
-
[12]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’21). ACM, 610–623. doi:10.1145/3442188.3445922
-
[13]
Jan Betley, Niels Warncke, Anna Sztyber-Betley, Daniel Tan, Xuchan Bao, Martín Soto, Megha Srivastava, Nathan Labenz, and Owain Evans. 2026. Training Large Language Models on Narrow Tasks Can Lead to Broad Misalignment.Nature649 (2026), 584–589. doi:10.1038/s41586-025-09937-5
-
[14]
Brown, Johnathan Flowers, Anthony Ventura, and Hanlin Konya
Abeba Birhane, Elayne Ruane, Thomas Laurent, Matthew S. Brown, Johnathan Flowers, Anthony Ventura, and Hanlin Konya. 2024. AI Auditing: The Broken Bus on the Road to AI Accountability. InProceedings of the IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). doi:10.1109/satml59370.2024.00037
-
[15]
Piercosma Bisconti, Marcello Galisai, Federico Pierucci, Marcantonio Bracale, and Matteo Prandi. 2025. Beyond Single-Agent Safety: A Taxonomy of Risks in LLM-to-LLM Interactions. doi:10.48550/arXiv.2512.02682
-
[16]
Bolton, Elena Katok, and Axel Ockenfels
Gary E. Bolton, Elena Katok, and Axel Ockenfels. 2004. How Effective Are Electronic Reputation Mechanisms? An Experimental Investigation.Management Science50, 11 (2004), 1587–1602. doi:10.1287/mnsc.1030.0199
-
[17]
Robert Boyd and Peter J. Richerson. 1992. Punishment allows the evolution of cooperation (or anything else) in sizable groups.Ethology and Sociobiology13, 3 (May 1992), 171–195. doi:10.1016/0162-3095(92)90032-Y
-
[18]
Diego De Siqueira Braga, Marco Niemann, Bernd Hellingrath, and Fernando Buarque De Lima Neto. 2018. Survey on Computational Trust and Reputation Models.ACM Comput. Surv.51, 5, Article 101 (Nov. 2018), 40 pages. doi:10.1145/3236008
-
[19]
Stephen E. Braude. 1995.First Person Plural: Multiple Personality and the Philosophy of Mind. Rowman & Littlefield
1995
-
[20]
2004.The Economy of Esteem: An Essay on Civil and Political Society
Geoffrey Brennan and Philip Pettit. 2004.The Economy of Esteem: An Essay on Civil and Political Society. Oxford University Press. doi:10.1093/0199246483.001.0001
-
[21]
Joanna J. Bryson, Mihailis E. Diamantis, and Thomas D. Grant. 2017. Of, for, and by the people: the legal lacuna of synthetic persons. Artificial Intelligence and Law25, 3 (Sept. 2017), 273–291. doi:10.1007/s10506-017-9214-9 Dissociative Identity FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
-
[22]
Luís Cabral and Ali Hortaçsu. 2010. The Dynamics of Seller Reputation: Evidence from eBay.The Journal of Industrial Economics58, 1 (March 2010), 54–78. doi:10.1111/j.1467-6451.2010.00405.x
-
[23]
Florian Carichon, Aditi Khandelwal, Marylou Fauchard, and Golnoosh Farnadi. 2025. The Coming Crisis of Multi-Agent Misalignment: AI Alignment Must Be a Dynamic and Social Process. doi:10.48550/arXiv.2506.01080
-
[24]
Tomer Jordi Chaffer. 2025. Know Your Agent: Governing AI Identity on the Agentic Web. (2025). doi:10.2139/ssrn.5162127
-
[25]
Alan Chan, Carson Ezell, Max Kaufmann, Kevin Wei, Lewis Hammond, Herbie Bradley, Emma Bluemke, Nitarshan Rajkumar, David Krueger, Noam Kolt, Lennart Heim, and Markus Anderljung. 2024. Visibility into AI Agents. InThe 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24). ACM, 958–973. doi:10.1145/3630106.3658948
-
[26]
Alan Chan, Noam Kolt, Peter Wills, Usman Anwar, Christian Schroeder de Witt, Nitarshan Rajkumar, Lewis Hammond, David Krueger, Lennart Heim, and Markus Anderljung. 2024. IDs for AI Systems. doi:10.48550/arXiv.2406.12137
-
[27]
Hadfield, and Markus Anderljung
Alan Chan, Kevin Wei, Sihao Huang, Nitarshan Rajkumar, Elija Perrier, Seth Lazar, Gillian K. Hadfield, and Markus Anderljung. 2025. Infrastructure for AI Agents. doi:10.48550/arXiv.2501.10114
-
[28]
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. 2025. Persona Vectors: Monitoring and Controlling Character Traits in Language Models. doi:10.48550/ARXIV.2507.21509
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.21509 2025
-
[29]
Alice Cheng and Eric Friedman. 2005. Sybilproof reputation mechanisms. InProceeding of the 2005 ACM SIGCOMM Workshop on Economics of Peer-to-Peer Systems (P2PECON ’05). ACM Press, 128–132. doi:10.1145/1080192.1080202
-
[30]
Mohd Sameen Chishti, Damilare Peter Oyinloye, and Jingyue Li. 2026. AgentReputation: A Decentralized Agentic AI Reputation Framework. doi:10.48550/ARXIV.2605.00073
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.00073 2026
-
[31]
Andy Clark and David Chalmers. 1998. The Extended Mind.Analysis58, 1 (Jan. 1998), 7–19. doi:10.1093/analys/58.1.7
-
[32]
Xin Dai. 2018. Toward a Reputation State: The Social Credit System Project of China.SSRN Electronic Journal(2018). doi:10.2139/ssrn. 3193577
-
[33]
Antonio R. Damasio. 1994.Descartes’ Error: Emotion, Reason, and the Human Brain. G.P. Putnam’s Sons
1994
-
[34]
John Danaher. 2016. Robots, law and the retribution gap.Ethics and Information Technology18, 4 (May 2016), 299–309. doi:10.1007/s10676- 016-9403-3
-
[35]
2025.ERC-8004: Trustless Agents
Marco De Rossi, Davide Crapis, Jordan Ellis, and Erik Reppel. 2025.ERC-8004: Trustless Agents. Technical Report. https://eips.ethereum. org/EIPS/eip-8004 Ethereum Improvement Proposal, Draft
2025
-
[36]
Chrysanthos Dellarocas. 2003. The Digitization of Word of Mouth: Promise and Challenges of Online Feedback Mechanisms.Manage- ment Science49, 10 (Oct. 2003), 1407–1424. doi:10.1287/mnsc.49.10.1407.17308
-
[37]
Daniel C. Dennett. 1992. The Self as a Center of Narrative Gravity. InSelf and Consciousness: Multiple Perspectives, Frank S. Kessel, Pamela M. Cole, and Dale L. Johnson (Eds.). Lawrence Erlbaum Associates, 103–115
1992
-
[38]
Ameet Deshpande, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan. 2023. Toxicity in ChatGPT: Analyzing Persona-Assigned Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics, 1236–1270. doi:10.18653/v1/2023.findings-emnlp.88
-
[39]
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. 2024. A Survey on In-Context Learning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 1107–1128. doi:10.18653/v1/2024.emnlp-main.64
-
[40]
Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang. 2025. MINJA: Memory Injection Attacks on LLM Agents via Query-Only Interaction. InAdvances in Neural Information Processing Systems (NeurIPS). doi:10.48550/arXiv.2503.03704
-
[41]
John R. Douceur. 2002.The Sybil Attack. Springer Berlin Heidelberg, 251–260. doi:10.1007/3-540-45748-8_24
-
[42]
Raymond Douglas, Jan Kulveit, Ondřej Havlíček, Theia Pearson-Vogel, Owen Cotton-Barratt, and David Duvenaud. 2026. The Artificial Self: Characterising the Landscape of AI Identity. doi:10.48550/arXiv.2603.11353
-
[43]
R. A. Duff. 2007.Answering for Crime: Responsibility and Liability in the Criminal Law. Hart Publishing. doi:10.5040/9781472560155
-
[44]
Abul Ehtesham, Aditi Singh, Gaurav Kumar Gupta, and Saket Kumar. 2025. A Survey of Agent Interoperability Protocols: Model Context Protocol (MCP), Agent Communication Protocol (ACP), Agent-to-Agent Protocol (A2A), and Agent Network Protocol (ANP). doi:10.48550/ARXIV.2505.02279
-
[45]
Naomi I. Eisenberger, Matthew D. Lieberman, and Kipling D. Williams. 2003. Does Rejection Hurt? An fMRI Study of Social Exclusion. Science302, 5643 (Oct. 2003), 290–292. doi:10.1126/science.1089134
-
[46]
Madeleine Clare Elish. 2019. Moral Crumple Zones: Cautionary Tales in Human-Robot Interaction.Engaging Science, Technology, and Society5 (March 2019), 40–60. doi:10.17351/ests2019.260
-
[47]
Karen Elliott, Kovila Coopamootoo, Edward Curran, Paul Ezhilchelvan, Samantha Finnigan, Dave Horsfall, Zhichao Ma, Magdalene Ng, Tasos Spiliotopoulos, Han Wu, and Aad van Moorsel. 2022. Know Your Customer: Balancing Innovation and Regulation for Financial Inclusion.Data & Policy4 (2022), e34. doi:10.1017/dap.2022.23
-
[48]
Ernst Fehr and Simon Gächter. 2002. Altruistic punishment in humans.Nature415, 6868 (Jan. 2002), 137–140. doi:10.1038/415137a FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Botao Amber Hu, Helena Rong, and Max Van Kleek
-
[49]
Apostolos Filippas, John J. Horton, and Joseph M. Golden. 2022. Reputation Inflation.Marketing Science41, 4 (July 2022), 733–745. doi:10.1287/mksc.2022.1350
-
[50]
B. J. Fogg. 2003. Prominence-Interpretation Theory: Explaining How People Assess Credibility Online. InCHI ’03 Extended Abstracts on Human Factors in Computing Systems (CHI ’03). ACM Press, 722–723. doi:10.1145/765891.765951
-
[51]
B. J. Fogg, Jonathan Marshall, Othman Laraki, Alex Osipovich, Chris Varma, Nicholas Fang, Jyoti Paul, Akshay Rangnekar, John Shon, Preeti Swani, and Marissa Treinen. 2001. What Makes Web Sites Credible? A Report on a Large Quantitative Study. InProceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’01). ACM, 61–68. doi:10.1145/36...
-
[52]
Eric J. Friedman and Paul Resnick. 2001. The Social Cost of Cheap Pseudonyms.Journal of Economics & Management Strategy10, 2 (June 2001), 173–199. doi:10.1111/j.1430-9134.2001.00173.x
-
[53]
Drew Fudenberg and David K. Levine. 1989. Reputation and Equilibrium Selection in Games with a Patient Player.Econometrica57, 4 (July 1989), 759–778. doi:10.2307/1913771
-
[54]
Sandro Garzon, Awid Vaziry, Enis Kuzu, Dennis Gehrmann, Buse Varkan, Alexander Gaballa, and Axel Küpper. 2026. AI Agents with Decentralized Identifiers and Verifiable Credentials. InProceedings of the 18th International Conference on Agents and Artificial Intelligence. SCITEPRESS, 252–259. doi:10.5220/0014234400004052
-
[55]
Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. 2024. Scaling Synthetic Data Creation with 1,000,000,000 Personas. doi:10.48550/arXiv.2406.20094
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.20094 2024
-
[56]
Jones Granatyr, Vanderson Botelho, Otto Robert Lessing, Edson Emílio Scalabrin, Jean-Paul Barthès, and Fabrício Enembreck. 2015. Trust and Reputation Models for Multiagent Systems.Comput. Surveys48, 2 (Oct. 2015), 1–42. doi:10.1145/2816826
-
[57]
Zihan Guo, Yuanjian Zhou, Chenyi Wang, Linlin You, Minjie Bian, and Weinan Zhang. 2025. BetaWeb: Towards a Blockchain-enabled Trustworthy Agentic Web. doi:10.48550/ARXIV.2508.13787
-
[58]
Lewis Hammond, Alan Chan, Jesse Clifton, Jason Hoelscher-Obermaier, Akbir Khan, Euan McLean, Chandler Smith, Wolfram Barfuss, Jakob Foerster, Tomáš Gavenčiak, The Anh Han, Edward Hughes, Vojtěch Kovařík, Jan Kulveit, Joel Z. Leibo, Caspar Oesterheld, Christian Schroeder de Witt, Nisarg Shah, Michael Wellman, Paolo Bova, Theodor Cimpeanu, Carson Ezell, Que...
-
[59]
H. L. A. Hart. 1968.Punishment and Responsibility: Essays in the Philosophy of Law. Oxford University Press. doi:10.1093/acprof: oso/9780199534777.001.0001
-
[60]
Joseph Henrich, Richard McElreath, Abigail Barr, Jean Ensminger, Clark Barrett, Alexander Bolyanatz, Juan Camilo Cardenas, Michael Gurven, Edwins Gwako, Natalie Henrich, Carolyn Lesorogol, Frank Marlowe, David Tracer, and John Ziker. 2006. Costly Punishment Across Human Societies.Science312, 5781 (June 2006), 1767–1770. doi:10.1126/science.1127333
-
[61]
Botao Amber Hu and Helena Rong. 2025. Spore in the Wild: A Case Study of Spore.fun as an Open-Environment Evolution Experiment with Sovereign AI Agents on TEE-Secured Blockchains. doi:10.1162/ISAL.a.838
-
[62]
Liao, Esin Durmus, Alex Tamkin, and Deep Ganguli
Saffron Huang, Divya Siddarth, Liane Lovitt, Thomas I. Liao, Esin Durmus, Alex Tamkin, and Deep Ganguli. 2024. Collective Constitutional AI: Aligning a Language Model with Public Input. doi:10.48550/arXiv.2406.07814
-
[63]
Evan Hubinger, Carson Denison, Jesse Mu, Mike Lambert, Meg Tong, Monte MacDiarmid, Tamera Lanham, Daniel M. Ziegler, Tim Maxwell, Newton Cheng, Adam Jermyn, Amanda Askell, Ansh Radhakrishnan, Cem Anil, David Duvenaud, Deep Ganguli, Fazl Barez, Jack Clark, Kamal Ndousse, Kshitij Sachan, Michael Sellitto, Mrinank Sharma, Nova DasSarma, Roger Grosse, Shauna ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2401.05566 2024
-
[64]
Trung Dong Huynh, Nicholas R. Jennings, and Nigel R. Shadbolt. 2006. An integrated trust and reputation model for open multi-agent systems.Autonomous Agents and Multi-Agent Systems13, 2 (March 2006), 119–154. doi:10.1007/s10458-005-6825-4
-
[65]
2026.International AI Safety Report 2026
International AI Safety Report Consortium. 2026.International AI Safety Report 2026. Technical Report. International AI Safety Report. https://internationalaisafetyreport.org/sites/default/files/2026-02/international-ai-safety-report-2026.pdf
2026
-
[66]
Keise Izuma, Daisuke N. Saito, and Norihiro Sadato. 2008. Processing of Social and Monetary Rewards in the Human Striatum.Neuron 58, 2 (April 2008), 284–294. doi:10.1016/j.neuron.2008.03.020
-
[67]
Jiaming Ji, Wenqi Chen, Kaile Wang, Donghai Hong, Sitong Fang, Boyuan Chen, Jiayi Zhou, Juntao Dai, Sirui Han, Yike Guo, and Yaodong Yang. 2025. Mitigating Deceptive Alignment via Self-Monitoring. doi:10.48550/arXiv.2505.18807
-
[68]
Audun Jøsang and Roslan Ismail. 2002. The Beta Reputation System. InProceedings of the 15th Bled Electronic Commerce Conference. 2502–2511
2002
-
[69]
Geoff Keeling, Winnie Street, Martyna Stachaczyk, Daria Zakharova, Iulia M. Comsa, Anastasiya Sakovych, Isabella Logothetis, Zejia Zhang, Blaise Agüera y Arcas, and Jonathan Birch. 2024. Can LLMs Make Trade-Offs Involving Stipulated Pain and Pleasure States? doi:10.48550/arXiv.2411.02432 Dissociative Identity FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
-
[70]
Bryan Kolb and Robbin Gibb. 2011. Brain Plasticity and Behaviour in the Developing Brain.Journal of the Canadian Academy of Child and Adolescent Psychiatry20, 4 (2011), 265–276
2011
-
[71]
Noam Kolt. 2024. Governing AI Agents.SSRN Electronic Journal(2024). doi:10.2139/ssrn.4772956
-
[72]
David M. Kreps and Robert Wilson. 1982. Reputation and imperfect information.Journal of Economic Theory27, 2 (Aug. 1982), 253–279. doi:10.1016/0022-0531(82)90030-8
-
[73]
Ziegler, Elizabeth Barnes, and Lawrence Chan
Thomas Kwa, Ben West, Joel Becker, Amy Deng, Katharyn Garcia, Max Hasin, Sami Jawhar, Megan Kinniment, Nate Rush, Sydney Von Arx, Ryan Bloom, Thomas Broadley, Haoxing Du, Brian Goodrich, Nikola Jurkovic, Luke Harold Miles, Seraphina Nix, Tao Lin, Neev Parikh, David Rein, Lucas Jun Koba Sato, Hjalmar Wijk, Daniel M. Ziegler, Elizabeth Barnes, and Lawrence ...
-
[74]
Donghyun Lee and Mo Tiwari. 2024. Prompt Infection: LLM-to-LLM Prompt Injection within Multi-Agent Systems. doi:10.48550/arXiv. 2410.07283
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[75]
Cheng Li, Jindong Wang, Yixuan Zhang, Kaijie Zhu, Wenxin Hou, Jianxun Lian, Fang Luo, Qiang Yang, and Xing Xie. 2023. Large Language Models Understand and Can Be Enhanced by Emotional Stimuli. doi:10.48550/arXiv.2307.11760
-
[76]
Gabriel Lima, Meeyoung Cha, Chihyung Jeon, and Kyung Sin Park. 2021. The Conflict Between People’s Urge to Punish AI and Legal Systems.Frontiers in Robotics and AI8 (Nov. 2021). doi:10.3389/frobt.2021.756242
-
[77]
Zibin Lin, Shengli Zhang, Guofu Liao, Dacheng Tao, and Taotao Wang. 2025. Binding Agent ID: Unleashing the Power of AI Agents with Accountability and Credibility. doi:10.48550/arXiv.2512.17538
-
[78]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics12 (2024), 157–173. doi:10.1162/tacl_a_00638
-
[79]
Christina Lu, Jack Gallagher, Jonathan Michala, Kyle Fish, and Jack Lindsey. 2025. The Assistant Axis: Situating and Stabilizing the Default Persona of Language Models. doi:10.48550/arXiv.2601.10387
-
[80]
Keming Lu, Bowen Yu, Chang Zhou, and Jingren Zhou. 2024. Large Language Models are Superpositions of All Characters: Attaining Arbitrary Role-play via Self-Alignment. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangkok, Thailand, 7828–7840. do...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.