What drives performance in molecular MPNNs? An operator-level factorial benchmark
Pith reviewed 2026-06-29 06:23 UTC · model grok-4.3
The pith
Message construction operators drive performance in molecular MPNNs more than update functions do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
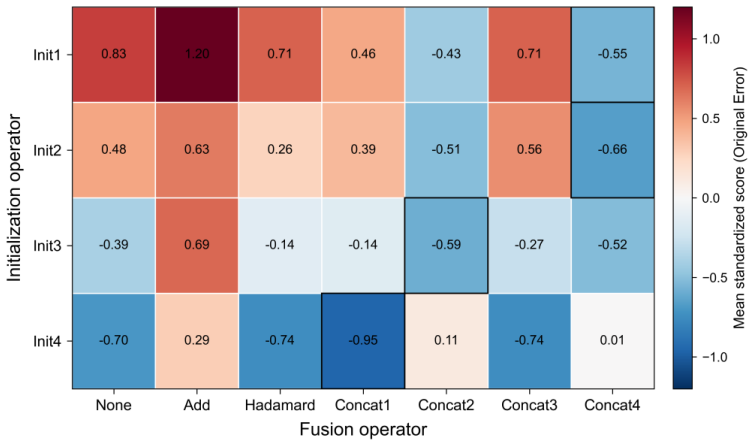
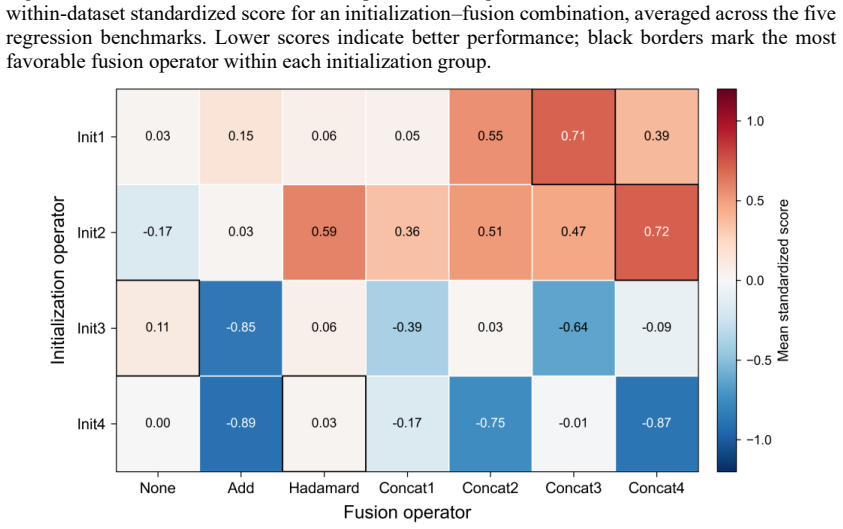
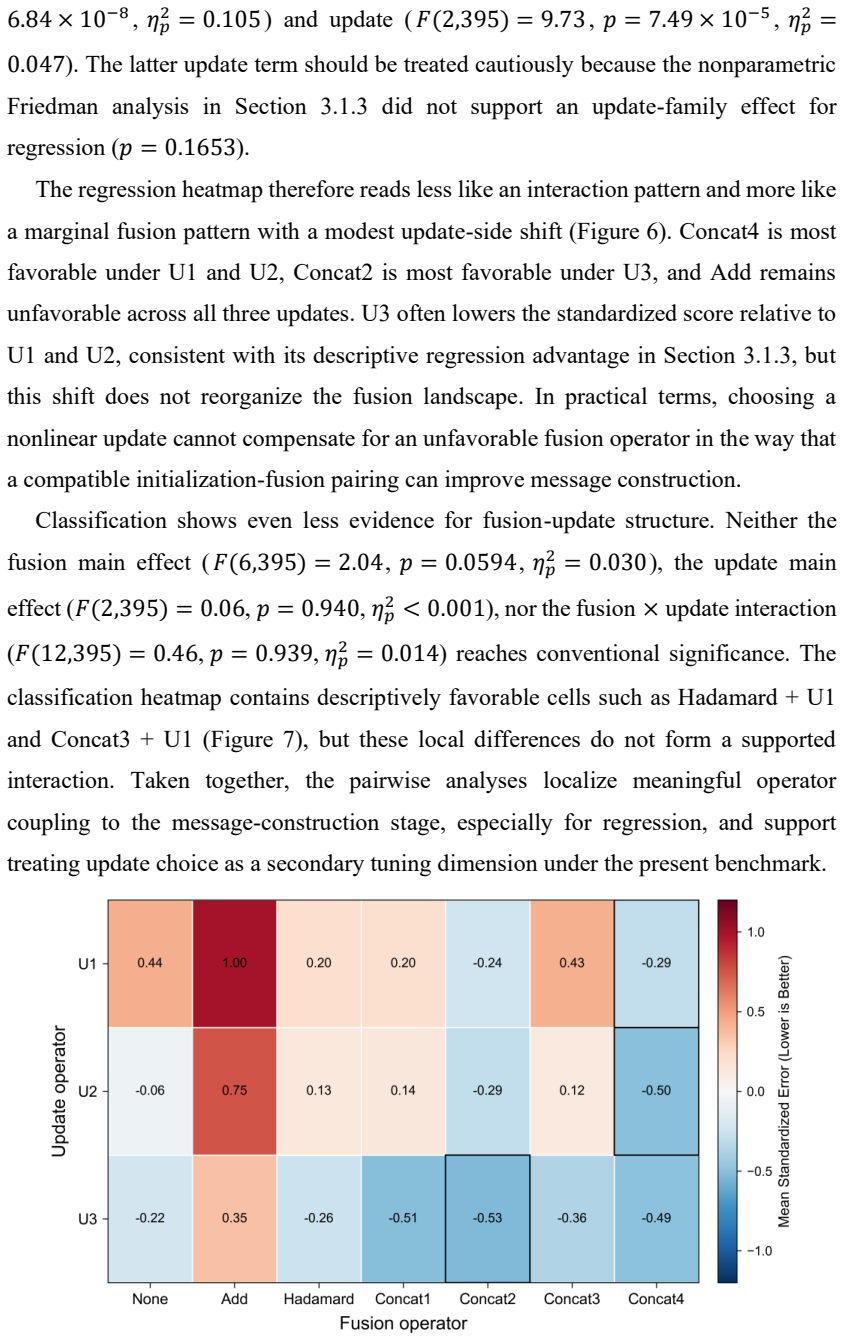
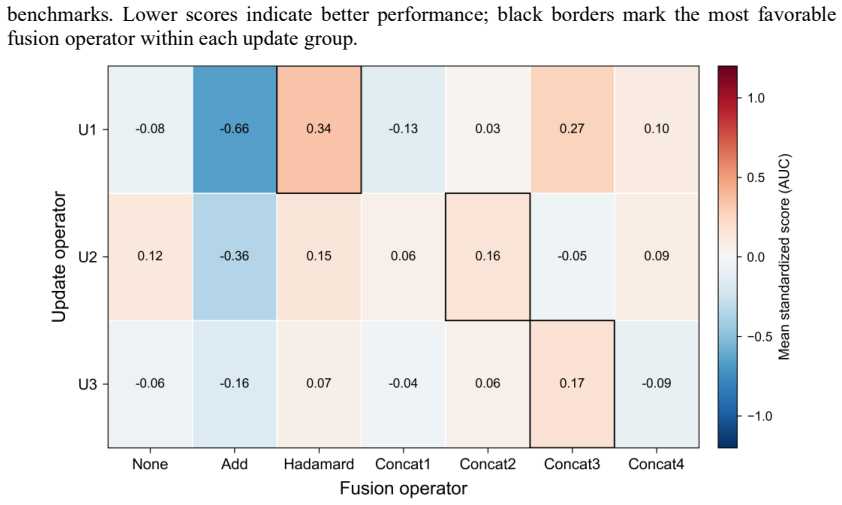
Across 84 configurations benchmarked on ten MoleculeNet datasets, performance variation is associated primarily with message construction rather than update complexity. Message-seed initialization shows significant family-level effects for both regression and classification; node-edge fusion shows a significant family-level effect for regression with descriptive advantages for concatenation-based mixing; and the update family shows no statistically supported effect for either endpoint family.
What carries the argument
An operator-level factorial benchmark that decomposes MPNNs into the three families of message-seed initialization, node-edge fusion, and node update operators.
If this is right
- Message-seed initialization choices produce measurable effects on both regression and classification tasks.
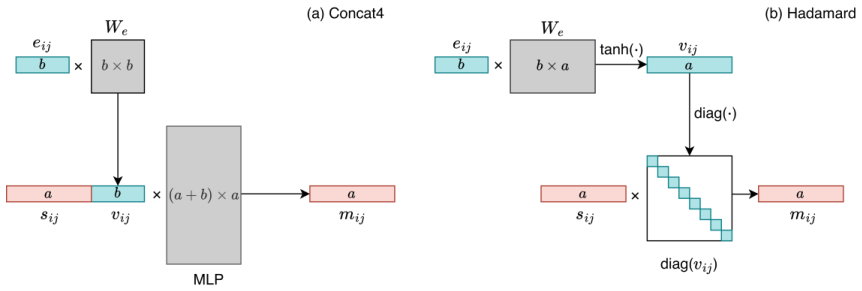
- Concatenation-based node-edge mixing outperforms Hadamard gating on regression tasks and better preserves distinctions between chemically distinct atoms.
- Node update operator complexity can be reduced without loss of performance under the tested conditions.
- Selected configurations from the benchmark recover competitive or best-in-class numbers on eight of ten MoleculeNet datasets relative to established GNN baselines.
Where Pith is reading between the lines
- Design effort can be redirected from tuning update functions toward testing message-construction variants on new molecular datasets.
- The same decomposition could be applied to 3D or equivariant MPNNs to test whether message construction remains the dominant factor.
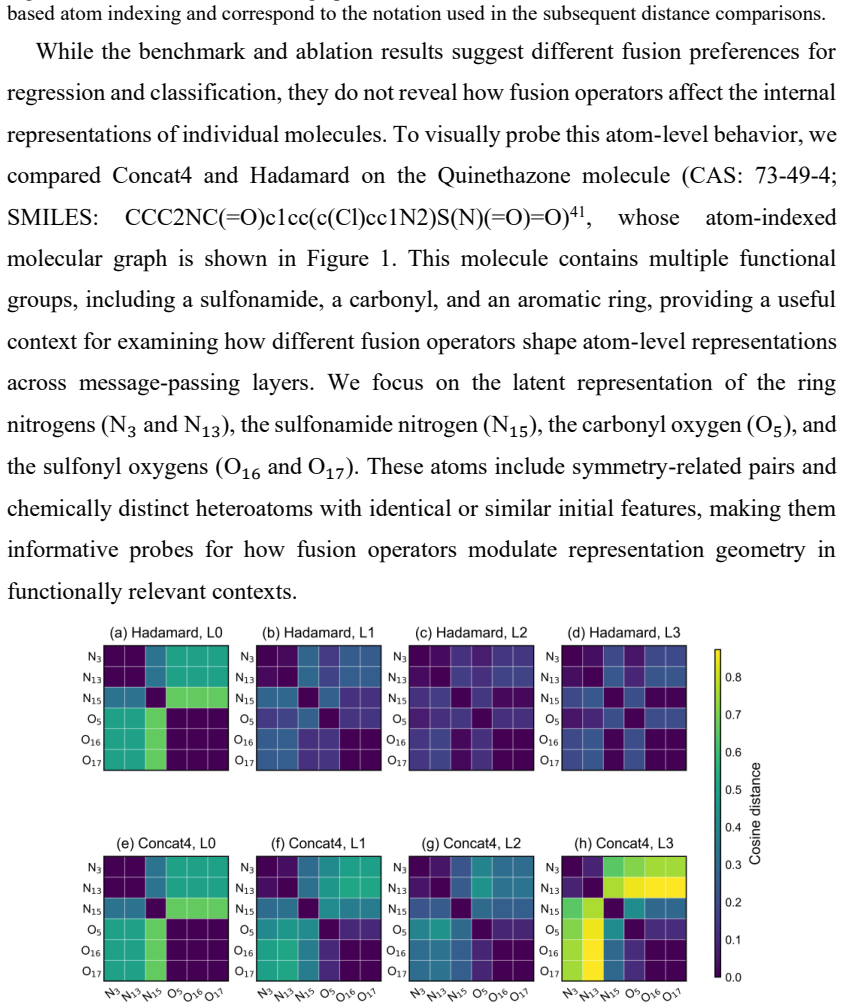
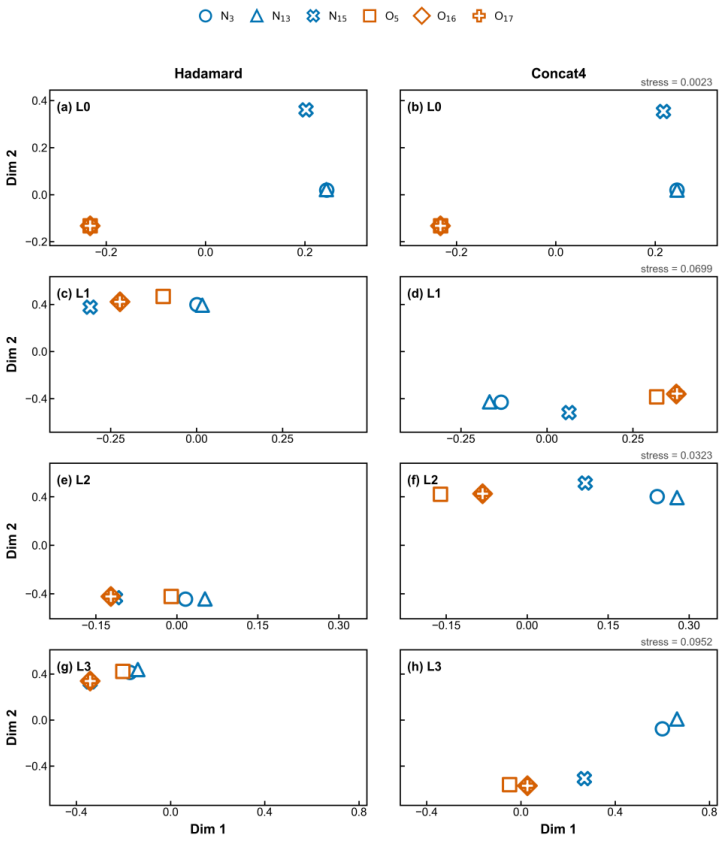
- Probes like the Quinethazone representation analysis could be extended to measure oversmoothing rates across the full factorial grid.
Load-bearing premise
The three operator families can be varied independently without hidden interactions or missing variants that would change the family-level performance rankings.
What would settle it
A new set of MPNN variants in which an update operator interacts strongly with a particular message-seed choice and produces a statistically significant performance shift on the same datasets under the same protocol.
Figures
read the original abstract
Message-passing neural networks (MPNNs) are widely used for molecular property prediction, but their deployment as monolithic architectures makes it difficult to identify how specific message-passing operators affect performance. We present an operator-level factorial benchmark that decomposes 2D molecular MPNNs into the three families of message-seed initialization, node-edge fusion, and node update operators. The resulting 84 configurations are benchmarked on ten MoleculeNet datasets under a shared experimental setup and statistical analysis protocol. Across this controlled design, performance variation is associated primarily with message construction rather than update complexity. Message-seed initialization shows significant family-level effects for both regression and classification, node-edge fusion shows a significant family-level effect for regression with descriptive advantages for concatenation-based mixing, and the update family shows no statistically supported effect for either endpoint family. A representation probe into the Quinethazone molecule further demonstrates that concatenation-based mixing can better differentiate chemically distinct heteroatoms and withstand oversmoothing than Hadamard gating. Representative configurations selected separately for classification and regression recover competitive performance relative to established molecular graph neural network (GNN) baselines, ranking numerically best on eight of ten benchmark datasets. These empirical results are interpreted through concise mechanistic analyses of representative node-edge fusion and update operators. Our findings provide empirical design heuristics for molecular MPNNs by turning model design from a search over monolithic architectures into a targeted assessment of where and how chemical information enters the message-passing pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an operator-level factorial benchmark that decomposes 2D molecular MPNNs into three families—message-seed initialization, node-edge fusion, and node update operators—yielding 84 configurations. These are evaluated on ten MoleculeNet datasets under a shared experimental setup and statistical analysis protocol. The central claim is that performance variation is associated primarily with message construction rather than update complexity: message-seed initialization shows significant family-level effects for both regression and classification, node-edge fusion shows a significant effect for regression (with descriptive advantages for concatenation), and the update family shows no statistically supported effect. A representation probe on Quinethazone and mechanistic analyses of representative operators are provided, with selected configurations achieving competitive performance against established GNN baselines on eight of ten datasets.
Significance. If the separability of operator families holds, the work supplies actionable empirical design heuristics for molecular MPNNs by reframing architecture choices as targeted assessment of message-passing components rather than monolithic search. The controlled factorial design with family-level statistical tests and the representation probe into oversmoothing and heteroatom differentiation are clear strengths that could inform more efficient model development in the field.
major comments (2)
- [Abstract (benchmark design paragraph)] Abstract (benchmark design paragraph): The attribution of performance variation primarily to message construction requires that the three families are sufficiently separable. The design reports main-effect significance but does not appear to include or report cross-family interaction terms; if non-additive interactions exist (e.g., message seeds altering gradient flow under specific update rules), the reported absence of update-family effects could be an artifact of marginal averaging rather than a robust finding. This is load-bearing for the central claim.
- [Abstract (performance variation claim)] Abstract (performance variation claim): The statement that 'performance variation is associated primarily with message construction' would be strengthened by reporting effect sizes or a variance decomposition (e.g., proportion of total variance attributable to each family versus residuals). Without this, the relative magnitude of the message-construction effects versus other sources remains unclear.
minor comments (2)
- [Abstract] Clarify the exact number of variants per family that produce the total of 84 configurations and whether all combinations were feasible under the shared experimental setup.
- The methods section should explicitly state exclusion criteria, data-split details, and the precise statistical family-level test procedure to allow verification of the reported significance results.
Simulated Author's Rebuttal
We thank the referee for these focused comments on statistical robustness. Both points are addressable through additions to the analysis and will be incorporated in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract (benchmark design paragraph)] The attribution of performance variation primarily to message construction requires that the three families are sufficiently separable. The design reports main-effect significance but does not appear to include or report cross-family interaction terms; if non-additive interactions exist (e.g., message seeds altering gradient flow under specific update rules), the reported absence of update-family effects could be an artifact of marginal averaging rather than a robust finding. This is load-bearing for the central claim.
Authors: We agree that the absence of reported interaction terms leaves open the possibility that main-effect conclusions are influenced by non-additive effects. The 3-way factorial design already contains the data needed to test two-way interactions; in the revision we will fit models that include all two-way interaction terms, report their significance, and discuss whether any significant interactions alter the interpretation of the update-family null result. revision: yes
-
Referee: [Abstract (performance variation claim)] The statement that 'performance variation is associated primarily with message construction' would be strengthened by reporting effect sizes or a variance decomposition (e.g., proportion of total variance attributable to each family versus residuals). Without this, the relative magnitude of the message-construction effects versus other sources remains unclear.
Authors: We accept that effect-size reporting would make the relative importance of the families more transparent. In the revised statistical analysis we will add partial eta-squared values for each main effect (and, where relevant, interactions) together with a simple variance-component summary showing the proportion of total variance attributable to each family versus residuals. revision: yes
Circularity Check
No circularity: purely empirical factorial benchmark with no derivations or self-referential reductions
full rationale
The paper describes an operator-level factorial benchmark that enumerates 84 MPNN configurations across three operator families and evaluates them on ten external MoleculeNet datasets under a shared protocol. All reported effects (message-seed initialization, node-edge fusion, update family) are obtained from statistical analysis of these experimental outcomes. No equations, fitted parameters, predictions, or uniqueness theorems appear in the abstract or described design. The decomposition into families is presented as an experimental design choice, not derived from prior results or self-citations. No load-bearing self-citation chains, ansatzes smuggled via citation, or renamings of known results are present. The work is self-contained against external benchmarks and datasets.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard statistical tests can detect family-level effects across regression and classification endpoints under the shared experimental protocol
Reference graph
Works this paper leans on
-
[1]
(17) Simonovsky, M.; Komodakis, N
https://openreview.net/forum?id=11vXmgtP8iF. (17) Simonovsky, M.; Komodakis, N. Dynamic Edge -Conditioned Filters in Convolutional Neural Networks on Graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) ; 2017; pp 3693 –3702. https://doi.org/10.1109/CVPR.2017.11. (18) Chen, C.; Ye, W.; Zuo, Y.; Zheng, C.; Ong, S....
-
[2]
Fast Graph Representation Learning with PyTorch Geometric
https://openreview.net/forum?id=SJU4ayYgl. (22) Bradley, A. P. The Use of the Area Under the ROC Curve in the Evaluation of Machine Learning Algorithms. Pattern Recognition 1997, 30 (7), 1145 –1159. https://doi.org/10.1016/S0031-3203(96)00142-2. (23) Delaney, J. S. ESOL: Estimating Aqueous Solubility Directly from Molecular Structure. Journal of Chemical ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/s0031-3203(96)00142-2 1997
-
[3]
Deep Graph Library: A Graph-Centric, Highly-Performant Package for Graph Neural Networks
https://openreview.net/forum?id=rJXMpikCZ. (31) Wang, M.; Zheng, D.; Ye, Z.; Gan, Q.; Li, M.; Song, X.; Zhou, J.; Ma, C.; Yu, L.; Gai, Y.; Xiao, T.; He, T.; Karypis, G.; Li, J.; Zhang, Z. Deep Graph Library: A Graph-Centric, Highly-Performant Package for Graph Neural Networks. arXiv preprint arXiv:1909.01315, 2019. https://arxiv.org/abs/1909.01315. (32) S...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/jproc.2015.2494218 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.