VideoFDB: Evaluating Full-Duplex Vision-Speech Capabilities in Conversational Agents
Pith reviewed 2026-06-29 08:26 UTC · model grok-4.3
The pith
Current vision-speech agents fail at full-duplex audiovisual conversation by treating vision as optional except for explicit questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VideoFDB establishes that existing vision-speech agents exploit vision for explicit visual question answering but not for the streaming joint audiovisual grounding required in natural conversation. Systematic failure modes include captioning collapse and visual-stream ignorance. Cascaded architectures fundamentally preclude production of full-duplex nonverbal cues.
What carries the argument
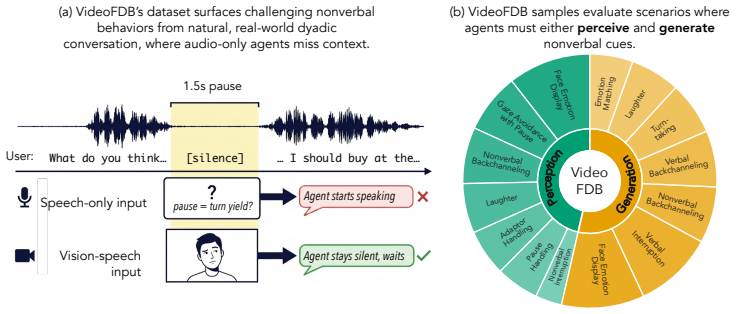
VideoFDB benchmark with 237 dyadic clips from video calls, a perception-generation taxonomy, and rubric-based LM-as-judge evaluation of nonverbal conversational dynamics.
If this is right
- Agents require continuous visual interpretation during speech rather than vision as an on-demand module.
- Cascaded speech-to-avatar designs cannot support simultaneous nonverbal production and must be replaced by integrated architectures.
- Evaluation of conversational agents must shift from isolated visual QA tasks to joint audiovisual streaming scenarios.
- Development of next-generation multimodal agents can now be tracked against concrete failure modes identified in the benchmark.
Where Pith is reading between the lines
- Models trained end-to-end on synchronized audiovisual streams may overcome the observed visual-stream ignorance.
- Extending the benchmark to measure cultural variation in nonverbal dynamics could expose additional failure modes.
- Combining VideoFDB scores with existing speech-only full-duplex benchmarks might reveal whether audio failures compound visual ones.
- Live deployment tests with the same clips could serve as an external check on the LM judge's reliability.
Load-bearing premise
The 237 dyadic clips and the rubric-based LM-as-judge framework are assumed to provide a representative and reliable measure of full-duplex AV2AV conversational quality without further human validation or inter-rater checks.
What would settle it
A new agent that scores high on the VideoFDB rubrics yet produces mismatched nonverbal timing and responses when tested in live human video calls would falsify the claim that the benchmark captures required capabilities.
Figures

read the original abstract
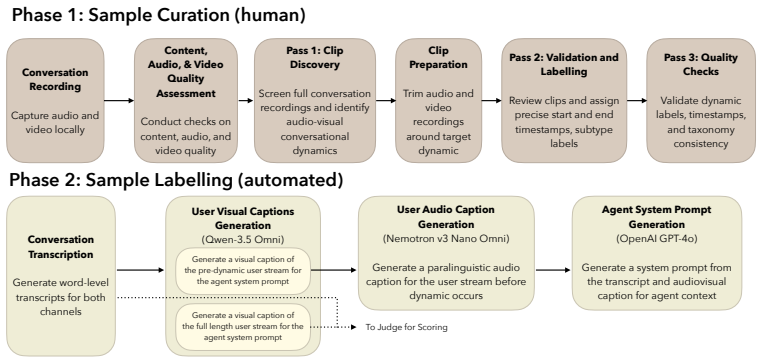
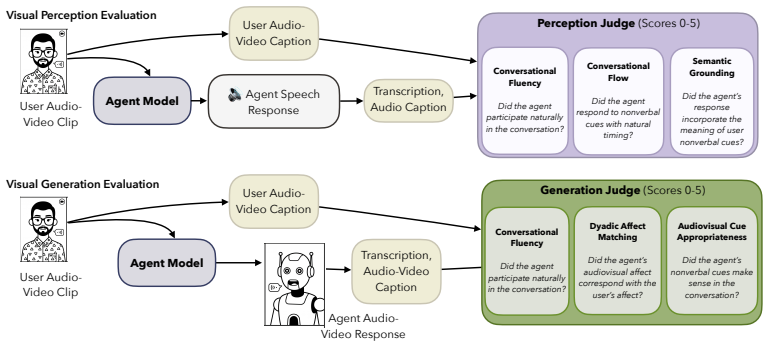
Natural human conversation is full-duplex and audio-visual: people simultaneously speak and listen while continuously interpreting and producing nonverbal cues, such as nods, smiles, and gestures. To support successful human-agent interaction, agents must model full-duplex audiovisual conversation; however, existing full-duplex benchmarks evaluate only speech. In this work, we present VideoFDB, the first benchmark to evaluate full-duplex audio-visual-to-audio-visual (AV2AV) conversational agents. VideoFDB contributes (i) 237 dyadic clips spanning 11 nonverbal conversational dynamics from real-world video calls, (ii) a taxonomy separating perception from generation behaviors, and (iii) a rubric-based LM-as-judge evaluation framework with interpretable axes for assessing conversational quality with respect to nonverbal conversational dynamics. Across open- and closed-source vision-speech agents, we find systematic failure modes: captioning collapse and visual-stream ignorance, and we show that current systems exploit vision for explicit visual question answering but not for the streaming joint audiovisual grounding required in natural conversation. We further evaluate cascaded speech-to-avatar systems and find that their architecture fundamentally precludes the production of full-duplex nonverbal cues. As the first benchmark for full-duplex AV2AV interaction, VideoFDB establishes a foundation for systematic evaluation and, we hope, will accelerate the advancement and development of next-generation multimodal conversational agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VideoFDB, the first benchmark for full-duplex AV2AV conversational agents. It contributes 237 dyadic clips spanning 11 nonverbal dynamics from real-world video calls, a taxonomy separating perception from generation behaviors, and a rubric-based LM-as-judge evaluation framework. Across open- and closed-source vision-speech agents, it reports systematic failure modes including captioning collapse and visual-stream ignorance, while also evaluating cascaded speech-to-avatar systems.
Significance. If the evaluation framework proves reliable, VideoFDB would be a significant contribution as the first dedicated benchmark for full-duplex audiovisual conversation, highlighting gaps between explicit VQA use of vision and streaming joint audiovisual grounding. The taxonomy and real-world clips provide a useful foundation for future work on multimodal agents.
major comments (2)
- [Evaluation Framework] Evaluation Framework section: The claims of systematic captioning collapse and visual-stream ignorance across agents rest entirely on the rubric-based LM-as-judge correctly assessing the 11 nonverbal dynamics in the 237 clips. No human validation, inter-rater agreement statistics, or calibration of the LM judge against human raters is reported, which is load-bearing for interpreting all failure-mode results.
- [Dataset Construction] Dataset section: The manuscript does not specify clip selection criteria or inter-annotator agreement for assigning the 11 dynamics to the 237 dyadic clips. This undermines assessment of whether the benchmark is representative for the reported failure modes.
minor comments (2)
- [Abstract] The abstract states quantitative findings on failure modes but the results section would benefit from explicit tables or metrics reporting the per-dynamics scores.
- [Taxonomy] Ensure the taxonomy is illustrated with concrete examples of perception vs. generation behaviors in a table or figure for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on VideoFDB. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation Framework] Evaluation Framework section: The claims of systematic captioning collapse and visual-stream ignorance across agents rest entirely on the rubric-based LM-as-judge correctly assessing the 11 nonverbal dynamics in the 237 clips. No human validation, inter-rater agreement statistics, or calibration of the LM judge against human raters is reported, which is load-bearing for interpreting all failure-mode results.
Authors: We agree that human validation of the LM-as-judge is essential for establishing the reliability of the reported failure modes. The original submission did not include such calibration. In the revised manuscript we will add a human validation study on a representative subset of clips, reporting inter-rater agreement (e.g., Cohen's kappa) and agreement between the LM judge and human raters across the 11 dynamics. revision: yes
-
Referee: [Dataset Construction] Dataset section: The manuscript does not specify clip selection criteria or inter-annotator agreement for assigning the 11 dynamics to the 237 dyadic clips. This undermines assessment of whether the benchmark is representative for the reported failure modes.
Authors: We acknowledge that explicit clip selection criteria and inter-annotator agreement were not reported. The revised manuscript will include a new subsection detailing the selection process from real-world video calls (e.g., duration, quality, and diversity filters) and will report inter-annotator agreement statistics for the labeling of the 11 nonverbal dynamics. revision: yes
Circularity Check
No circularity: benchmark construction and empirical evaluation contain no derivations or self-referential reductions
full rationale
The paper introduces a benchmark (237 clips, taxonomy of 11 dynamics, rubric-based LM-as-judge) and applies it to existing agents to report failure modes. No equations, first-principles derivations, fitted parameters, or predictions appear anywhere in the manuscript. Claims rest on direct empirical measurement via the new benchmark rather than any chain that reduces to its own inputs by construction. Self-citations, if present, are not load-bearing for any uniqueness theorem or ansatz. This is a standard benchmark paper whose central contribution is the dataset and evaluation protocol itself; no circularity patterns from the enumerated list apply.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Parakeet tdt 0.6b v2 (en).https://huggingface.co/nvidia/parakeet-tdt-0.6b-v2, 2024
2024
-
[2]
Effects of visibility between speaker and listener on gesture production: Some gestures are meant to be seen.Journal of Memory and Language, 44(2): 169–188, 2001
Martha W Alibali, Dana C Heath, and Heather J Myers. Effects of visibility between speaker and listener on gesture production: Some gestures are meant to be seen.Journal of Memory and Language, 44(2): 169–188, 2001
2001
-
[3]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. InProceedings of the IEEE international conference on computer vision, pages 2425–2433, 2015
2015
-
[4]
Anam cara-3: Why ai needs a face
Ben Carr. Anam cara-3: Why ai needs a face. https://anam.ai/blog/ cara-3-interactive-avatars, feb 2026. Accessed: 2026-05-05
2026
-
[5]
Avere: Improving audiovisual emotion reasoning with preference optimization
Ashutosh Chaubey, Jiacheng Pang, Maksim Siniukov, and Mohammad Soleymani. Avere: Improving audiovisual emotion reasoning with preference optimization. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps://openreview.net/forum?id=td682AAuPr
2026
-
[6]
Talking-head generation with rhythmic head motion
Lele Chen, Guofeng Cui, Celong Liu, Zhong Li, Ziyi Kou, Yi Xu, and Chenliang Xu. Talking-head generation with rhythmic head motion. InEuropean conference on computer vision, pages 35–51. Springer, 2020
2020
-
[7]
Savvy: Spatial awareness via audio-visual llms through seeing and hearing.NeurIPS, 2025
Mingfei Chen, Zijun Cui, Xiulong Liu, Jinlin Xiang, Caleb Zheng, Jingyuan Li, and Eli Shlizerman. Savvy: Spatial awareness via audio-visual llms through seeing and hearing.NeurIPS, 2025
2025
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
MiniCPM-o 4.5: Towards real-time full-duplex omni-modal interaction, 2025
Junbo Cui, Bokai Xu, Chongyi Wang, Tianyu Yu, Weiyue Sun, Yingjing Xu, Tianran Wang, Zhihui He, Wenshuo Ma, Tianchi Cai, Jiancheng Gui, Luoyuan Zhang, Xian Sun, Fuwei Huang, Moye Chen, Changlin Liu, Hanyu Liu, Ziyang Wang, Qingxin Gui, Qingzhe Han, Yuyang Wen, Huiping Liu, Rongkang Wang, Yaqi Zhang, Hongliang Wei, Chi Chen, You Li, Kechen Fang, Jie Zhou, ...
2025
-
[10]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Pearson Education, Inc, 16th edition, 01 2019
Joseph A DeVito.The Interpersonal Communication Book. Pearson Education, Inc, 16th edition, 01 2019
2019
-
[12]
Yikang Ding, Jiwen Liu, Wenyuan Zhang, Zekun Wang, Wentao Hu, Liyuan Cui, Mingming Lao, Yingchao Shao, Hui Liu, Xiaohan Li, et al. Kling-avatar: Grounding multimodal instructions for cascaded long- duration avatar animation synthesis.arXiv preprint arXiv:2509.09595, 2025
-
[13]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025. 10
2025
-
[14]
VITA-1.5: Towards GPT-4o level real-time vision and speech interaction
Chaoyou Fu, Haojia Lin, Xiong Wang, YiFan Zhang, Yunhang Shen, Xiaoyu Liu, Haoyu Cao, Zuwei Long, Heting Gao, Ke Li, Long MA, Xiawu Zheng, Rongrong Ji, Xing Sun, Caifeng Shan, and Ran He. VITA-1.5: Towards GPT-4o level real-time vision and speech interaction. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://...
2025
-
[15]
Charles Goodwin.Conversational Organization: Interaction Between Speakers and Hearers. 01 1981
1981
-
[16]
Gemini live api
Google DeepMind. Gemini live api. https://ai.google.dev/gemini-api/docs/live-api, 2025. Accessed: 2026-04-30
2025
-
[17]
Salm-duplex: Efficient and direct duplex modeling for speech-to-speech language model.Interspeech, 2025
Ke Hu, Ehsan Hosseini-Asl, Chen Chen, Edresson Casanova, Subhankar Ghosh, Piotr ˙Zelasko, Zhehuai Chen, Jason Li, Jagadeesh Balam, and Boris Ginsburg. Salm-duplex: Efficient and direct duplex modeling for speech-to-speech language model.Interspeech, 2025
2025
-
[18]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Keyframe: Persona-1-live
Keyframe. Keyframe: Persona-1-live. https://www.keyframelabs.com/blog/persona-1-live, may 2026. Accessed: 2026-05-05
2026
-
[20]
A guideline of selecting and reporting intraclass correlation coefficients for reliability research.Journal of chiropractic medicine, 15 2:155–63, 2016
Terry K Koo and Ma Li. A guideline of selecting and reporting intraclass correlation coefficients for reliability research.Journal of chiropractic medicine, 15 2:155–63, 2016. URL https://api. semanticscholar.org/CorpusID:1837377
2016
-
[21]
Perceptions as hypotheses: Saccades as experiments.Frontiers in Psychology, V olume 3 - 2012, 2012
Stephen C. Levinson and Francisco Torreira. Timing in turn-taking and its implications for processing models of language.Frontiers in Psychology, V olume 6 - 2015, 2015. ISSN 1664-1078. doi: 10.3389/fpsyg. 2015.00731. URL https://www.frontiersin.org/journals/psychology/articles/10.3389/ fpsyg.2015.00731
-
[22]
Full-Duplex-Bench v1.5: Evaluating Overlap Handling for Full-Duplex Speech Models
Guan-Ting Lin, Shih-Yun Shan Kuan, Qirui Wang, Jiachen Lian, Tingle Li, and Hung-yi Lee. Full-duplex- bench v1. 5: Evaluating overlap handling for full-duplex speech models.arXiv preprint arXiv:2507.23159, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Guan-Ting Lin, Jiachen Lian, Tingle Li, Qirui Wang, Gopala Anumanchipalli, Alexander H Liu, and Hung- yi Lee. Full-duplex-bench: A benchmark to evaluate full-duplex spoken dialogue models on turn-taking capabilities.arXiv preprint arXiv:2503.04721, 2025
-
[24]
Guan-Ting Lin, Shih-Yun Shan Kuan, Jiatong Shi, Kai-Wei Chang, Siddhant Arora, Shinji Watanabe, and Hung-yi Lee. Full-duplex-bench-v2: A multi-turn evaluation framework for duplex dialogue systems with an automated examiner.arXiv preprint arXiv:2510.07838, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Beat: A large-scale semantic and emotional multi-modal dataset for conversational gestures synthesis
Haiyang Liu, Zihao Zhu, Naoya Iwamoto, Yichen Peng, Zhengqing Li, You Zhou, Elif Bozkurt, and Bo Zheng. Beat: A large-scale semantic and emotional multi-modal dataset for conversational gestures synthesis. InEuropean conference on computer vision, pages 612–630. Springer, 2022
2022
-
[26]
Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling
Haiyang Liu, Zihao Zhu, Giorgio Becherini, Yichen Peng, Mingyang Su, You Zhou, Xuefei Zhe, Naoya Iwamoto, Bo Zheng, and Michael J Black. Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1144–1154, 2024
2024
-
[27]
Emo-reasoning: Benchmarking emotional reasoning capabilities in spoken dialogue systems
Jingwen Liu, Kan Jen Cheng, Jiachen Lian, Akshay Anand, Rishi Jain, Faith Qiao, Robin Netzorg, Huang- Cheng Chou, Tingle Li, Guan-Ting Lin, and Gopala Anumanchipalli. Emo-reasoning: Benchmarking emotional reasoning capabilities in spoken dialogue systems. 2025
2025
-
[28]
Livekit cloud
LiveKit, Inc. Livekit cloud. https://docs.livekit.io/intro/cloud/, 2026. Fully managed plat- form for building, hosting, and operating AI agent applications at scale
2026
-
[29]
Omniresponse: Online multimodal conversational response generation in dyadic interactions.NeurIPS, 2025
Cheng Luo, Jianghui Wang, Bing Li, Siyang Song, and Bernard Ghanem. Omniresponse: Online multimodal conversational response generation in dyadic interactions.NeurIPS, 2025
2025
-
[30]
Antje S. Meyer. Timing in conversation.Journal of Cognition, Apr 2023. doi: 10.5334/joc.268
-
[31]
Examining gesture production in the presence of communication challenges.JoVE (Journal of Visualized Experiments), (203):e66256, 2024
Laura M Morett. Examining gesture production in the presence of communication challenges.JoVE (Journal of Visualized Experiments), (203):e66256, 2024
2024
-
[32]
See, hear, and understand: Benchmarking audiovisual human speech understanding in multimodal large language models.CVPR Findings, 2026
Le Thien Phuc Nguyen, Zhuoran Yu, Samuel Low Yu Hang, Subin An, Jeongik Lee, Yohan Ban, SeungEun Chung, Thanh-Huy Nguyen, JuWan Maeng, Soochahn Lee, et al. See, hear, and understand: Benchmarking audiovisual human speech understanding in multimodal large language models.CVPR Findings, 2026. 11
2026
-
[33]
Generative spoken dialogue language modeling.Transactions of the Association for Computational Linguistics, 11:250–266, 2023
Tu Anh Nguyen, Eugene Kharitonov, Jade Copet, Yossi Adi, Wei-Ning Hsu, Ali Elkahky, Paden Tomasello, Robin Algayres, Benoit Sagot, Abdelrahman Mohamed, et al. Generative spoken dialogue language modeling.Transactions of the Association for Computational Linguistics, 11:250–266, 2023
2023
-
[34]
Nemotron 3 Nano Omni: Efficient and Open Multimodal Intelligence
NVIDIA, :, Amala Sanjay Deshmukh, Kateryna Chumachenko, Tuomas Rintamaki, Matthieu Le, Tyler Poon, Danial Mohseni Taheri, Ilia Karmanov, Guilin Liu, Jarno Seppanen, Arushi Goel, Mike Ranzinger, Greg Heinrich, Guo Chen, Lukas V oegtle, Philipp Fischer, Timo Roman, Karan Sapra, Collin McCarthy, Shaokun Zhang, Fuxiao Liu, Hanrong Ye, Yi Dong, Mingjie Liu, Yi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Openai realtime api
OpenAI. Openai realtime api. https://developers.openai.com/api/docs/guides/realtime,
-
[36]
Accessed: 2026-04-30
2026
-
[37]
Yizhou Peng, Yi-Wen Chao, Dianwen Ng, Yukun Ma, Chongjia Ni, Bin Ma, and Eng Siong Chng. Fd- bench: A full-duplex benchmarking pipeline designed for full duplex spoken dialogue systems, 2025. URL https://arxiv.org/abs/2507.19040
-
[38]
Dualtalk: Dual-speaker interaction for 3d talking head conversations
Ziqiao Peng, Yanbo Fan, Haoyu Wu, Xuan Wang, Hongyan Liu, Jun He, and Zhaoxin Fan. Dualtalk: Dual-speaker interaction for 3d talking head conversations. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21055–21064, 2025
2025
-
[39]
Can vision-language models answer face to face questions in the real-world? InThe Fourteenth International Conference on Learning Representations, 2026
Reza Pourreza, Rishit Dagli, Apratim Bhattacharyya, Sunny Panchal, Guillaume Berger, and Roland Memisevic. Can vision-language models answer face to face questions in the real-world? InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=I3dPEvbp8o
2026
-
[40]
Face-human-bench: A comprehensive benchmark of face and human understanding for multi-modal assistants.NeurIPS, 2025
Lixiong Qin, Shilong Ou, Miaoxuan Zhang, Jiangning Wei, Yuhang Zhang, Xiaoshuai Song, Yuchen Liu, Mei Wang, and Weiran Xu. Face-human-bench: A comprehensive benchmark of face and human understanding for multi-modal assistants.NeurIPS, 2025
2025
-
[41]
Qwen Team. Qwen2.5-Omni technical report. arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https://qwen.ai/ blog?id=qwen3.5
2026
-
[43]
Blaschko, and Tinne Tuytelaars
Gorjan Radevski, Teodora Popordanoska, Matthew B. Blaschko, and Tinne Tuytelaars. DA VE: Diagnostic benchmark for audio visual evaluation. InThe Thirty-ninth Annual Conference on Neural Information 12 Processing Systems Datasets and Benchmarks Track, 2025. URL https://openreview.net/forum? id=4ZAX1NT0ms
2025
-
[44]
Personaplex: V oice and role control for full duplex conversational speech models, 2026
Rajarshi Roy, Jonathan Raiman, Sang gil Lee, Teodor-Dumitru Ene, Robert Kirby, Sungwon Kim, Jaehyeon Kim, and Bryan Catanzaro. Personaplex: V oice and role control for full duplex conversational speech models, 2026. URLhttps://arxiv.org/abs/2602.06053
-
[45]
Amélie Royer, Moritz Böhle, Gabriel de Marmiesse, Laurent Mazaré, Neil Zeghidour, Alexandre Défossez, and Patrick Pérez. Vision-speech models: Teaching speech models to converse about images.arXiv preprint arXiv:2503.15633, 2025
-
[46]
video-SALMONN: Speech-enhanced audio-visual large language models
Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun MA, Yuxuan Wang, and Chao Zhang. video-SALMONN: Speech-enhanced audio-visual large language models. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/ forum?id=nYsh5GFIqX
2024
-
[47]
Yunlong Tang, Pinxin Liu, Zhangyun Tan, Mingqian Feng, Rui Mao, Chao Huang, Jing Bi, Yunzhong Xiao, Susan Liang, Hang Hua, et al. Mmperspective: Do mllms understand perspective? a comprehensive benchmark for perspective perception, reasoning, and robustness.The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks...
2025
-
[48]
Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier.https://github.com/snakers4/silero-vad, 2024
Silero Team. Silero vad: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier.https://github.com/snakers4/silero-vad, 2024
2024
-
[49]
Beyond turn-based interfaces: Synchronous LLMs as full-duplex dialogue agents
Bandhav Veluri, Benjamin N Peloquin, Bokai Yu, Hongyu Gong, and Shyamnath Gollakota. Beyond turn-based interfaces: Synchronous LLMs as full-duplex dialogue agents. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 21390–21402, Miami, Florida, USA, Nov...
-
[50]
Omnimmi: A comprehensive multi-modal interaction benchmark in streaming video contexts, 2025
Yuxuan Wang, Yueqian Wang, Bo Chen, Tong Wu, Dongyan Zhao, and Zilong Zheng. Omnimmi: A comprehensive multi-modal interaction benchmark in streaming video contexts, 2025
2025
-
[51]
Jackson.Pragmatics of Human Communication: A Study of Interactional Patterns, Pathologies, and Paradoxes
Paul Watzlawick, Janet Helmick Beavin, and Don D. Jackson.Pragmatics of Human Communication: A Study of Interactional Patterns, Pathologies, and Paradoxes. W. W. Norton, New York, NY , 1967
1967
-
[52]
Zhifei Xie and Changqiao Wu. Mini-omni2: Towards open-source gpt-4o with vision, speech and duplex capabilities.ArXiv, abs/2410.11190, 2024
-
[53]
Codetalker: Speech-driven 3d facial animation with discrete motion prior
Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, and Tien-Tsin Wong. Codetalker: Speech-driven 3d facial animation with discrete motion prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12780–12790, 2023
2023
-
[54]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Rtv-bench: Benchmarking mllm continuous perception, understanding and reasoning through real-time video
Shuhang Xun, Sicheng Tao, Jungang Li, Yibo Shi, Zhixin Lin, Zhanhui Zhu, Yibo Yan, Hanqian Li, Linghao Zhang, Shikang Wang, Yixin Liu, Hanbo Zhang, Ying Ma, and Xuming Hu. Rtv-bench: Benchmarking mllm continuous perception, understanding and reasoning through real-time video. InAdvances in Neural Information Processing Systems, volume 38. NeurIPS, 2025
2025
-
[56]
Victor H. Yngve. On getting a word in edgewise. 1970. URL https://api.semanticscholar.org/ CorpusID:143317921
1970
-
[57]
SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 15757–15773, Singapore, December 2023. Asso...
-
[58]
OmniFlatten: An end-to-end GPT model for seamless voice conversation
Qinglin Zhang, Luyao Cheng, Chong Deng, Qian Chen, Wen Wang, Siqi Zheng, Jiaqing Liu, Hai Yu, Chao- Hong Tan, Zhihao Du, and ShiLiang Zhang. OmniFlatten: An end-to-end GPT model for seamless voice conversation. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association...
-
[59]
I am an AI robot named VITA
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595–46623, 2023. 14 Appendix A Dataset Reviewer Dataset Access.We provide access to the full VideoFDB Evalua...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.