Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
Pith reviewed 2026-06-29 07:12 UTC · model grok-4.3
The pith
One model unifies robot manipulation, navigation, and trajectories across different bodies and scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
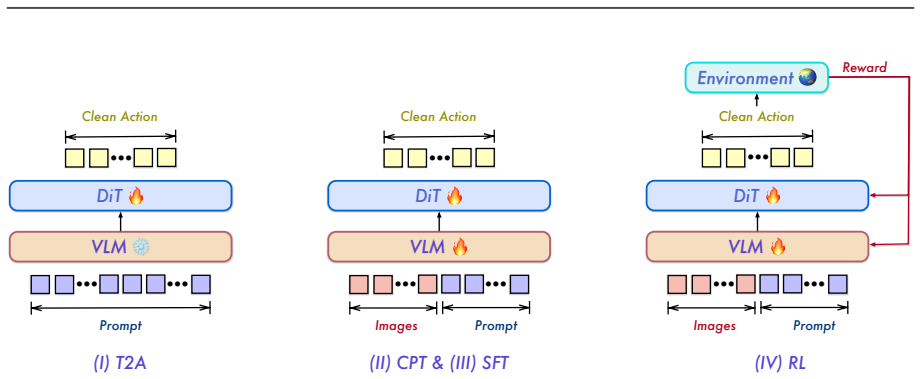
Qwen-VLA extends Qwen's vision-language modeling stack from perception and reasoning to continuous action and trajectory generation through a DiT-based action decoder, trained via large-scale joint pretraining over robotics trajectories, egocentric demonstrations, simulation data, vision-language navigation, and auxiliary vision-language sources, with embodiment-aware prompt conditioning to support multiple robot platforms, casting manipulation, navigation, and trajectory prediction into a unified action-and-trajectory prediction framework.
What carries the argument
DiT-based action decoder with embodiment-aware prompt conditioning that specifies the current robot and control convention to enable unified action-and-trajectory prediction.
If this is right
- The model reports 97.9 percent on LIBERO, 73.7 percent on Simpler-WidowX, and 76.9 percent average out-of-distribution success in real ALOHA experiments.
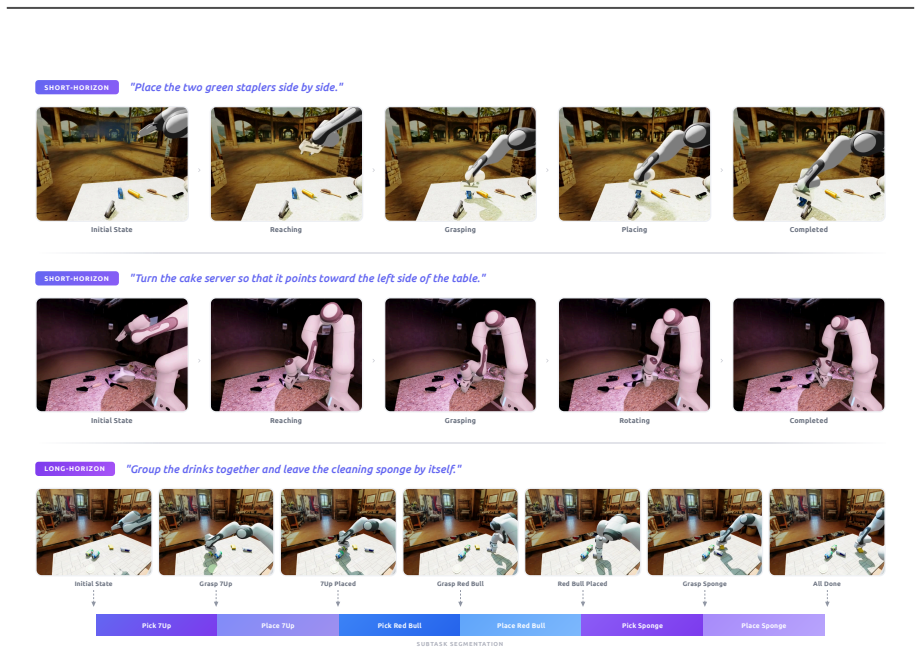
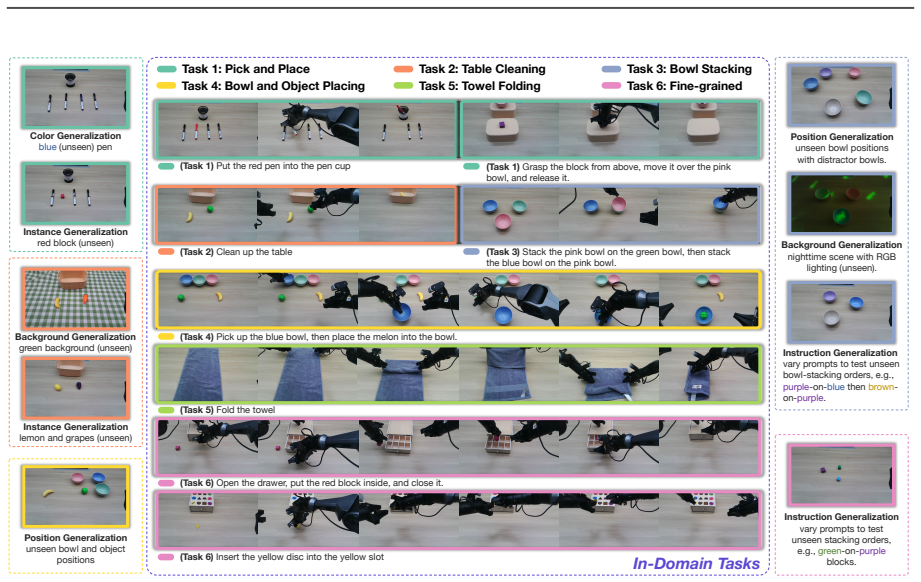
- It shows generalization under changes in scene layout, background, lighting, object configuration, and robot embodiment.
- Casting tasks into one action-and-trajectory framework allows transferable visual grounding and spatial reasoning across morphologies.
Where Pith is reading between the lines
- Scaling the joint pretraining further could allow zero-shot transfer to entirely new robot hardware without additional fine-tuning.
- The same conditioning trick might apply to other multimodal domains where the output format changes with the physical interface.
- If the unification holds, separate research tracks for manipulation versus navigation models become less necessary.
Load-bearing premise
Heterogeneous embodied decision-making problems can be unified inside one vision-language-action model by joint pretraining on diverse data and robot-specific text prompts.
What would settle it
Training the same recipe on a new robot embodiment or task family and measuring whether success rates fall below those of specialized single-task models on that embodiment.
Figures


read the original abstract
Embodied intelligence is often studied through specialized models for individual tasks such as manipulation or navigation, resulting in fragmented capabilities and limited generalization across tasks, environments, and robot embodiments. In this work, we study whether heterogeneous embodied decision-making problems can be unified within a single vision-language-action model. We present Qwen-VLA, a unified embodied foundation model that extends Qwen's vision-language modeling stack from perception, understanding, and reasoning to continuous action and trajectory generation through a DiT-based action decoder. Qwen-VLA is trained with a large-scale joint pretraining recipe over diverse data sources, including robotics manipulation trajectories, human egocentric demonstrations, synthetic simulation data, vision-and-language navigation data, trajectory-centric supervision, and auxiliary vision-language data. To support multiple robot platforms, we introduce embodiment-aware prompt conditioning, where robot-specific textual descriptions specify the current embodiment and control convention. We further cast manipulation, navigation, and trajectory prediction into a unified action-and-trajectory prediction framework, enabling transferable visual grounding, spatial reasoning, and continuous action generation across robot morphologies, task families, and environments. Experiments on manipulation, navigation, and trajectory-centric benchmarks show consistent multi-task performance and out-of-distribution generalization under variations in scene layout, background, lighting, object configuration, and robot embodiment. Qwen-VLA-Instruct achieves 97.9% on LIBERO, 73.7% on Simpler-WidowX, 86.1%/87.2% on RoboTwin-Easy/Hard, 69.0% OSR on R2R, 59.6% SR on RxR, 76.9% average OOD success in real-world ALOHA experiments, and 26.6% zero-shot success on DOMINO dynamic manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Qwen-VLA, a unified vision-language-action model that extends the Qwen VLM backbone with a DiT-based action decoder to enable continuous action and trajectory generation. It is trained via large-scale joint pretraining on heterogeneous data sources (robotics manipulation trajectories, human egocentric demonstrations, synthetic simulation, VLN data, trajectory supervision, and auxiliary VLM data) and uses embodiment-aware textual prompt conditioning to support multiple robot platforms. The central claim is that this approach unifies manipulation, navigation, and trajectory tasks into a single framework, yielding strong multi-task performance and OOD generalization across scene variations, lighting, objects, and embodiments, with reported scores including 97.9% on LIBERO, 73.7% on Simpler-WidowX, 86.1%/87.2% on RoboTwin, 69.0% OSR on R2R, 59.6% SR on RxR, 76.9% real-world ALOHA OOD, and 26.6% zero-shot on DOMINO.
Significance. If the unification claim is substantiated with proper controls, the work would be significant for embodied AI by showing that a single VLA model can span task families and robot morphologies through joint pretraining and prompt-based conditioning rather than specialized per-task models. The breadth of data sources and the DiT decoder choice are plausible technical ingredients, and the reported cross-benchmark numbers indicate potential for transferable visual grounding and action generation.
major comments (3)
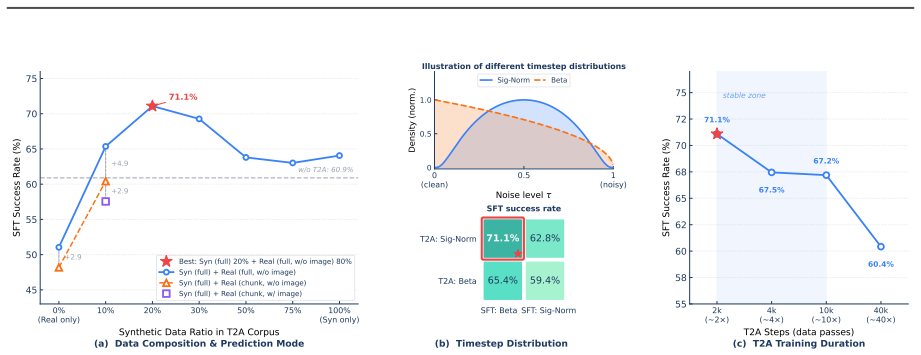
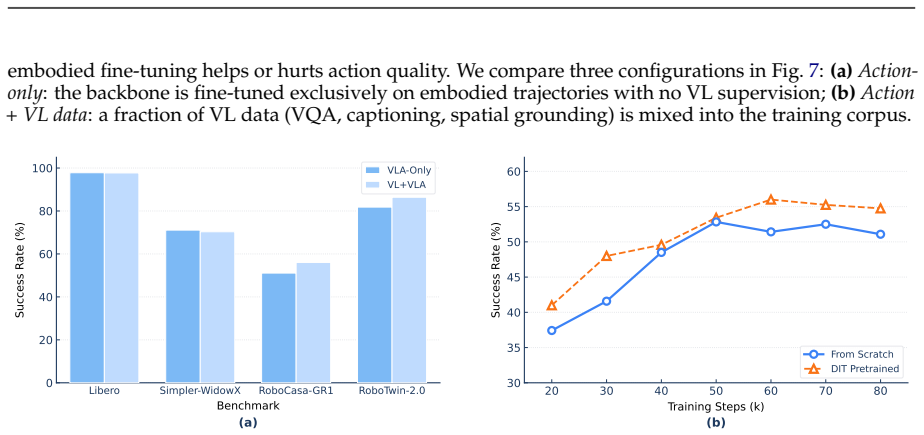
- [Abstract] Abstract: The reported benchmark scores (e.g., 97.9% LIBERO, 73.7% Simpler-WidowX) are presented without any baseline comparisons, ablations isolating the contribution of joint pretraining versus single-task training, error bars, or details on data filtering and embodiment prompt construction, so the unification benefit cannot be verified from the given text.
- [Abstract (paragraph 2)] Abstract (paragraph 2) and skeptic note: The unification claim rests on the assumption that embodiment-aware textual prompts alone allow a shared DiT decoder to correctly modulate output dimensionality, semantics, and dynamics across heterogeneous action spaces (e.g., 7-DoF WidowX vs. bimanual ALOHA) without negative transfer; no analysis, ablation, or loss-term description is supplied to address this risk.
- [Experiments] Experiments (implied by benchmark reporting): The OOD generalization results (76.9% average on real ALOHA, 26.6% zero-shot DOMINO) are presented as evidence of cross-embodiment transfer, yet no cross-embodiment ablations or comparisons to embodiment-specific heads/normalization are described, leaving the load-bearing assumption untested.
minor comments (1)
- [Abstract] The abstract refers to both 'Qwen-VLA' and 'Qwen-VLA-Instruct'; the distinction and any differences in training or prompting should be clarified in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate additional baselines, ablations, and details that strengthen the evidence for the unification approach.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported benchmark scores (e.g., 97.9% LIBERO, 73.7% Simpler-WidowX) are presented without any baseline comparisons, ablations isolating the contribution of joint pretraining versus single-task training, error bars, or details on data filtering and embodiment prompt construction, so the unification benefit cannot be verified from the given text.
Authors: We agree that the abstract would benefit from explicit context. The full manuscript reports multi-task results across benchmarks, but we will revise to include key baseline comparisons, ablations contrasting joint pretraining with single-task training, error bars, and expanded details on data filtering and embodiment prompt construction. This will make the unification benefit more verifiable. revision: yes
-
Referee: [Abstract (paragraph 2)] Abstract (paragraph 2) and skeptic note: The unification claim rests on the assumption that embodiment-aware textual prompts alone allow a shared DiT decoder to correctly modulate output dimensionality, semantics, and dynamics across heterogeneous action spaces (e.g., 7-DoF WidowX vs. bimanual ALOHA) without negative transfer; no analysis, ablation, or loss-term description is supplied to address this risk.
Authors: The embodiment-aware prompts are intended to condition the shared DiT decoder on robot-specific action spaces and dynamics. We acknowledge the absence of dedicated analysis on negative transfer risks. In revision we will add ablations with and without prompt conditioning, comparisons across action spaces, and a description of the joint training loss terms used to support modulation without negative transfer. revision: yes
-
Referee: [Experiments] Experiments (implied by benchmark reporting): The OOD generalization results (76.9% average on real ALOHA, 26.6% zero-shot DOMINO) are presented as evidence of cross-embodiment transfer, yet no cross-embodiment ablations or comparisons to embodiment-specific heads/normalization are described, leaving the load-bearing assumption untested.
Authors: The reported OOD results provide initial evidence of transfer via the unified framework. To directly test the prompt-conditioning assumption we will add cross-embodiment ablations and comparisons against models using embodiment-specific heads or normalization layers in the revised experiments section. revision: yes
Circularity Check
No circularity: empirical training and benchmark evaluation
full rationale
The paper describes joint pretraining of a VLA model on heterogeneous data sources followed by empirical evaluation on manipulation, navigation, and trajectory benchmarks. No equations, derivations, or 'predictions' are presented that reduce by construction to fitted parameters or self-citations within the paper. Embodiment-aware prompting and the DiT decoder are architectural choices whose validity is tested externally via reported success rates, not defined circularly. This is a standard empirical foundation-model paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- DiT decoder weights and training hyperparameters
- Embodiment prompt embeddings
axioms (2)
- domain assumption Heterogeneous embodied tasks can be cast as a single action-and-trajectory prediction problem
- domain assumption Textual embodiment descriptions are sufficient to condition the model across morphologies
Forward citations
Cited by 4 Pith papers
-
ABot-M0.5: Unified Mobility-and-Manipulation World Action Model
ABot-M0.5 proposes a unified mobility-and-manipulation world action model using three alignment strategies that achieves state-of-the-art performance on mobile and fine-grained manipulation benchmarks.
-
LA4VLA: Learning to Act without Seeing via Language-Action Pretraining
LA4VLA pretrains on language-action pairs from decomposed demonstrations to create reusable action priors, yielding up to 45 percentage point gains in real-world VLA success rates when mixed with standard training.
-
LA4VLA: Learning to Act without Seeing via Language-Action Pretraining
LA4VLA creates a 33K language-action dataset from existing demos and shows that pretraining on language-action pairs before or alongside vision-language-action training boosts success rates in sim and real robot tasks.
-
ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
ImageWAM shows image editing models can replace video generation in world action models, delivering better performance with 6x lower FLOPs and 4x lower latency by using edit-derived KV caches as compact context.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.