SchGen: PCB Schematic Generation with Semantic-Grounded Code Representations
Pith reviewed 2026-06-29 07:02 UTC · model grok-4.3
The pith
A semantically grounded code representation lets LLMs generate correct PCB schematics from natural language prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that encoding schematic editing primitives with relative placement and pin-name-based wiring in a semantically grounded code representation transforms PCB schematic generation from a geometry-driven problem into a semantics-driven matching task that current LLMs can perform reliably, producing functional and editable outputs from natural-language requests at higher accuracy than alternative formats or larger general-purpose models.
What carries the argument
The semantically grounded code representation, which encodes editing primitives using relative placement and pin-name-based wiring to enable semantics-driven generation.
If this is right
- LLMs can now handle wire connectivity and functional correctness in PCB schematics at scale using this format.
- Generated designs remain editable in existing tools because the output uses standard primitives.
- Representation choice directly determines whether generative models succeed on hardware design tasks.
- A dataset constructed this way supports both training and benchmarking for schematic generation.
- The method generalizes the idea that semantic grounding reduces the difficulty of structured output generation.
Where Pith is reading between the lines
- Similar representation shifts could apply to other geometry-heavy design domains such as mechanical layouts or floorplanning.
- The dataset pipeline offers a template for creating training data in fields where public examples exist but lack suitable encodings.
- End-to-end systems might chain this schematic generator with layout tools if the semantic format extends downstream.
- Performance gaps between specialized representations and general models suggest that domain-specific encoding deserves priority over model scale alone.
Load-bearing premise
The human-agent collaborative pipeline yields a large-scale, high-quality dataset of schematics in the new representation that is representative enough for training and evaluating LLMs.
What would settle it
Running the generated schematics through a standard PCB tool and finding that they produce incorrect netlists or fail functional simulation on the intended circuits would show the representation does not deliver reliable outputs.
Figures



read the original abstract
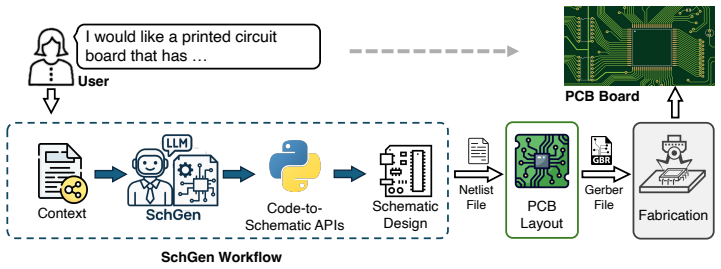
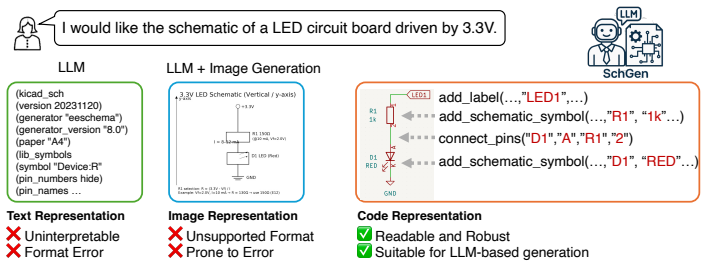
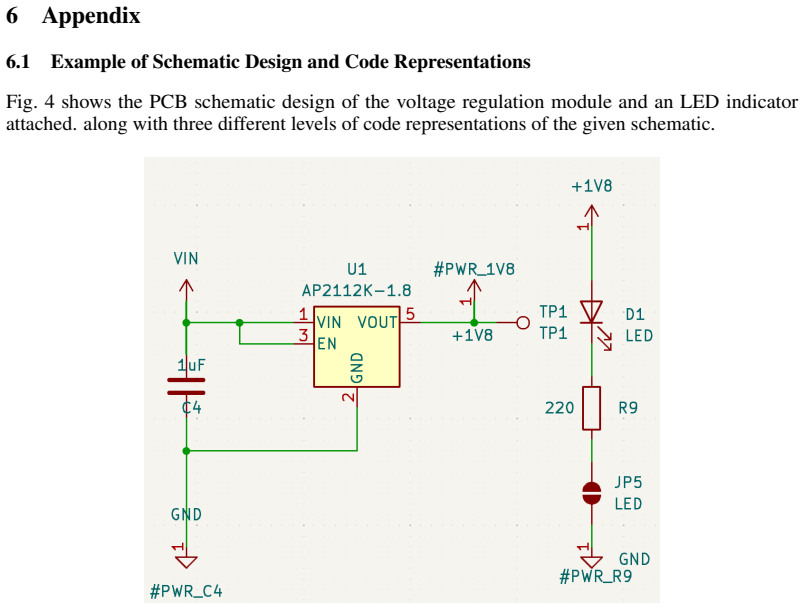
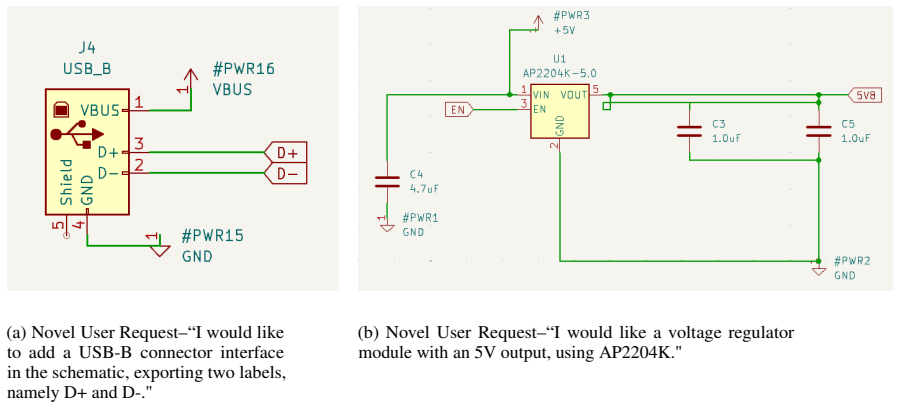
Printed circuit board (PCB) schematic design defines nearly all electronic hardware, but it remains manual and expertise-intensive. While generative AI has advanced digital and analog IC design, PCB schematic generation from natural-language intent is largely unexplored. This paper presents SchGen, the first large language model that generates editable PCB schematics from natural-language requests. The key challenge lies in the lack of an LLM-suited representation and a large-scale dataset. Current schematic formats are dominated by verbose, tool-specific syntax and geometry-heavy descriptions, making them difficult to generate reliably. We introduce a semantically grounded code representation that encodes schematic editing primitives with relative placement and pin-name-based wiring, transforming a geometry-driven generation problem into a semantics-driven matching task amenable to LLMs. We further construct a large-scale dataset of PCB schematics paired with user prompts via a human-agent collaborative pipeline that converts open-source hardware designs into our representation. Experiments show that SchGen significantly outperforms alternative representations and even larger general-purpose LLMs on wire connectivity accuracy and functional correctness. Our results highlight the critical role of representation design in enabling generative models for complex hardware design tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SchGen, the first LLM-based system for generating editable PCB schematics from natural-language prompts. It proposes a semantically grounded code representation that encodes editing primitives, relative placement, and pin-name wiring to convert geometry-driven generation into a semantics-driven task. A large-scale dataset is constructed via a human-agent collaborative pipeline that converts open-source designs into this representation. Experiments are reported to show that SchGen outperforms alternative representations and larger general-purpose LLMs on wire connectivity accuracy and functional correctness.
Significance. If the central experimental claims hold after proper validation, the work would be significant as an early demonstration that representation design can enable reliable LLM generation for complex hardware tasks such as PCB schematic design, where current formats are ill-suited to generative models. The human-agent dataset construction pipeline, if shown to preserve fidelity at scale, would also provide a reusable resource for the community.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): the claim that SchGen 'significantly outperforms' alternatives on wire connectivity accuracy and functional correctness is presented without any definition of the metrics, description of baselines, statistical tests, or raw numbers; this absence leaves the headline result unsupported and prevents assessment of whether gains are attributable to the representation rather than data artifacts.
- [§3] §3 (Dataset construction): the human-agent collaborative pipeline is described as converting open-source designs, but no quantitative validation is supplied (e.g., manual audit rates, connectivity preservation statistics, prompt fidelity scores, or coverage metrics); without these checks the assumption that the dataset is high-quality, undistorted, and representative remains unverified and is load-bearing for attributing performance to the new representation.
- [§2] §2 (Representation): while the shift from geometry-heavy to pin-name-based wiring is conceptually appealing, the paper does not provide a formal definition or grammar of the 'semantically grounded code representation,' making it impossible to reproduce the claimed transformation of the generation problem or to compare it rigorously with the 'alternative representations' mentioned in the experiments.
minor comments (2)
- [Abstract] The abstract states outperformance 'even [over] larger general-purpose LLMs' but does not name the models or their sizes; this detail should be added for clarity.
- [§2] Notation for the new representation (e.g., how relative placement and pin wiring are encoded) should be introduced with a small example in §2 to aid readability.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback. The comments identify important areas for improving the clarity, reproducibility, and validation of our work. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the claim that SchGen 'significantly outperforms' alternatives on wire connectivity accuracy and functional correctness is presented without any definition of the metrics, description of baselines, statistical tests, or raw numbers; this absence leaves the headline result unsupported and prevents assessment of whether gains are attributable to the representation rather than data artifacts.
Authors: We agree that additional details are necessary to support the experimental claims. In the revised manuscript, we will provide explicit definitions of the wire connectivity accuracy and functional correctness metrics in §4, describe all baselines used, include raw numerical results in tables, and report any statistical tests. The abstract will be updated to reference these details. This will enable a clearer assessment of the results. revision: yes
-
Referee: [§3] §3 (Dataset construction): the human-agent collaborative pipeline is described as converting open-source designs, but no quantitative validation is supplied (e.g., manual audit rates, connectivity preservation statistics, prompt fidelity scores, or coverage metrics); without these checks the assumption that the dataset is high-quality, undistorted, and representative remains unverified and is load-bearing for attributing performance to the new representation.
Authors: We acknowledge the need for quantitative validation of the dataset construction pipeline. We will augment §3 with results from manual audits on sampled designs, statistics on connectivity preservation, prompt fidelity scores, and coverage metrics to demonstrate the quality and fidelity of the generated dataset. revision: yes
-
Referee: [§2] §2 (Representation): while the shift from geometry-heavy to pin-name-based wiring is conceptually appealing, the paper does not provide a formal definition or grammar of the 'semantically grounded code representation,' making it impossible to reproduce the claimed transformation of the generation problem or to compare it rigorously with the 'alternative representations' mentioned in the experiments.
Authors: We agree that a formal definition is required for reproducibility. In the revision, we will add a formal grammar and detailed specification of the semantically grounded code representation in §2, clarifying how editing primitives, relative placement, and pin-name-based wiring are encoded. This will also aid in comparing with alternative representations. revision: yes
Circularity Check
No circularity: performance claims rest on external experimental comparisons
full rationale
The paper's central claims are empirical: a new representation is defined, a dataset is built via an external human-agent pipeline converting open-source designs, and results are reported from direct comparisons against alternative representations and larger LLMs on wire connectivity and functional correctness. No derivation chain, equations, or first-principles results are present that reduce by construction to fitted inputs or self-citations. The representation is introduced as an ansatz chosen for LLM suitability rather than derived from prior self-work, and no uniqueness theorem or load-bearing self-citation is invoked. This is the common case of an applied ML paper whose validity hinges on data quality and experiment design, not internal circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A semantics-driven representation using relative placement and pin-name wiring makes schematic generation amenable to LLMs
invented entities (1)
-
Semantically grounded code representation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1162/089976604322860677
ISSN 0899-7667. doi: 10.1162/089976604322860677. URL https://doi.org/10. 1162/089976604322860677. Cadence Design Systems. PCB Design Software | OrCAD X. https://www.cadence.com/en_ US/home/tools/pcb-design-and-analysis/orcad.html, 2025. Accessed: 2025-09-02. Chen-Chia Chang, Yikang Shen, Shaoze Fan, Jing Li, Shun Zhang, Ningyuan Cao, Yiran Chen, and Xin Z...
-
[2]
doi: 10.1109/ECCE50734.2022.9947957. Ruiyu Wang, Yu Yuan, Shizhao Sun, and Jiang Bian. Text-to-cad generation through infusing visual feedback in large language models, 2025. URLhttps://arxiv.org/abs/2501.19054. Haoyuan Wu, Zhuolun He, Xinyun Zhang, Xufeng Yao, Su Zheng, Haisheng Zheng, and Bei Yu. Chateda: A large language model powered autonomous agent ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.