VideoMLA: Low-Rank Latent KV Cache for Minute-Scale Autoregressive Video Diffusion
Pith reviewed 2026-06-29 08:15 UTC · model grok-4.3
The pith
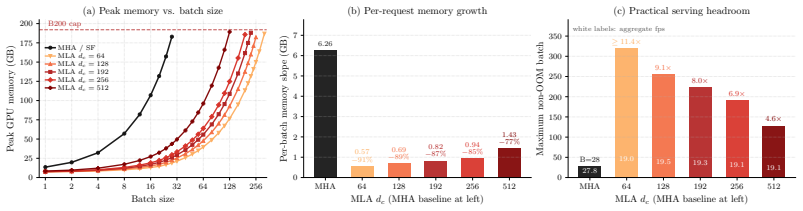
VideoMLA replaces per-head KV caches with a shared low-rank content latent and decoupled 3D-RoPE key to cut memory 92.7 percent per token in video diffusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
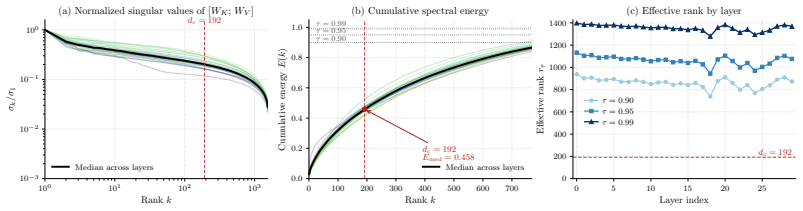
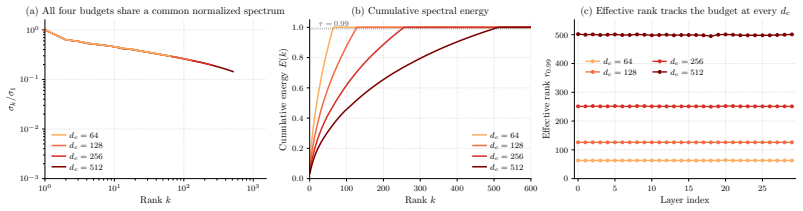
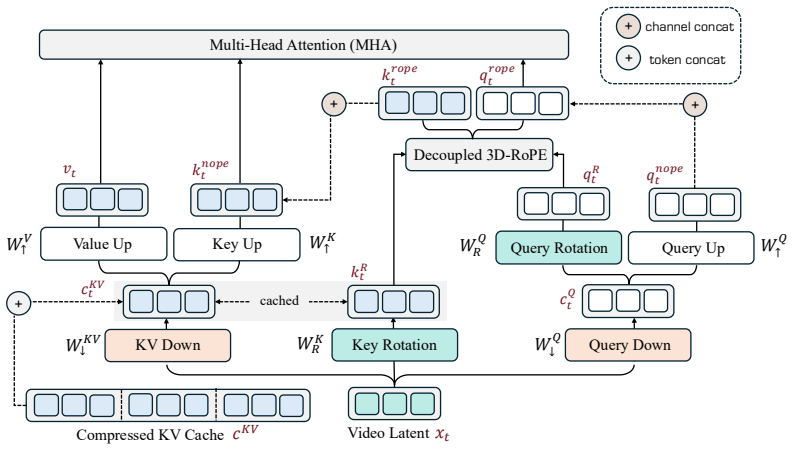
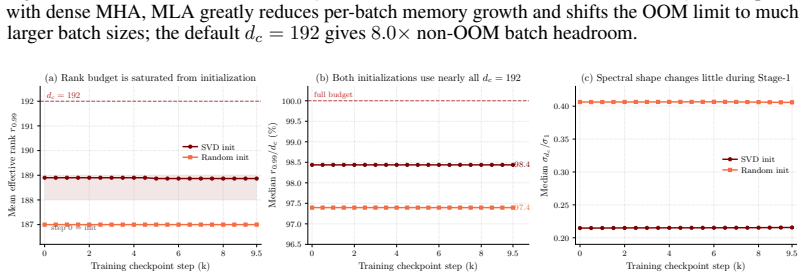
VideoMLA replaces per-head keys and values with a shared low-rank content latent and a shared decoupled 3D-RoPE positional key. This reduces per-token KV memory by 92.7 percent at every cached layer. The method retains quality at compression ratios where direct spectral approximation would predict large reconstruction error because the MLA bottleneck, rather than the pretrained spectrum, determines the effective rank: both spectral and random initializations occupy nearly the full rank budget from initialization, and training preserves this budget while adapting within it.
What carries the argument
Multi-Head Latent Attention (MLA) that projects per-head keys and values into a shared low-rank content latent while handling positions with a separate decoupled 3D-RoPE key.
If this is right
- Matches short-horizon streaming video diffusion baselines on VBench
- Achieves the best overall score at long horizons among evaluated methods
- Improves throughput by 1.23x on a single B200
- Retains quality at high compression ratios even when pretrained attention is not low-rank
Where Pith is reading between the lines
- The same latent compression pattern could be applied to autoregressive models in other modalities to achieve similar memory reductions without retraining from scratch.
- Choosing the latent dimension may matter more than the choice of initialization for rank control in attention layers across diffusion architectures.
- Minute-scale video generation may become feasible on hardware with tighter memory limits if the per-layer savings compound across deeper models.
Load-bearing premise
The low-rank latent bottleneck itself sets the effective rank during training rather than the spectrum of the pretrained attention weights.
What would settle it
Train or evaluate a video diffusion model with the same latent dimension but force a different rank occupation after training and check whether quality at the reported compression ratio collapses on long video sequences.
Figures


read the original abstract
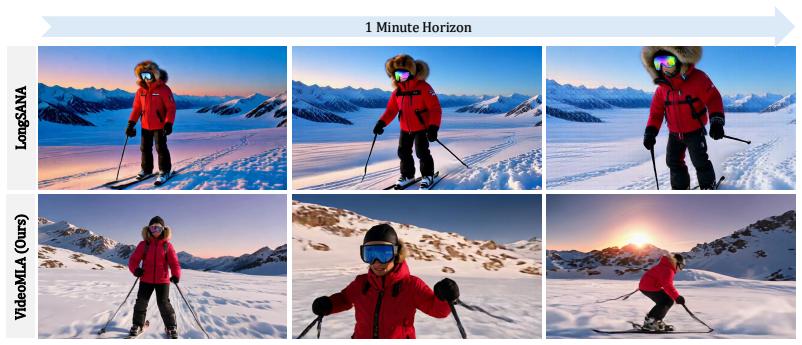
Long-rollout causal video diffusion has converged on a fixed-size sliding-window KV cache, with recent progress innovating within this layout by changing which tokens occupy the window or how their positions are encoded. The per-head KV layout itself, a dominant contributor to streaming memory and latency, has been mostly left unchanged. In this paper, we present the first study of Multi-Head Latent Attention (MLA) in video diffusion. VideoMLA replaces per-head keys and values with a shared low-rank content latent and a shared decoupled 3D-RoPE positional key, reducing per-token KV memory by 92.7% at every cached layer. We further investigate why MLA succeeds in video diffusion even though the spectral assumption often used to motivate it in language models does not hold: pretrained video attention is not low-rank, with 99%-energy effective rank far above any practical latent dimension. VideoMLA retains quality at compression ratios where direct spectral approximation would predict large reconstruction error. We show that the MLA bottleneck, rather than the pretrained spectrum, determines the effective rank: both spectral and random initialization occupy nearly the full rank budget from initialization, and training preserves this budget while adapting within it. On VBench, VideoMLA matches short-horizon streaming video diffusion baselines, achieves the best overall score at long horizons among evaluated methods, and improves throughput by 1.23x on a single B200.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VideoMLA, an adaptation of Multi-Head Latent Attention (MLA) to autoregressive video diffusion. It replaces per-head keys and values with a shared low-rank content latent and a shared decoupled 3D-RoPE positional key, reducing per-token KV memory by 92.7% at every cached layer. Despite pretrained video attention having 99%-energy effective rank far above practical latent dimensions, VideoMLA retains quality on VBench at compression ratios where direct spectral approximation would predict large error. The authors attribute this to the MLA bottleneck determining effective rank, supported by the observation that both spectral and random initializations occupy nearly the full rank budget from the start and that training preserves this budget while adapting within it. Empirically, VideoMLA matches short-horizon streaming baselines, achieves the best overall VBench score at long horizons, and improves throughput by 1.23x on a single B200.
Significance. If the central claims hold, the work enables practical minute-scale autoregressive video diffusion by substantially lowering KV-cache memory and latency while preserving generation quality, with a concrete throughput gain. The empirical results on VBench for long-horizon settings and the investigation of rank dynamics constitute a useful contribution to efficient attention mechanisms in diffusion models. No machine-checked proofs or open reproducible code are mentioned.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments: VBench scores and throughput numbers are reported without error bars, multiple runs, ablation studies on rank choice, or any description of training data and exclusion rules; the central quality-retention claim therefore rests on summary statistics whose robustness cannot be assessed.
- [Rank-dynamics analysis] Rank-dynamics analysis: The mechanistic claim that the MLA bottleneck (rather than the pretrained spectrum) determines effective rank rests on the specific observation that spectral and random initializations occupy nearly the full rank budget from initialization and that training preserves this budget; if this rank-occupation behavior does not generalize beyond the tested models or datasets, the attribution of quality retention to the bottleneck mechanism does not hold.
minor comments (1)
- [Abstract] Abstract: The statement that this is 'the first study of MLA in video diffusion' would benefit from a brief citation to prior MLA work in language models to clarify the novelty scope.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments: VBench scores and throughput numbers are reported without error bars, multiple runs, ablation studies on rank choice, or any description of training data and exclusion rules; the central quality-retention claim therefore rests on summary statistics whose robustness cannot be assessed.
Authors: We agree that the reported metrics lack error bars, multiple runs, rank ablations, and training-data details, limiting assessment of robustness. In revision we will rerun the main experiments across multiple random seeds and report means with standard deviations for both VBench scores and throughput. We will also add an ablation table varying latent rank and expand the experimental-setup section with a full description of the training corpus and exclusion criteria. revision: yes
-
Referee: [Rank-dynamics analysis] Rank-dynamics analysis: The mechanistic claim that the MLA bottleneck (rather than the pretrained spectrum) determines effective rank rests on the specific observation that spectral and random initializations occupy nearly the full rank budget from initialization and that training preserves this budget; if this rank-occupation behavior does not generalize beyond the tested models or datasets, the attribution of quality retention to the bottleneck mechanism does not hold.
Authors: The rank-occupation observations are reported for the concrete models and datasets used in the paper. We will revise the relevant section to explicitly limit the mechanistic attribution to the tested setting and to note that broader generalization remains an open question. The consistent behavior across both spectral and random initializations still supports the bottleneck explanation within the scope of our experiments. revision: partial
Circularity Check
No significant circularity; central claims rest on direct empirical measurements
full rationale
The paper's explanation for MLA quality retention at high compression is presented as an experimental observation: both spectral and random initializations occupy nearly the full rank budget from the start, with training preserving the budget while adapting inside it. This is a post-training measurement, not a fitted parameter renamed as a prediction or a self-definitional reduction. Performance results are reported via VBench scores and throughput benchmarks rather than any derivation that reduces to its own inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes smuggled via prior work appear in the derivation chain; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard multi-head attention can be replaced by a low-rank latent without loss of expressivity when the bottleneck is the dominant constraint
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Ainslie, J., Lee-Thorp, J., De Jong, M., Zemlyanskiy, Y ., Lebrón, F., Sanghai, S.: Gqa: Training generalized multi-query transformer models from multi-head checkpoints. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 4895–4901 (2023)
2023
-
[2]
arXiv preprint arXiv:2602.10095 (2026)
Bai, X., He, G., Li, Z., Shechtman, E., Huang, X., Wu, Z.: Causality in video diffusers is separable from denoising. arXiv preprint arXiv:2602.10095 (2026)
-
[3]
Sana-video: Efficient video generation with block linear diffusion transformer, 2025
Chen, J., Zhao, Y ., Yu, J., Chu, R., Chen, J., Yang, S., Wang, X., Pan, Y ., Zhou, D., Ling, H., et al.: Sana-video: Efficient video generation with block linear diffusion transformer. arXiv preprint arXiv:2509.24695 (2025)
-
[4]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Cui, J., Wu, J., Li, M., Yang, T., Li, X., Wang, R., Bai, A., Ban, Y ., Hsieh, C.J.: Self-forcing++: Towards minute-scale high-quality video generation. arXiv preprint arXiv:2510.02283 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Autoregressive Video Generation without Vector Quantization
Deng, H., Pan, T., Diao, H., Luo, Z., Cui, Y ., Lu, H., Shan, S., Qi, Y ., Wang, X.: Autoregressive video generation without vector quantization. arXiv preprint arXiv:2412.14169 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
arXiv preprint arXiv:2505.13544 (2025)
Deng, K., Woodland, P.C.: Multi-head temporal latent attention. arXiv preprint arXiv:2505.13544 (2025)
-
[7]
arXiv preprint arXiv:2508.03694 (2025)
Gao, J., Chen, Z., Liu, X., Feng, J., Si, C., Fu, Y ., Qiao, Y ., Liu, Z.: Longvie: Multimodal-guided controllable ultra-long video generation. arXiv preprint arXiv:2508.03694 (2025)
-
[8]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Henschel, R., Khachatryan, L., Poghosyan, H., Hayrapetyan, D., Tadevosyan, V ., Wang, Z., Navasardyan, S., Shi, H.: Streamingt2v: Consistent, dynamic, and extendable long video gener- ation from text. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2568–2577 (2025)
2025
-
[9]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers)
Ji, T., Guo, B., Wu, Y ., Guo, Q., Shen, L., Chen, Z., Qiu, X., Zhang, Q., Gui, T.: Towards economical inference: Enabling deepseek’s multi-head latent attention in any transformer- based llms. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers). pp. 33313–33328 (2025)
2025
-
[11]
Pyramidal flow matching for efficient video generative modeling,
Jin, Y ., Sun, Z., Li, N., Xu, K., Jiang, H., Zhuang, N., Huang, Q., Song, Y ., Mu, Y ., Lin, Z.: Pyra- midal flow matching for efficient video generative modeling. arXiv preprint arXiv:2410.05954 (2024)
-
[12]
Kim, Y ., Hu, Q., Kuo, C.C.J., Beerel, P.A.: Memrope: Training-free infinite video generation via evolving memory tokens. arXiv preprint arXiv:2603.12513 (2026) 10
-
[13]
Li, H., Liu, S., Lin, Z., Chandraker, M.: Rolling sink: Bridging limited-horizon training and open-ended testing in autoregressive video diffusion. arXiv preprint arXiv:2602.07775 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., et al.: Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.: Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Liu, K., Hu, W., Xu, J., Shan, Y ., Lu, S.: Rolling forcing: Autoregressive long video diffusion in real time. arXiv preprint arXiv:2509.25161 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Lu, Y ., Zeng, Y ., Li, H., Ouyang, H., Wang, Q., Cheng, K.L., Zhu, J., Cao, H., Zhang, Z., Zhu, X., et al.: Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation. arXiv preprint arXiv:2512.04678 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
arXiv preprint arXiv:2502.07864 (2025)
Meng, F., Tang, P., Tang, X., Yao, Z., Sun, X., Zhang, M.: Transmla: Multi-head latent attention is all you need. arXiv preprint arXiv:2502.07864 (2025)
-
[19]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Nan, K., Xie, R., Zhou, P., Fan, T., Yang, Z., Chen, Z., Li, X., Yang, J., Tai, Y .: Openvid-1m: A large-scale high-quality dataset for text-to-video generation. arXiv preprint arXiv:2407.02371 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Advances in neural information processing systems30 (2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems30 (2017)
2017
-
[21]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
LongLive: Real-time Interactive Long Video Generation
Yang, S., Huang, W., Chu, R., Xiao, Y ., Zhao, Y ., Wang, X., Li, M., Xie, E., Chen, Y ., Lu, Y ., et al.: Longlive: Real-time interactive long video generation. arXiv preprint arXiv:2509.22622 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Anchor forcing: Anchor memory and tri-region rope for interactive streaming video diffusion
Yang, Y ., Zhang, T., Huang, W., Chen, J., Wu, B., He, X., Cai, D., Li, B., Jiang, P.T.: Anchor forcing: Anchor memory and tri-region rope for interactive streaming video diffusion. arXiv preprint arXiv:2603.13405 (2026)
-
[24]
Yesiltepe, H., Meral, T.H.S., Akan, A.K., Oktay, K., Yanardag, P.: Infinity-rope: Action- controllable infinite video generation emerges from autoregressive self-rollout. arXiv preprint arXiv:2511.20649 (2025)
-
[25]
arXiv preprint arXiv:2512.05081 (2025) 4
Yi, J., Jang, W., Cho, P.H., Nam, J., Yoon, H., Kim, S.: Deep forcing: Training-free long video generation with deep sink and participative compression. arXiv preprint arXiv:2512.05081 (2025)
-
[26]
Advances in neural information processing systems37, 47455–47487 (2024)
Yin, T., Gharbi, M., Park, T., Zhang, R., Shechtman, E., Durand, F., Freeman, B.: Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems37, 47455–47487 (2024)
2024
-
[27]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yin, T., Zhang, Q., Zhang, R., Freeman, W.T., Durand, F., Shechtman, E., Huang, X.: From slow bidirectional to fast autoregressive video diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 22963–22974 (2025)
2025
-
[28]
arXiv preprint arXiv:2512.04519 , year=
Yu, Y ., Wu, X., Hu, X., Hu, T., Sun, Y ., Lyu, X., Wang, B., Ma, L., Ma, Y ., Wang, Z., et al.: Videossm: Autoregressive long video generation with hybrid state-space memory. arXiv preprint arXiv:2512.04519 (2025)
-
[29]
arXiv e-prints pp
Zhang, L., Agrawala, M.: Packing input frame context in next-frame prediction models for video generation. arXiv e-prints pp. arXiv–2504 (2025)
2025
-
[30]
Relax forcing: Relaxed kv-memory for consistent long video generation,
Zhao, Z., Lu, Y ., Liu, Z., Song, J., Deng, J., Patras, I.: Relax forcing: Relaxed kv-memory for consistent long video generation. arXiv preprint arXiv:2603.21366 (2026) 11
-
[31]
Zhu, H., Zhao, M., He, G., Su, H., Li, C., Zhu, J.: Causal forcing: Autoregressive diffusion distillation done right for high-quality real-time interactive video generation. arXiv preprint arXiv:2602.02214 (2026) 12 Table of Contents A Videos and Website 1 B Details on User Study 1 C Background 1 C.1 Wan2.1-T2V-1.3B Backbone . . . . . . . . . . . . . . . ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.