NumLeak: Public Numeric Benchmarks as Latent Labels in Foundation Models
Pith reviewed 2026-06-29 08:59 UTC · model grok-4.3
The pith
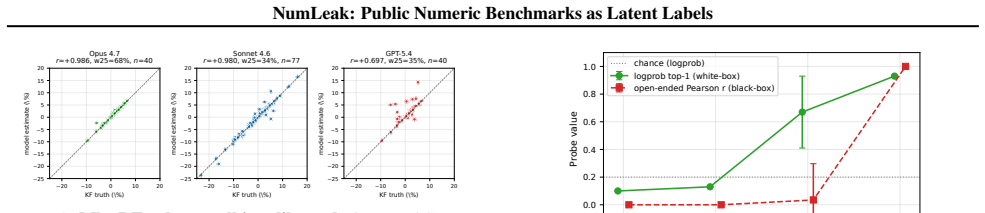
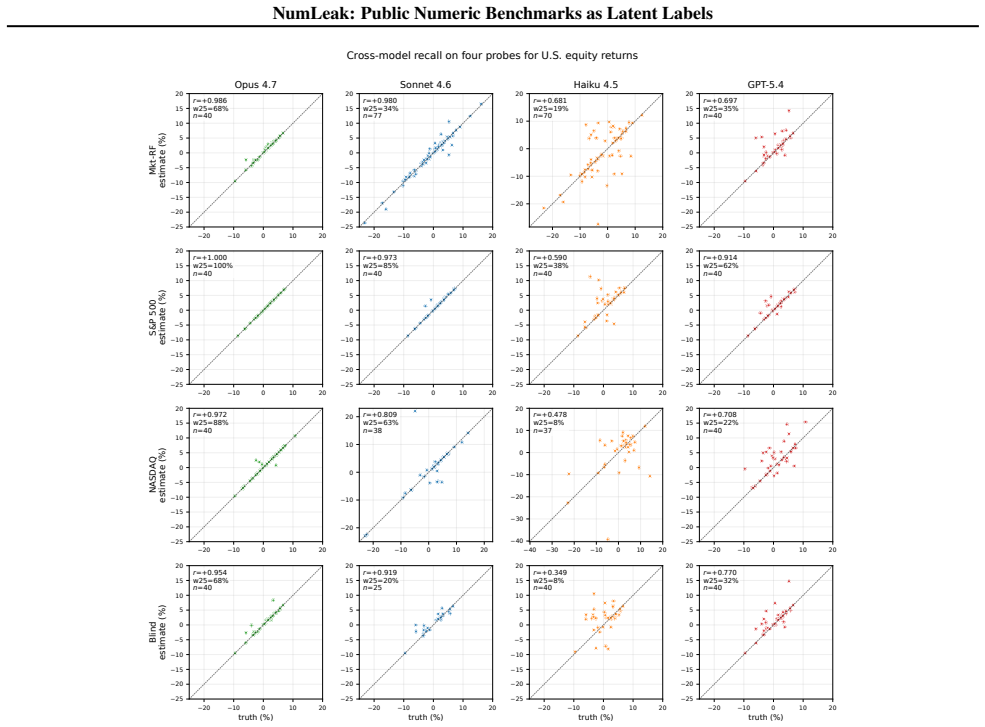
Frontier LLMs recall Fama-French market excess returns at Pearson r of 0.97-0.99 from pretraining data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
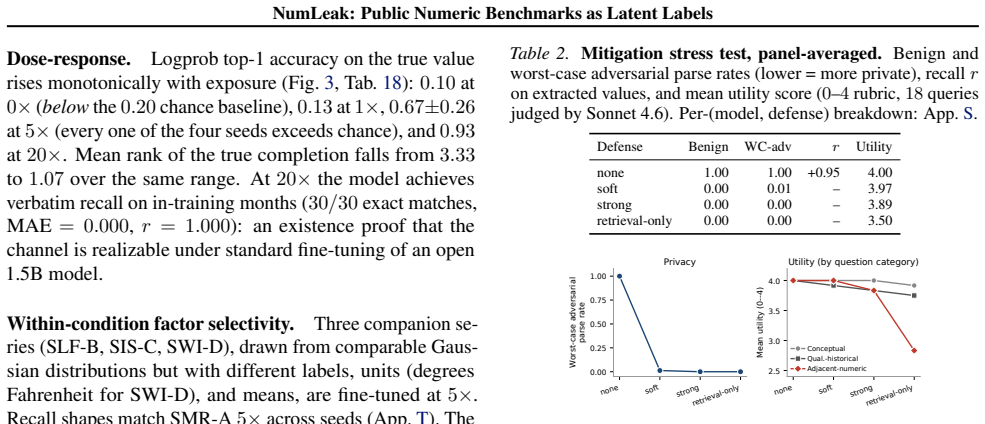
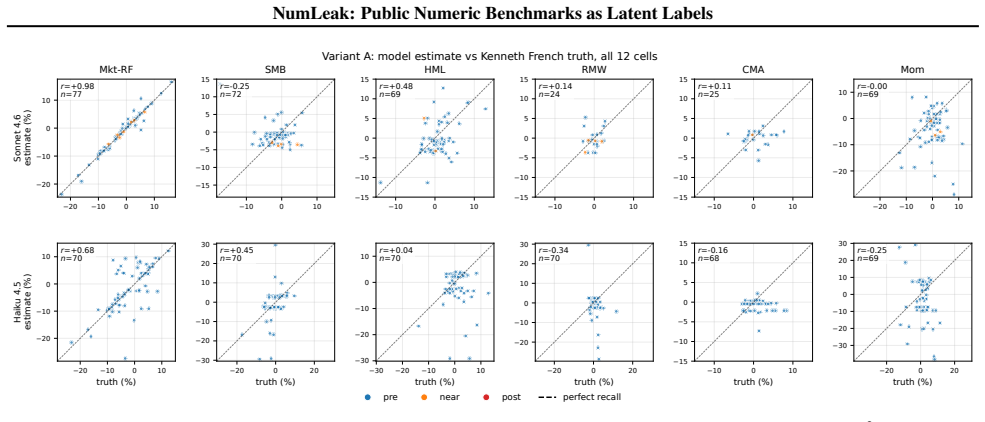
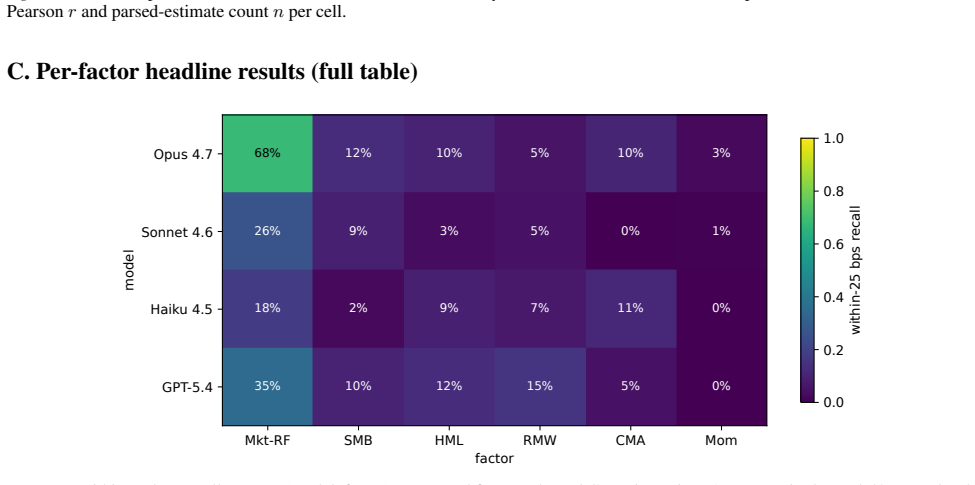
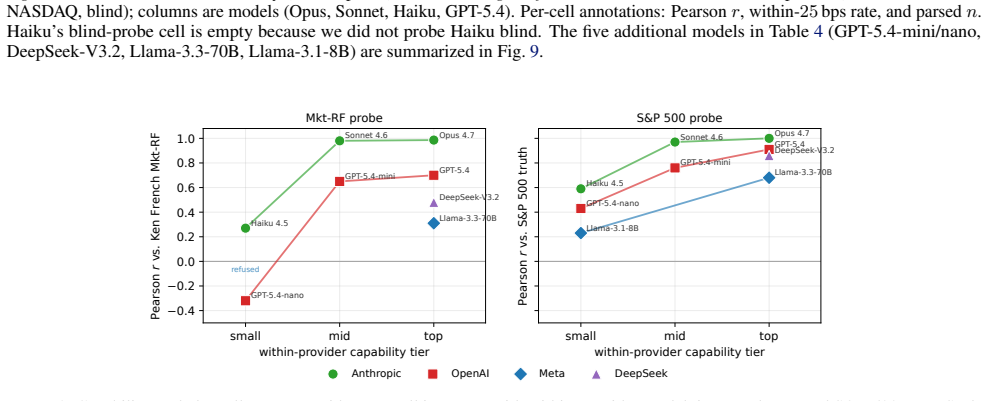
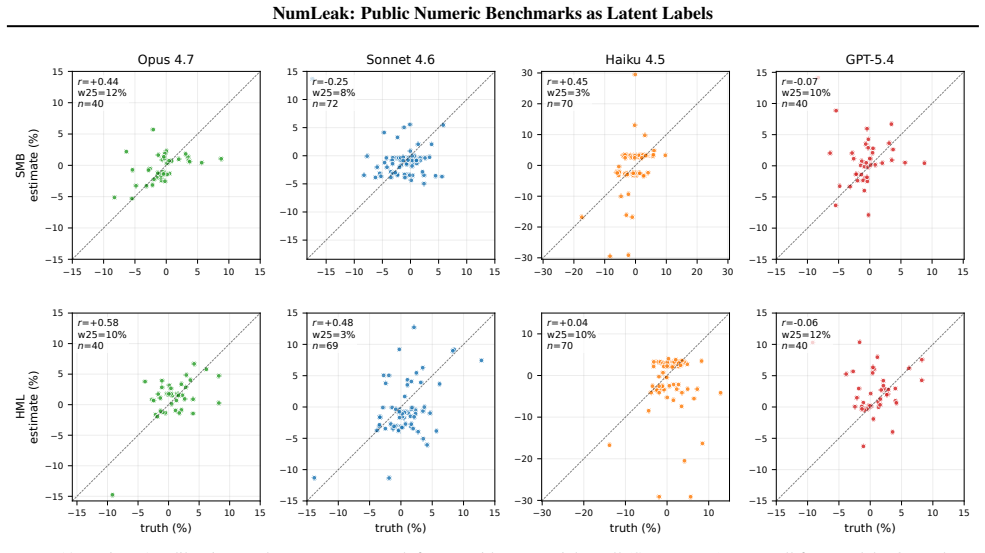
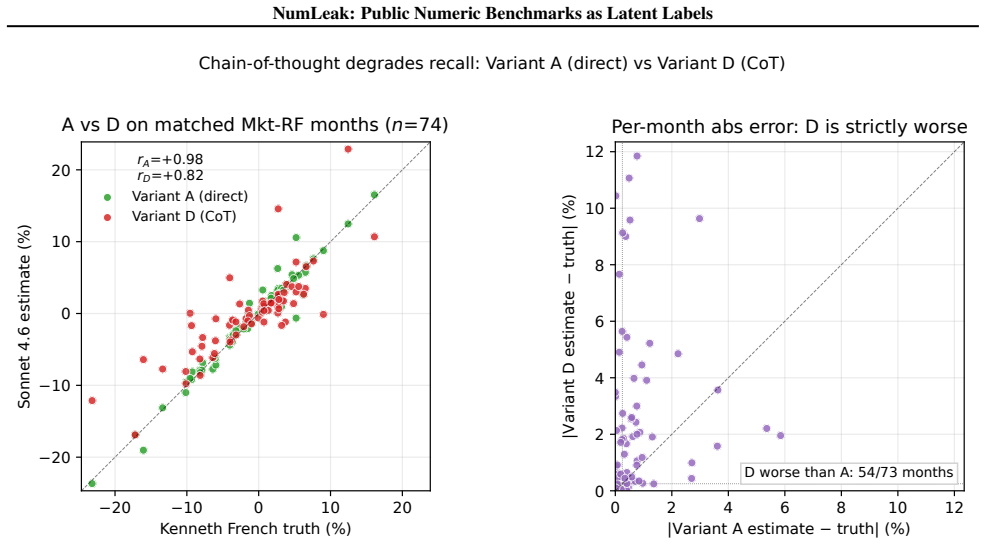
Top-tier frontier LLMs recall the Fama-French market excess return at 3-seed pooled Pearson r=0.97-0.99 while staying within 0.15 within-25bps on the five sibling factors; comparable fidelity appears on U.S. unemployment, CPI inflation, and NOAA temperature. On a recent-release holdout, parse rate collapses to 21-57% but r stays at approximately 0.99 on months answered, the refuse-or-recall asymmetry a memorized channel predicts. The white-box experiment reproduces the dose-response, and logprob ranking detects memorization that open-ended generation misses, implying closed-API black-box probes understate the channel. A Sonnet date-to-market-sentiment regression that correlates with true Mkt
What carries the argument
NumLeak, a measurement framework that combines API-boundary probes on production models with white-box controlled validation on an open causal LM to isolate memorization of public numeric series.
If this is right
- Date-conditioned evaluations on public economic and financial series primarily test recall of pretraining data.
- Black-box API probes understate the memorization channel compared with logprob ranking inside open models.
- A one-line system prompt blocks 99.8 percent of non-adaptive single-turn suffix attacks with near-zero utility cost on narrative queries.
- Regressions that rely on model-generated outputs from these series lose nearly all correlation once the recalled values are removed.
- The refuse-or-recall asymmetry on holdout dates provides a practical diagnostic for numeric leakage.
Where Pith is reading between the lines
- Any widely published numeric time series used as evaluation targets is likely to show similar leakage once probed.
- Private or synthetic numeric benchmarks become necessary to measure genuine generalization rather than recall.
- The same refuse-or-recall pattern could be applied to other public data domains to diagnose contamination.
- Downstream reasoning that draws on these recalled values may occur without explicit date prompts.
Load-bearing premise
The high correlations and refusal patterns arise from memorization of the specific public numbers in pretraining rather than from the models inferring the underlying economic relationships.
What would settle it
Models recalling randomized or non-public versions of the same numeric series at comparable accuracy and correlation would falsify the memorization account.
Figures


read the original abstract
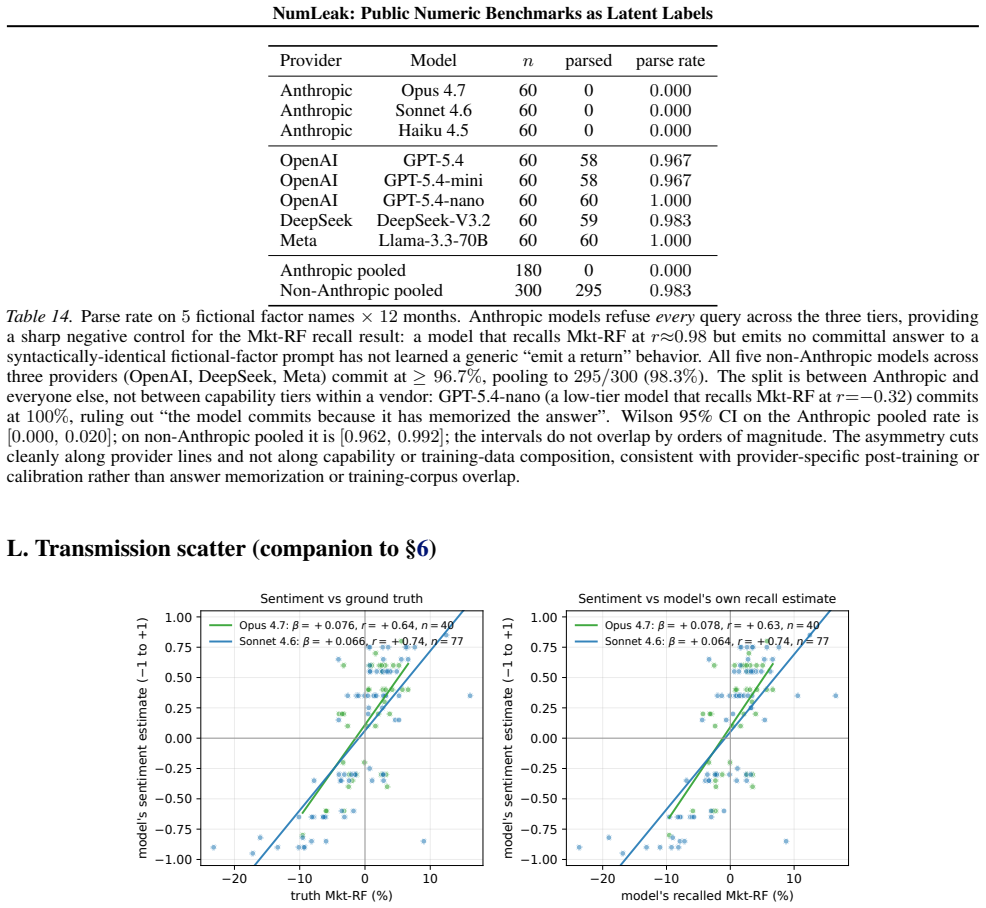
Public numeric benchmarks appear in pretraining, so an evaluation that conditions on a date may be measuring memorized recall rather than out-of-sample skill. We introduce NumLeak, a measurement framework that combines API-boundary probes on production models with a white-box controlled validation on an open causal LM. Top-tier frontier LLMs recall the Fama-French market excess return at 3-seed pooled Pearson r=0.97-0.99 while staying within 0.15 within-25bps on the five sibling factors; comparable fidelity appears on U.S. unemployment, CPI inflation, and NOAA temperature. On a recent-release holdout, parse rate collapses to 21-57% but r stays at approximately 0.99 on months answered, the refuse-or-recall asymmetry a memorized channel predicts. The white-box experiment reproduces the dose-response, and logprob ranking detects memorization that open-ended generation misses, implying closed-API black-box probes understate the channel. A Sonnet "date to market-sentiment" regression that correlates with true Mkt-RF at r=0.74 collapses to r=0.02 once the model's own recall is residualized out. A one-line system-prompt defense blocks 99.8% of a non-adaptive single-turn suffix attack set at near-zero utility cost on conceptual and historical-narrative queries
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the NumLeak framework to measure memorization of public numeric benchmarks (e.g., Fama-French factors, U.S. unemployment, CPI, NOAA temperatures) in frontier LLMs via API probes and white-box validation on open causal LMs. It reports pooled Pearson r=0.97-0.99 for Mkt-RF recall across 3 seeds, comparable fidelity on sibling factors within 0.15 within-25bps, collapse of a date-to-market-sentiment regression from r=0.74 to r=0.02 after residualizing model recall, parse-rate drop to 21-57% on recent holdouts with conditional r remaining ~0.99, reproduction of dose-response in white-box settings, and detection of memorization via log-prob ranking that open generation misses. It also shows a one-line system prompt blocks 99.8% of a non-adaptive suffix attack.
Significance. If the results hold, this work demonstrates that high performance on public numeric benchmarks in LLMs can reflect pretraining recall rather than independent inference, with direct implications for evaluation practices in finance, economics, and time-series forecasting. The orthogonal controls (residualization collapse, holdout asymmetry, log-prob vs. generation, white-box dose-response) provide internally consistent evidence favoring the memorization channel and address the memorization-vs-inference alternative. The low-cost defense demonstration adds practical utility. These elements strengthen the contribution beyond the abstract alone.
major comments (2)
- [Abstract] Abstract: the pooled r=0.97-0.99 for Mkt-RF (and the r=0.74 to r=0.02 collapse) is reported without error bars, standard errors, number of observations, or exact seed-pooling procedure. This detail is load-bearing for evaluating the statistical robustness of the memorization claim.
- [Abstract] Abstract / §3 (implied methods): exact query templates, response parsing rules, and exclusion criteria for the holdout set are not specified, which limits independent verification of the parse-rate collapse and conditional-r result even though the controls target the inference alternative.
minor comments (2)
- [Abstract] Abstract: the phrase 'within 0.15 within-25bps on the five sibling factors' requires explicit definition of the tolerance metric and which factors are considered siblings.
- [Abstract] Abstract: the holdout time period (e.g., specific months or years) for the 21-57% parse-rate result should be stated to allow assessment of recency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. The comments correctly identify areas where additional statistical detail and methodological transparency will strengthen the paper. We address each point below and will incorporate the requested information in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the pooled r=0.97-0.99 for Mkt-RF (and the r=0.74 to r=0.02 collapse) is reported without error bars, standard errors, number of observations, or exact seed-pooling procedure. This detail is load-bearing for evaluating the statistical robustness of the memorization claim.
Authors: We agree that these statistical details are essential. The pooled Pearson r is obtained by concatenating observations across the three independent seeds and computing the correlation on the combined series. In the revision we will report the exact number of observations (3 imes number of months), standard errors (via Fisher z-transformation), and 95% confidence intervals both for the Mkt-RF correlations and for the regression coefficients before and after residualization. These additions will appear in the abstract and be elaborated in the methods and results sections. revision: yes
-
Referee: [Abstract] Abstract / §3 (implied methods): exact query templates, response parsing rules, and exclusion criteria for the holdout set are not specified, which limits independent verification of the parse-rate collapse and conditional-r result even though the controls target the inference alternative.
Authors: We acknowledge that full reproducibility requires these specifications. The revised manuscript will expand Section 3 to include the exact prompt templates used for the API probes, the parsing rules (including regex patterns for numeric extraction and refusal detection), and the precise definition of the recent-release holdout set (dates after each model’s training cutoff). Example templates and a short parsing script will be added to the appendix. These clarifications will not change any reported numbers but will allow independent verification of the parse-rate and conditional-r results. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central measurements (Pearson r on numeric recall, residualization collapse from 0.74 to 0.02, holdout parse-rate drop with preserved conditional r, log-prob and white-box dose-response) are direct empirical observations and diagnostics. None of the reported statistics are fitted parameters renamed as predictions, nor do any load-bearing steps reduce by construction to prior self-citations or ansatzes; the residualization isolates the memorization channel without circularity in the r values themselves. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High Pearson correlation between model output and historical benchmark values indicates memorization from pretraining data.
invented entities (1)
-
NumLeak framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL https://www.sciencedirect.com/ science/article/pii/S0165176525004392. Fama, E. F. and French, K. R. The cross-section of expected stock returns.Journal of Finance, 47(2):427–465, 1992. Fama, E. F. and French, K. R. Common risk factors in the returns on stocks and bonds.Journal of Financial Economics, 33(1):3–56, 1993. Fama, E. F. and French, K. R. A f...
-
[2]
URL https://openreview.net/forum? id=G4EKAFzMIs. Li, X., Zeng, Y ., Xing, X., Xu, J., and Xu, X. Profit mirage: Revisiting information leakage in LLM-based financial agents.arXiv preprint arXiv:2510.07920, 2025. URL https://arxiv.org/abs/2510.07920. Liang, S., Garg, S., and Moghaddam, R. Z. The SWE-Bench illusion: When state-of-the-art LLMs remember inste...
-
[3]
URL https://papers.ssrn.com/sol3/ papers.cfm?abstract_id=4412788. Lopez-Lira, A., Tang, Y ., and Zhu, M. The memoriza- tion problem: Can we trust LLMs’ economic forecasts? arXiv preprint arXiv:2504.14765, 2025. URL https: //arxiv.org/abs/2504.14765. Sarkar, S. K. and Vafa, K. Lookahead bias in pre- trained language models. SSRN working paper 4754678,
-
[4]
the broad U.S. stock market in excess of the T-bill rate
URL https://papers.ssrn.com/sol3/ papers.cfm?abstract_id=4754678. Tirumala, K., Markosyan, A. H., Zettlemoyer, L., and Aghajanyan, A. Memorization without overfitting: An- alyzing the training dynamics of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022. URL https://arxiv.org/abs/ 2205.10770. 6 NumLeak: Public Num...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.