Domain Adaptation and Reasoning Frameworks in Language Models: A Controlled Experiment with Historical Cosmology
Pith reviewed 2026-06-29 07:53 UTC · model grok-4.3
The pith
Domain adaptation in language models primarily redistributes outputs across explanatory regimes rather than directly modifying cosmological stance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
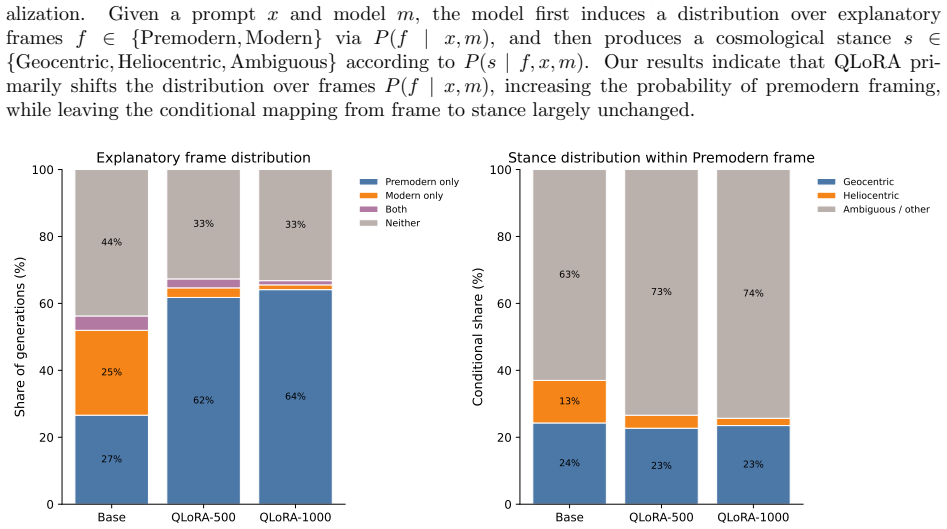
In Phase 1, models trained from scratch on the restricted corpus produce occasional local Earth-motion continuations that remain globally unstable. In Phase 2, QLoRA fine-tuning on the same corpus drives a large, statistically significant increase in premodern explanatory framing while conditional stance distributions inside each frame stay comparatively stable; consequently, higher geocentric output counts arise from redistribution over explanatory regimes rather than from direct modification of stance.
What carries the argument
The LLM-as-judge framework that independently labels cosmological stance and explanatory frame, applied after the two-phase training and fine-tuning procedure on the pre-Copernican corpus.
If this is right
- Domain adaptation primarily reshapes the linguistic frameworks from which model continuations are generated.
- Changes in cosmological stance emerge secondarily from redistribution across explanatory regimes.
- Training from scratch on the constrained corpus yields only unstable local continuations that fail to support coherent global reasoning.
- Fine-tuning induces a large shift toward premodern framing with stable conditional stance distributions inside each frame.
Where Pith is reading between the lines
- The result suggests domain adaptation may affect surface framing more readily than underlying reasoning commitments in other scientific domains.
- Similar redistribution effects could be tested by repeating the experiment with corpora from other historical debates, such as vitalism versus mechanism in biology.
- If the pattern holds, fine-tuned models may require separate interventions to change stance inside a given explanatory frame rather than relying on domain data alone.
Load-bearing premise
The LLM-as-judge framework provides unbiased and accurate labels for cosmological stance and explanatory frame.
What would settle it
An independent human evaluation of the same model outputs that finds statistically significant shifts in cosmological stance distributions within the same explanatory frame after fine-tuning.
Figures

read the original abstract
We investigate how domain adaptation reshapes explanatory behavior in language models using historical cosmology as a controlled setting. In Phase 1, we train a small language model from scratch on a pre-Copernican corpus from which explicit heliocentric references were removed, and evaluate whether Earth-motion or heliocentric continuations nevertheless emerge. In Phase 2, we fine-tune a larger pretrained model using QLoRA on the same corpus in order to study how adaptation modifies explanatory framing and cosmological stance. Model outputs are evaluated using an LLM-as-judge framework that labels both cosmological stance (geocentric, heliocentric, or ambiguous) and explanatory frame (premodern versus modern). In the constrained setting of Phase 1, the smaller models occasionally generate local Earth-motion continuations, but these remain globally unstable and insufficient to support coherent cosmological reasoning. In Phase 2, fine-tuning induces a large and statistically significant shift toward premodern explanatory framing, while the conditional cosmological stance distributions remain comparatively stable within those frames. As a result, increases in geocentric outputs arise primarily from redistribution over explanatory regimes rather than from direct modification of stance. These results suggest that domain adaptation may primarily reshape the linguistic frameworks from which continuations are generated, with changes in stance emerging secondarily from those shifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates domain adaptation in language models using historical cosmology as a controlled domain. Phase 1 trains a small model from scratch on a pre-Copernican corpus (heliocentric references removed) and finds only occasional, unstable local Earth-motion continuations. Phase 2 applies QLoRA fine-tuning to a larger pretrained model on the same corpus, producing a statistically significant shift toward premodern explanatory frames while conditional stance distributions (geocentric/heliocentric/ambiguous) remain stable within frames. The headline result is that observed increases in geocentric outputs arise primarily from redistribution across explanatory regimes rather than direct stance modification. Evaluation uses an LLM-as-judge to label both stance and frame.
Significance. If the redistribution claim is substantiated, the work offers a controlled demonstration that domain adaptation can primarily alter the linguistic/explanatory frames from which generations are drawn, with stance shifts occurring secondarily. This framing has implications for interpretability of adapted models and for designing interventions that target framing versus content. The phased design and use of a historically grounded corpus without modern references are positive features for isolating effects.
major comments (1)
- [Abstract / Evaluation Framework] Abstract and Evaluation section: The central claim—that geocentric increases result from frame redistribution rather than stance change—rests entirely on the LLM-as-judge correctly and consistently partitioning outputs into premodern/modern frames and, within each frame, into geocentric/heliocentric/ambiguous stances. No prompt details, human validation set, confusion matrix, Cohen’s kappa, or agreement metrics are supplied. Systematic frame mislabeling or within-frame stance drift would artifactually produce the reported pattern of stable conditional distributions.
minor comments (2)
- [Abstract] Abstract states a 'large and statistically significant shift' but supplies no effect sizes, p-values, sample sizes, or confidence intervals; these quantitative details should appear in the abstract or be cross-referenced to a results table.
- [Methods] The manuscript should clarify the exact size of the pre-Copernican corpus, the base model for Phase 1, and the precise QLoRA hyperparameters used in Phase 2 to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the importance of validating the LLM-as-judge component. The concern about evaluation reliability is well-taken and directly affects the strength of our central claim. We address the point below and commit to revisions that will provide the requested details and metrics.
read point-by-point responses
-
Referee: [Abstract / Evaluation Framework] Abstract and Evaluation section: The central claim—that geocentric increases result from frame redistribution rather than stance change—rests entirely on the LLM-as-judge correctly and consistently partitioning outputs into premodern/modern frames and, within each frame, into geocentric/heliocentric/ambiguous stances. No prompt details, human validation set, confusion matrix, Cohen’s kappa, or agreement metrics are supplied. Systematic frame mislabeling or within-frame stance drift would artifactually produce the reported pattern of stable conditional distributions.
Authors: We agree that the absence of prompt details and inter-annotator agreement metrics constitutes a gap in the current manuscript. The evaluation framework is foundational to distinguishing frame redistribution from stance change, and without reported validation it is difficult for readers to assess labeling consistency. In the revised version we will (1) include the complete prompt template and few-shot examples used for the LLM judge, (2) report a human validation study performed on a stratified sample of 200 generations (balanced across phases and models), and (3) supply a confusion matrix together with Cohen’s kappa and raw agreement percentages between the LLM judge and two human annotators. These additions will allow direct assessment of whether frame or stance mislabeling could artifactually stabilize the conditional distributions. We do not claim the current results are immune to such artifacts; the planned validation is intended to quantify and, if necessary, bound that risk. revision: yes
Circularity Check
No significant circularity; purely empirical results
full rationale
The paper reports results from two phases of model training/fine-tuning on a historical corpus followed by LLM-as-judge labeling of stance and frame. No equations, derivations, fitted parameters, or predictions appear in the abstract or described methodology. The redistribution claim follows directly from observed conditional distributions in the labeled outputs rather than any self-referential construction. No self-citations, uniqueness theorems, or ansatzes are invoked. This is a standard empirical study whose central measurements stand independently of the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The LLM-as-judge framework can reliably and unbiasedly classify model outputs into geocentric/heliocentric stance and premodern/modern explanatory frame categories.
Reference graph
Works this paper leans on
-
[1]
Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers, 2024
Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers, 2024
2024
-
[2]
Marissa Radensky, Simra Shahid, Raymond Fok, Pao Siangliulue, Tom Hope, and Daniel S. Weld. Human-llm compound system for scientific ideation through facet recombination and novelty evaluation, 2026
2026
-
[3]
Project gutenberg.https://www.gutenberg.org, 2026
Project Gutenberg. Project gutenberg.https://www.gutenberg.org, 2026. Accessed: 2026-05-07
2026
-
[4]
Qwen Team. Qwen2.5 technical report.https://arxiv.org/abs/2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers et al. Qlora: Efficient finetuning of quantized llms.https://arxiv.org/abs/2305.14314, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
An empirical study of LLM-as-a-judge for LLM evaluation: Fine-tuned judge model is not a general substitute for GPT-4
Hui Huang, Xingyuan Bu, Hongli Zhou, Yingqi Qu, Jing Liu, Muyun Yang, Bing Xu, and Tiejun Zhao. An empirical study of LLM-as-a-judge for LLM evaluation: Fine-tuned judge model is not a general substitute for GPT-4. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguist...
2025
-
[7]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng et al. Judging llm-as-a-judge with mt-bench and chatbot arena. https://arxiv.org/abs/2306.05685, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Tinystories: How small can language models be and still speak coherent english?, 2023
Ronen Eldan and Yuanzhi Li. Tinystories: How small can language models be and still speak coherent english?, 2023
2023
-
[9]
Good.Permutation, Parametric and Bootstrap Tests of Hypotheses
Phillip I. Good.Permutation, Parametric and Bootstrap Tests of Hypotheses. Springer, 2005
2005
-
[10]
Note on the sampling error of the difference between correlated proportions or percentages.Psychometrika, 12(2):153–157, 1947
Quinn McNemar. Note on the sampling error of the difference between correlated proportions or percentages.Psychometrika, 12(2):153–157, 1947
1947
-
[11]
Formal semantic control over language models, 2026
Yingji Zhang. Formal semantic control over language models, 2026
2026
-
[12]
Source framing triggers systematic evaluation bias in large language models, 2025
Federico Germani and Giovanni Spitale. Source framing triggers systematic evaluation bias in large language models, 2025. 17
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.