Revisiting Padded Transformer Expressivity: Which Architectural Choices Matter and Which Don't
Pith reviewed 2026-06-29 08:11 UTC · model grok-4.3
The pith
Padded transformers with constant precision equal L-uniform AC^0 circuits while growing precision reaches L-uniform TC^0 regardless of width.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
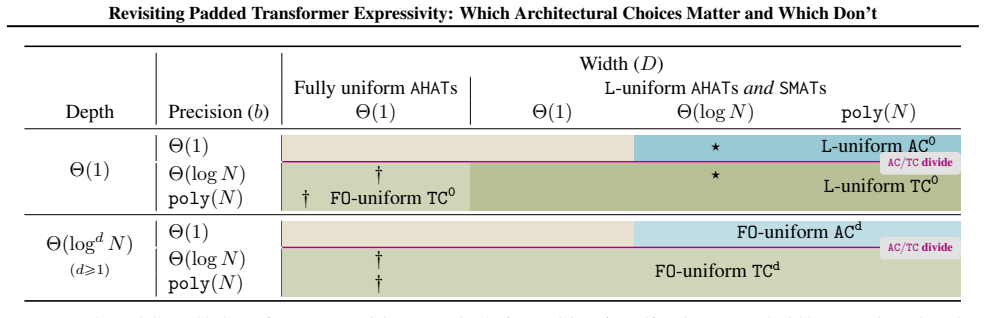
Core claim
Polynomially padded L-uniform constant-precision transformers are equivalent to L-uniform AC^0, while growing-precision ones achieve L-uniform TC^0 regardless of width. Furthermore, looping enables sequential processing analogous to circuits: log^d N-looped constant-precision transformers reach FO-uniform AC^d, and growing-precision ones reach FO-uniform TC^d. All results hold for both softmax and average hard attention transformers.
What carries the argument
Polynomially padded transformer model whose expressivity is governed by constant versus growing numeric precision and by L-uniform versus FO-uniform circuit families.
If this is right
- Increasing width beyond logarithmic size adds no further expressivity.
- Softmax attention and average hard attention produce identical expressivity results.
- Looping the transformer log^d N times raises its power from AC^0/TC^0 to AC^d/TC^d.
- Precision level, not width or attention variant, determines whether the model reaches AC^0 or TC^0.
Where Pith is reading between the lines
- Fixed-precision transformers in practice may remain confined to AC^0-level tasks even when given padded inputs.
- Recurrent or looped transformer variants could be used to target higher circuit classes without changing precision.
- Design efforts aimed at greater expressivity should prioritize scaling numeric precision over increasing width.
Load-bearing premise
Padded inputs with filler symbols supply enough polynomial space for adaptive parallel computation, and the chosen definitions of L-uniform and FO-uniform circuit families correctly model what the transformer can do.
What would settle it
Exhibit a specific language in L-uniform TC^0 that no polynomially padded growing-precision transformer (of any width) can compute, or exhibit one outside TC^0 that such a transformer can compute.
Figures
read the original abstract
Recent work describes what transformers can and cannot compute through connections to boolean circuits, but existing results lack exact characterizations and are sensitive to modeling choices. Padded transformers -- to whose input filler symbols such as ``...'' are appended -- emerge as a useful gadget for establishing equivalences to circuit classes by providing polynomial space for adaptive parallel computation. However, only a limited set of padded transformer idealizations has been studied, leaving open how robustly these equivalences hold under changes to attention type, model width, and uniformity. We find that, under practical assumptions, padded transformers are surprisingly robust to all of these, and identify numeric precision and model depth as the main factors affecting expressivity. Concretely, we prove that polynomially padded $\text{L-uniform}$ constant-precision transformers are equivalent to $\text{L-uniform AC}^0$, while growing-precision ones achieve $\text{L-uniform TC}^0$ regardless of width. Furthermore, looping enables sequential processing analogous to circuits: $\log^d N$-looped constant-precision transformers reach $\text{FO-uniform AC}^d$, and growing-precision ones reach $\text{FO-uniform TC}^d$. Interestingly, growing width or precision beyond logarithmic does not increase expressivity, and all our results hold for both softmax and average hard attention transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that polynomially padded L-uniform constant-precision transformers are equivalent to L-uniform AC^0, while growing-precision versions are equivalent to L-uniform TC^0 independent of width. It further establishes that log^d N-looped constant-precision transformers reach FO-uniform AC^d and growing-precision ones reach FO-uniform TC^d. These equivalences are asserted to hold for both softmax and average hard attention, with numeric precision and depth as the primary factors affecting expressivity rather than width or attention type. Padding is positioned as a gadget supplying polynomial space for adaptive parallel computation.
Significance. If the equivalences and uniformity preservations hold, the work provides exact characterizations of padded transformer expressivity that are robust to attention type and width, clarifying the theoretical connections to circuit classes. This strengthens prior results by isolating precision and depth as the decisive parameters and demonstrates the utility of the padding construction for adaptive computation under standard uniformity notions.
major comments (2)
- [Proofs of the main equivalences (likely §4-5)] The bidirectional simulations between padded transformers and the claimed circuit classes must explicitly preserve L-uniformity (and FO-uniformity for the looped case). Any dependence on the encoding or positioning of filler symbols in the attention definitions could introduce non-uniform advice, undermining the uniformity statements in the main theorems.
- [Definitions of precision and the TC^0 simulation] The distinction between constant and growing numeric precision is load-bearing for separating AC^0 from TC^0; the manuscript should verify that the growing-precision simulation does not implicitly rely on width or non-constant precision in the constant-precision direction, and vice versa.
minor comments (2)
- [Preliminaries] Clarify the exact definition of 'average hard attention' and how it differs from standard hard attention in the circuit constructions.
- [Section 2] Ensure all uniformity notions (L-uniform, FO-uniform) are defined with explicit reference to the circuit families and transformer parameters.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback on uniformity preservation and the role of precision. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Proofs of the main equivalences (likely §4-5)] The bidirectional simulations between padded transformers and the claimed circuit classes must explicitly preserve L-uniformity (and FO-uniformity for the looped case). Any dependence on the encoding or positioning of filler symbols in the attention definitions could introduce non-uniform advice, undermining the uniformity statements in the main theorems.
Authors: The proofs in §§4–5 construct the simulations using only logspace-computable functions to generate both the circuit descriptions and the transformer parameters from the input length, which directly preserves L-uniformity (and FO-uniformity for the looped case). Polynomial padding length is itself L-uniform, and both softmax and average-hard attention are defined via relative-position comparisons that are computable by logspace machines without reference to any non-uniform encoding of the filler symbols. We will add a short clarifying paragraph after the main simulation theorems to make this uniformity argument explicit. revision: partial
-
Referee: [Definitions of precision and the TC^0 simulation] The distinction between constant and growing numeric precision is load-bearing for separating AC^0 from TC^0; the manuscript should verify that the growing-precision simulation does not implicitly rely on width or non-constant precision in the constant-precision direction, and vice versa.
Authors: Constant precision is defined as a fixed constant number of bits independent of N; growing precision is O(log N) bits. The AC^0 direction uses only the constant-precision model and never invokes threshold gates. The TC^0 direction uses the extra bits solely to realize majority gates and does not rely on super-logarithmic width. We will insert a short verification subsection (or appendix paragraph) that cross-checks both directions against these definitions. revision: yes
Circularity Check
No significant circularity; equivalences grounded in standard circuit definitions
full rationale
The paper derives equivalences between polynomially padded transformers (constant/growing precision, L-uniform/FO-uniform, softmax/hard attention) and circuit classes (AC^0, TC^0, AC^d, TC^d) by formalizing padding as adaptive space and simulating both directions of the correspondence. These steps rely on explicit definitions of uniformity, attention, and looping rather than any self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. No equation or claim reduces to its own input by construction; the results are presented as robust across modeling choices and independent of the authors' prior work for the core uniformity arguments. This is the expected non-finding for a self-contained theoretical equivalence proof.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard definitions of AC^0, TC^0, L-uniform and FO-uniform circuit families
- domain assumption Padded transformers provide polynomial space for adaptive parallel computation
Reference graph
Works this paper leans on
-
[1]
ISSN 2192-5283. doi: 10.4230/DagRep.15. 7.22. URL https://drops.dagstuhl.de/entities/ document/10.4230/DagRep.15.7.22. Bhattamishra, S., Ahuja, K., and Goyal, N. On the Ability and Limitations of Transformers to Recognize Formal Languages. In Webber, B., Cohn, T., He, Y ., and Liu, Y . (eds.),Proceedings of the 2020 Conference on Empiri- cal Methods in Na...
-
[2]
URL https://www.sciencedirect.com/ science/article/pii/S0022000002000259
doi: https://doi.org/10.1016/S0022-0000(02) 00025-9. URL https://www.sciencedirect.com/ science/article/pii/S0022000002000259. Special Issue on Complexity 2001. Immerman, N.Descriptive Complexity. Graduate Texts in Computer Science. Springer, New York,
-
[3]
doi: 10.1007/ 978-1-4612-0539-5
ISBN 978-0-387-98600-5. doi: 10.1007/ 978-1-4612-0539-5. URL https://link.springer. com/book/10.1007/978-1-4612-0539-5. Jerad, S., Svete, A., Li, J., and Cotterell, R. Unique hard attention: A tale of two sides. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.),Proceed- ings of the 63rd Annual Meeting of the Association for Computational Li...
-
[4]
Characterizing the Expressivity of Local Attention in Transformers
doi: 10.18653/v1/2025.acl-short.76. URL https: //aclanthology.org/2025.acl-short.76/. Jerad, S., Svete, A., Hao, S., Cotterell, R., and Merrill, W. Context-free recognition with transformers. In Forty-third International Conference on Machine Learn- ing, 2026. URL https://openreview.net/forum?id= JOyxs9ElI7. Kövér, B., Butoi, A., Svete, A., Hahn, M., and ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.acl-short.76 2025
-
[5]
URL https://jmlr.org/papers/v25/23-0518. html. Weiss, G., Goldberg, Y ., and Yahav, E. On the practi- cal computational power of finite precision RNNs for language recognition. In Gurevych, I. and Miyao, Y . (eds.),Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 740–745, Melbourne, Aust...
-
[6]
Association for Computational Linguistics. doi: 10.18653/v1/P18-2117. URL https://aclanthology. org/P18-2117/. Yang, A., Chiang, D., and Angluin, D. Masked hard- attention transformers recognize exactly the star-free lan- guages. InNeurIPS, 2024. URL https://openreview. net/forum?id=FBMsBdH0yz. Yang, A., Cadilhac, M., and Chiang, D. Knee-deep in c-RASP: A...
-
[7]
Computing the initial hidden states H p0q for the input string w“w 1 ¨ ¨ ¨w N and computing H pl1q using the first l1 layers of the transformer
-
[8]
, l2 Ttimes to the hidden statesH pl1q to obtainH pl1`Tpl 2´l1qq
Applying the transformer layersl 1 `1, . . . , l2 Ttimes to the hidden statesH pl1q to obtainH pl1`Tpl 2´l1qq
-
[9]
, L to the hidden states H pl1`Tpl 2´l1qq to obtain the final representations Hthat are passed to the output layer
Applying the transformer layers l2 `1, . . . , L to the hidden states H pl1`Tpl 2´l1qq to obtain the final representations Hthat are passed to the output layer. The dynamic computational depth of looped transformers lets them perform more complex reasoning tasks by iteratively refining their hidden states across multiple timesteps. Importantly, these reas...
-
[10]
yPR 2D where x
and the form we use in our constructions when convenient. Padded transformers additionally pad the input string with padding (pause) symbols (Pfau et al., 2024; Goyal et al., 2024; 18 Revisiting Padded Transformer Expressivity: Which Architectural Choices Matter and Which Don’t London & Kanade, 2025). The number of padding symbols can depend on the input ...
2024
-
[11]
If it is,wn1 stores e1 and d1 def “w n1e1 in designated parts of its residual stream
At timestep t“1 (the first application of the looped block), each symbol wn1 P t0,1u checks if it is immediately preceded by the & symbol, which denotes the beginning of the pointer in the string. If it is,wn1 stores e1 and d1 def “w n1e1 in designated parts of its residual stream. Here,e 1 is the first unit vector ofR rlogNs
-
[12]
B ˘pn‚q
At each subsequent timestep tP t2, . . . ,rlogNsu (i.e., the t-th application of the same single-layer block), each symbol wn1 checks if the entry et´1 has already been written to the designated space of the previous symbol’s residual stream. If it has, wn1 copies and shifts et´1 into et, and stores et and dt def “d t´1 `w n1et in designated parts of its ...
2025
-
[13]
Let AP t0,1u NˆN be G’s adjacency matrix
We again only highlight the differences in the construction. Let AP t0,1u NˆN be G’s adjacency matrix. The input to the transformer is a string over the alphabet Σ def “ t0,1,˝,&u , where ˝ is the padding symbol and & is a dedicatedseparatorsymbol used to delimit the binary encodings of the source and target nodes; the adjacency matrix A occupies N 2 posi...
-
[14]
Both retrievals are facilitated by binary PEs: Head 1 attends with query B˘pi¨N`kq and head 2 with query B˘pk¨N`jq , both against keys B˘pi1 ¨N`j 1q at input position pi1, j1q
Computing Cℓ in the padding positions.A padding position with coordinates pi, k, jq uses two attention heads to retrieve Bℓ´1pi, kq from the input position pi, kq and Bℓ´1pk, jq from the input position pk, jq. Both retrievals are facilitated by binary PEs: Head 1 attends with query B˘pi¨N`kq and head 2 with query B˘pk¨N`jq , both against keys B˘pi1 ¨N`j 1...
-
[15]
We compute this disjunction by detection (Lem
Computing Bℓ in the input positions.An input position with coordinates pi, jq accepts as Bℓpi, jq iff there exists k with Cℓpi, k, jq “1 , i.e., Bℓpi, jq “ ŽN k“1 Cℓpi, k, jq. We compute this disjunction by detection (Lem. B.6): One attention head at the input position pi, jq attends over the N padding positions pi, k, jq for kP rNs (selected via the PE b...
-
[16]
First, graph connectivity is known to beNL-complete underFOreductions (Immerman, 1999)
1999
-
[17]
C.1 shows that log-depth transformers with cubic padding can recognize the graph connectivity problem L, i.e.,LPL-uniformLPT 1 c,l
Second, Thm. C.1 shows that log-depth transformers with cubic padding can recognize the graph connectivity problem L, i.e.,LPL-uniformLPT 1 c,l
-
[18]
4.1 gives L-uniformLPT 0 c,l “L-uniformAC 0
Finally, Thm. 4.1 gives L-uniformLPT 0 c,l “L-uniformAC 0. Since L-uniformAC 0 ĚFO-uniformAC 0 “FO (Mix Barrington et al., 1990),L-uniformLPT 0 c,l can recognize languages inFOand can therefore computeFOreductions. ■ C.3.1. CIRCUITEVALUATION We now introduce the circuit evaluation problem and show its completeness under L reductions. This section adapts M...
1990
-
[19]
This stage requiresOplogNqlayers
Stage 1, implemented by T read N : Converting the input w˝xCy into internal representations that will allow the transformer to process it. This stage requiresOplogNqlayers
-
[20]
This stage requiresLlayers
Stage 2, implemented byT step N unrolled L times: Iteratively applying the circuit operations to the internal representations to compute the final output. This stage requiresLlayers. Stage 1 converts the binary encodings of the argument pointers stored in the input string xCy into binary encodings stored in the residual stream as per the L-uniform constru...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.