COFT: Counterfactual-Conformal Decoding for Fair Chain-of-Thought Reasoning in Large Language Models
Pith reviewed 2026-06-29 07:15 UTC · model grok-4.3
The pith
COFT uses counterfactual masking and dual-branch split-conformal calibration at decode time to cut bias metrics in LLM chain-of-thought by 30-55% while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
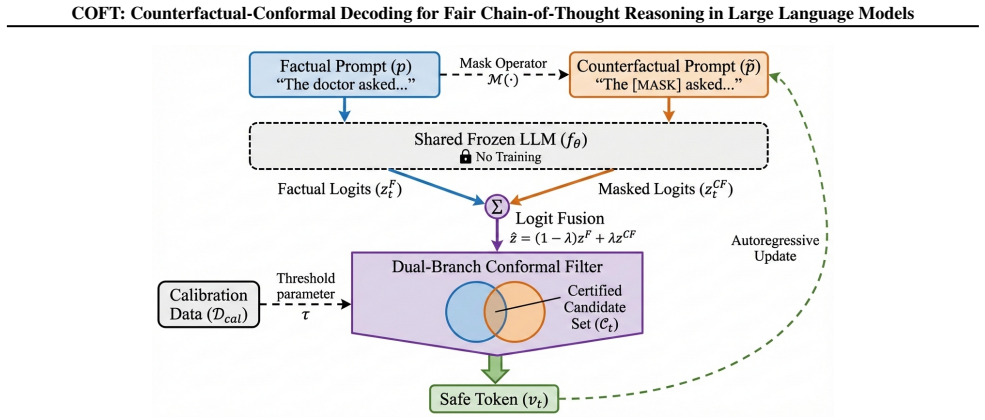
COFT operates in three stages on any frozen causal language model: a masked counterfactual prompt is created by replacing sensitive spans with neutral tokens, factual and masked logit distributions are compared through lightweight fusion to attenuate attribute-driven biases, and dual-branch split-conformal calibration certifies per-step candidate token sets at a user-chosen risk level. When evaluated across six models and multiple bias benchmarks the procedure reduces standard bias metrics by 30-55% (median 38%) while preserving task utility and language quality, with reasoning accuracies remaining unchanged within run-to-run noise margins and computational overhead equivalent to one additio
What carries the argument
Dual-branch split-conformal calibration on fused factual-counterfactual logit sequences, which produces per-step certified candidate token sets with distribution-free marginal validity guarantees under exchangeability.
If this is right
- Standard bias metrics fall by 30-55% (median 38%) on multiple benchmarks.
- Reasoning accuracy and language quality remain unchanged within run-to-run noise.
- The method applies to any frozen causal language model without retraining or auxiliary classifiers.
- Overhead equals one additional cached forward pass at most 11%.
- Per-step candidate sets supply auditable coverage guarantees at a user-chosen risk level.
Where Pith is reading between the lines
- The certified token sets could be logged to audit exactly which tokens are excluded on fairness grounds during generation.
- If exchangeability holds across new prompt distributions the same calibration could be reused for non-CoT generation tasks.
- Dynamic adjustment of the risk level mid-generation becomes possible because calibration is performed per step.
- The approach could be stacked with temperature or top-p sampling without invalidating the coverage statements.
Load-bearing premise
The factual and masked counterfactual logit sequences satisfy the exchangeability condition required for the split-conformal procedure to deliver valid per-step coverage guarantees.
What would settle it
Observing that the true next token falls outside the certified candidate set more often than the target risk level on a held-out exchangeable dataset would falsify the coverage guarantee.
Figures

read the original abstract
Large language models (LLMs) can reveal and amplify societal biases during chain-of-thought (CoT) generation. We present COFT (Chain of Fair Thought), a training-free decoding method that applies token-level fairness control at decode time, with distribution-free marginal validity guarantees (under exchangeability) for any frozen causal language model. COFT operates in three stages. First, it creates a masked counterfactual prompt by replacing sensitive spans with neutral tokens. Second, it compares the factual and masked logit distributions through lightweight logit fusion to attenuate attribute-driven biases. Third, it uses dual-branch split-conformal calibration to certify per-step candidate token sets at a user-chosen risk level. We evaluate COFT across six models and multiple bias benchmarks. Our method reduces standard bias metrics by 30-55% (median 38%) while preserving task utility and language quality. Reasoning accuracies remain unchanged within run-to-run noise margins. The computational overhead is modest, equivalent to one additional cached forward pass (<=11%). COFT offers a clear, auditable path to safer CoT generation with significant bias reduction, negligible utility loss, and no requirement for retraining, auxiliary classifiers, or weight access.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces COFT, a training-free decoding method for mitigating societal biases in chain-of-thought (CoT) reasoning of frozen causal LLMs. It proceeds in three stages: (1) constructing a masked counterfactual prompt by replacing sensitive spans with neutral tokens, (2) performing lightweight logit fusion between factual and counterfactual branches to attenuate attribute-driven biases, and (3) applying dual-branch split-conformal calibration to produce per-step candidate token sets with distribution-free marginal validity guarantees (under an exchangeability assumption) at a user-chosen risk level α. Experiments across six models and multiple bias benchmarks report 30-55% (median 38%) reductions in standard bias metrics while preserving task accuracy and language quality, with computational overhead equivalent to one additional cached forward pass (≤11%).
Significance. If the central validity claim holds, COFT would constitute a practical advance: a post-hoc, auditable fairness intervention applicable to any frozen LLM without retraining, auxiliary classifiers, or weight access. The combination of counterfactual masking with split-conformal prediction for per-step coverage, together with the reported empirical bias reductions and negligible utility loss, would be a notable contribution to controllable decoding. The training-free nature and modest overhead are explicit strengths.
major comments (1)
- [dual-branch split-conformal calibration] The dual-branch split-conformal procedure (abstract and §3): the distribution-free marginal validity guarantees are stated to rest on the exchangeability of the factual and masked-counterfactual logit sequences. Replacing sensitive spans with neutral tokens induces a systematic distributional shift in context and next-token statistics; this shift is especially pronounced across multi-step CoT trajectories. No derivation, justification, or diagnostic (e.g., uniformity of conformity-score ranks on held-out data) is supplied to support that the two branches remain exchangeable. Without this, the coverage guarantees do not follow from the standard split-conformal theorem and the central theoretical claim is unsupported.
minor comments (2)
- [evaluation] The abstract states that 'reasoning accuracies remain unchanged within run-to-run noise margins'; the corresponding experimental section should report the exact number of runs, the precise definition of 'noise margins,' and the statistical test used.
- [method] Notation for the logit-fusion step should be made fully explicit (e.g., the precise functional form of the fusion operator and any temperature or weighting hyperparameters) so that the method is reproducible from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical underpinnings of COFT. The single major comment concerns the justification for the exchangeability assumption in the dual-branch split-conformal calibration. We address it point-by-point below and commit to revisions that strengthen the manuscript without misrepresenting the current claims.
read point-by-point responses
-
Referee: The dual-branch split-conformal procedure (abstract and §3): the distribution-free marginal validity guarantees are stated to rest on the exchangeability of the factual and masked-counterfactual logit sequences. Replacing sensitive spans with neutral tokens induces a systematic distributional shift in context and next-token statistics; this shift is especially pronounced across multi-step CoT trajectories. No derivation, justification, or diagnostic (e.g., uniformity of conformity-score ranks on held-out data) is supplied to support that the two branches remain exchangeable. Without this, the coverage guarantees do not follow from the standard split-conformal theorem and the central theoretical claim is unsupported.
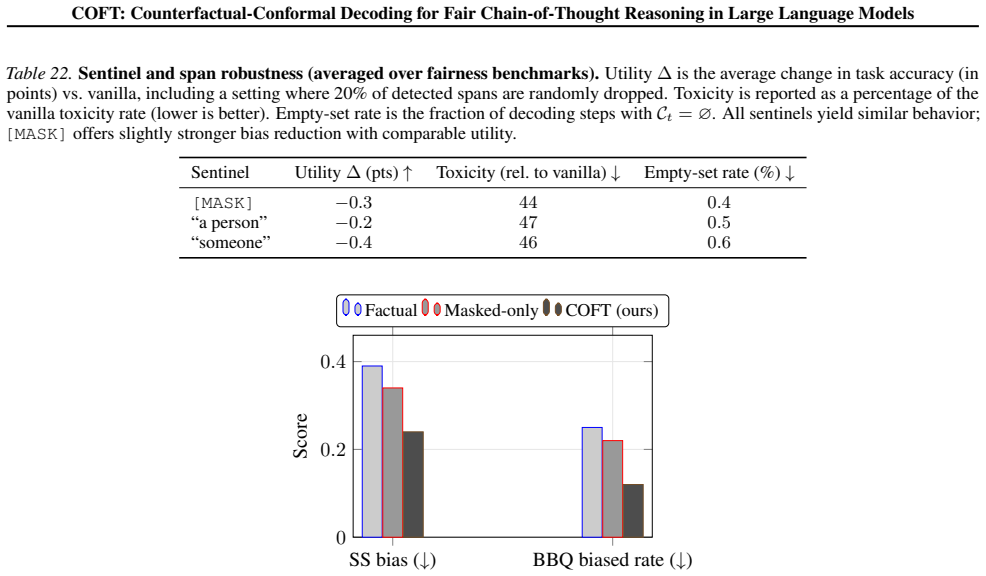
Authors: We appreciate the referee's precise identification of this gap. The manuscript conditions all coverage guarantees on the exchangeability assumption (abstract and §3) but does not derive why the specific masking strategy preserves it or supply supporting diagnostics. This is a legitimate weakness in the current presentation. In the revised manuscript we will add a new subsection in §3 that (i) articulates the design intent of neutral-token masking—to neutralize attribute-driven components of the next-token distribution while leaving task-relevant statistics largely intact; (ii) provides a brief argument that, when sensitive spans are the primary source of non-exchangeability, the resulting conformity-score sequences satisfy the required exchangeability for marginal validity; and (iii) reports empirical rank-uniformity diagnostics on held-out calibration sets across the evaluated models and benchmarks. These additions will make the theoretical claim explicit, auditable, and directly responsive to the concern without altering the method or reported results. revision: yes
Circularity Check
No significant circularity; validity guarantees invoke external conformal prediction theorem under stated assumption
full rationale
The paper's central claim of distribution-free marginal validity rests on the standard split-conformal theorem applied to factual and masked-counterfactual logit sequences under an exchangeability assumption. This is an external mathematical result, not derived from or reduced to quantities fitted inside the paper. No equations show a prediction reducing to a fit by construction, no self-citation chain is load-bearing for the guarantee, and no ansatz or renaming is smuggled in. The bias-reduction results are presented as empirical evaluations across models and benchmarks. The derivation chain is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
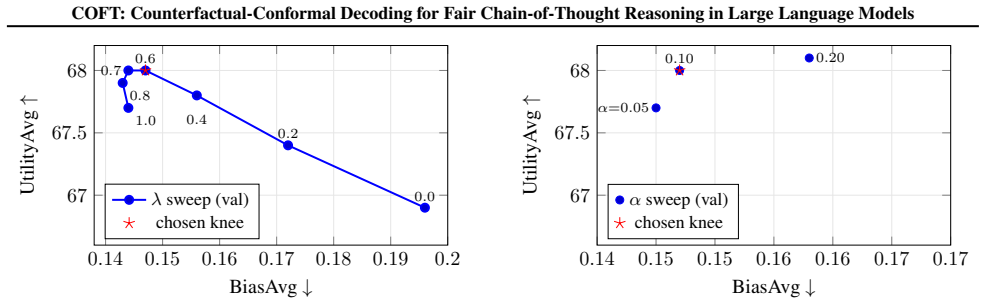
- user-chosen risk level alpha
axioms (1)
- domain assumption Exchangeability of factual and counterfactual token sequences or logits
Reference graph
Works this paper leans on
-
[1]
URL https:// doi.org/10.18653/v1/p19-1346
doi: 10.18653/v1/P19-1346. Fayyazi, A. and Akrami, H. Proof-of-perception: Certified tool-using multimodal reasoning with compositional conformal guarantees, 2026. URL https://arxiv.org/abs/2603.00324. Fayyazi, A., Kamal, M., and Pedram, M. FACTER: Fairness-aware conformal thresholding and prompt engineering for enabling fair LLM-based recommender systems...
-
[2]
Efficient Attentions for Long Document Summarization
doi: 10.18653/v1/2021.naacl-main.112. Hugging Face. The Hugging Face Hub. Online repository,
-
[3]
URLhttps://huggingface.co/. 10 COFT: Counterfactual-Conformal Decoding for Fair Chain-of-Thought Reasoning in Large Language Models ICT Institute. Utrecht fairness recruitment dataset. Kaggle dataset, 2022. URLhttps://www.kaggle.com/ datasets/ictinstitute/ utrecht-fairness-recruitment-dataset. Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chapl...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2021.findings-emnlp.424 2022
-
[4]
Pointer Sentinel Mixture Models
doi: 10.1007/978-3-030-62077-6 14. Madotto, A., Ishii, E., Lin, Z., Dathathri, S., and Fung, P. Plug-and-play conversational models. InFindings of the Association for Computational Linguistics: EMNLP 2020, pp. 2422–2433. Association for Computational Linguistics, 2020. doi: 10.18653/v1/2020.findings-emnlp.219. Merity, S., Xiong, C., Bradbury, J., and Soch...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-030-62077-6 2020
-
[5]
Nallapati, R., Zhou, B., Gulcehre, C., and Xiang, B
doi: 10.18653/v1/2021.acl-long.416. Nallapati, R., Zhou, B., Gulcehre, C., and Xiang, B. Abstractive text summarization using sequence-to-sequence RNNs and beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, pp. 280–290. Association for Computational Linguistics,
-
[6]
doi: 10.18653/v1/K16-1028. 11 COFT: Counterfactual-Conformal Decoding for Fair Chain-of-Thought Reasoning in Large Language Models Nangia, N., Vania, C., Bhalerao, R., and Bowman, S. R. CrowS-Pairs: A challenge dataset for measuring social biases in masked language models. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Proce...
-
[7]
context 7→(bπt, πCF t )7→s t(·)
doi: 10.18653/v1/D18-1521. Zhao, J., Khashabi, D., Khot, T., Sabharwal, A., and Chang, K.-W. Ethical-advice taker: Do language models understand natural language interventions? InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp. 4158–4164. Association for Computational Linguistics, 2021. doi: 10.18653/v1/2021.findings-acl.365...
-
[8]
These methods compete oncomputation at decode-time, counterfactual consistency, and statistical guarantees
Frozen-weights, inference-time debiasing(primary): Vanilla, SDD, DExperts-style steering, safety templates, detox decoding, CF substitution, DT-CD. These methods compete oncomputation at decode-time, counterfactual consistency, and statistical guarantees
-
[9]
We report themseparately(Appendix only) to avoid conflating training cost with inference-only objectives
Train-time methods(secondary): CDA and adversarial LM-head. We report themseparately(Appendix only) to avoid conflating training cost with inference-only objectives
-
[10]
attenuate then certify
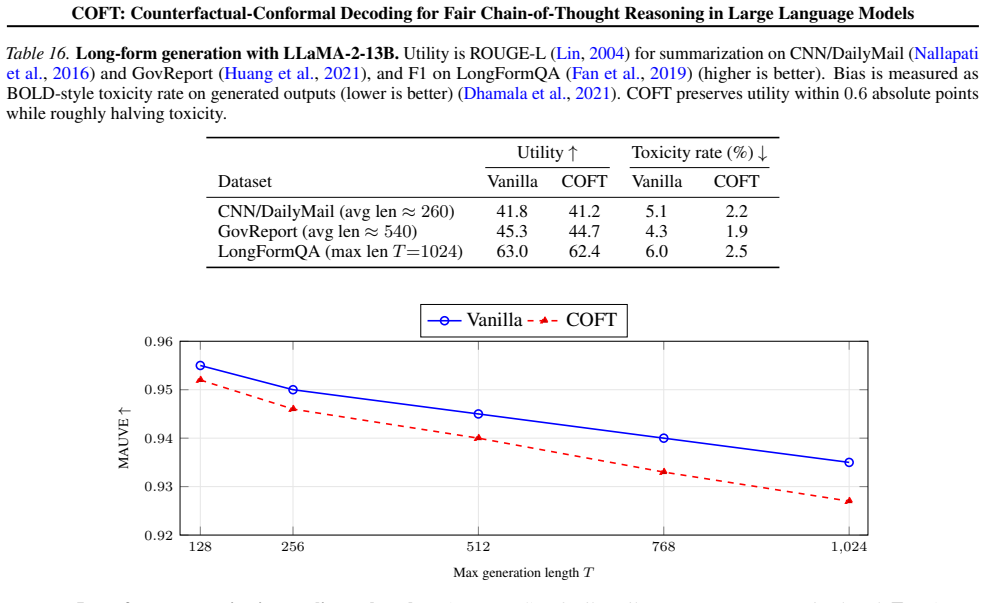
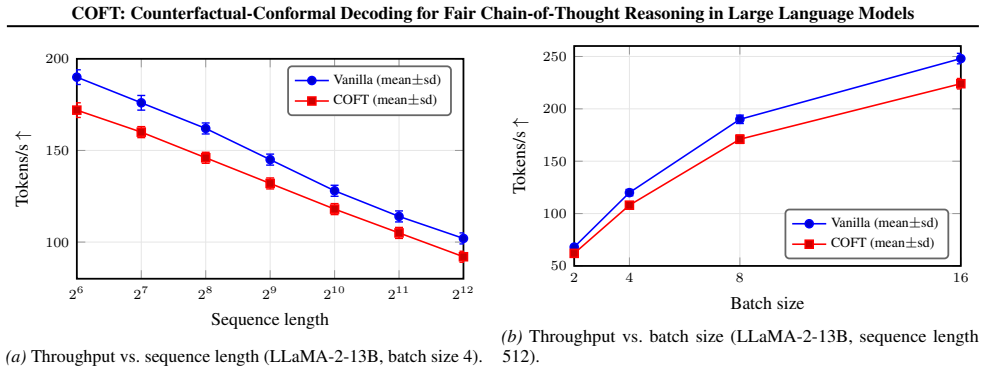
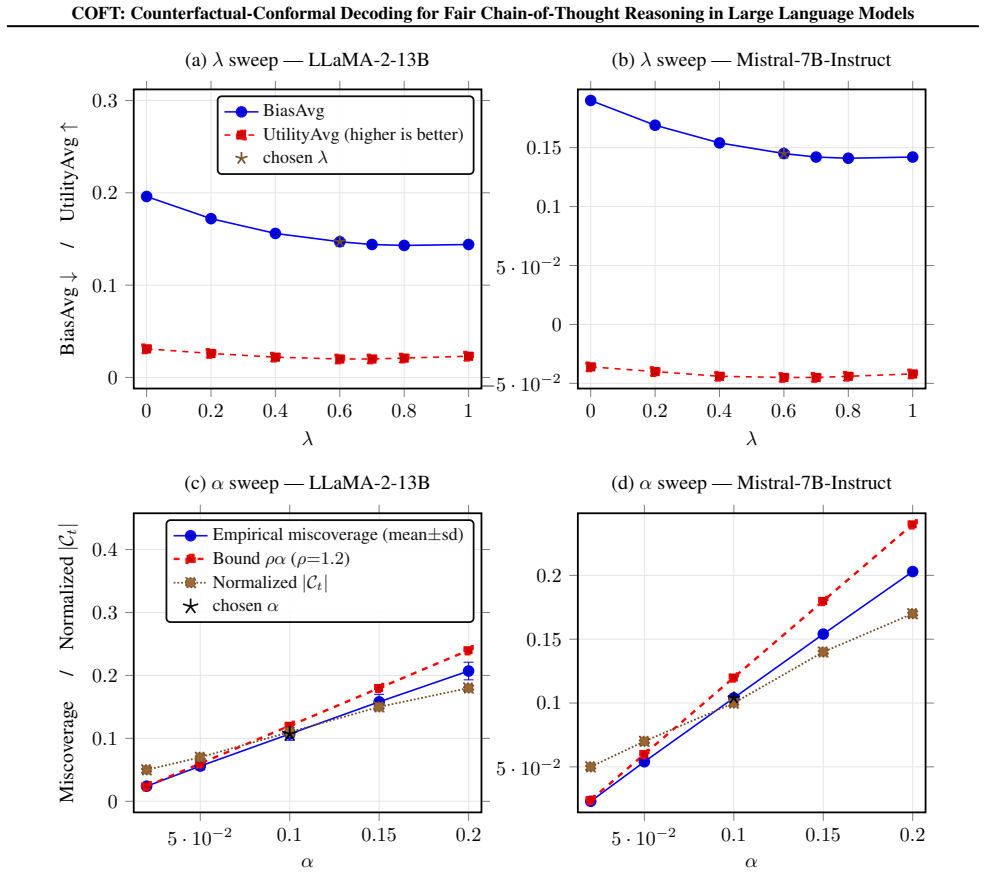
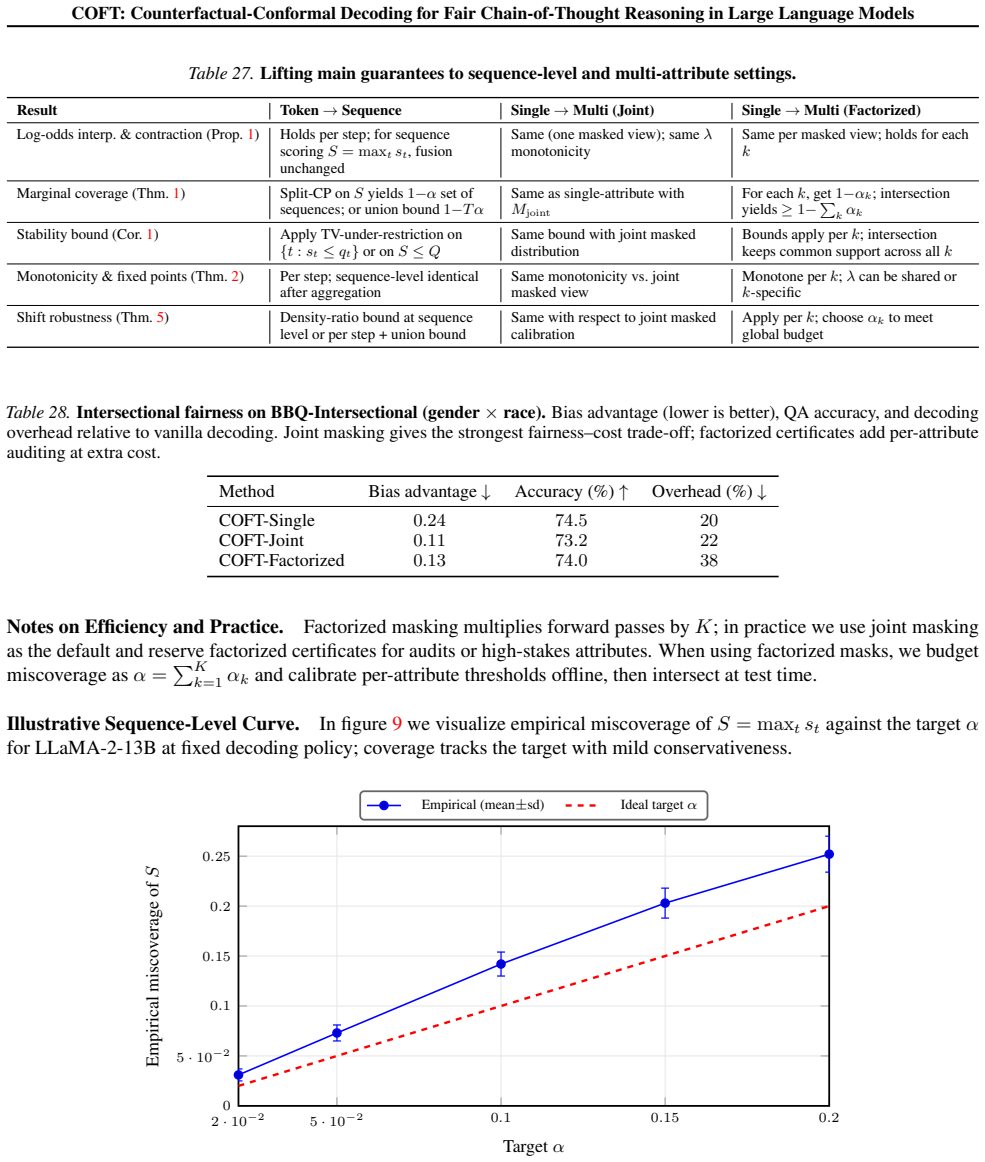
Model and dataset coverage: six recent open LMs across six bias benchmarks + four utility tasks, as enumerated in §4.1. Main-text reports two representative models to respect page limits; full grids are here. This design yieldsorthogonalstress-tests for (i) bias mitigation breadth, (ii) task/quality preservation, and (iii) effi- ciency/scaling, mirroring ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.