Same Patient, Different Words, Different Diagnosis? Evaluating Semantic Stability in Clinical LLMs
Pith reviewed 2026-06-29 07:12 UTC · model grok-4.3
The pith
Domain specialization does not consistently improve clinical LLMs' robustness to meaning-preserving prompt changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
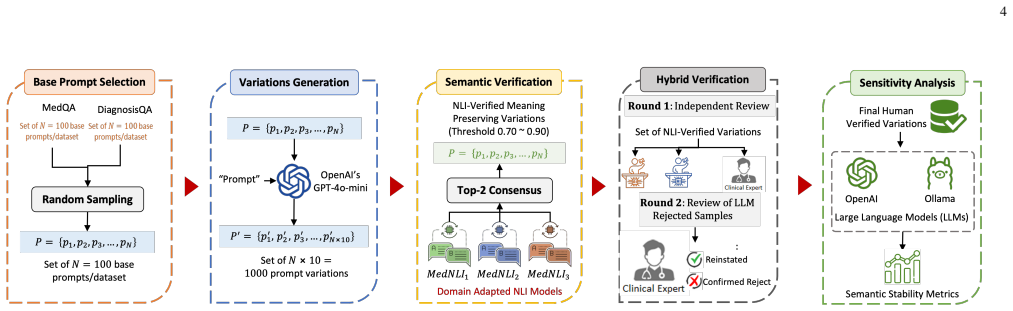
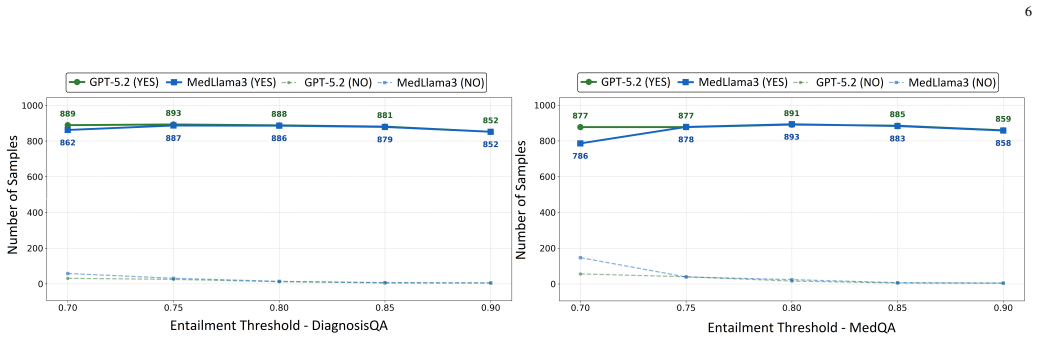
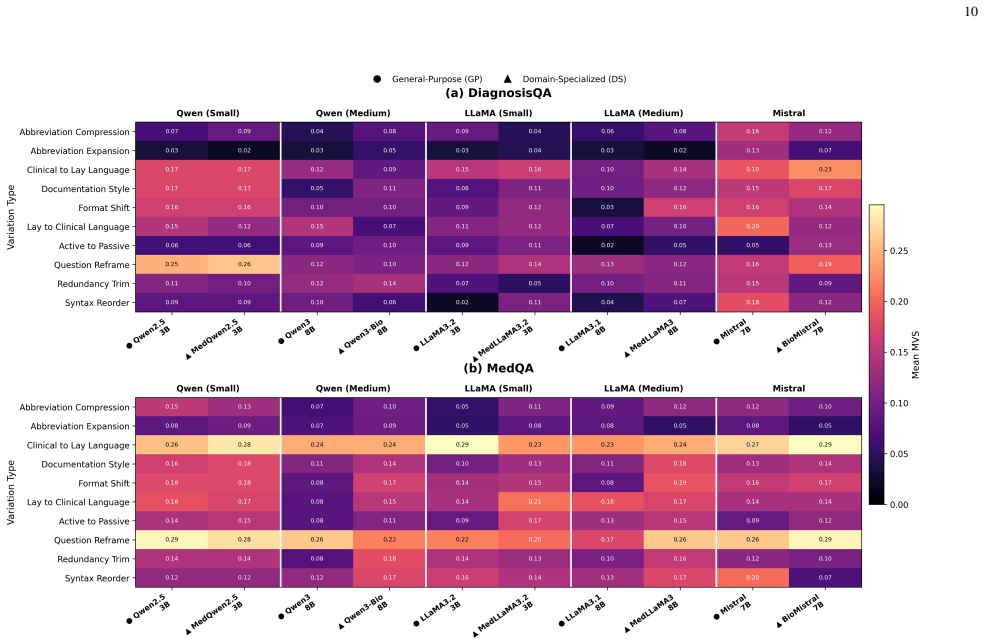
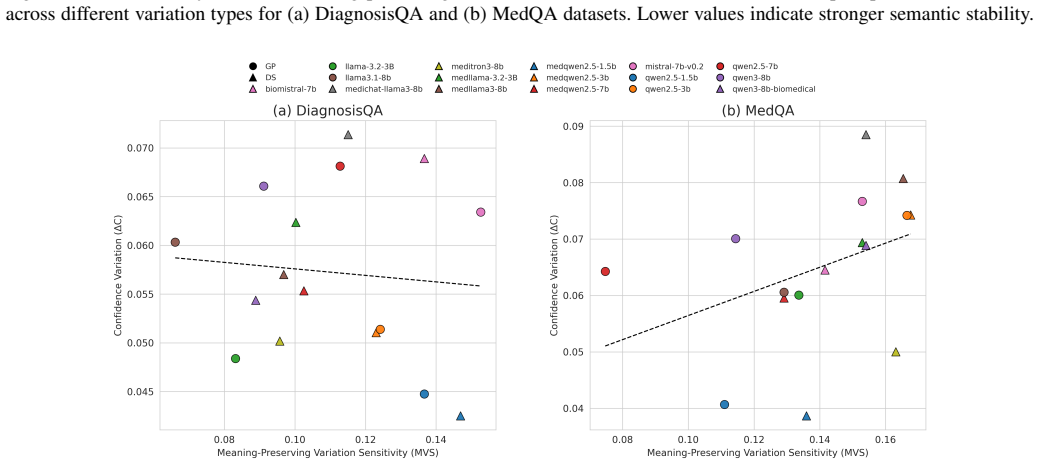
Using a semantic verification framework based on Natural Language Inference, refined by LLM-as-a-judge and clinical expert audit, the authors evaluate 16 open-source general-purpose and medical LLMs on reformulated prompts from DiagnosisQA and MedQA. They find that robustness differences between domain-specific models are mixed and highly model-dependent, meaning domain specialization does not consistently improve or reduce robustness to meaning-preserving prompt reformulations. Several domain-specific models rank among the most robust compared to their general-purpose counterparts, while strong general baselines remain competitive.
What carries the argument
NLI-based semantic verification framework that filters meaning-preserving prompt variations, combined with metrics MeaningPreserving Variation Sensitivity (MVS), confidence variation (ΔC), and Worst-Case Instability (WCI).
If this is right
- Domain specialization in medical LLMs does not guarantee greater stability to rephrased inputs.
- General-purpose LLMs can compete with or exceed domain-specific ones in semantic robustness.
- Meaning-preserving variations must be carefully verified to avoid missing distinctions like negation or severity.
- Model selection for clinical use should include robustness testing beyond accuracy.
Where Pith is reading between the lines
- The findings imply that factors beyond domain labels, such as specific training data or architecture choices, drive robustness.
- Applying the verification framework to other domains like legal or financial LLMs could reveal similar patterns.
- Real-world deployment might require ongoing monitoring of prompt sensitivity in live clinical settings.
Load-bearing premise
The NLI-based semantic verification framework, refined by an LLM-as-a-judge and audited by a clinical expert, correctly identifies meaning-preserving prompt variations without missing clinically important distinctions such as negation, temporality, or severity.
What would settle it
A clinical expert review finding that two prompts labeled as meaning-preserving by the framework actually differ in a key clinical detail like negation or severity, causing the model to change its diagnosis.
Figures
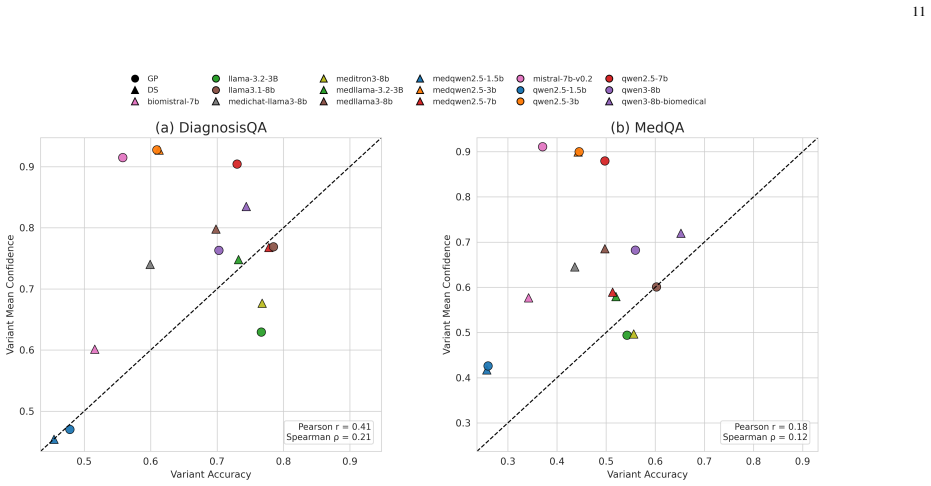
read the original abstract
Large Language Models (LLMs) are increasingly used in clinical applications. However, their behavior remains highly sensitive to subtle linguistic variations, such as rephrasing or syntactic variation. This sensitivity poses risks in safety-critical healthcare settings, where semantically equivalent inputs should produce consistent predictions. However, a key challenge is to ensure that prompt variations truly preserve clinical meaning, as embedding-based similarity metrics often fail to capture distinctions involving negation, temporality, or severity. To address this limitation, we propose a semantic verification framework based on Natural Language Inference (NLI) to filter meaning-preserving prompt variations, which are further refined using an LLM-as-a-judge and audited by a clinical expert. In addition, we introduce three metrics to quantify model sensitivity: MeaningPreserving Variation Sensitivity (MVS), confidence variation (\Delta C), and Worst-Case Instability (WCI). We evaluate 16 open-source general-purpose (GP) and medical LLMs within the same model families and parameter scales, using reformulated prompts derived from the DiagnosisQA and MedQA datasets. Our results demonstrate that robustness differences between domain-specific (DS) models are mixed and highly model-dependent, i.e., domain specialization does not consistently improve or reduce robustness to meaning-preserving prompt reformulations. Several DS models rank among the most robust (when compared with GP counterparts), and strong GP baselines remain competitive as well.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a semantic verification framework that combines NLI filtering, an LLM-as-a-judge, and single-expert clinical audit to retain meaning-preserving prompt reformulations from DiagnosisQA and MedQA. It defines three sensitivity metrics (MVS, ΔC, WCI) and evaluates 16 open-source general-purpose and domain-specific LLMs from matched families and scales, reporting that robustness differences are mixed and model-dependent, so that domain specialization does not consistently improve or reduce stability to semantically equivalent rephrasings.
Significance. If the retained pairs are verifiably meaning-preserving at the level of clinical inference, the mixed DS/GP pattern would indicate that medical fine-tuning alone does not reliably mitigate prompt-sensitivity risks in safety-critical settings. The use of public datasets, same-family controls, and standard NLI tools supports reproducibility and allows direct comparison of specialization effects.
major comments (1)
- [Methods (semantic verification framework)] Methods (semantic verification framework): the NLI + LLM-judge + expert-audit pipeline is described but supplies no quantitative validation—no inter-rater agreement on the expert audit, no error analysis or false-positive rates on held-out negation/temporality/severity cases, and no reported performance of the NLI+LLM filter on clinical text. Because the central claim rests on the retained pairs being clinically equivalent, the absence of these checks leaves open the possibility that observed robustness differences are artifacts of inconsistent labels rather than model behavior.
minor comments (2)
- [Abstract] Abstract: reports the high-level conclusion and method but contains no numerical results, key statistics, or dataset sizes, making it difficult for readers to gauge effect magnitude without reading the full text.
- [Results] Results section: when presenting the mixed DS/GP ranking, include a table that explicitly pairs each DS model with its GP counterpart (same family and scale) so that the model-dependent claim can be inspected at a glance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and will make revisions to strengthen the validation of the semantic verification framework.
read point-by-point responses
-
Referee: Methods (semantic verification framework): the NLI + LLM-judge + expert-audit pipeline is described but supplies no quantitative validation—no inter-rater agreement on the expert audit, no error analysis or false-positive rates on held-out negation/temporality/severity cases, and no reported performance of the NLI+LLM filter on clinical text. Because the central claim rests on the retained pairs being clinically equivalent, the absence of these checks leaves open the possibility that observed robustness differences are artifacts of inconsistent labels rather than model behavior.
Authors: We agree that quantitative validation of the NLI + LLM-judge + expert-audit pipeline is necessary to substantiate that retained pairs are clinically equivalent. In the revised manuscript we will add: (1) performance metrics (e.g., accuracy or F1) of the NLI+LLM filter evaluated on a held-out set of clinical examples that explicitly cover negation, temporality, and severity; (2) an error analysis that reports false-positive rates for meaning-preserving classifications; and (3) an expanded description of the single-expert audit protocol together with an explicit discussion of this design choice as a study limitation. These additions will directly address the concern that robustness differences could be artifacts of label inconsistency. revision: yes
Circularity Check
No significant circularity; metrics defined directly from outputs on public data
full rationale
The paper applies standard NLI tools and an LLM judge to public DiagnosisQA/MedQA data to filter prompt pairs, then computes three new metrics (MVS, ΔC, WCI) directly from the resulting model outputs. No parameters are fitted to the target robustness conclusion, no self-citation chain supports the central empirical claim, and the reported mixed DS/GP robustness pattern is an observation rather than a definitional or fitted consequence. The framework is proposed and executed; results remain falsifiable against external clinical validation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embedding-based similarity metrics fail to capture distinctions involving negation, temporality, or severity
- domain assumption NLI models plus LLM-as-judge plus clinical expert can accurately filter meaning-preserving variations
Reference graph
Works this paper leans on
-
[1]
Application of large language models in medicine,
F. Liu, H. Zhou, B. Gu, X. Zou, J. Huang, J. Wu, Y . Li, S. S. Chen, Y . Hua, P. Zhouet al., “Application of large language models in medicine,”Nature Reviews Bioengineering, vol. 3, no. 6, pp. 445–464, 2025
2025
-
[2]
K. Subedi, “The reliability of LLMs for medical diagnosis: An exam- ination of consistency, manipulation, and contextual awareness,”arXiv preprint arXiv:2503.10647, 2025
-
[3]
Large language models encode clinical knowledge,
K. Singhal, S. Azizi, T. Tu, S. S. Mahdavi, J. Wei, H. W. Chung, N. Scales, A. Tanwani, H. Cole-Lewis, S. Pfohlet al., “Large language models encode clinical knowledge,”Nature, vol. 620, no. 7972, pp. 172– 180, 2023
2023
-
[4]
Toward expert- level medical question answering with large language models,
K. Singhal, T. Tu, J. Gottweis, R. Sayres, E. Wulczyn, M. Amin, L. Hou, K. Clark, S. R. Pfohl, H. Cole-Lewiset al., “Toward expert- level medical question answering with large language models,”Nature medicine, vol. 31, no. 3, pp. 943–950, 2025
2025
-
[5]
Llm sensitivity evaluation framework for clinical diagnosis,
C. Yan, X. Fu, Y . Xiong, T. Wang, S. C. Hui, J. Wu, and X. Liu, “Llm sensitivity evaluation framework for clinical diagnosis,” inProceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 3083–3094
2025
-
[6]
Evaluation and mitigation of the limitations of large language models in clinical decision-making,
P. Hager, F. Jungmann, R. Holland, K. Bhagat, I. Hubrecht, M. Knauer, J. Vielhauer, M. Makowski, R. Braren, G. Kaissis, and D. Rueckert, “Evaluation and mitigation of the limitations of large language models in clinical decision-making,”Nature Medicine, vol. 30, no. 9, pp. 2613– 2622, 2024
2024
-
[7]
On the worst prompt performance of large language models,
B. Cao, D. Cai, Z. Zhang, Y . Zou, and W. Lam, “On the worst prompt performance of large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 69 022–69 042, 2024
2024
-
[8]
Semantically equivalent adversarial rules for debugging NLP models,
M. T. Ribeiro, S. Singh, and C. Guestrin, “Semantically equivalent adversarial rules for debugging NLP models,” inProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Melbourne, Australia: Association for Computational Linguistics, 2018, pp. 856–865
2018
-
[9]
Is BERT really robust? a strong baseline for natural language attack on text classification and entailment,
D. Jin, Z. Jin, J. T. Zhou, and P. Szolovits, “Is BERT really robust? a strong baseline for natural language attack on text classification and entailment,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 05, 2020, pp. 8018–8025
2020
-
[10]
Reevaluating adversarial examples in natural language,
J. X. Morris, E. Lifland, J. Lanchantin, Y . Ji, and Y . Qi, “Reevaluating adversarial examples in natural language,” inFindings of the Association for Computational Linguistics Findings of ACL: EMNLP 2020, 2020
2020
-
[11]
Tailor: Generating and perturbing text with semantic controls,
A. Ross, T. Wu, H. Peng, M. E. Peters, and M. Gardner, “Tailor: Generating and perturbing text with semantic controls,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Dublin, Ireland: Association for Computational Linguistics, 2022, pp. 3194–3213. 14
2022
-
[12]
Beyond accuracy: Behavioral testing of NLP models with CheckList,
M. T. Ribeiro, T. Wu, C. Guestrin, and S. Singh, “Beyond accuracy: Behavioral testing of NLP models with CheckList,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: Association for Computational Linguistics, 2020, pp. 4902– 4912
2020
-
[13]
Adaptive testing and debugging of NLP models,
M. T. Ribeiro and S. Lundberg, “Adaptive testing and debugging of NLP models,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Dublin, Ireland: Association for Computational Linguistics, 2022, pp. 3253– 3267
2022
-
[14]
Polyjuice: Generat- ing counterfactuals for explaining, evaluating, and improving models,
T. Wu, M. T. Ribeiro, J. Heer, and D. S. Weld, “Polyjuice: Generat- ing counterfactuals for explaining, evaluating, and improving models,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Online: Association for Comp...
2021
-
[15]
Paws: Paraphrase adversaries from word scrambling,
Y . Zhang, J. Baldridge, and L. He, “Paws: Paraphrase adversaries from word scrambling,” inNAACL HLT 2019 - 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies - Proceedings of the Conference, vol. 1, 2019
2019
-
[16]
Measuring and improving consistency in pretrained language models,
Y . Elazar, N. Kassner, S. Ravfogel, A. Ravichander, E. Hovy, H. Sch¨utze, and Y . Goldberg, “Measuring and improving consistency in pretrained language models,”Transactions of the Association for Computational Linguistics, vol. 9, pp. 1012–1031, 2021
2021
-
[17]
Evaluating paraphrastic robustness in textual entailment models,
D. Verma and A. Poliak, “Evaluating paraphrastic robustness in textual entailment models,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: Student Research Workshop. Online: Association for Computational Linguistics, 2021, pp. 351–358
2021
-
[18]
Paraphrasus: A comprehensive benchmark for evaluating paraphrase detection models,
A. Michail, S. Clematide, and J. Opitz, “Paraphrasus: A comprehensive benchmark for evaluating paraphrase detection models,” inProceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 8749–8762
2025
-
[19]
MENLI: Robust evaluation metrics from natural language inference,
Y . Chen and S. Eger, “MENLI: Robust evaluation metrics from natural language inference,”Transactions of the Association for Computational Linguistics, vol. 11, pp. 804–825, 2023
2023
-
[20]
SummaC: Re-visiting NLI-based models for inconsistency detection in summa- rization,
P. Laban, T. Schnabel, P. N. Bennett, and M. A. Hearst, “SummaC: Re-visiting NLI-based models for inconsistency detection in summa- rization,”Transactions of the Association for Computational Linguistics, vol. 10, pp. 163–177, 2022
2022
-
[21]
Enhancing self-consistency and performance of pre-trained language models through natural language inference,
E. Mitchell, J. Noh, S. Li, W. Armstrong, A. Agarwal, P. Liu, C. Finn, and C. D. Manning, “Enhancing self-consistency and performance of pre-trained language models through natural language inference,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Abu Dhabi, United Arab Emirates: Association for Computational L...
2022
-
[22]
Lessons from natural language inference in the clinical domain,
A. Romanov and C. Shivade, “Lessons from natural language inference in the clinical domain,” inProceedings of the 2018 Conference on Em- pirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics, 2018, pp. 1586–1596
2018
-
[23]
State of what art? a call for multi-prompt LLM eval- uation,
M. Mizrahi, G. Kaplan, D. Malkin, R. Dror, D. Shahaf, and G. Stanovsky, “State of what art? a call for multi-prompt LLM eval- uation,”Transactions of the Association for Computational Linguistics, vol. 12, pp. 933–949, 2024
2024
-
[24]
M. Sclar, Y . Choi, Y . Tsvetkov, and A. Suhr, “Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting,”arXiv preprint arXiv:2310.11324, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts,
K. Zhu, J. Wang, J. Zhou, Z. Wang, H. Chen, Y . Wang, L. Yang, W. Ye, Y . Zhang, N. Gonget al., “Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts,” in Proceedings of the 1st ACM workshop on large AI systems and models with privacy and safety analysis, 2023, pp. 57–68
2023
-
[26]
Limitations of large language models in clinical problem-solving aris- ing from inflexible reasoning,
J. Kim, A. Podlasek, K. Shidara, F. Liu, A. Alaa, and D. Bernardo, “Limitations of large language models in clinical problem-solving aris- ing from inflexible reasoning,”Scientific Reports, vol. 15, 2025
2025
-
[27]
A systematic review of large language model (llm) evaluations in clinical medicine,
S. Shool, S. Adimi, R. Saboori Amleshi, E. Bitaraf, R. Golpira, and M. Tara, “A systematic review of large language model (llm) evaluations in clinical medicine,”BMC Medical Informatics and Decision Making, vol. 25, no. 1, p. 117, 2025
2025
-
[28]
Testing and evaluation of health care applications of large language models: a systematic review,
S. Bedi, Y . Liu, L. Orr-Ewing, D. Dash, S. Koyejo, A. Callahan, J. A. Fries, M. Wornow, A. Swaminathan, L. S. Lehmannet al., “Testing and evaluation of health care applications of large language models: a systematic review,”Jama, vol. 333, no. 4, pp. 319–328, 2025
2025
-
[29]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inEMNLP-IJCNLP 2019 - 2019 Conference on Empirical Methods in Natural Language Processing and 9th Interna- tional Joint Conference on Natural Language Processing, Proceedings of the Conference, 2019
2019
-
[30]
Medsim: A novel seman- tic similarity measure in bio-medical knowledge graphs,
K. Lei, K. Yuan, Q. Zhang, and Y . Shen, “Medsim: A novel seman- tic similarity measure in bio-medical knowledge graphs,” inInterna- tional conference on knowledge science, engineering and management. Springer, 2018, pp. 479–490
2018
-
[31]
Semantics at an angle: When cosine similarity works until it doesn’t,
K. You, “Semantics at an angle: When cosine similarity works until it doesn’t,”arXiv preprint arXiv:2504.16318, 2025
-
[32]
Is cosine-similarity of embed- dings really about similarity?
H. Steck, C. Ekanadham, and N. Kallus, “Is cosine-similarity of embed- dings really about similarity?” inCompanion Proceedings of the ACM Web Conference 2024, 2024, pp. 887–890
2024
-
[33]
Does prompt formatting have any impact on llm performance?
J. He, M. Rungta, D. Koleczek, A. Sekhon, F. X. Wang, and S. Hasan, “Does prompt formatting have any impact on llm performance?”arXiv preprint arXiv:2411.10541, 2024
-
[34]
This Treatment Works, Right? Evaluating LLM Sensitivity to Patient Question Framing in Medical QA
H. S. Yun, G. Kapoor, M. Mackert, R. Kouzy, W. Xu, J. J. Li, and B. C. Wallace, “This treatment works, right? evaluating llm sensitivity to pa- tient question framing in medical qa,”arXiv preprint arXiv:2604.05051, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
What did i do wrong? quantifying llms’ sensitivity and consistency to prompt engineering,
F. Errica, D. Sanvito, G. Siracusano, and R. Bifulco, “What did i do wrong? quantifying llms’ sensitivity and consistency to prompt engineering,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 1543–1558
2025
-
[36]
Prosa: Assessing and understanding the prompt sensitivity of llms,
J. Zhuo, S. Zhang, X. Fang, H. Duan, D. Lin, and K. Chen, “Prosa: Assessing and understanding the prompt sensitivity of llms,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 1950–1976
2024
-
[37]
Promptception: How sensitive are large multimodal models to prompts?
M. I. Ismithdeen, M. U. Khattak, and S. Khan, “Promptception: How sensitive are large multimodal models to prompts?”arXiv preprint arXiv:2509.03986, 2025
-
[38]
Evaluating the zero-shot robustness of instruction-tuned language models,
J. Sun, C. Shaib, and B. C. Wallace, “Evaluating the zero-shot robustness of instruction-tuned language models,”arXiv preprint arXiv:2306.11270, 2023
-
[39]
S. S. Balamurali and L. Cheng, “Revisiting nli: Towards cost-effective and human-aligned metrics for evaluating llms in question answering,” arXiv preprint arXiv:2511.07659, 2025
-
[40]
Improving paraphrase detection with the adversarial paraphrasing task,
A. Nighojkar and J. Licato, “Improving paraphrase detection with the adversarial paraphrasing task,” inACL-IJCNLP 2021 - 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Proceedings of the Conference, vol. 1, 2021
2021
-
[41]
Improving medical nli using context-aware domain knowledge,
S. Chowdhury, S. Y . Philip, and Y . Luo, “Improving medical nli using context-aware domain knowledge,” inProceedings of the Ninth Joint Conference on Lexical and Computational Semantics, 2020, pp. 1–11
2020
-
[42]
A comprehensive survey on the trustworthiness of large language models in healthcare,
M. Aljohani, J. Hou, S. Kommu, and X. Wang, “A comprehensive survey on the trustworthiness of large language models in healthcare,”arXiv preprint arXiv:2502.15871, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.