Reinforcement Learning for Special Education: Aligning LLM Tutors to Diverse Learners through Disability-Adaptive Training
Pith reviewed 2026-06-28 20:57 UTC · model grok-4.3
The pith
A reinforcement learning framework adapts LLM tutors to five disability profiles using paired prompts and persona-conditioned rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Special-R1 extends pedagogical reinforcement learning through a two-dimensional adaptive system prompt that couples a difficulty-based support level with a disability-specific teaching style across five disability profiles, together with a persona-aware Thinking Reward whose judge rubric is conditioned on the learner's disability profile. On a persona-augmented test set of 690 multi-turn dialogues the full model raises persona-aware Fit from 6.75 to 8.40 and SPED-rubric Helpfulness from 0.720 to 0.768, leads the four-component Total at 2.911, and stays within 0.01 of the strongest variant on the out-of-domain OpenLearnLM benchmark at 8.53.
What carries the argument
The two-dimensional adaptive system prompt paired with the persona-aware Thinking Reward inside the reinforcement learning training loop.
If this is right
- The full model leads the four-component Total score at 2.911 on the persona-augmented test set.
- The Thinking Reward produces gains only when used together with the adaptive prompting.
- Performance on the out-of-domain OpenLearnLM benchmark remains within 0.01 of the strongest variant.
- Residual weakness on specific learning disability in mathematics suggests targeted multimodal extensions.
Where Pith is reading between the lines
- The same profile-conditioned reward structure could be reused to personalize tutors for other axes of learner variation such as age or prior knowledge.
- The noted gap for mathematics learning disabilities indicates that adding diagram or tool-use capabilities would be a direct next step.
- Replacing hand-crafted personas with data-driven profile inference from short learner interactions could reduce reliance on simulated dialogues.
Load-bearing premise
The five disability profiles and the persona-augmented dialogues used for both training and evaluation accurately capture the cognitive and communicative diversity of real learners with disabilities.
What would settle it
A controlled study measuring learning gains or engagement in live sessions between the model and actual students matching the five disability profiles would show whether the reported metric gains translate to real outcomes.
Figures
read the original abstract
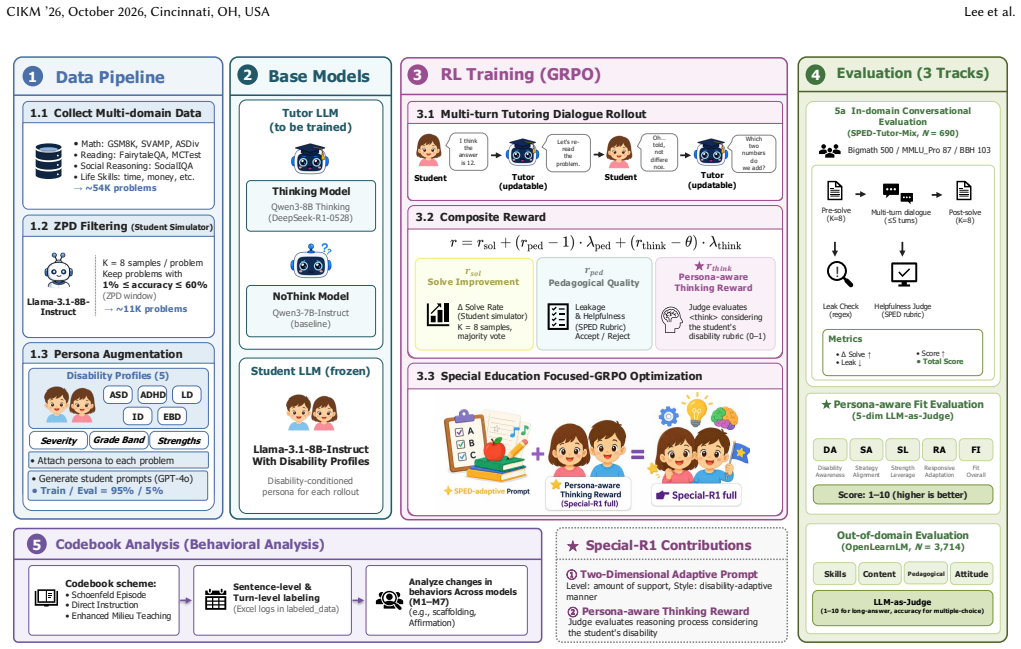
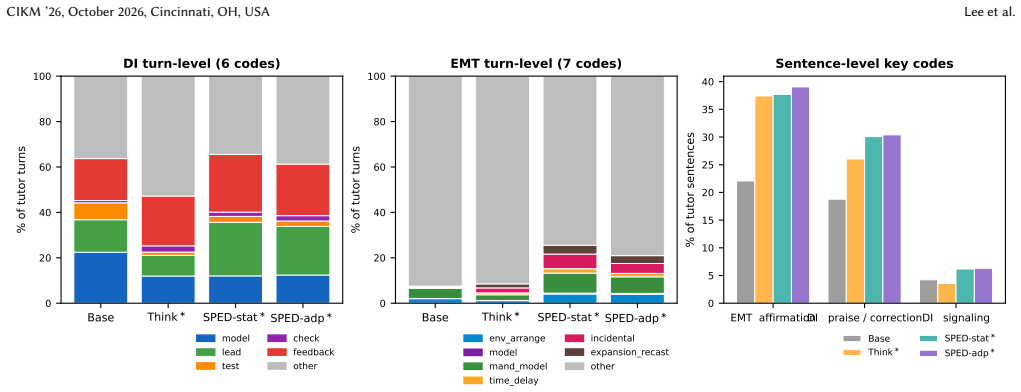
Large language models are increasingly deployed as intelligent tutors, yet research on aligning them for special education remains absent. Recent work has applied reinforcement learning to LLM tutors, but these methods target a generic learner in a single domain (mathematics) and do not address the cognitive and communicative diversity of learners with disabilities. We introduce \emph{Special-R1}, a framework that extends pedagogical RL to special education through two components: (1) a two-dimensional adaptive system prompt that couples a difficulty-based support level with a disability-specific teaching style across five disability profiles; and (2) a persona-aware Thinking Reward whose judge rubric is conditioned on the learner's disability profile. On a persona-augmented test set of 690 multi-turn dialogues, our full model raises persona-aware Fit from 6.75 (generic baseline) to 8.40 (+1.65) and SPED-rubric Helpfulness from 0.720 to 0.768, leading on the four-component Total (2.911, +0.064 over the runner-up) while remaining within 0.01 of the strongest variant on the out-of-domain OpenLearnLM benchmark (8.53). Ablations show that the Thinking Reward becomes effective only in combination with adaptive prompting, and that residual weakness on specific learning disability in mathematics motivates targeted multimodal extensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Special-R1, an RL framework extending pedagogical RL to special education via (1) a two-dimensional adaptive system prompt coupling difficulty-based support with disability-specific teaching styles across five profiles and (2) a persona-aware Thinking Reward with judge rubric conditioned on the learner's disability profile. On a persona-augmented test set of 690 multi-turn dialogues, the full model improves persona-aware Fit from 6.75 to 8.40 and SPED-rubric Helpfulness from 0.720 to 0.768, leads on the four-component Total (2.911), and stays within 0.01 of the top variant on out-of-domain OpenLearnLM (8.53). Ablations indicate the Thinking Reward is effective only with adaptive prompting.
Significance. If the results hold after addressing missing implementation details and validation gaps, the work would address an important gap in aligning LLM tutors to learners with disabilities, extending RL methods beyond generic mathematics domains. The reported out-of-domain stability on OpenLearnLM and the ablation isolating the interaction between reward and prompting are strengths that could support broader adoption in inclusive education tools.
major comments (2)
- [Abstract and methods] Abstract and methods section describing the two components and the test set: the abstract reports numeric gains (Fit +1.65, Helpfulness +0.048, Total +0.064) but supplies no training corpus, no exact reward equation, no description of how the judge rubric is implemented, and no statistical tests. Without these elements the central performance claim cannot be evaluated.
- [Abstract and methods] Test set description (abstract and methods): the persona-augmented test set of 690 dialogues is generated from the same five disability profiles used to construct the adaptive prompts and Thinking Reward. No human-subject validation, inter-rater reliability with SPED experts, or comparison to transcripts from actual learners is reported, making the headline gains dependent on the same profile definitions and raising circularity that the ablation does not resolve.
minor comments (1)
- [Abstract] The four-component Total metric is referenced but its exact weighting and components are not defined in the abstract or test-set paragraph, hindering interpretation of the leading score of 2.911.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback emphasizing the need for explicit implementation details and clearer validation of the evaluation setup. We address each major comment below with clarifications drawn from the manuscript and indicate revisions that will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract and methods] Abstract and methods section describing the two components and the test set: the abstract reports numeric gains (Fit +1.65, Helpfulness +0.048, Total +0.064) but supplies no training corpus, no exact reward equation, no description of how the judge rubric is implemented, and no statistical tests. Without these elements the central performance claim cannot be evaluated.
Authors: We agree that the abstract would benefit from greater explicitness to support independent evaluation of the claims. The full methods section defines the training corpus as persona-augmented dialogues constructed from the five disability profiles, formulates the Thinking Reward as a weighted sum of profile-conditioned fit and helpfulness scores, and specifies the judge rubric as a set of SPED-aligned criteria applied per profile. We will revise both the abstract and methods to include the exact reward equation, a step-by-step description of the rubric implementation, the training corpus composition, and the results of statistical significance tests on the reported deltas. revision: yes
-
Referee: [Abstract and methods] Test set description (abstract and methods): the persona-augmented test set of 690 dialogues is generated from the same five disability profiles used to construct the adaptive prompts and Thinking Reward. No human-subject validation, inter-rater reliability with SPED experts, or comparison to transcripts from actual learners is reported, making the headline gains dependent on the same profile definitions and raising circularity that the ablation does not resolve.
Authors: The test set is deliberately constructed from the same expert-defined profiles to enable controlled, profile-consistent measurement of persona-aware metrics; this is stated in the methods. The ablation results isolate the contribution of the Thinking Reward conditional on adaptive prompting, showing that gains require both components and are not an artifact of profile reuse alone. We nevertheless recognize the absence of human-subject validation, inter-rater reliability with SPED experts, and direct comparison to real learner transcripts as a substantive limitation. We will expand the discussion section to explicitly note this limitation and frame it as an important direction for future work. revision: partial
- Conducting new human-subject validation or inter-rater reliability studies with SPED experts, which would require fresh data collection outside the scope of the present manuscript.
Circularity Check
No significant circularity; results are empirical on synthetic data with external benchmark
full rationale
The paper's core contribution is an empirical RL framework using adaptive prompts and a Thinking Reward conditioned on five disability profiles, with gains measured on a persona-augmented test set of 690 dialogues plus an out-of-domain OpenLearnLM benchmark. No equations, derivations, or self-citations are present that reduce any claimed result to its inputs by construction. The shared use of profiles for prompt/reward design and test-set augmentation is an explicit in-distribution evaluation choice rather than a definitional loop or fitted prediction renamed as output. The out-of-domain benchmark performance (within 0.01 of strongest variant) supplies independent content, satisfying the criterion for a self-contained empirical claim.
Axiom & Free-Parameter Ledger
free parameters (2)
- disability-specific teaching styles
- weights inside the four-component Total metric
axioms (1)
- domain assumption The five disability profiles sufficiently represent the target population of learners with disabilities.
invented entities (1)
-
persona-aware Thinking Reward
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Archer and Charles A
Anita L. Archer and Charles A. Hughes. 2011.Explicit Instruction: Effective and Efficient Teaching. Guilford Press
2011
-
[2]
CAST. 2018. Universal Design for Learning Guidelines version 2.2. https:// udlguidelines.cast.org
2018
-
[3]
Alexis Chevalier, Jiayi Geng, Alexander Wettig, Howard Chen, Sebastian Miz- era, Toni Annala, Max Aragon, Arturo Rodriguez Fanlo, Simon Frieder, Simon Machado, et al. 2024. TutorChat: Synthetic Teacher-Student Dialogues for Tu- toring Models. InProceedings of the 41st International Conference on Machine Learning (ICML). CIKM ’26, October 2026, Cincinnati,...
2024
- [4]
-
[5]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
David Dinucu-Jianu, Jakub Macina, Nico Daheim, Ido Hakimi, Iryna Gurevych, and Mrinmaya Sachan. 2025. From Problem-Solving to Teaching Problem-Solving: Aligning LLMs with Pedagogy using Reinforcement Learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2025
-
[7]
Hancock and Ann P
Terry B. Hancock and Ann P. Kaiser. 2002. The Effects of Enhanced Milieu Teaching with Phonological Emphasis on the Language Development of Young Children with Cleft Palate.Topics in Early Childhood Special Education22, 4 (2002), 211-223
2002
-
[8]
Enkelejda Kasneci et al. 2023. ChatGPT for Good? On Opportunities and Chal- lenges of Large Language Models for Education.Learning and Individual Differ- ences103 (2023), 102274
2023
- [9]
-
[10]
Unggi Lee, Jiyeong Bae, Jaehyeon Park, Haeun Park, Taejun Park, Younghoon Jeon, Sungmin Cho, Junbo Koh, Yeil Jeong, and Gyeonggeon Lee. 2026. Reward- ing How Models Think Pedagogically: Integrating Pedagogical Reasoning and Thinking Rewards for LLMs in Education.arXiv preprint arXiv:2601.14560(2026)
-
[11]
Unggi Lee, Sookbun Lee, Heungsoo Choi, Jinseo Lee, Haeun Park, Younghoon Jeon, Sungmin Cho, Minju Kang, Junbo Koh, Jiyeong Bae, Minwoo Nam, Juyeon Eun, Yeonji Jung, and Yeil Jeong. 2026. OpenLearnLM Benchmark: A Unified Framework for Evaluating Knowledge, Skill, and Attitude in Educational Large Language Models.arXiv preprint arXiv:2601.13882(2026)
-
[12]
Yifei Liu, Yuxin Cao, Peng Li, and Bo Xu. 2024. Aligning LLM Tutors via Socratic Persona. InAdvances in Neural Information Processing Systems, Vol. 37
2024
-
[13]
Jakub Macina, Nico Daheim, Ido Hakimi, Manu Kapur, Iryna Gurevych, and Mrin- maya Sachan. 2025. MathTutorBench: A Benchmark for Measuring Open-ended Pedagogical Capabilities of LLM Tutors. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2025
-
[14]
Stephen MacNeil, Andrew Tran, Dan Mogil, Seth Bernstein, Erik Ross, and Ziheng Huang. 2023. Experiences from Using Code Explanations Generated by Large Language Models in a Web Software Development E-Book.Proceedings of the 54th ACM Technical Symposium on Computer Science Education V.1(2023), 931-937
2023
-
[15]
2017.High-Leverage Practices in Special Education
James McLeskey, Mary-Dean Barringer, Bonnie Billingsley, Mary Brownell, Dia Jackson, Michael Kennedy, Tim Lewis, Larry Maheady, Jackie Rodriguez, Mary Catherine Scheeler, Judy Winn, and Deborah Ziegler. 2017.High-Leverage Practices in Special Education. Council for Exceptional Children and CEEDAR Center
2017
-
[16]
1945.How to Solve It: A New Aspect of Mathematical Method
George Polya. 1945.How to Solve It: A New Aspect of Mathematical Method. Princeton University Press
1945
-
[17]
Schoenfeld
Alan H. Schoenfeld. 1985.Mathematical Problem Solving. Academic Press
1985
-
[18]
Schoenfeld
Alan H. Schoenfeld. 1992. Learning to Think Mathematically: Problem Solving, Metacognition, and Sense Making in Mathematics. InHandbook for Research on Mathematics Teaching and Learning, Douglas A. Grouws (Ed.). Macmillan, 334-370
1992
-
[19]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Snell and Fredda Brown
Martha E. Snell and Fredda Brown. 2011.Instruction of Students with Severe Disabilities(7 ed.). Pearson
2011
-
[21]
Anaïs Tack, Ekaterina Kochmar, Zheng Yuan, Serge Bibauw, and Chris Piech. 2023. The BEA 2023 Shared Task on Generating AI Teacher Responses in Educational Dialogues. InProceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA). 785-795
2023
-
[22]
Anaïs Tack and Chris Piech. 2022. The AI Teacher Test: Measuring the Pedagogical Ability of Blender and GPT-3 in Educational Dialogues. InProceedings of the International Conference on Artificial Intelligence in Education
2022
-
[23]
Vygotsky
Lev S. Vygotsky. 1978.Mind in Society: The Development of Higher Psychological Processes. Harvard University Press
1978
-
[24]
Bruner, and Gail Ross
David Wood, Jerome S. Bruner, and Gail Ross. 1976. The Role of Tutoring in Problem Solving.Journal of Child Psychology and Psychiatry17, 2 (1976), 89-100
1976
-
[25]
An Yang, Baosong Yang, Binyuan Hui, et al. 2024. Qwen2.5 Technical Report. arXiv preprint arXiv:2412.15115(2024). Jihoi Na2, Yeil Jeong3, Haeun Park4, Yeonju Jang5„
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.