XLGoBench: Detecting cross-lingual skill gaps with algorithmic tasks
Pith reviewed 2026-06-28 23:10 UTC · model grok-4.3
The pith
Synthetic algorithmic tasks reveal persistent cross-lingual gaps in state-of-the-art language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
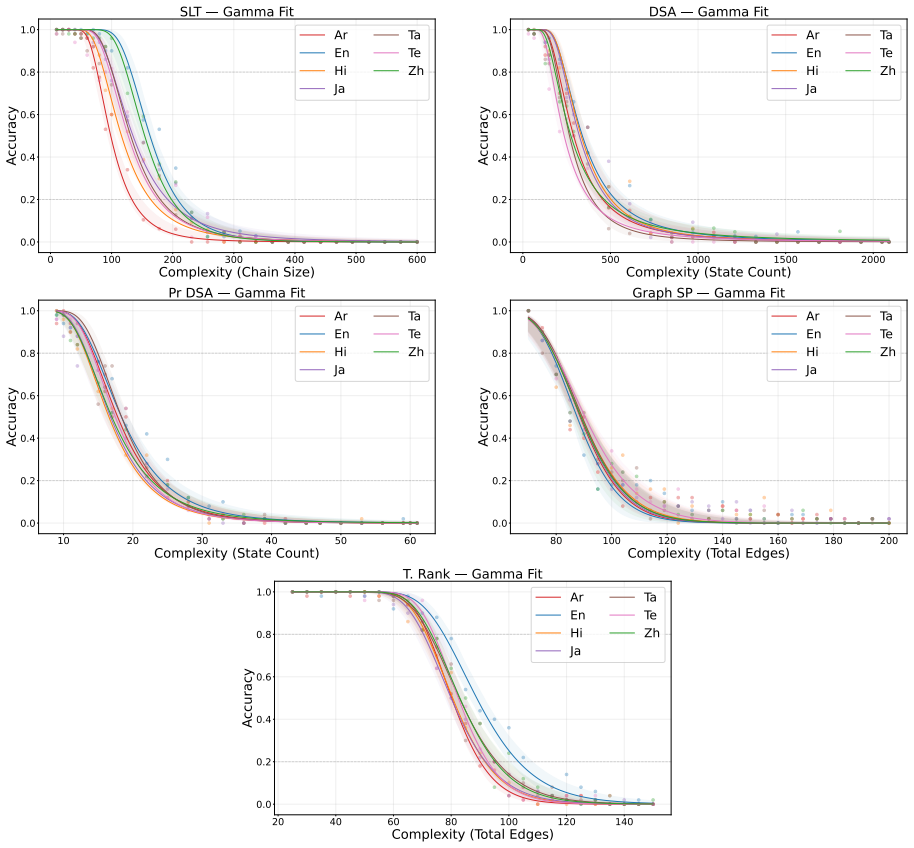
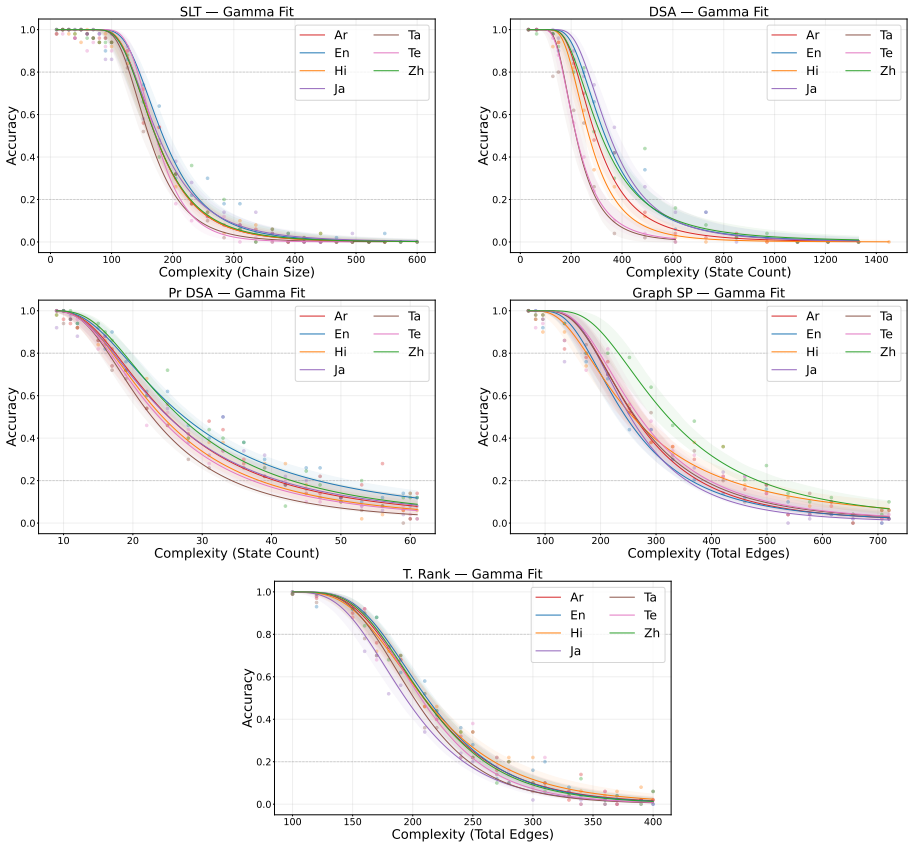
A benchmark consisting of algorithmic tasks generated from simple templates demonstrates that state-of-the-art large language models exhibit persistent performance differences when the same underlying task is presented in different languages.
What carries the argument
Synthetic algorithmic tasks generated from simple templates to keep the underlying computation identical across languages.
If this is right
- Models have not achieved full transfer of algorithmic skills across languages.
- Evaluation of future models can use these tasks to measure progress toward cross-lingual parity.
- Gaps appear even on objective, language-independent computations.
- The benchmark scales in complexity to match improving model capabilities.
Where Pith is reading between the lines
- Imbalances in training data may affect abstract reasoning abilities in addition to surface language skills.
- Template-driven tests of this form could extend to other structured domains such as basic mathematics.
- Persistent gaps may call for training methods that explicitly enforce equivalence on algorithmic operations.
Load-bearing premise
The synthetic algorithmic tasks remain fully commensurate across languages after translation and that observed performance differences arise from model capability rather than template artifacts or translation quality.
What would settle it
Showing equal performance across languages after expert verification of translation quality or after fixing template artifacts would indicate the gaps are not due to model capability.
Figures
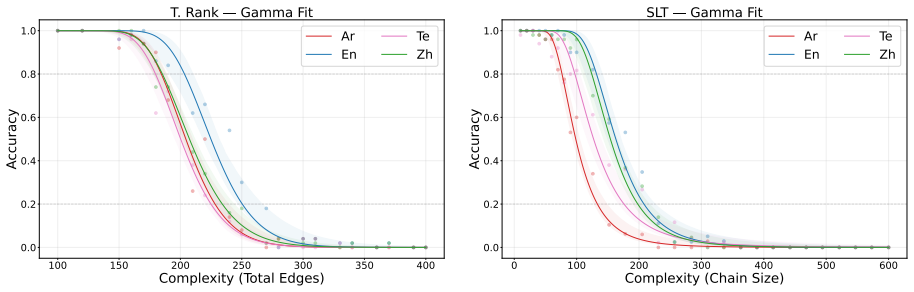
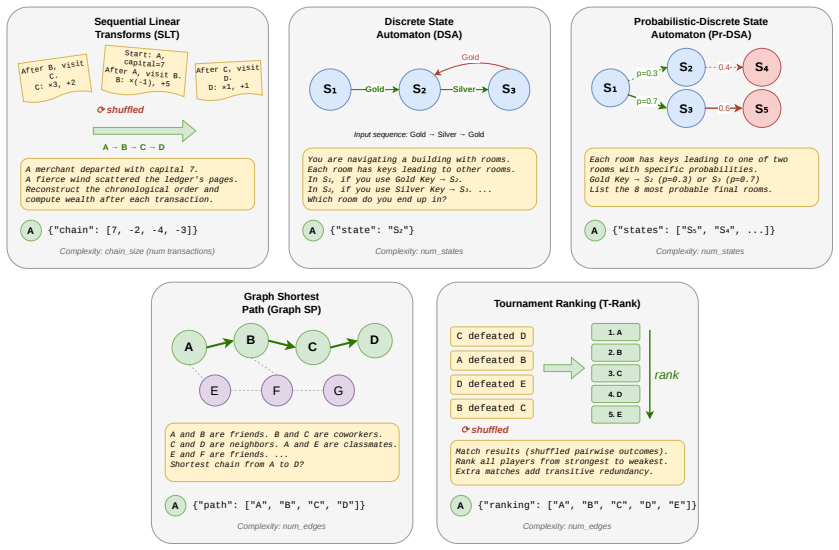
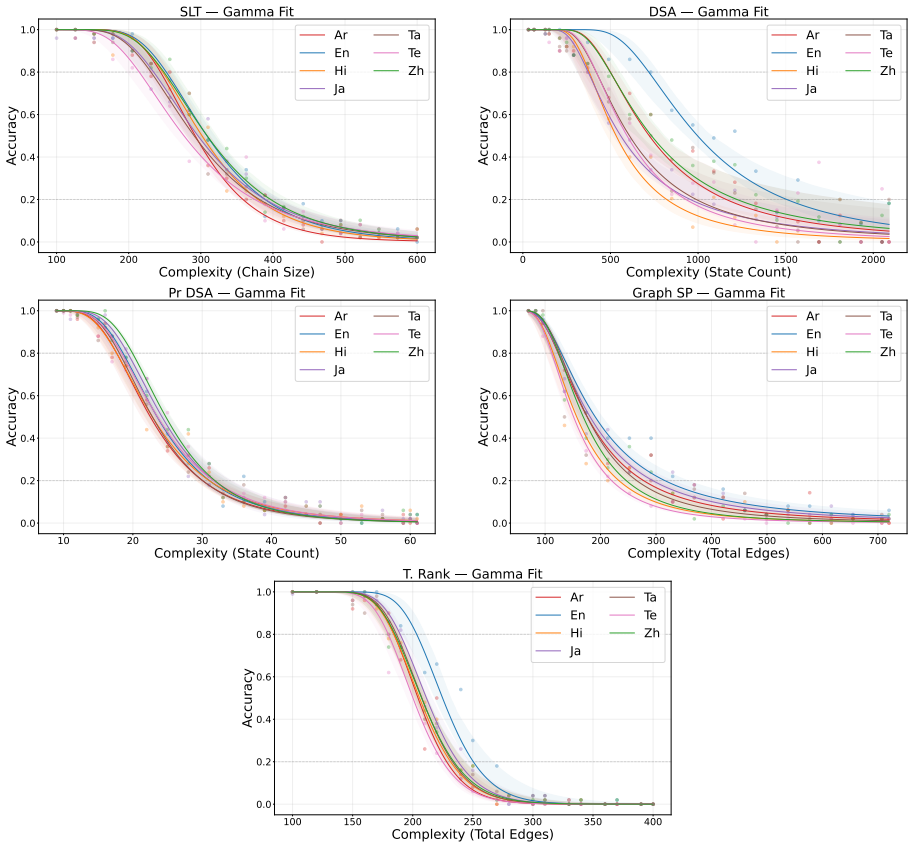
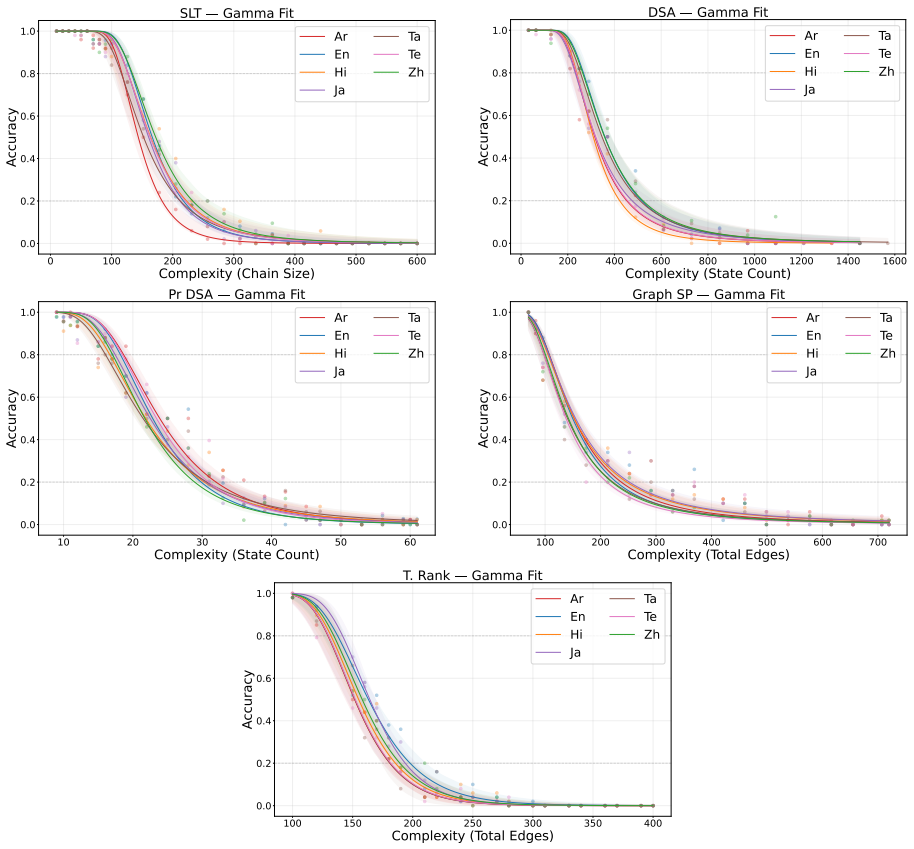
read the original abstract
We introduce a set of synthetic algorithmic tasks to detect cross-lingual gaps in the abilities of large language models. Our benchmark is commensurate across languages, since it requires models to perform the same underlying task in different languages; scalable, since each task can be generated at varying levels of complexity allowing it to be adapted to models with different capabilities; quantifiable, since every task admits an objective notion of correctness; and transparent, since tasks are generated from simple templates that can be readily audited for translation errors. Because our benchmark focuses on algorithmic tasks, differential performance is a sufficient -- but not necessary -- indicator of cross-lingual gaps. Nevertheless, we show through extensive experiments that our benchmark exposes persistent cross-lingual gaps in multiple state-of-the-art models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces XLGoBench, a benchmark consisting of synthetic algorithmic tasks (generated from simple templates) intended to measure cross-lingual gaps in LLMs. The tasks are presented as commensurate across languages because they require the same underlying algorithmic operations; the benchmark is further described as scalable via complexity variation, quantifiable via objective correctness, and transparent via auditable templates. Experiments on multiple state-of-the-art models are reported to reveal persistent cross-lingual performance differences.
Significance. If the commensurability claim holds, the benchmark would supply a useful, falsifiable instrument for isolating algorithmic reasoning gaps from language-specific knowledge or data imbalances, complementing existing multilingual evaluations. The synthetic, template-based design and objective scoring are strengths that could support reproducible follow-up work.
major comments (2)
- [Benchmark construction / task translation] Benchmark construction / task translation section: the central claim that observed performance gaps reflect model capability rather than template artifacts requires evidence that the translated instances remain algorithmically identical. No quantitative validation (back-translation BLEU, human semantic equivalence scores, or ablation on phrasing variants) is reported, leaving the commensurability assumption untested despite the paper's emphasis on 'readily audited' templates.
- [Experimental results] Experimental results section: without demonstrated translation equivalence, differential accuracy across languages cannot be unambiguously attributed to cross-lingual skill gaps; any reported gaps could arise from tokenization, instruction sensitivity, or translation artifacts, undermining the interpretation of the main findings.
minor comments (1)
- [Abstract / Introduction] Clarify in the abstract and introduction whether the benchmark is intended as a sufficient or merely indicative signal of gaps, to avoid overstatement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major point below, acknowledging where the manuscript is limited and committing to targeted revisions where appropriate.
read point-by-point responses
-
Referee: [Benchmark construction / task translation] Benchmark construction / task translation section: the central claim that observed performance gaps reflect model capability rather than template artifacts requires evidence that the translated instances remain algorithmically identical. No quantitative validation (back-translation BLEU, human semantic equivalence scores, or ablation on phrasing variants) is reported, leaving the commensurability assumption untested despite the paper's emphasis on 'readily audited' templates.
Authors: We agree that the manuscript reports no quantitative translation-equivalence metrics such as back-translation BLEU or human semantic scores. The benchmark construction section instead emphasizes that tasks are generated from simple, language-agnostic templates whose structure directly encodes the same algorithmic operations; translations are performed to preserve this structure, and the templates are presented as readily auditable. This design choice was intended to make equivalence verifiable by inspection rather than by aggregate metrics. Nevertheless, we accept that additional evidence would strengthen the claim and will add, in revision, a short validation subsection containing (i) manual equivalence checks on a stratified sample of translated templates and (ii) a limited set of phrasing-variant ablations on one task family. revision: partial
-
Referee: [Experimental results] Experimental results section: without demonstrated translation equivalence, differential accuracy across languages cannot be unambiguously attributed to cross-lingual skill gaps; any reported gaps could arise from tokenization, instruction sensitivity, or translation artifacts, undermining the interpretation of the main findings.
Authors: We concur that the interpretation of the reported gaps rests on the commensurability established in the benchmark-construction section. In the revised manuscript we will (a) restate the “sufficient but not necessary” framing already present in the abstract, (b) add explicit caveats in the experimental-results section regarding possible tokenization or phrasing effects, and (c) cross-reference the new validation subsection. These changes will make the evidential basis and its limitations clearer without altering the core experimental findings. revision: partial
Circularity Check
No circularity: empirical benchmark with design-based claims
full rationale
The paper introduces synthetic algorithmic tasks generated from simple templates and asserts commensurability across languages by construction of the task design (same underlying algorithm, auditable templates). No equations, fitted parameters, predictions derived from subsets of data, or self-citation chains appear in the provided text. The central claim that performance differences indicate gaps rests on the independent assumption of translation equivalence rather than reducing to a self-referential fit or definition. This is a standard empirical benchmark paper whose derivation chain is self-contained against external validation of the tasks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MultiZebraLogic: A Multilingual Logical Reasoning Benchmark
Multizebralogic: A multilingual log- ical reasoning benchmark . ArXiv preprint , abs/2511.03553. Erik Brynjolfsson, Danielle Li, and Lindsey Ray- mond. 2025. Generative ai at work. The Quar- terly Journal of Economics , 140(2):889–942. Google Deepmind. 2025. Gemini 3 flash: frontier intelligence built for speed. Google blog post. Google Deepmind. 2026a. G...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
ArXiv preprint, abs/2603.10793
Multilingual reasoning gym: Multilin- gual scaling of procedural reasoning environ- ments. ArXiv preprint, abs/2603.10793. Aryo Pradipta Gema, Joshua Ong Jun Leang, Gi- won Hong, Alessio Devoto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Yu Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, and 1 others. 2025. Are we done with mmlu? In Proceeding...
-
[3]
Generative ai’s impact on student achieve- ment and implications for worker productivity. Available at SSRN 5393516. Andre He, Nathaniel Weir, Kaj Bostrom, Allen Nie, Darion Cassel, Sam Bayless, and Huzefa Rangwala. 2026. Resyn: Autonomously scal- ing synthetic environments for reasoning mod- els. ArXiv preprint, abs/2602.20117. Dan Hendrycks, Collin Burn...
-
[4]
South Korea’s AI Surge: Policy, Models, and a Viral Cultural Moment
OpenReview.net. Junjie Hu, Sebastian Ruder, Aditya Siddhant, Gra- ham Neubig, Orhan Firat, and Melvin John- son. 2020. XTREME: A massively mul- tilingual multi-task benchmark for evaluating cross-lingual generalisation. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceed...
-
[5]
Language models are multilingual 10 chain-of-thought reasoners . In The Eleventh International Conference on Learning Repre- sentations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. Parshin Shojaee, Seyed Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. 2026. The illusion of think- ing: Understanding the st...
-
[6]
ArXiv preprint , abs/2504.15521
The bitter lesson learned from 2,000+ multilingual benchmarks . ArXiv preprint , abs/2504.15521. Weihao Xuan, Rui Y ang, Heli Qi, Qingcheng Zeng, Yunze Xiao, Aosong Feng, Dairui Liu, Yun Xing, Junjue Wang, Fan Gao, and 1 others. 2025. Mmlu-prox: A multilingual benchmark for ad- vanced large language model evaluation. In Pro- ceedings of the 2025 Conferenc...
-
[7]
Compute total nodes N = ( d + 1) + nc · (d + ce − 1)
-
[8]
Generate N unique alphanumeric node IDs (e.g. A1234)
-
[9]
Assign the first d+ 1 nodes as the back- bone: b0 → b1 → · · · → bd
-
[10]
Set source = b0, target = bd
-
[11]
Add edges (bi, bi+1) for i = 0, . . . , d−
-
[12]
Step 2: Parallel Bypass Chains
This creates the unique shortest path of length d. Step 2: Parallel Bypass Chains
-
[13]
, nc: • Allocate d + ce − 1 fresh nodes: cj 1, cj 2,
For each chain j = 1, . . . , nc: • Allocate d + ce − 1 fresh nodes: cj 1, cj 2, . . . , cj d+ce−1. • Add edges: b0 → cj 1 → cj 2 → · · · → cj d+ce−1 → bd
-
[14]
Step 3: Cross-Wiring Noise Edges
Each bypass chain has total length d + ce > d, so they cannot create a shorter path than the backbone. Step 3: Cross-Wiring Noise Edges
-
[15]
For each chain node u, consider two types of partners: • Chain–chain pairs: For each other chain node v: – Same chain: allow if depth gap > 1 and ≤ ce
Enumerate candidate edges. For each chain node u, consider two types of partners: • Chain–chain pairs: For each other chain node v: – Same chain: allow if depth gap > 1 and ≤ ce. – Different chains: allow if depth(v) − depth(u) ≤ excess(v) and depth(u) − depth(v) ≤ excess(u). • Chain–backbone pairs: For each backbone node bi: allow only if bi is at the sa...
-
[16]
Shuffle candidates, then for each (u, v) sampled with probability ρ: • Compute dists(u) + 1 + distt(v) and dists(v) + 1 + distt(u)
Add edges with distance safety check. Shuffle candidates, then for each (u, v) sampled with probability ρ: • Compute dists(u) + 1 + distt(v) and dists(v) + 1 + distt(u). • Reject if either value ≤ d (would create a path ≤ d from source to target). • Otherwise, add edge (u, v) and propagate updated distances via incremental BFS. Step 4: Verification
-
[17]
Verify shortest path length = d
Run BFS from source to target. Verify shortest path length = d
-
[18]
Verify exactly 1 unique shortest path exists
Count shortest paths. Verify exactly 1 unique shortest path exists. When scaling complexity levels we keep the pa- rameters d, nc, ce constant, and vary the noise den- 23 sity ρ to meet the desired number of edges. Once the maximum number of edges are achieved with the set parameters, we increment d by 1 and con- tinue from appropriate p based on required...
-
[19]
For each locale, we provide a separate tab within the same google sheet la- beled with the locale name
-
[20]
EN- GLISH_GROUNDTRUTH
Column A: “EN- GLISH_GROUNDTRUTH” to check against
-
[21]
{lang_id}_TRANSLATION
Column B: “{lang_id}_TRANSLATION” (e.g., AR_TRANSLATION) to verify
-
[22]
Translation OK
Column C: “Translation OK” (Y es/No)
-
[23]
Column D: Edited Translation to add the fixed translations if required
-
[24]
Trans- lation OK
Column E: Comments. Instructions: • Compare the English ground truth with translation based on metrics defined above. • Before you go ahead with translation please look at the rows marked as full example to see the full context of the task which will help with any ambigu- ities. • If translation has semantic equivalence with English ground truth and natur...
-
[25]
state”: “Room D6881
Silver Key, which room do you end up in? Example response: {“state”: “Room D6881”} IMPORTANT: The sequence has exactly 5 numbered triggers. Process them step by step: for each numbered trigger, find the matching transition rule for your current room and that trigger, then move to the next room. After applying all 5 triggers, report the final room. For exa...
-
[26]
IMPORTANT: Y our response must be a sin- gle valid JSON object and nothing else
Gold Key you apply trigger 1 (Gold Key), then trigger 2 (Silver Key), then trigger 3 (Gold Key), and report the room after exactly 3 steps. IMPORTANT: Y our response must be a sin- gle valid JSON object and nothing else. Arabic. ዛኞ ﺃ E2679. •ﺍ H4657. •ﺍܳڰ A5506. •ﺍ ؗ V9935. •ﺍ V9935. •ﺍܳڰ V9935. •ﺍܳڰ A5506. •ﺍ ؗ A5506. •ﺍ A5506. •ﺍ ؗ E2679. •ﺍ ؗ V9935. ﺍܳ...
-
[27]
state”: “ कमरा D6881
चांदी की चाबी, तो आप अंत में िकस कमर े में पहुँचेंगे? उदाहरण प्रितिक्रया: {“state”: “ कमरा D6881”} IMPORTANT: The sequence has exactly 5 numbered triggers. Process them step by step: for each numbered trigger, find the matching transition rule for your current room and that trigger, then move to the next room. After applying all 5 triggers, report the fin...
-
[28]
IMPORTANT: Y our response must be a single valid JSON object and nothing else
सोने की चाबी you apply trigger 1 (सोने की चाबी), then trig- ger 2 (चांदी की चाबी), then trigger 3 (सोने की चाबी), and report the room after exactly 3 steps. IMPORTANT: Y our response must be a single valid JSON object and nothing else. Japanese. あなたは異なる部屋がある建物を移動 しています。各部屋には他の部屋に移 動できる鍵があります。 あなたは部屋 E2679 から始めます。 • 部屋 V9935 で金の鍵を使うと、部 屋 H4657 にたどり着きます。 • ...
-
[29]
state”: “ 部屋 D6881
銀の鍵、どの部屋にたどり着きま すか? 回答の例: {“state”: “ 部屋 D6881”} IMPORTANT: The sequence has exactly 5 numbered triggers. Process them step by step: for each numbered trigger, find the matching transition rule for your current room and that trigger, then move to the next room. After applying all 5 triggers, report the final room. For example, if the sequence is:
-
[30]
IMPOR- TANT: Y our response must be a single valid JSON object and nothing else
金の鍵 you apply trigger 1 ( 金の鍵), then trigger 2 (銀の鍵 ), then trigger 3 ( 金の鍵 ), and re- port the room after exactly 3 steps. IMPOR- TANT: Y our response must be a single valid JSON object and nothing else. Tamil. நீங ் கள ் ெவவ ் ேவறு அைறகள ் ெகாண ் ட ஒரு கட ் டிடத ் திற ் குள ் ெசல ் கிறீர ் கள ் . ஒவ ் ெவாரு அைறயிலும ் மற ் ற அைறகளுக ் கு அைழத ் துச ் ெச...
-
[31]
state”: “அைற D6881
ெவள ் ளிச ் சாவி, இறுதியில ் நீங ் கள ் எந ் த அைறைய அைடவீர ் கள ் ? எடுத ் துக ் காட ் டு பதில ் : {“state”: “அைற D6881”} IMPORTANT: The sequence has exactly 5 numbered triggers. Process them step by step: for each numbered trigger, find the matching transition rule for your current room and that trigger, then move to the next room. After applying all 5 ...
-
[32]
IMPORTANT: Y our response must be a single valid JSON object and nothing else
தங ் கச ் சாவி you apply trigger 1 (தங ் கச ் சாவி),then trigger 2 (ெவள ் ளிச ் சாவி),then trig- ger 3 (தங ் கச ் சாவி),and report the room after exactly 3 steps. IMPORTANT: Y our response must be a single valid JSON object and nothing else. Telugu. మీరు వివిధ గదులు ఉనన్ భవనంలో నడుసు త్ నాన్రు. పȼతి గదిలో మిమమ్లిన్ ఇతర గదులకు తీసుకెళేళ్ తాళంచెవులు ఉనాన్యి...
-
[33]
state”: “ గది D6881
వెండి తాళంచెవి, చివరకు మీరు ఏ గదికి చేరుకుంటారు? ఉదాహరణ పȼతిసప్ందన: {“state”: “ గది D6881”} IMPORTANT: The sequence has exactly 5 numbered triggers. Process them step by step: for each numbered trigger, find the matching transition rule for your current room and that trigger, then move to the next room. After applying all 5 triggers, re- port the final ro...
-
[34]
state”ğ“ࡗٜD6881
ၿᄂӼ 2.ᄂӼ 3.ᄂӼ 4.Ĥ ճğ{“state”ğ“ࡗٜD6881”} IMPORTANT: The sequence has exactly 5 numbered triggers. Process them step by step: for each numbered trigger, find the matching transition rule for your current room and that trigger, then move to the next room. After applying all 5 triggers, report the final room. For example, if the sequence is: 1.ᄂӼ
-
[35]
states”: [“Room G5374
ၿᄂӼ 3.ᄂӼ you apply trigger 1 (ᄂӼ), then trigger 2 (ၿᄂӼ ), then trigger 3 (ᄂӼ ), and re- port the room after exactly 3 steps. IMPOR- TANT: Y our response must be a single valid JSON object and nothing else. C.3.3 Probabilistic Discrete State Automata (Pr-DSA) English. Y ou navigate through a building with dif- ferent rooms. Each room has keys, which can le...
-
[36]
W9928 and C4582 are neighbors
-
[37]
C7912 and R4257 are classmates
-
[38]
H4657 and C7912 are neighbors
-
[39]
H9279 and U2824 are classmates
-
[40]
U2824 and H4657 are coworkers. 39
-
[41]
A5506 and B1488 are coworkers
-
[42]
W9928 and V9935 are relatives
-
[43]
T1434 and V9935 are relatives
-
[44]
B1488 and R4257 are relatives
-
[45]
E2679 and T1434 are relatives
-
[46]
E2679 and A5506 are classmates
-
[47]
path”: [“A1234
H9279 and C4582 are friends. Question: What is the shortest chain of con- nections from H4657 to V9935? List the people in order from H4657 to V9935, in- cluding both H4657 and V9935. Solve the puzzle step by step using BFS al- gorithm. At the very end, only output your final answer as a single JSON object on its own line in this exact format: {“path”: [“...
-
[48]
W9928 और C4582 पड़ोसी हैं।
-
[49]
C7912 और R4257 सहपाठी हैं।
-
[50]
H4657 और C7912 पड़ोसी हैं।
-
[51]
H9279 और U2824 सहपाठी हैं।
-
[52]
U2824 और H4657 सहकमर्ी हैं।
-
[53]
A5506 और B1488 सहकमर्ी हैं।
-
[54]
W9928 और V9935 िरश्तेदार हैं।
-
[55]
T1434 और V9935 िरश्तेदार हैं।
-
[56]
B1488 और R4257 िरश्तेदार हैं।
-
[57]
E2679 और T1434 िरश्तेदार हैं।
-
[58]
E2679 और A5506 सहपाठी हैं।
-
[59]
path”: [“A1234
H9279 और C4582 िमत्र हैं। प्रश्न:H4657 से V9935 तक पहुँचने का सबसे छोटा संपकर्मागर्क्या है?H4657 से V9935 तक क े सभी लोगा ें को क्रम में बताइए,H4657 और V9935 दोनाें को शािमल करते हुए। Solve the puzzle step by step using BFS al- gorithm. At the very end, only output your final answer as a single JSON object on its own line in this exact format: {“path”: [“...
-
[60]
C7912 と R4257は同級生です。
-
[61]
H4657 と C7912 は隣人です。
-
[62]
H9279 と U2824は同級生です。
-
[63]
E2679 と A5506は同級生です。
-
[64]
path”: [“A1234
H9279 と C4582 は友達です。 質問:H4657 から V9935までの最も短 い つ な が り は 何 で す か?H4657 か ら V9935 ま で の 人 物 を、H4657 お よ び V9935を含めて順番に挙げてください。 Solve the puzzle step by step using BFS al- gorithm. At the very end, only output your final answer as a single JSON object on its own line in this exact format: {“path”: [“A1234”, “B5678”, “C9012”]} The path should list all nodes ...
-
[65]
W9928 மற ் றும ் C4582 அண ் ைட வீட ் டார ்
-
[66]
C7912 மற ் றும ்R4257 வகுப ் புத ் ேதாழர ் கள ்
-
[67]
H4657 மற ் றும ்C7912 அண ் ைட வீட ் டார ்
-
[68]
H9279 மற ் றும ்U2824 வகுப ் புத ் ேதாழர ் கள ்
-
[69]
U2824 மற ் றும ் H4657 சக ஊழBயர ் கள ்
-
[70]
A5506 மற ் றும ் B1488 சக ஊழBயர ் கள ்
-
[71]
W9928 மற ் றும ் V9935 உறவினர ் கள ்
-
[72]
T1434 மற ் றும ் V9935 உறவினர ் கள ்
-
[73]
B1488 மற ் றும ் R4257 உறவினர ் கள ்
-
[74]
E2679 மற ் றும ் T1434 உறவினர ் கள ்
-
[75]
E2679 மற ் றும ்A5506 வகுப ் புத ் ேதாழர ் கள ்
-
[76]
path”: [“A1234
H9279 மற ் றும ் C4582 நண ் பர ் கள ் . ேகள ் வி: H4657 இலிருந ் துV9935 வைரயிலான மBகக ் குறுகிய ெதாடர ் பு சங ் கிலி என ் ன? H4657 இலிருந ் து V9935 வைர வரிைசயாக நபர ் கைளப ் பட ் டியலிடுங ் கள ் ,H4657 மற ் றும ் V9935 இருவைரயும ் ேசர ் த ் து. Solve the puzzle step by step using BFS al- gorithm. At the very end, only output your final answer as a singl...
-
[77]
W9928 మరియు C4582 ఇరుగుపొరుగువారు
-
[78]
C7912 మరియుR4257 సహవిదాయ్రు థ్ లు
-
[79]
H4657 మరియు C7912 ఇరుగుపొరుగువారు
-
[80]
H9279 మరియుU2824 సహవిదాయ్రు థ్ లు
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.