DARTS: Distribution-Aware Active Rollout Trajectory Shaping for Accelerating LLM Reinforcement Learning
Pith reviewed 2026-06-28 23:24 UTC · model grok-4.3
The pith
Active distribution shaping removes ineffective verbosity from LLM rollout trajectories to accelerate reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
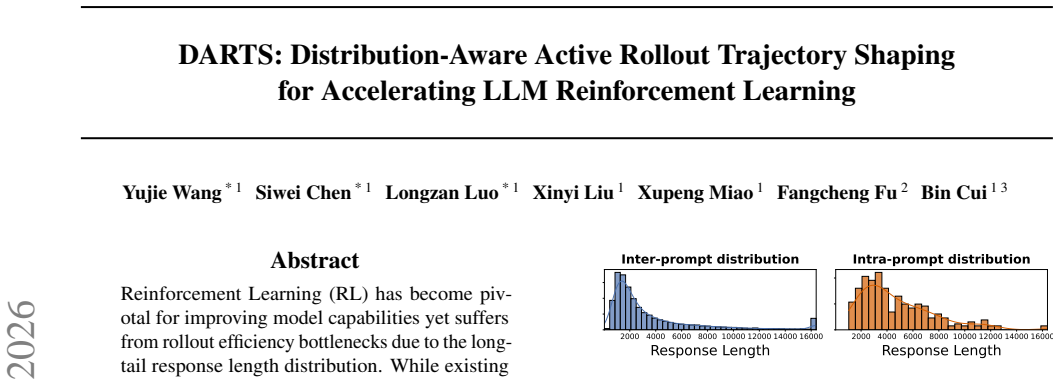
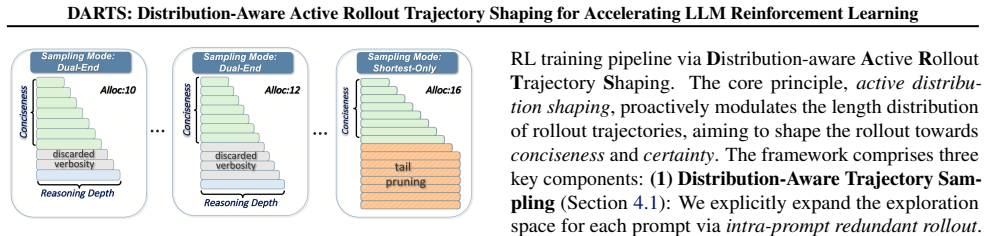
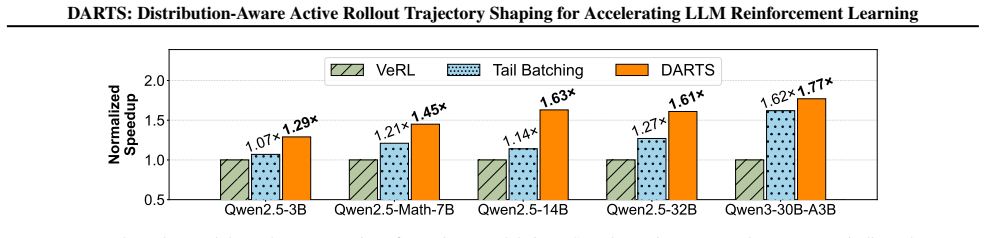
The central discovery is that intra-prompt long tails in LLM rollouts frequently consist of ineffective verbosity, and a distribution-aware trajectory sampling mechanism that selects from a redundant exploration space, paired with adaptive redundancy allocation, can shape the distribution toward conciseness and certainty, thereby resolving tail-induced overheads and achieving up to 1.77x acceleration over state-of-the-art systems without compromising model performance.
What carries the argument
The distribution-aware trajectory sampling mechanism, which selects trajectories from a redundant exploration space for each prompt, together with an adaptive redundancy allocation scheme.
If this is right
- RL for LLMs becomes more efficient by focusing computation on concise trajectories.
- State-of-the-art systems can be accelerated by up to 1.77x.
- Model performance remains intact while reducing overhead from long tails.
- The approach addresses the root source of inefficiency in the distribution itself rather than just scheduling.
Where Pith is reading between the lines
- This method might generalize to other domains where RL involves generating long sequences with variable lengths.
- It could lead to new ways of thinking about exploration in LLM training that prioritize certainty over exhaustive verbosity.
- Practitioners might see reduced compute costs for fine-tuning LLMs with RL.
Load-bearing premise
Intra-prompt long tails consist mostly of ineffective verbosity that sampling can filter without losing the diversity required for effective policy improvement.
What would settle it
An experiment where removing the sampled trajectories leads to degraded final model performance or slower convergence in policy improvement compared to full sampling.
Figures




read the original abstract
Reinforcement Learning (RL) has become pivotal for improving model capabilities yet suffers from rollout efficiency bottlenecks due to the long-tail response length distribution. While existing works mitigate the impact of long tails via prompt-level tail scheduling, we focus on the root source of inefficiency: the distribution itself. Specifically, we characterize the long-tail distribution at a finer granularity, identifying intra-prompt long tails, and revealing that they frequently consist of ineffective verbosity. To address this, we propose a novel paradigm of active distribution shaping to shape the rollout distribution towards conciseness and certainty, thereby fundamentally resolving tail-induced overheads. We achieve this through a distribution-aware trajectory sampling mechanism, which selects trajectories from a redundant exploration space for each prompt, and an adaptive redundancy allocation scheme to maximize both shaping effectiveness and system efficiency. Experiments demonstrate significant acceleration over state-of-the-art systems by up to 1.77x without compromising model performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that intra-prompt long tails in LLM RL rollouts are predominantly ineffective verbosity, and introduces DARTS: a distribution-aware trajectory sampling mechanism that selects from a redundant exploration space per prompt, combined with adaptive redundancy allocation, to actively shape the rollout distribution toward conciseness. This is asserted to yield up to 1.77x acceleration over SOTA systems without compromising model performance.
Significance. If the core assumption and empirical results hold, the work could meaningfully improve rollout efficiency in RL for LLMs by targeting the distribution itself rather than prompt-level scheduling. The paradigm of active distribution shaping is presented as a new approach that could apply more broadly to long-tailed RL settings.
major comments (2)
- [Abstract] Abstract: The central claim of 'significant acceleration ... by up to 1.77x without compromising model performance' is stated without any reported metrics, baselines, controls, or statistical tests. This is load-bearing for the 'no performance compromise' assertion, as the method's safety depends on demonstrating that pruned trajectories do not remove necessary diversity for policy improvement.
- [Abstract] Abstract: The characterization of intra-prompt long tails as 'frequently consist[ing] of ineffective verbosity' is presented without quantitative evidence (e.g., fraction of tail trajectories that are high-reward, diverse, or correct-but-extended). If a non-negligible portion carries useful exploration, the sampling and allocation scheme risks biasing gradients or reducing sample efficiency, directly undermining the acceleration result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that strengthening the abstract with explicit metrics and quantitative support will improve clarity and address the concerns about self-containment. We will revise the manuscript accordingly while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'significant acceleration ... by up to 1.77x without compromising model performance' is stated without any reported metrics, baselines, controls, or statistical tests. This is load-bearing for the 'no performance compromise' assertion, as the method's safety depends on demonstrating that pruned trajectories do not remove necessary diversity for policy improvement.
Authors: We agree the abstract should be more self-contained. In the revision we will update the abstract to explicitly report the 1.77x speedup (with the corresponding baseline system), the evaluation benchmarks, and a concise statement that performance is preserved or improved (with reference to the reward curves, diversity metrics, and statistical tests already present in Sections 4 and 5). These sections already contain the controls showing that the shaped distribution does not remove high-reward or diverse trajectories required for policy improvement; the abstract revision will surface this evidence. revision: yes
-
Referee: [Abstract] Abstract: The characterization of intra-prompt long tails as 'frequently consist[ing] of ineffective verbosity' is presented without quantitative evidence (e.g., fraction of tail trajectories that are high-reward, diverse, or correct-but-extended). If a non-negligible portion carries useful exploration, the sampling and allocation scheme risks biasing gradients or reducing sample efficiency, directly undermining the acceleration result.
Authors: The full manuscript already contains quantitative support for this characterization (reward-vs-length scatter plots and histograms in Section 3.2, plus the fraction of tail trajectories that are both high-reward and low-diversity). To make the abstract self-contained we will add a short quantitative clause (e.g., “>70 % of intra-prompt tail trajectories exhibit low reward and low diversity”) and will reference the corresponding figures. This directly addresses the concern that useful exploration might be removed; the added numbers will show that the adaptive sampling preserves the minority of high-value tail trajectories. revision: yes
Circularity Check
No significant circularity; method presented as novel paradigm without reduction to fitted inputs or self-citations
full rationale
The abstract and description introduce a new active distribution shaping paradigm via distribution-aware trajectory sampling and adaptive redundancy allocation, characterizing intra-prompt long tails as ineffective verbosity. No equations, parameter fits, predictions derived from subsets of data, or self-citations appear in the provided text. The central claims rest on empirical characterization and a proposed mechanism rather than any self-definitional loop, fitted-input renaming, or load-bearing self-citation chain, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Anthropic. Claude 4.5 opus. https://www. anthropic.com/news/claude-opus-4-5/ , 2025a. Anthropic. Claude 4.5 sonnet. https://www. anthropic.com/news/claude-sonnet-4-5/ , 2025b. Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Han, Z., You, A., Wang, H., Luo, K., Yang, G., Shi, W., Chen, M., Zhang, S., Lan, Z., Deng, C., et al. Asyncflow: An asynchronous streaming rl framework for efficient llm post-training.arXiv preprint arXiv:2507.01663,
-
[4]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Car- ney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Let’s verify step by step
Lightman, H., Kosaraju, V ., Burda, Y ., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let’s verify step by step. InInternational Conference on Learning Representations, volume 2024, pp. 39578–39601,
2024
-
[6]
Part ii: Roll flash– accelerating rlvr and agentic training with asynchrony
10 DARTS: Distribution-Aware Active Rollout Trajectory Shaping for Accelerating LLM Reinforcement Learning Lu, H., Liu, Z., Xiong, S., He, Y ., Gao, W., Wu, Y ., Wang, W., Liu, J., Li, Y ., Zhao, H., et al. Part ii: Roll flash– accelerating rlvr and agentic training with asynchrony. arXiv preprint arXiv:2510.11345,
-
[7]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Kimi K2: Open Agentic Intelligence
Team, K., Bai, Y ., Bao, Y ., Chen, G., Chen, J., Chen, N., Chen, R., Chen, Y ., Chen, Y ., Chen, Y ., et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025a. Team, K., Du, A., Gao, B., Xing, B., Jiang, C., Chen, C., Li, C., Xiao, C., Du, C., Liao, C., et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arX...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Yang, A., Zhang, B., Hui, B., Gao, B., Yu, B., Li, C., Liu, D., Tu, J., Zhou, J., Lin, J., et al. Qwen2. 5-math techni- cal report: Toward mathematical expert model via self- improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Zhong, Y ., Zhang, Z., Song, X., Hu, H., Jin, C., Wu, B., Chen, N., Chen, Y ., Zhou, Y ., Wan, C., et al. Streamrl: Scalable, heterogeneous, and elastic rl for llms with disaggregated stream generation.arXiv preprint arXiv:2504.15930,
-
[13]
doi: 10.1007/S41019-023-00235-6. Zhou, Y ., Li, J., Su, Y ., Ramesh, G., Zhu, Z., Long, X., Zhao, C., Pan, J., Yu, X., Wang, Z., et al. April: Active partial rollouts in reinforcement learning to tame long-tail generation.arXiv preprint arXiv:2509.18521,
-
[14]
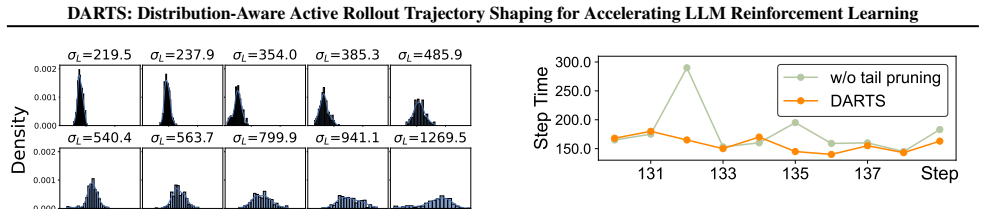
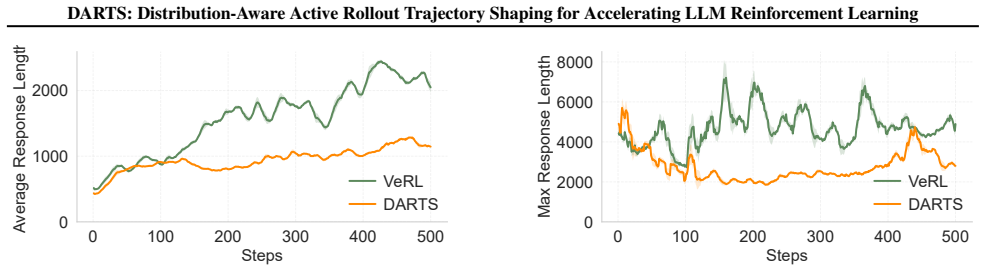
This trend confirms that our method effectively mitigates the verbose long-tail issue early on, greatly enhancing training efficiency
As shown by the orange curves (DARTS), both the average and maximum response lengths exhibit a significant reduction during the early and middle stages of training compared to the baseline (VeRL). This trend confirms that our method effectively mitigates the verbose long-tail issue early on, greatly enhancing training efficiency. Crucially, the data revea...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.