Inverse Reinforcement Learning without an Optimal Demonstrator: A Feasible Reward Set Approach
Pith reviewed 2026-06-28 23:56 UTC · model grok-4.3
The pith
Intersecting linear constraints from multiple imperfect demonstrators recovers the ground-truth optimal reward set under coverage conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating each demonstrator's suboptimality level as a linear constraint and intersecting the resulting half-spaces, the feasible reward set for the ground-truth optimal demonstrator can be recovered even when no demonstrator is near-optimal, provided the collected trajectories supply sufficient coverage; the joint set contracts monotonically and a new demonstrator tightens it precisely when its constraint cuts the current polytope.
What carries the argument
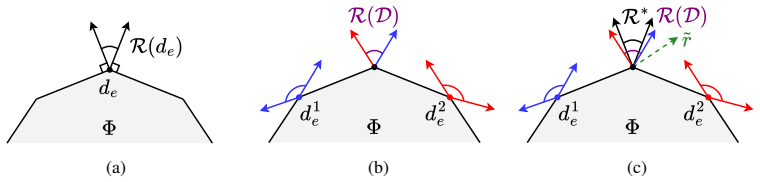
The feasible reward set formed by intersecting linear suboptimality constraints, one per demonstrator.
If this is right
- The joint feasible set shrinks monotonically as additional demonstrators are incorporated.
- A new demonstrator strictly tightens the set if and only if its linear constraint cuts the interior of the current polytope.
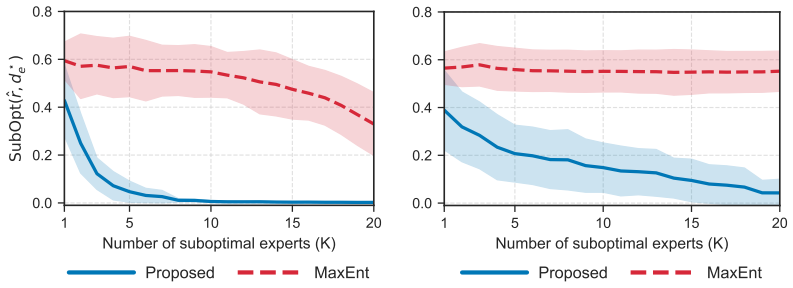
- Recovery of the ground-truth optimal reward set is guaranteed when trajectories are close to the optimal occupancy measure.
- A second recovery guarantee holds under sufficient coverage alone, without any near-optimal demonstrator.
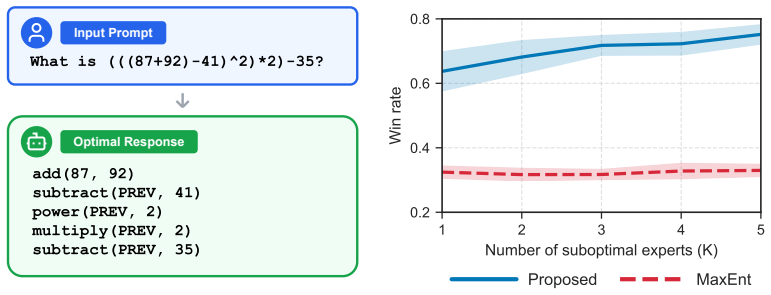
- The offline algorithm with function approximation produces a practical reward set usable for downstream policy optimization.
Where Pith is reading between the lines
- The same intersection idea could be applied to preference data where each user supplies an implicit suboptimality bound.
- In high-dimensional control, the coverage condition might be checked via reachability analysis before claiming recovery.
- Ambiguity-resolution heuristics proposed for the reward set could be replaced by downstream task performance as a selection criterion.
Load-bearing premise
Each demonstrator's declared suboptimality level can be accurately encoded as a linear constraint on the reward.
What would settle it
An experiment in which adding a new demonstrator with a known suboptimality level fails to shrink the feasible set, or in which the recovered set excludes the true reward despite full coverage of the state-action space.
Figures
read the original abstract
Inverse reinforcement learning (IRL) typically assumes demonstrations from a single optimal demonstrator, but in many applications data come from multiple imperfect demonstrators with heterogeneous suboptimality levels. We study reward learning in this setting through a feasible-reward-set framework: for each demonstrator, we encode its declared suboptimality level as a linear constraint and intersect the resulting feasible sets across demonstrators. Our theoretical analysis shows that the joint feasible set shrinks monotonically as data are added, and we give an exact characterization of when a new demonstrator strictly tightens it. We further establish two recovery guarantees for the feasible reward set of the ground-truth optimal demonstrator: one bound depends on closeness to the optimal occupancy, while the other requires only sufficient coverage and no near-optimal demonstrator. On the practical side, we introduce strategies to address the inherent reward ambiguity in the obtained reward set and provide an offline algorithm with function approximation for high-dimensional environments. Experiments in tabular grid-world and large language model (LLM) fine-tuning settings are consistent with the theoretical predictions and demonstrate the effectiveness of the proposed framework over baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a feasible-reward-set framework for inverse reinforcement learning from multiple demonstrators with heterogeneous but declared suboptimality levels. For each demonstrator the declared suboptimality ε is encoded as a linear constraint on the reward vector (via the difference between the demonstrator's occupancy measure and the optimal one); the joint feasible set is their intersection. The manuscript proves that this joint set shrinks monotonically with additional demonstrators, supplies an exact characterization of when a new demonstrator strictly tightens the set, and states two recovery guarantees for the ground-truth reward of an optimal demonstrator (one depending on closeness to the optimal occupancy, the other requiring only sufficient coverage). Practical contributions include ambiguity-resolution strategies and an offline algorithm with function approximation; experiments in tabular grid-worlds and LLM fine-tuning are reported to be consistent with the theory.
Significance. If the linear-constraint encoding is valid and the occupancy measures are known exactly, the monotonicity result and the two recovery guarantees would constitute a useful theoretical advance for IRL settings that do not assume optimality. The provision of a function-approximation algorithm and the LLM experiment also add practical value for high-dimensional applications.
major comments (2)
- [Abstract / §3 (linear constraint definition)] Abstract / linear-constraint construction: the claim that each demonstrator's declared suboptimality level can be encoded exactly as a linear inequality on the reward (via expected-return difference under occupancy measures) is load-bearing for monotonic shrinking, the tightening characterization, and both recovery guarantees. The manuscript must derive this inequality from first principles and state the precise assumptions (exact knowledge of occupancy measures, absence of variance or non-stationarity effects) under which the inequality remains valid and tight; without this derivation the intersection may exclude the ground-truth reward or retain spurious rewards.
- [Abstract / recovery guarantees section] Recovery guarantees (abstract): the two stated bounds presuppose that the linear constraints are both valid and tight for the declared ε values. If occupancy estimation error or higher-order effects are present, the feasible set may fail to contain the ground-truth reward; the manuscript should supply a formal statement of the bounds together with the error terms that arise from constraint violation.
minor comments (1)
- [Abstract] The abstract refers to 'strategies to address the inherent reward ambiguity' without naming them; a one-sentence description would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the linear-constraint derivation and the recovery guarantees.
read point-by-point responses
-
Referee: [Abstract / §3 (linear constraint definition)] Abstract / linear-constraint construction: the claim that each demonstrator's declared suboptimality level can be encoded exactly as a linear inequality on the reward (via expected-return difference under occupancy measures) is load-bearing for monotonic shrinking, the tightening characterization, and both recovery guarantees. The manuscript must derive this inequality from first principles and state the precise assumptions (exact knowledge of occupancy measures, absence of variance or non-stationarity effects) under which the inequality remains valid and tight; without this derivation the intersection may exclude the ground-truth reward or retain spurious rewards.
Authors: We agree that an explicit derivation from first principles is necessary for clarity. The constraint arises directly because the expected return equals the inner product of the reward vector R and the occupancy measure μ; a declared suboptimality ε therefore yields the linear inequality R · (μ* − μ_d) ≤ ε. We will add a dedicated paragraph in §3 that starts from the definition of return, states the exact assumptions (known occupancy measures, stationary policies, and deterministic transitions), and shows why the inequality is valid and tight under those conditions. This revision will also note that the monotonicity and recovery results hold precisely when these assumptions are satisfied. revision: yes
-
Referee: [Abstract / recovery guarantees section] Recovery guarantees (abstract): the two stated bounds presuppose that the linear constraints are both valid and tight for the declared ε values. If occupancy estimation error or higher-order effects are present, the feasible set may fail to contain the ground-truth reward; the manuscript should supply a formal statement of the bounds together with the error terms that arise from constraint violation.
Authors: We acknowledge the need to make the dependence on constraint validity explicit. We will augment the recovery-guarantee theorems with a corollary that introduces an additive slack term δ (the maximum violation of any linear constraint) and shows that the ground-truth reward lies inside an enlarged feasible set whose radius grows linearly with δ. The statement will also indicate how the monotonic-shrinkage property is preserved under approximate constraints. These additions will appear in the theoretical section immediately following the original guarantees. revision: yes
Circularity Check
No circularity; framework derives results from explicit modeling assumptions
full rationale
The paper constructs the feasible reward set by directly encoding each demonstrator's declared suboptimality ε as a linear inequality on the reward vector (via occupancy measure differences) and intersecting the resulting half-spaces. All claimed properties—monotonic shrinking of the joint set, exact characterization of when a new demonstrator tightens the intersection, and the two recovery guarantees—are standard consequences of this linear feasible-set construction under the modeling assumptions. No equation or guarantee is shown to equal its own inputs by construction, no fitted parameter is relabeled as a prediction, and no self-citation or prior ansatz is invoked as load-bearing justification. The derivation is therefore self-contained conditional on the stated linear encoding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Declared suboptimality levels of demonstrators can be encoded as linear constraints on the reward function.
Reference graph
Works this paper leans on
-
[1]
Algorithms for inverse reinforcement learning
Andrew Y Ng and Stuart J Russell. Algorithms for inverse reinforcement learning. InInternational Conference on Machine Learning, pages 663–670. PMLR, 2000
2000
-
[2]
A survey of inverse reinforcement learning.Artificial Intelligence Review, 55(6):4307–4346, 2022
Stephen Adams, Tyler Cody, and Peter A Beling. A survey of inverse reinforcement learning.Artificial Intelligence Review, 55(6):4307–4346, 2022
2022
-
[3]
Robust reinforcement learning from corrupted human feedback.Advances in Neural Information Processing Systems, 37:124093–124113, 2024
Alexander Bukharin, Ilgee Hong, Haoming Jiang, Zichong Li, Qingru Zhang, Zixuan Zhang, and Tuo Zhao. Robust reinforcement learning from corrupted human feedback.Advances in Neural Information Processing Systems, 37:124093–124113, 2024
2024
-
[4]
Chanwoo Park, Mingyang Liu, Dingwen Kong, Kaiqing Zhang, and Asuman Ozdaglar. Rlhf from heterogeneous feedback via personalization and preference aggregation.arXiv preprint arXiv:2405.00254, 2024
-
[5]
Diverging preferences: When do annotators disagree and do models know? InInternational Conference on Machine Learning, pages 76193–76212
Michael Jq Zhang, Zhilin Wang, Jena D Hwang, Yi Dong, Olivier Delalleau, Yejin Choi, Eunsol Choi, Xiang Ren, and Valentina Pyatkin. Diverging preferences: When do annotators disagree and do models know? InInternational Conference on Machine Learning, pages 76193–76212. PMLR, 2025
2025
-
[6]
Joint goal and strategy inference across heterogeneous demonstrators via reward network distillation
Letian Chen, Rohan Paleja, Muyleng Ghuy, and Matthew Gombolay. Joint goal and strategy inference across heterogeneous demonstrators via reward network distillation. InProceedings of the 2020 ACM/IEEE international conference on human-robot interaction, pages 659–668, 2020
2020
-
[7]
Learning from suboptimal demonstration via self-supervised reward regression
Letian Chen, Rohan Paleja, and Matthew Gombolay. Learning from suboptimal demonstration via self-supervised reward regression. InConference on robot learning, pages 1262–1277. PMLR, 2021
2021
-
[8]
Droid: Learning from offline heterogeneous demonstrations via reward-policy distillation
Sravan Jayanthi, Letian Chen, Nadya Balabanska, Van Duong, Erik Scarlatescu, Ezra Ameperosa, Zul- fiqar Haider Zaidi, Daniel Martin, Taylor Keith Del Matto, Masahiro Ono, et al. Droid: Learning from offline heterogeneous demonstrations via reward-policy distillation. InConference on Robot Learning, pages 1547–1571. PMLR, 2023
2023
-
[9]
Maximum entropy inverse reinforcement learning
Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, Anind K Dey, et al. Maximum entropy inverse reinforcement learning. InAaai, volume 8, pages 1433–1438. Chicago, IL, USA, 2008
2008
-
[10]
Bayesian inverse reinforcement learning
Deepak Ramachandran, Eyal Amir, et al. Bayesian inverse reinforcement learning. InIJCAI, volume 7, pages 2586–2591, 2007
2007
-
[11]
Imitation learning by estimating expertise of demonstrators
Mark Beliaev, Andy Shih, Stefano Ermon, Dorsa Sadigh, and Ramtin Pedarsani. Imitation learning by estimating expertise of demonstrators. InInternational Conference on Machine Learning, pages 1732–1748. PMLR, 2022
2022
-
[12]
Inverse reinforcement learning by estimating expertise of demonstra- tors
Mark Beliaev and Ramtin Pedarsani. Inverse reinforcement learning by estimating expertise of demonstra- tors. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 15532–15540, 2025
2025
-
[13]
Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations
Daniel Brown, Wonjoon Goo, Prabhat Nagarajan, and Scott Niekum. Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations. InInternational Conference on Machine Learning, pages 783–792. PMLR, 2019
2019
-
[14]
Better-than-demonstrator imitation learning via automatically-ranked demonstrations
Daniel S Brown, Wonjoon Goo, and Scott Niekum. Better-than-demonstrator imitation learning via automatically-ranked demonstrations. InConference on Robot Learning, pages 330–359. PMLR, 2020
2020
-
[15]
Provably efficient learning of transferable rewards
Alberto Maria Metelli, Giorgia Ramponi, Alessandro Concetti, and Marcello Restelli. Provably efficient learning of transferable rewards. InInternational Conference on Machine Learning, pages 7665–7676. PMLR, 2021
2021
-
[16]
Towards theoretical understanding of inverse reinforcement learning
Alberto Maria Metelli, Filippo Lazzati, and Marcello Restelli. Towards theoretical understanding of inverse reinforcement learning. InInternational Conference on Machine Learning, pages 24555–24591. PMLR, 2023
2023
-
[17]
A unified linear programming frame- work for offline reward learning from human demonstrations and feedback
Kihyun Kim, Jiawei Zhang, Asuman E Ozdaglar, and Pablo Parrilo. A unified linear programming frame- work for offline reward learning from human demonstrations and feedback. InInternational Conference on Machine Learning, pages 24694–24712. PMLR, 2024
2024
-
[18]
Sub-optimal experts mitigate ambiguity in inverse reinforcement learning.Advances in Neural Information Processing Systems, 37: 85778–85823, 2024
Riccardo Poiani, Gabriele Curti, Alberto M Metelli, and Marcello Restelli. Sub-optimal experts mitigate ambiguity in inverse reinforcement learning.Advances in Neural Information Processing Systems, 37: 85778–85823, 2024. 10
2024
-
[19]
Filippo Lazzati and Alberto Maria Metelli. Generalizing behavior via inverse reinforcement learning with closed-form reward centroids.arXiv preprint arXiv:2509.12010, 2025
-
[20]
Inverse reinforcement learning from failure
Kyriacos Shiarlis, Joao Messias, and Shimon Whiteson. Inverse reinforcement learning from failure. In Proceedings of the 2016 International Conference on Autonomous Agents & Multiagent Systems, pages 1060–1068, 2016
2016
-
[21]
Maximum margin planning
Nathan D Ratliff, J Andrew Bagnell, and Martin A Zinkevich. Maximum margin planning. InInternational Conference on Machine Learning, pages 729–736, 2006
2006
-
[22]
Learning to search: Functional gradient techniques for imitation learning.Autonomous Robots, 27(1):25–53, 2009
Nathan D Ratliff, David Silver, and J Andrew Bagnell. Learning to search: Functional gradient techniques for imitation learning.Autonomous Robots, 27(1):25–53, 2009
2009
-
[23]
Reinforcement Learning from Imperfect Demonstrations
Yang Gao, Huazhe Xu, Ji Lin, Fisher Yu, Sergey Levine, and Trevor Darrell. Reinforcement learning from imperfect demonstrations.arXiv preprint arXiv:1802.05313, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Confidence-aware imitation learning from demonstrations with varying optimality.Advances in Neural Information Processing Systems, 34: 12340–12350, 2021
Songyuan Zhang, Zhangjie Cao, Dorsa Sadigh, and Yanan Sui. Confidence-aware imitation learning from demonstrations with varying optimality.Advances in Neural Information Processing Systems, 34: 12340–12350, 2021
2021
-
[25]
John Wiley & Sons, 1994
Martin L Puterman.Markov decision processes: discrete stochastic dynamic programming. John Wiley & Sons, 1994
1994
-
[26]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[27]
Wiley New York, 1959
R Duncan Luce et al.Individual choice behavior, volume 4. Wiley New York, 1959
1959
-
[28]
SIAM, 2021
Alexander Shapiro, Darinka Dentcheva, and Andrzej Ruszczynski.Lectures on stochastic programming: modeling and theory. SIAM, 2021
2021
-
[29]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Apprenticeship learning via inverse reinforcement learning
Pieter Abbeel and Andrew Y Ng. Apprenticeship learning via inverse reinforcement learning. InInterna- tional Conference on Machine Learning, page 1, 2004
2004
-
[31]
A game-theoretic approach to apprenticeship learning.Advances in neural information processing systems, 20, 2007
Umar Syed and Robert E Schapire. A game-theoretic approach to apprenticeship learning.Advances in neural information processing systems, 20, 2007
2007
-
[32]
Apprenticeship learning using linear programming
Umar Syed, Michael Bowling, and Robert E Schapire. Apprenticeship learning using linear programming. InProceedings of the 25th international conference on Machine learning, pages 1032–1039, 2008
2008
-
[33]
Relative entropy inverse reinforcement learning
A Boularias, J Kober, and J Peters. Relative entropy inverse reinforcement learning. InFourteenth International Conference on Artificial Intelligence and Statistics (AISTATS 2011), pages 182–189. MIT Press, 2011
2011
-
[34]
Guided cost learning: Deep inverse optimal control via policy optimization
Chelsea Finn, Sergey Levine, and Pieter Abbeel. Guided cost learning: Deep inverse optimal control via policy optimization. InInternational conference on machine learning, pages 49–58. PMLR, 2016
2016
-
[35]
Learning Robust Rewards with Adversarial Inverse Reinforcement Learning
Justin Fu, Katie Luo, and Sergey Levine. Learning robust rewards with adversarial inverse reinforcement learning.arXiv preprint arXiv:1710.11248, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Active exploration for inverse reinforcement learning.Advances in Neural Information Processing Systems, 35:5843–5853, 2022
David Lindner, Andreas Krause, and Giorgia Ramponi. Active exploration for inverse reinforcement learning.Advances in Neural Information Processing Systems, 35:5843–5853, 2022
2022
-
[37]
Is inverse reinforcement learning harder than standard reinforcement learning? a theoretical perspective
Lei Zhao, Mengdi Wang, and Yu Bai. Is inverse reinforcement learning harder than standard reinforcement learning? a theoretical perspective. InInternational Conference on Machine Learning, pages 60957–61020. PMLR, 2024
2024
-
[38]
On feasible rewards in multi-agent inverse reinforcement learning
Till Freihaut and Giorgia Ramponi. On feasible rewards in multi-agent inverse reinforcement learning. arXiv preprint arXiv:2411.15046, 2024
-
[39]
Bayesian multitask inverse reinforcement learning
Christos Dimitrakakis and Constantin A Rothkopf. Bayesian multitask inverse reinforcement learning. In European Workshop on Reinforcement Learning, pages 273–284. Springer, 2011. 11
2011
-
[40]
Apprenticeship learning about multiple intentions
Monica Babes, Vukosi Marivate, Kaushik Subramanian, and Michael L Littman. Apprenticeship learning about multiple intentions. InInternational Conference on Machine Learning, pages 897–904, 2011
2011
-
[41]
The analysis of permutations.Journal of the Royal Statistical Society Series C: Applied Statistics, 24(2):193–202, 1975
Robin L Plackett. The analysis of permutations.Journal of the Royal Statistical Society Series C: Applied Statistics, 24(2):193–202, 1975
1975
-
[42]
A ranking game for imitation learning.Transactions on machine learning research, 2023
H Sikchi, A Saran, W Goo, and S Niekum. A ranking game for imitation learning.Transactions on machine learning research, 2023
2023
-
[43]
A framework for behavioural cloning
Michael Bain and Claude Sammut. A framework for behavioural cloning. InMachine intelligence 15, pages 103–129, 1995
1995
-
[44]
Efficient reductions for imitation learning
Stéphane Ross and Drew Bagnell. Efficient reductions for imitation learning. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 661–668. JMLR Workshop and Conference Proceedings, 2010
2010
-
[45]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
2011
-
[46]
Reinforcement and Imitation Learning via Interactive No-Regret Learning
Stephane Ross and J Andrew Bagnell. Reinforcement and imitation learning via interactive no-regret learning.arXiv preprint arXiv:1406.5979, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[47]
Generative adversarial imitation learning.Advances in neural information processing systems, 29, 2016
Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning.Advances in neural information processing systems, 29, 2016
2016
-
[48]
Deep rein- forcement learning from human preferences.Advances in neural information processing systems, 30, 2017
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep rein- forcement learning from human preferences.Advances in neural information processing systems, 30, 2017
2017
-
[49]
Reward learning from human preferences and demonstrations in atari.Advances in neural information processing systems, 31, 2018
Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, and Dario Amodei. Reward learning from human preferences and demonstrations in atari.Advances in neural information processing systems, 31, 2018
2018
-
[50]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[51]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[52]
On approximate solutions of systems of linear inequalities.Journal of Research of the National Bureau of Standards, 49(4), 1952
Alan J Hoffman. On approximate solutions of systems of linear inequalities.Journal of Research of the National Bureau of Standards, 49(4), 1952
1952
-
[53]
New characterizations of hoffman constants for systems of linear constraints.Mathematical Programming, 187(1):79–109, 2021
Javier Pena, Juan C Vera, and Luis F Zuluaga. New characterizations of hoffman constants for systems of linear constraints.Mathematical Programming, 187(1):79–109, 2021. 12 A Additional related work IRL from a single optimal demonstrator and apprenticeship learning.Classical IRL studies the recovery of a reward function that rationalizes a single optimal ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.