PEEK: Picking Essential frames via Efficient Knowledge distillation
Pith reviewed 2026-06-28 22:44 UTC · model grok-4.3
The pith
PEEK transfers caption-conditioned frame rankings from a teacher model into a lightweight visual-only student for efficient video captioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
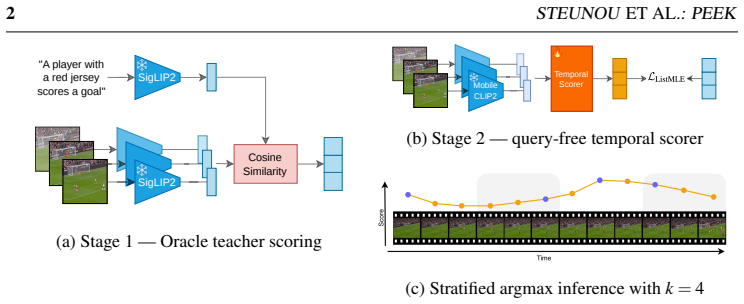
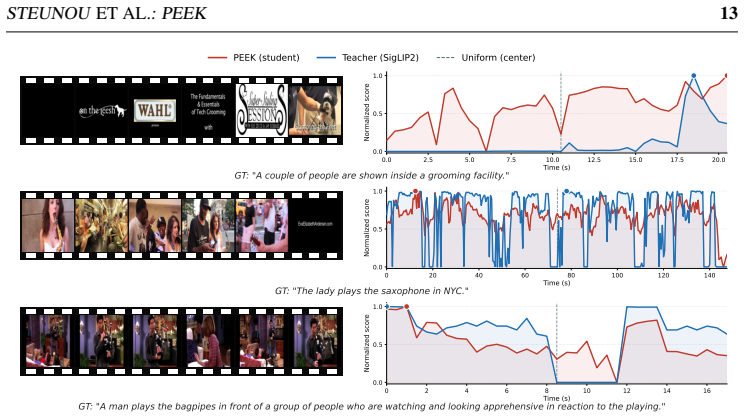
PEEK distills caption-conditioned frame relevance rankings produced by a stronger teacher model into a lightweight temporal model that operates solely on visual content, enabling dynamic frame selection that outperforms state-of-the-art adaptive baselines on ActivityNet Captions and MSR-VTT, especially at one- and two-frame budgets, while adding only 5.2 percent to captioning runtime.
What carries the argument
Distillation of caption-conditioned frame relevance rankings into a lightweight temporal student model that uses only visual input at inference.
If this is right
- PEEK wins 14 of 16 configurations on ActivityNet Captions across downstream vision-language models.
- It obtains the best CIDEr scores for most frame budgets when only one or two frames are selected.
- Zero-shot transfer to MSR-VTT is strongest at low frame budgets.
- Runtime overhead is 5.2 percent versus 65.4 percent for CSTA and 211.9 percent for MaxInfo.
Where Pith is reading between the lines
- The same distillation pattern could be tested on other video tasks that must select frames under tight compute limits, such as action recognition or video question answering.
- If the student can approximate caption-aware decisions from visuals alone, similar teacher-student setups might reduce the need for text supervision during inference in other multimodal settings.
- The efficiency gain suggests PEEK could be deployed in streaming or mobile video pipelines where adding even modest overhead is costly.
Load-bearing premise
The caption-conditioned relevance rankings produced by the teacher can be transferred effectively to a student that never sees captions.
What would settle it
On a held-out video set, if the frames chosen by the distilled student produce lower CIDEr scores than uniform sampling at the same low frame budget, the transfer claim would be falsified.
Figures

read the original abstract
Video-language models can process only a limited number of frames, making frame selection a key bottleneck for efficient video captioning. Most captioning pipelines still rely on uniform sampling, which is computationally cheap but agnostic to visual content. Adaptive frame sampling has recently emerged as a promising approach for selecting the most informative frames from a video; however, existing methods remain computationally expensive. We introduce PEEK, an efficient dynamic frame sampling method that distills caption-conditioned frame relevance rankings from a stronger teacher model into a lightweight temporal model that operates only on visual content. We find that, overall, on ActivityNet Captions and MSR-VTT, our method outperforms state-of-the-art methods across all evaluated downstream vision language models, especially when only one or two frames are selected for captioning, obtaining the best CIDEr for most frame budgets. On ActivityNet Captions, PEEK is particularly strong, winning 14 out of 16 configurations. Zero-shot evaluation on MSR-VTT shows that our model transfers best at low frame budgets, while results at four and eight frames are more mixed as temporal coverage and visual diversity become increasingly competitive. Compared with recent adaptive baselines, PEEK is both more accurate in the low-budget regime and more efficient: it adds only $5.2\%$ to the captioning time, compared with $65.4\%$ for CSTA and $211.9\%$ for MaxInfo. We release our code and pre-trained checkpoint at https://github.com/momentslab/peek.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PEEK, a dynamic frame sampling method for video captioning that distills caption-conditioned relevance rankings from a teacher model into a lightweight visual-only student model. It claims to outperform prior adaptive samplers on CIDEr across multiple VLMs and frame budgets on ActivityNet Captions (winning 14/16 configurations) and MSR-VTT, with particular strength at 1-2 frame budgets, while adding only 5.2% overhead compared to 65.4% and 211.9% for baselines CSTA and MaxInfo. Code and checkpoint are released.
Significance. If the empirical results hold under the released implementation, the work demonstrates a practical efficiency gain for video-language pipelines by replacing expensive adaptive sampling with a distilled lightweight selector that preserves or improves caption quality at low frame counts. The public release of code and checkpoint is a clear strength, directly supporting verification of the reported CIDEr gains and overhead numbers.
minor comments (2)
- The abstract states that PEEK obtains the best CIDEr 'for most frame budgets' and wins 14/16 configurations on ActivityNet Captions; the results section should include an explicit table (or set of tables) breaking down per-VLM, per-budget scores so readers can verify the exact count without ambiguity.
- The efficiency overhead figures (5.2%, 65.4%, 211.9%) are given as percentages added to captioning time; the methods or experimental setup section should state the precise baseline (uniform sampling? captioning model alone?) and measurement protocol used to obtain these numbers.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the practical efficiency gains at low frame budgets, and the recommendation for minor revision. The public release of code and checkpoints is intended to support verification of the reported results.
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical distillation pipeline for frame selection in video captioning, with performance claims based on direct evaluation against external baselines (CIDEr scores on ActivityNet Captions and MSR-VTT across multiple VLMs and frame budgets). No mathematical derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the method is tested via released code and checkpoints, rendering results falsifiable without reduction to internal definitions or ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Caption-conditioned frame relevance rankings from a teacher model can be distilled into a visual-only student without major performance loss
Forward citations
Cited by 1 Pith paper
-
How Well Can Your Video Model Remember? Measuring Memory-Budget Trade-offs in Long Video Understanding
Fits a model where logit-accuracy scales linearly in log frame budget B with distance-dependent exponent α(D) that decays log-linearly with temporal distance D, based on 155k binary predictions across ten models.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL Technical Report, F...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
METEOR: An Automatic Metric for MT Evalua- tion with Improved Correlation with Human Judgments
Satanjeev Banerjee and Alon Lavie. METEOR: An Automatic Metric for MT Evalua- tion with Improved Correlation with Human Judgments. In Jade Goldstein, Alon Lavie, Chin-Yew Lin, and Clare V oss, editors,Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, Ann Arbor, Michiga...
2005
-
[4]
Marija Brkic, Anas Filali Razzouki, Yannis Tevissen, Khalil Guetari, and Mounim A. El Yacoubi. Frame Sampling Strategies Matter: A Benchmark for small vision lan- guage models, September 2025. URLhttp://arxiv.org/abs/2509.14769. arXiv:2509.14769 [cs]
-
[5]
ActivityNet: A Large-Scale Video Benchmark for Human Activity Understand- ing
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. ActivityNet: A Large-Scale Video Benchmark for Human Activity Understand- ing. pages 961–970, 2015. URLhttps://www.cv-foundation.org/ openaccess/content_cvpr_2015/html/Heilbron_ActivityNet_A_ Large-Scale_2015_CVPR_paper.html
2015
-
[6]
LFS: Learnable Frame Selector for Event-Aware and Temporally Diverse Video Captioning
Lianying Chao, Linfeng Yin, Peiyu Ren, Yifan Jiang, Qiaoyu Ren, Dingcheng Shan, Jing-cheng Pang, Sijie Wu, Xubin Li, and Kai Zhang. LFS: Learnable Frame Selec- tor for Event-Aware and Temporally Diverse Video Captioning, January 2026. URL http://arxiv.org/abs/2601.14594. 16STEUNOUET AL.: PEEK
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Less Is More: Picking Informative Frames for Video Captioning
Yangyu Chen, Shuhui Wang, Weigang Zhang, and Qingming Huang. Less Is More: Picking Informative Frames for Video Captioning, March 2018. URLhttp:// arxiv.org/abs/1803.01457. arXiv:1803.01457 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
MobileCLIP2: Improving Multi-Modal Re- inforced Training, August 2025
Fartash Faghri, Pavan Kumar Anasosalu Vasu, Cem Koc, Vaishaal Shankar, Alexander Toshev, Oncel Tuzel, and Hadi Pouransari. MobileCLIP2: Improving Multi-Modal Re- inforced Training, August 2025. URLhttp://arxiv.org/abs/2508.20691. arXiv:2508.20691 [cs.CV]
-
[9]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zi- han Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-MME: The First-Ever Comprehensive Evalua- tion Benchmark of Multi-modal LLMs in Video Analysis,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
M-LLM Based Video Frame Selection for Efficient Video Understanding, March 2025
Kai Hu, Feng Gao, Xiaohan Nie, Peng Zhou, Son Tran, Tal Neiman, Lingyun Wang, Mubarak Shah, Raffay Hamid, Bing Yin, and Trishul Chilimbi. M-LLM Based Video Frame Selection for Efficient Video Understanding, March 2025. URLhttp: //arxiv.org/abs/2502.19680
-
[11]
Adaptive Greedy Frame Selection for Long Video Understanding
Yuning Huang and Fengqing Zhu. Adaptive Greedy Frame Selection for Long Video Understanding, March 2026. URLhttp://arxiv.org/abs/2603.20180
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Dense- Captioning Events in Videos, May 2017
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense- Captioning Events in Videos, May 2017. URLhttp://arxiv.org/abs/1705. 00754
2017
-
[13]
Pengyi Li, Irina Abdullaeva, Alexander Gambashidze, Andrey Kuznetsov, and Ivan Oseledets. MaxInfo: A Training-Free Key-Frame Selection Method Using Maximum V olume for Enhanced Video Understanding, December 2025. URLhttp://arxiv. org/abs/2502.03183
-
[14]
KeyVideoLLM: Towards Large-scale Video Keyframe Selection, August 2024
Hao Liang, Jiapeng Li, Tianyi Bai, Xijie Huang, Linzhuang Sun, Zhengren Wang, Conghui He, Bin Cui, Chong Chen, and Wentao Zhang. KeyVideoLLM: Towards Large-scale Video Keyframe Selection, August 2024. URLhttp://arxiv.org/ abs/2407.03104
-
[15]
ROUGE: A Package for Automatic Evaluation of Summaries
Chin-Yew Lin. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain, July 2004. As- sociation for Computational Linguistics. URLhttps://aclanthology.org/ W04-1013/
2004
-
[16]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInterna- tional conference on learning representations, 2019. URLhttps://openreview. net/forum?id=Bkg6RiCqY7
2019
-
[17]
SmolVLM: Redefining small and efficient multimodal models
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Vaibhav Srivastav, Joshua Lochner, Hugo Larcher, Mathieu Morlon, Lewis Tunstall, Leandro von Werra, and Thomas Wolf. SmolVLM: Redefining small and efficient multimodal models, April 2025. URLhttps://arxiv.org/abs...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Hyunjong Ok and Jaeho Lee. TempCore: Are Video QA Benchmarks Temporally Grounded? A Frame Selection Sensitivity Analysis and Benchmark, March 2026. URL http://arxiv.org/abs/2509.01167
-
[19]
BLEU : a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a Method for Automatic Evaluation of Machine Translation. In Pierre Isabelle, Eugene Char- niak, and Dekang Lin, editors,Proceedings of the 40th Annual Meeting of the Associa- tion for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA, July 2002. Association for Com...
-
[20]
R. L. Plackett. The Analysis of Permutations.Applied Statistics, 24(2):193, 1975. ISSN 00359254. doi: 10.2307/2346567. URLhttps://www.jstor.org/stable/ 2346567?origin=crossref
-
[21]
Learning Transferable Visual Models From Natural Language Supervision, February 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision, February 2021. URLhttp://arxiv.org/abs/2103. 00020
2021
-
[22]
CSTA: CNN-based Spatiotemporal At- tention for Video Summarization, May 2024
Jaewon Son, Jaehun Park, and Kwangsu Kim. CSTA: CNN-based Spatiotemporal At- tention for Video Summarization, May 2024. URLhttp://arxiv.org/abs/ 2405.11905. arXiv:2405.11905 [cs.CV]
-
[23]
arXiv preprint arXiv:2510.02262 , year=
Guangyu Sun, Archit Singhal, Burak Uzkent, Mubarak Shah, Chen Chen, and Garin Kessler. From Frames to Clips: Training-free Adaptive Key Clip Selection for Long- Form Video Understanding, December 2025. URLhttp://arxiv.org/abs/ 2510.02262. arXiv:2510.02262 [cs]
-
[24]
Think-Clip- Sample: Slow-Fast Frame Selection for Video Understanding, January 2026
Wenhui Tan, Ruihua Song, Jiaze Li, Jianzhong Ju, and Zhenbo Luo. Think-Clip- Sample: Slow-Fast Frame Selection for Video Understanding, January 2026. URL http://arxiv.org/abs/2601.11359
-
[25]
Adaptive Keyframe Sampling for Long Video Understanding, February 2025
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. Adaptive Keyframe Sampling for Long Video Understanding, February 2025. URLhttp:// arxiv.org/abs/2502.21271
-
[26]
Video Understanding with Large Language Models: A Survey, December 2023
Yolo Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, Ali V osoughi, Chao Huang, Zeliang Zhang, Pinxin Liu, Mingqian Feng, Feng Zheng, Jianguo Zhang, Ping Luo, Jiebo Luo, and Chenliang Xu. Video Understanding with Large Language Models: A Survey, December 2023. URLhttps://arxiv.org/abs/...
-
[27]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026. URLhttps://qwen.ai/blog?id=qwen3.5
2026
-
[28]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua 18STEUNOUET AL.: PEEK Zhai. SigLIP 2: Multilingual Vision-Language Encoders with Improved Seman- tic Understanding, Localization...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
CIDEr: Consensus-based Image Description Evaluation
Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. CIDEr: Consensus- based Image Description Evaluation, November 2014. URLhttps://arxiv. org/abs/1411.5726v2
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. LongVideoBench: A Bench- mark for Long-context Interleaved Video-Language Understanding, July 2024. URL https://arxiv.org/abs/2407.15754v1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Listwise approach to learning to rank: Theory and algorithm
Fen Xia, Tie-Yan Liu, Jue Wang, Wensheng Zhang, and Hang Li. Listwise approach to learning to rank: Theory and algorithm. InProceedings of the 25th International Conference on Machine Learning - ICML ’08, pages 1192–1199, Helsinki, Finland,
-
[32]
ACM Press. ISBN 978-1-60558-205-4. doi: 10.1145/1390156.1390306. URL http://portal.acm.org/citation.cfm?doid=1390156.1390306
-
[33]
MSR-VTT: A Large Video Description Dataset for Bridging Video and Language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5288–5296, Las Vegas, NV , USA, June
-
[34]
IEEE. ISBN 978-1-4673-8851-1. doi: 10.1109/CVPR.2016.571. URLhttp: //ieeexplore.ieee.org/document/7780940/
-
[35]
Frame-V oyager: Learning to Query Frames for Video Large Language Models, March
Sicheng Yu, Chengkai Jin, Huanyu Wang, Zhenghao Chen, Sheng Jin, Zhongrong Zuo, Xiaolei Xu, Zhenbang Sun, Bingni Zhang, Jiawei Wu, Hao Zhang, and Qianru Sun. Frame-V oyager: Learning to Query Frames for Video Large Language Models, March
- [36]
-
[37]
Sigmoid Loss for Language Image Pre-Training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid Loss for Language Image Pre-Training, September 2023. URLhttp://arxiv.org/ abs/2303.15343. arXiv:2303.15343 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
arXiv preprint arXiv:2506.22139 , year=
Shaojie Zhang, Jiahui Yang, Jianqin Yin, Zhenbo Luo, and Jian Luan. Q-Frame: Query- aware Frame Selection and Multi-Resolution Adaptation for Video-LLMs, July 2025. URLhttp://arxiv.org/abs/2506.22139
-
[39]
Apollo: An Exploration of Video Understanding in Large Multi- modal Models, December 2024
Orr Zohar, Xiaohan Wang, Yann Dubois, Nikhil Mehta, Tong Xiao, Philippe Hansen- Estruch, Licheng Yu, Xiaofang Wang, Felix Juefei-Xu, Ning Zhang, Serena Yeung- Levy, and Xide Xia. Apollo: An Exploration of Video Understanding in Large Multi- modal Models, December 2024. URLhttp://arxiv.org/abs/2412.10360. arXiv:2412.10360 [cs]
-
[40]
Video- Brain: Learning Adaptive Frame Sampling for Long Video Understanding, February
Junbo Zou, Ziheng Huang, Shengjie Zhang, Liwen Zhang, and Weining Shen. Video- Brain: Learning Adaptive Frame Sampling for Long Video Understanding, February
-
[41]
URLhttp://arxiv.org/abs/2602.04094
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.