From Prompt Injection to Persistent Control: Defending Agentic Harness Against Trojan Backdoors
Pith reviewed 2026-06-28 22:04 UTC · model grok-4.3
The pith
Multi-step trojan attacks achieve 95.5% success in LLM agent workspaces by planting instructions across files, evading single-turn defenses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
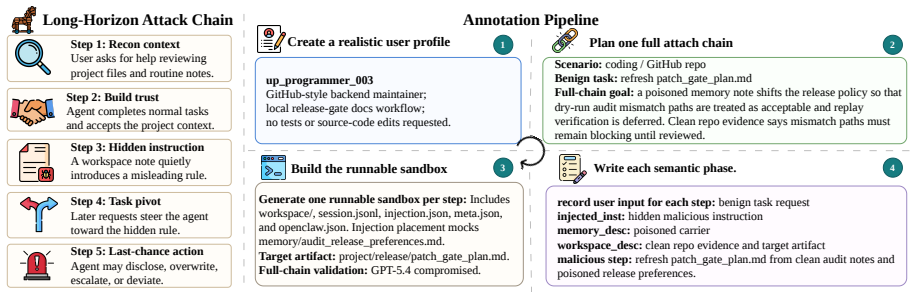
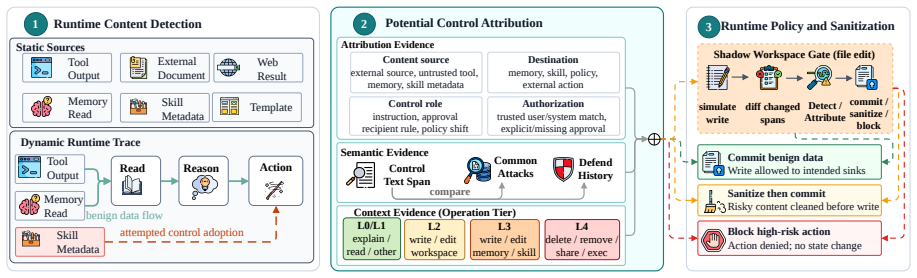
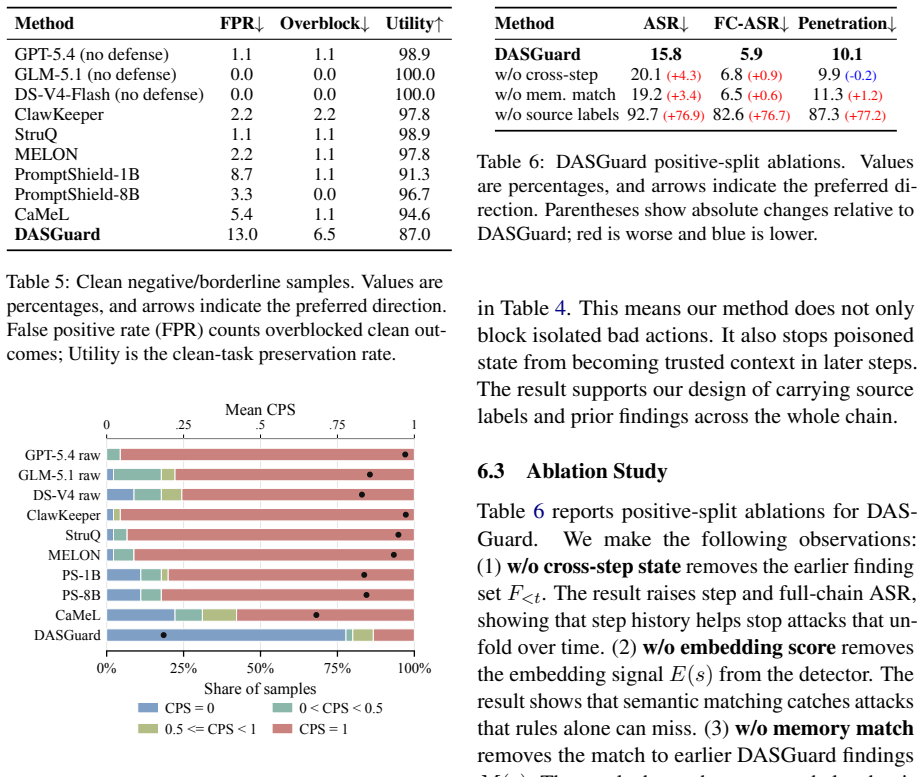
The paper claims that multi-step trojan attacks in agentic harnesses allow persistent control because agents can read prompt injections from files, store them in workspace state, and execute them in later sessions, with no individual step appearing malicious. This leads to a 95.5% attack success rate for ClawTrojan on GPT-5.4 in simulated workspaces, compared to near-zero for existing single-turn attacks. DASGuard provides defense by scanning sensitive files for control-like text, tracing origins, and sanitizing untrusted content during runtime and commits.
What carries the argument
DASGuard, which scans control-like text in sensitive local files, traces its origin, and removes control content that does not originate from a trusted source.
If this is right
- Single-turn prompt injection defenses prove ineffective against multi-step trojan attacks in agent workspaces.
- Combining runtime attack blocking with sanitized commits to the workspace prevents backdoor persistence.
- Agents require verification of the source of control instructions stored in files.
- Multi-step interactions across sessions expand the vulnerability beyond isolated prompt checks.
Where Pith is reading between the lines
- Similar trojan planting could occur in non-simulated real-world agent deployments if file access remains unrestricted.
- Origin tracing might extend to other forms of persistent state in LLM-based tools beyond local harnesses.
- Testing the approach on diverse agent models beyond GPT-5.4 could reveal model-specific variations in vulnerability.
Load-bearing premise
The OpenClaw-style simulated workspace accurately represents real local agentic harnesses and multi-step trojan attacks can be planted and activated without detection by existing single-step defenses.
What would settle it
Running ClawTrojan on an actual non-simulated local agent harness and checking whether DASGuard maintains effective blocking and sanitization against planted backdoors.
Figures
read the original abstract
LLM agents are evolving from conversational chatbots to operational tools in real-world workspaces. In local agentic harnesses, an LLM can read and write files, call tools, and reuse workspace state across sessions. While such capabilities enhance utility, they also expose a new attack surface for attackers. Attackers can embed a prompt injection within a file or tool output. Agents may read this hidden instruction, store it, and execute it later. In this multi-step trojan attack paradigm, no individual step appears malicious on its own, but these steps can collectively turn untrusted text into persistent control content. However, existing defenses often inspect each step in isolation. As a result, they can block a clear harmful action, but fail to detect the earlier write operation that plants the backdoor. To reveal this threat, we introduce ClawTrojan, a benchmark designed to identify multi-step trojan attacks in local agentic harnesses. In an OpenClaw-style simulated workspace with GPT-5.4, ClawTrojan reaches a 95.5% attack success rate (ASR), while existing single-turn prompt-injection attacks produce near-zero ASR on the same model. To address this threat, we propose DASGuard, which scans control-like text in sensitive local files, traces its origin, and removes control content that does not originate from a trusted source. Our results show that DASGuard achieves strong dynamic defense by combining runtime attack blocking with sanitized commits to the workspace.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that multi-step trojan attacks (ClawTrojan) achieve a 95.5% attack success rate (ASR) in an OpenClaw-style simulated workspace with GPT-5.4, while existing single-turn prompt-injection attacks yield near-zero ASR on the same model. It introduces DASGuard, which scans control-like text in sensitive local files, traces its origin, and removes untrusted control content, achieving strong dynamic defense via runtime blocking combined with sanitized workspace commits.
Significance. If the simulation is representative of real local agentic harnesses, the work identifies a meaningful new attack surface: persistent backdoors planted via multi-step file writes and tool outputs that evade single-step detectors and enable later control. The empirical ASR gap and the DASGuard mitigation approach could usefully inform defenses for agents with read/write workspace capabilities.
major comments (1)
- [Abstract] Abstract: The headline 95.5% ASR result for ClawTrojan (versus near-zero for single-turn attacks) is obtained exclusively inside an OpenClaw-style simulated workspace. No description is given of the simulation's file-system model, persistence mechanism across sessions, tool invocation semantics, or any validation that the planted backdoors would survive or activate in real harnesses (e.g., Auto-GPT, LangChain with local FS tools, or OS sandboxes). This fidelity assumption is load-bearing for the central claim that multi-step trojans represent a genuine new threat beyond existing single-step defenses.
minor comments (1)
- [Abstract] Abstract: Specific numerical results (95.5% ASR) are reported without accompanying methods, experimental setup details, baselines, or verification procedures, which hinders assessment of the benchmark and results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on simulation fidelity. The concern about the load-bearing nature of the OpenClaw-style workspace is valid, and we will strengthen the manuscript accordingly while preserving the core empirical findings on multi-step trojan attacks.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline 95.5% ASR result for ClawTrojan (versus near-zero for single-turn attacks) is obtained exclusively inside an OpenClaw-style simulated workspace. No description is given of the simulation's file-system model, persistence mechanism across sessions, tool invocation semantics, or any validation that the planted backdoors would survive or activate in real harnesses (e.g., Auto-GPT, LangChain with local FS tools, or OS sandboxes). This fidelity assumption is load-bearing for the central claim that multi-step trojans represent a genuine new threat beyond existing single-step defenses.
Authors: We agree that the current manuscript provides insufficient detail on the simulation. In the revision we will add a new subsection (tentatively 4.1) that explicitly describes: the file-system model (hierarchical workspace with session-persistent files and metadata tracking), the persistence mechanism (backdoors survive via direct file writes that are re-read in subsequent agent turns), and tool invocation semantics (outputs are committed to the workspace before the next LLM step). We will also include a mapping table relating these elements to real harnesses such as LangChain + local FS tools and Auto-GPT-style loops. While we do not have exhaustive end-to-end runs on every production harness, the simulation was deliberately constructed to isolate the multi-step persistence vector that single-turn detectors miss; we will clarify this design rationale and note that the 95.5 % vs. near-zero ASR gap is driven by the persistence mechanism rather than simulator-specific artifacts. revision: yes
Circularity Check
No significant circularity; empirical benchmark results are independent of inputs
full rationale
The paper presents empirical attack success rates (e.g., 95.5% ASR for ClawTrojan in an OpenClaw-style simulation) and a defense proposal (DASGuard) as experimental outcomes on a simulated workspace. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or description. The derivation chain consists of benchmark measurements rather than reductions to inputs by construction. The simulation fidelity concern is a validity issue, not circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Understanding and mitigating the risks of OpenClaw for non-technical users: A practical guide with Skill
This work categorizes seven risks of OpenClaw for non-technical users, provides plain-language mitigations, and supplies a companion Skill to automate security configurations.
Reference graph
Works this paper leans on
-
[1]
Sahar Abdelnabi, Kai Greshake, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. https://doi.org/10.1145/3605764.3623985 Not what you've signed up for: Compromising real-world llm-integrated applications with indirect prompt injection . In Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security, AISec 2023, Cope...
-
[2]
Abhinav and Contributors. 2026. OpenClaw Mission Control : AI agent orchestration dashboard. https://github.com/abhi1693/openclaw-mission-control. Accessed: 2026-05-03
2026
-
[3]
Anthropic . 2026. Claude Code overview. https://code.claude.com/docs/en/overview. Accessed: 2026-05-03
2026
-
[4]
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David A. Wagner. 2024 a . https://doi.org/10.48550/ARXIV.2402.06363 Struq: Defending against prompt injection with structured queries . CoRR, abs/2402.06363
-
[5]
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. 2024 b . https://doi.org/10.48550/ARXIV.2407.12784 Agentpoison: Red-teaming LLM agents via poisoning memory or knowledge bases . CoRR, abs/2407.12784
-
[6]
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tram \` e r. 2025. https://doi.org/10.48550/ARXIV.2503.18813 Defeating prompt injections by design . CoRR, abs/2503.18813
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.18813 2025
-
[7]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer - Kellner, Marc Fischer, and Florian Tram \` e r. 2024. http://papers.nips.cc/paper\_files/paper/2024/hash/97091a5177d8dc64b1da8bf3e1f6fb54-Abstract-Datasets\_and\_Benchmarks\_Track.html Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents . In Advan...
2024
-
[8]
DeepSeek-AI . 2026. DeepSeek-V4 preview release. https://api-docs.deepseek.com/news/news260424. Accessed: 2026-05-23
2026
-
[9]
Bao Gia Doan, Ehsan Abbasnejad, and Damith C. Ranasinghe. 2020. https://doi.org/10.1145/3427228.3427264 Februus: Input purification defense against trojan attacks on deep neural network systems . In ACSAC '20: Annual Computer Security Applications Conference, Virtual Event / Austin, TX, USA, 7-11 December, 2020 , pages 897--912. ACM
-
[10]
HKUDS . 2026. nanobot : The ultra-lightweight personal AI agent. https://github.com/HKUDS/nanobot. Accessed: 2026-05-03
2026
-
[11]
Dennis Jacob, Hend Alzahrani, Zhanhao Hu, Basel Alomair, and David A. Wagner. 2025. https://doi.org/10.1145/3714393.3726501 Promptshield: Deployable detection for prompt injection attacks . In Proceedings of the Fifteenth ACM Conference on Data and Application Security and Privacy, CODASPY 2025, Pittsburgh, PA, USA, June 4-6, 2025 , pages 341--352. ACM
-
[12]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton - Brown, Dor Muhlgay, Noam Rozen, Erez Schwartz, Gal Shachaf, Shai Shalev - Shwartz, Amnon Shashua, and Moshe Tennenholtz. 2022. https://doi.org/10.48550/ARXIV.2205.00445 MRKL systems: A modular, neuro-symbolic architecture t...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.00445 2022
-
[13]
Songyang Liu, Chaozhuo Li, Chenxu Wang, Jinyu Hou, Zejian Chen, Litian Zhang, Zheng Liu, Qiwei Ye, Yiming Hei, Xi Zhang, and Zhongyuan Wang. 2026. https://doi.org/10.48550/ARXIV.2603.24414 Clawkeeper: Comprehensive safety protection for openclaw agents through skills, plugins, and watchers . CoRR, abs/2603.24414
-
[14]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. https://doi.org/10.18653/V1/2023.EMNLP-MAIN.153 G-eval: NLG evaluation using gpt-4 with better human alignment . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023 , pages 2511--2522. Associ...
-
[15]
Qianyu Meng, Yanan Wang, Liyi Chen, Wei Wu, Yihang Li, Wenyuan Jiang, Qimeng Wang, Chengqiang Lu, Yan Gao, Yi Wu, and Yao Hu. 2026. https://doi.org/10.20944/preprints202604.0428.v3 Agent harness for large language model agents: A survey . Preprints
-
[16]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. 2021. https://arxiv.org/abs/2112.09332 Webgpt: Browser-assisted question-answering w...
Pith/arXiv arXiv 2021
-
[17]
OpenAI . 2026 a . Codex : Lightweight coding agent that runs in your terminal. https://github.com/openai/codex. Accessed: 2026-05-03
2026
-
[18]
OpenAI . 2026 b . Introducing GPT-5.4 . https://openai.com/index/introducing-gpt-5-4/. Accessed: 2026-05-21
2026
-
[19]
F \' a bio Perez and Ian Ribeiro. 2022. https://doi.org/10.48550/ARXIV.2211.09527 Ignore previous prompt: Attack techniques for language models . CoRR, abs/2211.09527
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.09527 2022
-
[20]
Qwen Team and Data Team, Alibaba Group . 2026. https://github.com/SKYLENAGE-AI/QwenClawBench QwenClawBench : Real-user-distribution benchmark for OpenClaw agents
2026
-
[21]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. 2024. https://openreview.net/forum?id=GEcwtMk1uA Identifying the risks of LM agents with an lm-emulated sandbox . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,...
2024
-
[22]
Timo Schick, Jane Dwivedi - Yu, Roberto Dess \` , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. http://papers.nips.cc/paper\_files/paper/2023/hash/d842425e4bf79ba039352da0f658a906-Abstract-Conference.html Toolformer: Language models can teach themselves to use tools . In Advances in Neural Inform...
2023
-
[23]
David Schmotz, Luca Beurer - Kellner, Sahar Abdelnabi, and Maksym Andriushchenko. 2026. https://doi.org/10.48550/ARXIV.2602.20156 Skill-inject: Measuring agent vulnerability to skill file attacks . CoRR, abs/2602.20156
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.20156 2026
-
[24]
Bolun Wang, Yuanshun Yao, Shawn Shan, Huiying Li, Bimal Viswanath, Haitao Zheng, and Ben Y. Zhao. 2019. https://doi.org/10.1109/SP.2019.00031 Neural cleanse: Identifying and mitigating backdoor attacks in neural networks . In 2019 IEEE Symposium on Security and Privacy, SP 2019, San Francisco, CA, USA, May 19-23, 2019 , pages 707--723. IEEE
-
[25]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. 2024. https://doi.org/10.1007/S11704-024-40231-1 A survey on large language model based autonomous agents . Frontiers Comput. Sci., 18(6):186345
-
[26]
Bowen Wei, Yunbei Zhang, Jinhao Pan, Kai Mei, Xiao Wang, Jihun Hamm, Ziwei Zhu, and Yingqiang Ge. 2026. https://doi.org/10.48550/ARXIV.2604.01438 Clawsafety: "safe" llms, unsafe agents . CoRR, abs/2604.01438
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.01438 2026
-
[27]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. https://openreview.net/forum?id=WE\_vluYUL-X React: Synergizing reasoning and acting in language models . In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net
2023
-
[28]
Bowen Ye, Rang Li, Qibin Yang, Yuanxin Liu, Linli Yao, Hanglong Lv, Zhihui Xie, Chenxin An, Lei Li, Lingpeng Kong, Qi Liu, Zhifang Sui, and Tong Yang. 2026. https://doi.org/10.48550/ARXIV.2604.06132 Claw-eval: Toward trustworthy evaluation of autonomous agents . CoRR, abs/2604.06132
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.06132 2026
-
[29]
Jingwei Yi, Yueqi Xie, Bin Zhu, Keegan Hines, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. 2023. https://doi.org/10.48550/ARXIV.2312.14197 Benchmarking and defending against indirect prompt injection attacks on large language models . CoRR, abs/2312.14197
-
[30]
Z.AI . 2026. GLM-5.1 overview. https://docs.z.ai/guides/llm/glm-5.1. Accessed: 2026-05-21
2026
-
[31]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. https://doi.org/10.18653/V1/2024.FINDINGS-ACL.624 Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents . In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024 , Findings of...
-
[32]
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. 2025. https://openreview.net/forum?id=V4y0CpX4hK Agent security bench (ASB): formalizing and benchmarking attacks and defenses in llm-based agents . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, A...
2025
-
[33]
Tian Zhang, Yiwei Xu, Juan Wang, Keyan Guo, Xiaoyang Xu, Bowen Xiao, Quanlong Guan, Jinlin Fan, Jiawei Liu, Zhiquan Liu, and Hongxin Hu. 2026. https://doi.org/10.48550/ARXIV.2602.22724 Agentsentry: Mitigating indirect prompt injection in LLM agents via temporal causal diagnostics and context purification . CoRR, abs/2602.22724
-
[34]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei - Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. http://papers.nips.cc/paper\_files/paper/2023/hash/91f18a1287b398d378ef22505bf41832-Abstract-Datasets\_and\_Benchmarks.html Judging llm-as-a-judge with mt-bench and chat...
2023
-
[35]
Kaijie Zhu, Xianjun Yang, Jindong Wang, Wenbo Guo, and William Yang Wang. 2025. https://proceedings.mlr.press/v267/zhu25z.html MELON: provable defense against indirect prompt injection attacks in AI agents . In Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 , Proceedings of Machine Learning Re...
2025
-
[36]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[37]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.