Don't Fool Me Twice: Adapting to Adversity in the Wild with Experience-Driven Reasoning
Pith reviewed 2026-06-28 22:09 UTC · model grok-4.3
The pith
Robots can learn online from disturbances by attributing causes via vision-language models and modeling them as spatial behaviors for improved recovery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
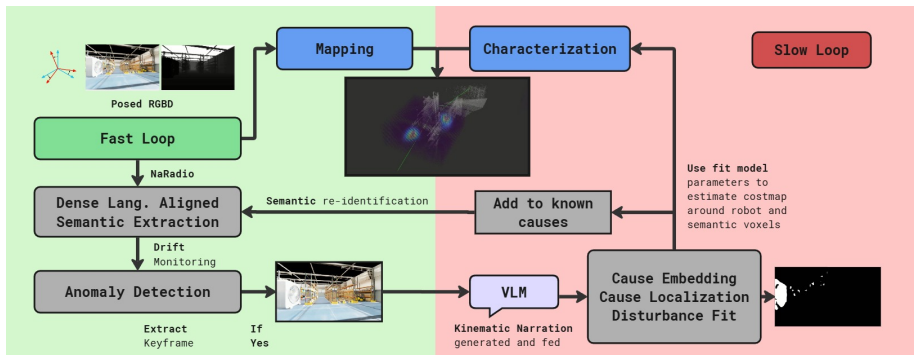
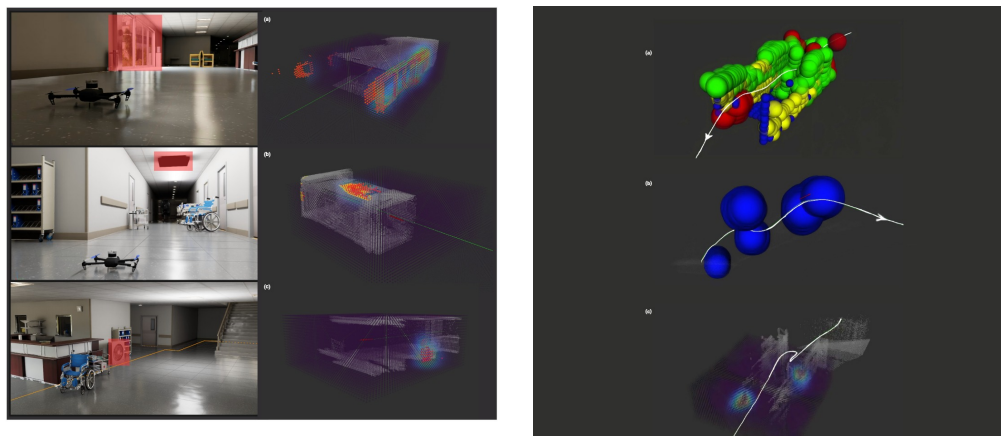
The framework first observes disturbances and describes their effects on the robot; this description is augmented with visual context to query a VLM to predict possible causes; the local disturbance is characterized using kernel regression for efficient few-shot modeling of transient anomalies; semantic voxel-centric modeling estimates epistemic uncertainty to enable richer downstream recovery by treating interaction-driven disturbances as learnable spatial behaviors. This allows the agent to learn online from disturbances and attribute anomalous behaviours to causes through semantics, enabling better prediction and planning of the world in the future.
What carries the argument
The Don't Fool Me Twice framework that combines VLM-based semantic cause attribution from disturbance descriptions and visuals, kernel regression for transient anomaly modeling, and semantic voxel modeling for uncertainty estimation and spatial behavior learning.
If this is right
- Robots achieve improved recovery in unstructured environments by modeling disturbances as learnable spatial behaviors rather than fixed hazards.
- Few-shot kernel regression enables efficient characterization of transient anomalies without requiring large datasets.
- Semantic attribution of causes supports generalization across different robot bodies and interaction types.
- Voxel-based epistemic uncertainty estimation leads to more informed planning that accounts for interaction-driven risks.
Where Pith is reading between the lines
- The method implies that online adaptation after first encounters may outperform exhaustive pre-training on common dangers for novel settings.
- Similar attribution and modeling steps could apply to non-mobile agents facing embodiment-specific anomalies in other domains.
- Limitations may appear when VLM predictions fail for interactions far outside training distributions, suggesting need for fallback mechanisms.
- The framework connects to broader problems of continual learning where semantic explanations of errors drive future behavior changes.
Load-bearing premise
A vision-language model queried with a disturbance description plus visual context can reliably predict embodiment-dependent causes that were not foreseeable in advance.
What would settle it
A test case with a novel disturbance on a new robot embodiment where the VLM attributes an incorrect cause, causing the kernel regression and voxel-based recovery to produce unusable or harmful behaviors.
Figures




read the original abstract
In robotics, dangers and adversity modes are often embodiment-specific and relative to each agent. A frontier of autonomous mobile robotics is to enable agents to operate effectively in the wild in unseen unstructured environments. A significant challenge in unseen unstructured environments is that it may not be possible to predict all the dangers to the specific robot. Although recent work has used large foundation vision-language models (VLMs) to preemptively predict an exhaustive list of common-sense dangers, it remains difficult to capture possible interaction and embodiment-dependent adversities. We propose a continual learning framework for a mobile embodied agent to learn online from disturbances and attribute anomalous behaviours to causes through semantics, enabling better prediction and planning of the world in the future. Our framework, "Don't Fool Me Twice", first observes disturbances and describes their effects on the robot; this description is augmented with visual context to query a VLM to predict possible causes; the local disturbance is characterized using kernel regression, which allows for efficient, few-shot modeling of transient anomalies. We leverage semantic voxel-centric modeling to estimate epistemic uncertainty, enabling richer downstream recovery by treating interaction-driven disturbances as learnable spatial behaviors. We present four hypotheses and validate them in simulation and on hardware across embodiments and adversity modes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
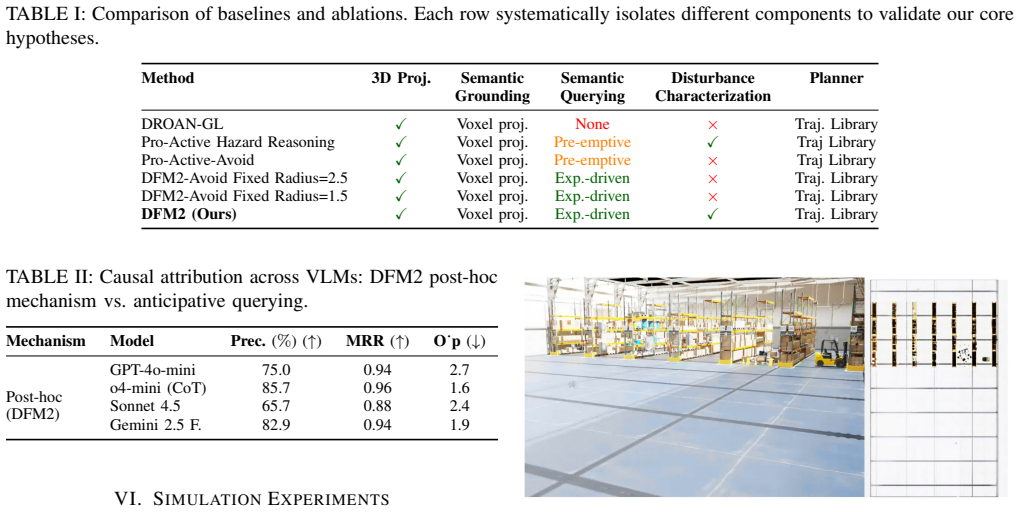
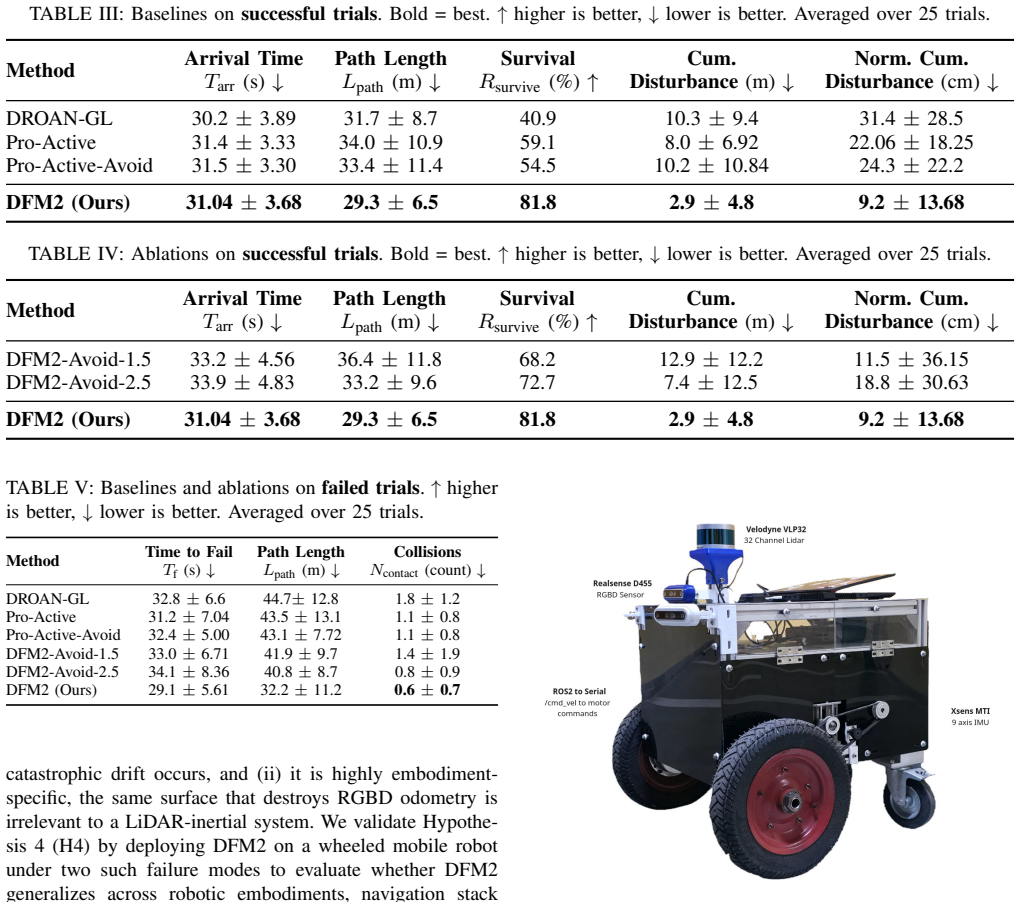
Summary. The manuscript proposes 'Don't Fool Me Twice', a continual learning framework for embodied mobile robots operating in unseen unstructured environments. The approach observes disturbances and their effects on the robot, augments descriptions with visual context to query a VLM for cause attribution, applies kernel regression for few-shot modeling of transient anomalies, and uses semantic voxel-centric modeling to estimate epistemic uncertainty for recovery planning. Four hypotheses are stated and claimed to be validated through simulation and hardware experiments across multiple embodiments and adversity modes, with the goal of enabling improved online prediction and adaptation to embodiment-specific adversities.
Significance. If the empirical claims hold with supporting quantitative evidence, the work would offer a meaningful contribution to robotics by integrating VLMs with few-shot kernel methods and spatial uncertainty modeling for online adaptation to unforeseen, agent-specific disturbances. This addresses a recognized gap in preemptive danger prediction for novel embodiments. No machine-checked proofs, parameter-free derivations, or reproducible code artifacts are highlighted as strengths.
major comments (2)
- [Abstract] Abstract: The central claim that four hypotheses were validated in simulation and on hardware, enabling 'better prediction and planning,' is unsupported by any quantitative results, error bars, sample sizes, exclusion criteria, or performance metrics. This absence makes it impossible to evaluate whether the framework delivers the asserted improvements.
- [Framework description] Framework pipeline (VLM attribution step): The VLM query that takes a disturbance description plus visual context and outputs embodiment-dependent causes is load-bearing, as it directly supplies inputs to the kernel regression and semantic voxel model. No attribution accuracy, failure rates on held-out embodiments, or non-VLM baselines are reported, leaving the reliability of this step unverified despite the abstract's validation claim.
minor comments (2)
- [Abstract] The abstract would benefit from explicitly listing the four hypotheses rather than only stating that they were validated.
- Notation and definitions for the kernel regression and voxel-centric epistemic uncertainty components should be introduced with equations or pseudocode for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas where additional clarity and evidence are needed to support the claims. We address each major comment below and commit to revisions that strengthen the presentation of quantitative results and component evaluations without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that four hypotheses were validated in simulation and on hardware, enabling 'better prediction and planning,' is unsupported by any quantitative results, error bars, sample sizes, exclusion criteria, or performance metrics. This absence makes it impossible to evaluate whether the framework delivers the asserted improvements.
Authors: We acknowledge that the abstract, as a high-level summary, does not include specific quantitative metrics, error bars, or sample sizes. The full manuscript presents experimental validation of the four hypotheses in dedicated sections, including performance metrics across simulation and hardware trials with multiple embodiments. To address this concern directly, we will revise the abstract to incorporate key quantitative findings (e.g., prediction accuracy improvements, recovery success rates, and trial counts) while maintaining its brevity. revision: yes
-
Referee: [Framework description] Framework pipeline (VLM attribution step): The VLM query that takes a disturbance description plus visual context and outputs embodiment-dependent causes is load-bearing, as it directly supplies inputs to the kernel regression and semantic voxel model. No attribution accuracy, failure rates on held-out embodiments, or non-VLM baselines are reported, leaving the reliability of this step unverified despite the abstract's validation claim.
Authors: We agree that the VLM attribution step is central to the pipeline and that its reliability should be explicitly quantified. The current manuscript emphasizes end-to-end framework performance rather than isolating this component. In the revision, we will add a dedicated evaluation of the VLM attribution accuracy, including success/failure rates on held-out embodiments and comparisons against non-VLM baselines (e.g., rule-based or embedding-only alternatives) to verify this step's contribution. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's abstract and description outline a pipeline using VLM-based cause attribution from disturbance descriptions, followed by kernel regression for transient anomalies and semantic voxel modeling for epistemic uncertainty. No equations, fitted parameters, or self-citations are present in the provided text. No load-bearing step reduces a claimed prediction or result to its own inputs by construction, self-definition, or renaming. The framework is presented as self-contained with external validation across embodiments, yielding no evidence of circularity per the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLMs queried with disturbance descriptions plus visual context can predict embodiment-specific causes that were not pre-listed.
- domain assumption Kernel regression can efficiently model transient anomalies from few observations.
Reference graph
Works this paper leans on
-
[1]
M. Labb ´e and F. Michaud, “Rtab-map as an open-source lidar and visual simultaneous localization and mapping library for large- scale and long-term online operation,”Journal of Field Robotics, vol. 36, no. 2, p. 416–446, Oct. 2018. [Online]. Available: http://dx.doi.org/10.1002/rob.21831
-
[2]
C. Campos, R. Elvira, J. J. G. Rodriguez, J. M. M. Montiel, and J. D. Tardos, “Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,”IEEE Transactions on Robotics, vol. 37, no. 6, p. 1874–1890, Dec. 2021. [Online]. Available: http://dx.doi.org/10.1109/TRO.2021.3075644
-
[3]
Mirrordrift: Actuated mirror-based attacks on lidar slam,
R. Nagata, K. Koide, K. Ikeda, O. Sako, S. Horie, and K. Yoshioka, “Mirrordrift: Actuated mirror-based attacks on lidar slam,” 2026. [Online]. Available: https://arxiv.org/abs/2603.11364
-
[4]
Experimental analysis of the behavior of mirror-like objects in lidar-based robot navigation,
D. Damodaran, S. Mozaffari, S. Alirezaee, and M. J. Ahamed, “Experimental analysis of the behavior of mirror-like objects in lidar-based robot navigation,”Applied Sciences, vol. 13, no. 5, 2023. [Online]. Available: https://www.mdpi.com/2076-3417/13/5/2908
2023
-
[5]
Real-time out-of-distribution failure prevention via multi-modal reasoning,
M. Ganai, R. Sinha, C. Agia, D. Morton, and M. Pavone, “Real-time out-of-distribution failure prevention via multi-modal reasoning,”
-
[6]
Available: https://arxiv.org/abs/2505.10547
[Online]. Available: https://arxiv.org/abs/2505.10547
-
[7]
Real-time anomaly detection and reactive planning with large language models,
R. Sinha, A. Elhafsi, C. Agia, M. Foutter, E. Schmerling, and M. Pavone, “Real-time anomaly detection and reactive planning with large language models,” 2024. [Online]. Available: https: //arxiv.org/abs/2407.08735
-
[8]
Language as cost: Proactive hazard mapping using vlm for robot navigation,
M. Oh, C. Kim, S.-W. Seo, and S.-W. Kim, “Language as cost: Proactive hazard mapping using vlm for robot navigation,” 2025. [Online]. Available: https://arxiv.org/abs/2508.03138
-
[9]
V-RoAst: Visual Road Assessment. Can VLM be a Road Safety Assessor Using the iRAP Standard?
N. Jongwiriyanurak, Z. Zeng, J. M. Goo, X. Wang, I. Ilyankou, K. Sriroongvikrai, N. Christie, M. Wang, H. Chen, and J. Haworth, “V-roast: Visual road assessment. can vlm be a road safety assessor using the irap standard?” 2025. [Online]. Available: https://arxiv.org/abs/2408.10872
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
T. Chakraborty, U. Ghosh, A. E. Gongora, R. Glatt, Y . Dong, J. Li, A. K. Roy-Chowdhury, and C. Song, “Toward autonomous laboratory safety monitoring with vision language models: Learning to see hazards through scene structure,” 2026. [Online]. Available: https://arxiv.org/abs/2602.00414
-
[11]
System identification: Theory for the user, 2nd edition (ljung, l.; 1999) [on the shelf],
C. Simpkins, “System identification: Theory for the user, 2nd edition (ljung, l.; 1999) [on the shelf],”Robotics & Automation Magazine, IEEE, vol. 19, pp. 95–96, 06 2012
1999
-
[12]
C. E. Rasmussen and C. K. I. Williams,Gaussian Processes for Machine Learning. The MIT Press, 11 2005. [Online]. Available: https://doi.org/10.7551/mitpress/3206.001.0001
-
[13]
Distributed gaussian processes,
M. P. Deisenroth and J. W. Ng, “Distributed gaussian processes,”
-
[14]
Distributed Gaussian Processes
[Online]. Available: https://arxiv.org/abs/1502.02843
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Robust Gaussian process regression with the trimmed marginal likelihood,
D. Andrade and A. Takeda, “Robust Gaussian process regression with the trimmed marginal likelihood,” inProceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, ser. Proceedings of Machine Learning Research, R. J. Evans and I. Shpitser, Eds., vol
-
[16]
PMLR, 31 Jul–04 Aug 2023, pp. 67–76. [Online]. Available: https://proceedings.mlr.press/v216/andrade23a.html
2023
-
[17]
A. Garbuno-Inigo, F. A. DiazDelaO, and K. M. Zuev, “Gaussian process hyper-parameter estimation using parallel asymptotically independent markov sampling,” 2016. [Online]. Available: https: //arxiv.org/abs/1506.08010
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
Dynamic systems identification with gaussian processes,
J. Kocijan, A. Girard, B. Banko, and R. Murray-Smith, “Dynamic systems identification with gaussian processes,”Mathematical and Computer Modelling of Dynamical Systems, vol. 11, no. 4, pp. 411–424, 2005. [Online]. Available: https://doi.org/10.1080/ 13873950500068567
2005
-
[19]
M. Faessler, A. Franchi, and D. Scaramuzza, “Differential flatness of quadrotor dynamics subject to rotor drag for accurate tracking of high-speed trajectories,”IEEE Robotics and Automation Letters, vol. 3, no. 2, p. 620–626, Apr. 2018. [Online]. Available: http://dx.doi.org/10.1109/LRA.2017.2776353
-
[20]
Gaussian process occupancy maps*,
S. T. O’Callaghan and F. T. Ramos, “Gaussian process occupancy maps*,”The International Journal of Robotics Research, vol. 31, pp. 42 – 62, 2012. [Online]. Available: https://api.semanticscholar.org/ CorpusID:34447821
2012
-
[21]
Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” 2017. [Online]. Available: https://arxiv.org/abs/1703.03400
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Learning to Adapt in Dynamic, Real-World Environments Through Meta-Reinforcement Learning
A. Nagabandi, I. Clavera, S. Liu, R. S. Fearing, P. Abbeel, S. Levine, and C. Finn, “Learning to adapt in dynamic, real-world environments through meta-reinforcement learning,” 2019. [Online]. Available: https://arxiv.org/abs/1803.11347
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Y . Long, K. Chen, L. Jin, and M. Shang, “Drae: Dynamic retrieval- augmented expert networks for lifelong learning and task adaptation in robotics,” 2025. [Online]. Available: https://arxiv.org/abs/2507.04661
-
[24]
Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration,
O. Alama, A. Bhattacharya, H. He, S. Kim, Y . Qiu, W. Wang, C. Ho, N. Keetha, and S. Scherer, “Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration,” 2025. [Online]. Available: https://arxiv.org/abs/2504.06994
-
[25]
Openvdb: an open-source data structure and toolkit for high-resolution volumes,
K. Museth, J. Lait, J. Johanson, J. Budsberg, R. Henderson, M. Alden, P. Cucka, D. Hill, and A. Pearce, “Openvdb: an open-source data structure and toolkit for high-resolution volumes,” inACM SIGGRAPH 2013 Courses, ser. SIGGRAPH ’13. New York, NY , USA: Association for Computing Machinery, 2013. [Online]. Available: https://doi.org/10.1145/2504435.2504454
-
[26]
Am-radio: Agglomerative vision foundation model – reduce all domains into one,
M. Ranzinger, G. Heinrich, J. Kautz, and P. Molchanov, “Am-radio: Agglomerative vision foundation model – reduce all domains into one,” 2024. [Online]. Available: https://arxiv.org/abs/2312.06709
-
[27]
Sigmoid Loss for Language Image Pre-Training
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” 2023. [Online]. Available: https://arxiv.org/abs/2303.15343
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Salon: Self-supervised adaptive learning for off-road navigation,
M. Sivaprakasam, S. Triest, C. Ho, S. Aich, J. Lew, I. Adu, W. Wang, and S. Scherer, “Salon: Self-supervised adaptive learning for off-road navigation,” 2024. [Online]. Available: https://arxiv.org/ abs/2412.07826
-
[29]
On the limited memory bfgs method for large scale optimization,
D. C. Liu and J. Nocedal, “On the limited memory bfgs method for large scale optimization,”Mathematical programming, vol. 45, no. 1, pp. 503–528, 1989
1989
-
[30]
Droan - disparity-space representation for obstacle avoidance: Enabling wire mapping & avoidance,
G. Dubey, R. Madaan, and S. Scherer, “Droan - disparity-space representation for obstacle avoidance: Enabling wire mapping & avoidance,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE Press, 2018, p. 6311–6318. [Online]. Available: https://doi.org/10.1109/IROS.2018.8593499
-
[31]
Isaac Sim
NVIDIA, “Isaac Sim.” [Online]. Available: https://github.com/ isaac-sim/IsaacSim
-
[32]
Pegasus simulator: An isaac sim framework for multiple aerial vehicles simulation,
M. Jacinto, J. Pinto, J. Patrikar, J. Keller, R. Cunha, S. Scherer, and A. Pascoal, “Pegasus simulator: An isaac sim framework for multiple aerial vehicles simulation,” in2024 International Conference on Unmanned Aircraft Systems (ICUAS). IEEE, 2024, p. 917–922. [Online]. Available: http://dx.doi.org/10.1109/ICUAS60882. 2024.10556959
-
[33]
Px4: A node-based multithreaded open source robotics framework for deeply embedded platforms,
L. Meier, D. Honegger, and M. Pollefeys, “Px4: A node-based multithreaded open source robotics framework for deeply embedded platforms,” in2015 IEEE International Conference on Robotics and Automation (ICRA), 2015, pp. 6235–6240
2015
-
[34]
The dynamic window approach to collision avoidance,
D. Fox, W. Burgard, and S. Thrun, “The dynamic window approach to collision avoidance,”IEEE Robotics & Automation Magazine, vol. 4, no. 1, pp. 23–33, 1997
1997
-
[35]
Artificial potential field based path planning for mobile robots using a virtual obstacle concept,
M. C. Lee and M. G. Park, “Artificial potential field based path planning for mobile robots using a virtual obstacle concept,” in Proceedings 2003 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM 2003), vol. 2, 2003, pp. 735–740 vol.2
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.