SpatialAct: Probing Spatial Reasoning-to-Action Capabilities of VLM Agents in 3D Scenes
Pith reviewed 2026-06-28 22:46 UTC · model grok-4.3
The pith
Current VLMs perform well on isolated spatial tasks but fail to maintain coherent beliefs and reliable actions across multi-turn feedback in 3D scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
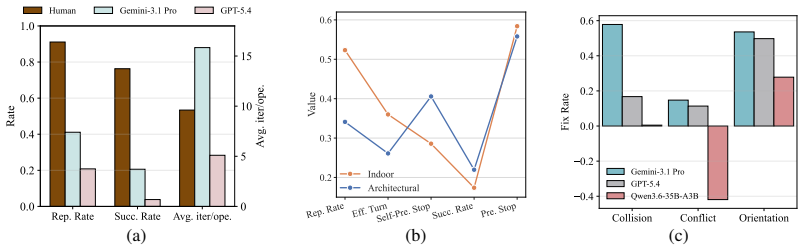
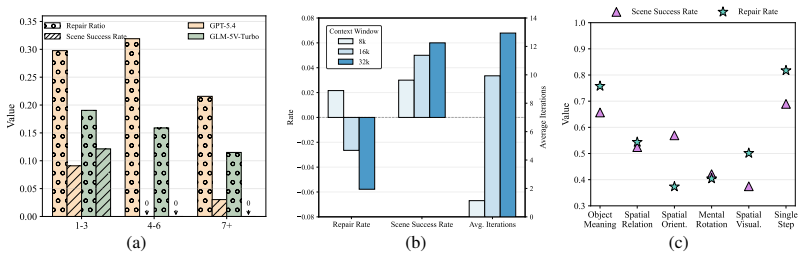
Current VLMs can perform well on isolated spatial reasoning tasks, but struggle to maintain coherent spatial beliefs and produce reliable actions during multi-turn feedback, substantially underperforming humans, because they lack robust spatial state tracking under action-induced environment changes.
What carries the argument
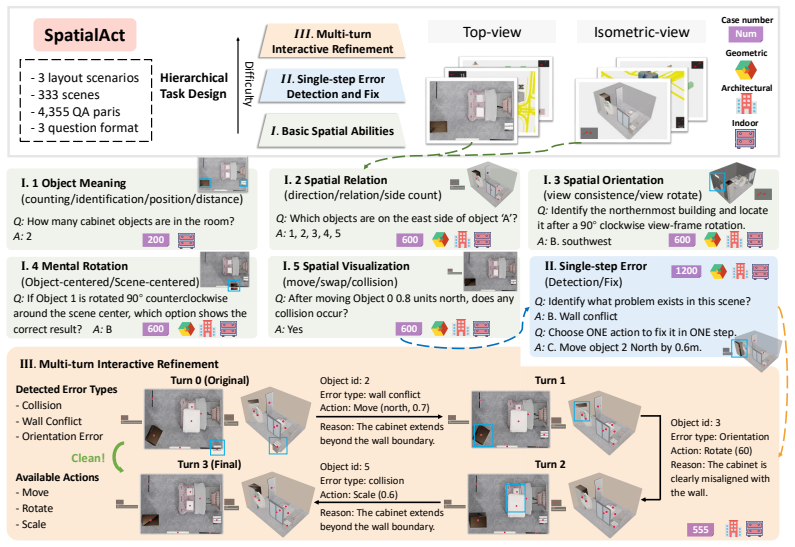
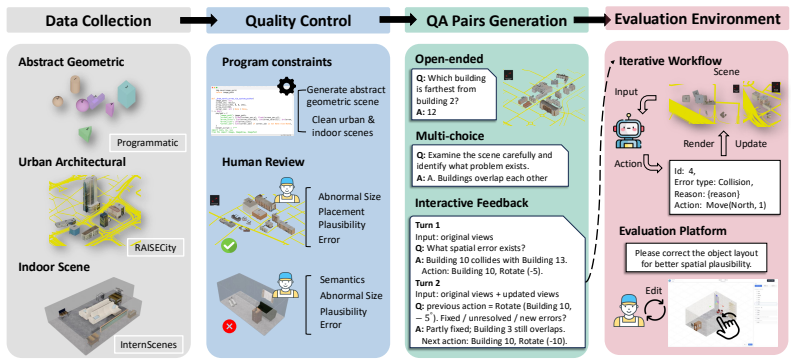
SpatialAct benchmark consisting of Multi-turn Interactive Refinement, its Single-step Error Detection and Fix decomposition, and five fundamental spatial ability tasks.
If this is right
- VLMs lack the ability to update spatial representations consistently when their own actions alter the scene.
- Decomposing multi-turn tasks into error detection steps still reveals failures in belief maintenance.
- The gap appears even when low-level motor control is abstracted away from the agent.
- Isolated spatial perception benchmarks overestimate real agent capabilities in interactive 3D settings.
Where Pith is reading between the lines
- Models may need explicit mechanisms to remember and update 3D layouts across turns rather than relying on current observations alone.
- Extending the benchmark to longer sequences could expose whether the gap grows with horizon length.
- Training objectives that reward state tracking consistency might close the gap more effectively than scale alone.
Load-bearing premise
The designed tasks isolate the reasoning-to-action gap without interference from simulator details, prompt wording, or task choices.
What would settle it
A VLM reaching human-level scores on the multi-turn interactive refinement task while keeping the same benchmark setup and prompts would falsify the reported gap.
Figures

read the original abstract
Humans can effortlessly perceive spatial layouts, form cognitive representations, reason about spatial relations, and translate such reasoning into actions in everyday 3D environments. Although recent vision-language models (VLMs) have shown promising performance on observation-conditioned spatial perception and reasoning tasks, it remains unclear whether they can build coherent spatial understanding, act upon it, and refine their actions through multi-turn feedback. To study this problem, we introduce \textbf{SpatialAct}, a simulator-grounded benchmark for probing \textit{action-conditioned spatial reasoning} in 3D scenes. Starting from the most challenging setting, Multi-turn Interactive Refinement, we further design its decomposed counterpart, Single-step Error Detection and Fix, together with five fundamental spatial ability tasks to diagnose the underlying causes of model failures. Experiments reveal a clear reasoning-to-action gap: current VLMs can perform well on isolated spatial reasoning tasks, but struggle to maintain coherent spatial beliefs and produce reliable actions during multi-turn feedback, substantially underperforming humans. These results suggest that current VLM agents still lack robust spatial state tracking under action-induced environment changes, even when low-level control is abstracted away.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpatialAct, a simulator-grounded benchmark for evaluating vision-language models (VLMs) on action-conditioned spatial reasoning in 3D scenes. It defines a Multi-turn Interactive Refinement task, its Single-step Error Detection and Fix decomposition, and five fundamental spatial ability tasks. Experiments show that current VLMs perform adequately on isolated spatial reasoning but struggle to maintain coherent spatial beliefs and produce reliable actions under multi-turn feedback, substantially underperforming humans, pointing to deficiencies in spatial state tracking when environments change due to actions.
Significance. If the results hold after addressing controls, the benchmark provides a useful diagnostic for a key limitation in VLM agents for embodied AI, distinguishing isolated perception/reasoning from integrated state tracking under feedback. The decomposed task structure enables targeted analysis of failure modes, which could guide improvements in spatial reasoning for robotics and interactive agents.
major comments (2)
- [§3] §3 (Benchmark Design), Multi-turn Interactive Refinement task: the central claim that failures are due to inability to maintain coherent spatial beliefs requires explicit controls or ablations showing that simulator state updates, feedback presentation format, and prompt phrasing do not introduce systematic artifacts; without these, the human-VLM gap cannot be confidently attributed to state-tracking deficits rather than task confounds.
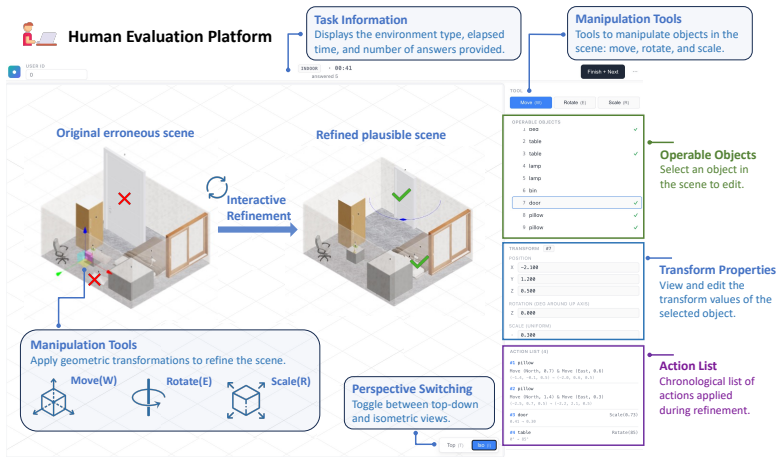
- [§4] §4 (Experiments), human baseline comparison: the reported human-model performance gap is load-bearing for the 'substantially underperforming humans' conclusion, but the manuscript provides no details on human task interface, number of participants, or whether humans received identical feedback modalities and prompt structures as the VLMs.
minor comments (2)
- The abstract and introduction could more precisely state the number of VLMs evaluated and the exact metrics used for 'reliable actions' to improve reproducibility.
- Figure captions for task visualizations should explicitly note any rendering parameters or abstraction levels in the simulator to aid reader interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, agreeing that both require additions to the manuscript to support the central claims.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Design), Multi-turn Interactive Refinement task: the central claim that failures are due to inability to maintain coherent spatial beliefs requires explicit controls or ablations showing that simulator state updates, feedback presentation format, and prompt phrasing do not introduce systematic artifacts; without these, the human-VLM gap cannot be confidently attributed to state-tracking deficits rather than task confounds.
Authors: We agree that the manuscript currently lacks explicit ablations for these potential confounds. In revision we will add a dedicated controls subsection to §3 that reports: (1) verification that simulator state updates are deterministic and consistent across turns, (2) ablations on feedback presentation (text-only vs. image-augmented), and (3) prompt-phrasing variants (rephrased instructions while preserving semantics). Results will show that the VLM-human gap persists under these variations, allowing stronger attribution to state-tracking deficits. revision: yes
-
Referee: [§4] §4 (Experiments), human baseline comparison: the reported human-model performance gap is load-bearing for the 'substantially underperforming humans' conclusion, but the manuscript provides no details on human task interface, number of participants, or whether humans received identical feedback modalities and prompt structures as the VLMs.
Authors: We acknowledge the omission of human-baseline protocol details. The revised §4 will include: participant count (15), recruitment criteria, web-based interface description that mirrors the VLM visual and textual feedback exactly, and explicit statement that humans received identical prompt structures and multi-turn feedback modalities. We will also report inter-rater agreement to validate the baseline reliability. revision: yes
Circularity Check
No circularity: empirical benchmark study
full rationale
This is an empirical benchmark paper that introduces SpatialAct tasks (Multi-turn Interactive Refinement, Single-step Error Detection and Fix, and five spatial ability tasks) and reports model performance gaps versus humans. No derivation chain, equations, fitted parameters, or predictions exist in the provided text. Claims rest on direct experimental results from the defined simulator-grounded tasks rather than reducing to self-citations, ansatzes, or input definitions by construction. The central reasoning-to-action gap finding is an observed outcome, not a tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Placeit3d: Language-guided object placement in real 3d scenes
Ahmed Abdelreheem, Filippo Aleotti, Jamie Watson, Zawar Qureshi, Abdelrahman Eldesokey, Peter Wonka, Gabriel Brostow, Sara Vicente, and Guillermo Garcia-Hernando. Placeit3d: Language-guided object placement in real 3d scenes. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 6645–6655, 2025
2025
-
[2]
Gemini-3.1 pro
Google DeepMind. Gemini-3.1 pro. https://deepmind.google/models/model-cards /gemini-3-1-pro/, 2026
2026
-
[3]
Scanedit: Hierarchically-guided functional 3d scan editing
Mohamed El Amine Boudjoghra, Ivan Laptev, and Angela Dai. Scanedit: Hierarchically-guided functional 3d scan editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27105–27115, 2025
2025
-
[4]
Repurposing 3D Generative Model for Autoregressive Layout Generation
Haoran Feng, Yifan Niu, Zehuan Huang, Yang-Tian Sun, Chunchao Guo, Yuxin Peng, and Lu Sheng. Repurposing 3d generative model for autoregressive layout generation.arXiv preprint arXiv:2604.16299, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Layoutgpt: Compositional visual planning and generation with large language models.Advances in Neural Information Processing Systems, 36:18225–18250, 2023
Weixi Feng, Wanrong Zhu, Tsu-jui Fu, Varun Jampani, Arjun Akula, Xuehai He, Sugato Basu, Xin Eric Wang, and William Yang Wang. Layoutgpt: Compositional visual planning and generation with large language models.Advances in Neural Information Processing Systems, 36:18225–18250, 2023
2023
-
[6]
GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents
Wenyi Hong, Xiaotao Gu, Ziyang Pan, Zhen Yang, Yuting Wang, Yue Wang, Yuanchang Yue, Yu Wang, Yanling Wang, Yan Wang, et al. Glm-5v-turbo: Toward a native foundation model for multimodal agents.arXiv preprint arXiv:2604.26752, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Fireplace: Geometric refinements of llm common sense reasoning for 3d object placement
Ian Huang, Yanan Bao, Karen Truong, Howard Zhou, Cordelia Schmid, Leonidas Guibas, and Alireza Fathi. Fireplace: Geometric refinements of llm common sense reasoning for 3d object placement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13466–13476, 2025
2025
-
[8]
Xinmiao Huang, Qisong He, Zhenglin Huang, Boxuan Wang, Zhuoyun Li, Guangliang Cheng, Yi Dong, and Xiaowei Huang. Spatial-dise: A unified benchmark for evaluating spatial reasoning in vision-language models.arXiv preprint arXiv:2510.13394, 2025
-
[9]
Do you see me: A multidimensional benchmark for evaluating visual perception in multimodal llms
Aditya Sanjiv Kanade and Tanuja Ganu. Do you see me: A multidimensional benchmark for evaluating visual perception in multimodal llms. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7285–7326, 2026
2026
-
[10]
Dingming Li, Hongxing Li, Zixuan Wang, Yuchen Yan, Hang Zhang, Siqi Chen, Guiyang Hou, Shengpei Jiang, Wenqi Zhang, Yongliang Shen, et al. Viewspatial-bench: Evaluating multi- perspective spatial localization in vision-language models.arXiv preprint arXiv:2505.21500, 2025
-
[11]
Embodied agent interface: Benchmarking llms for embodied decision making
Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Yu Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Li Li, Ruohan Zhang, Weiyu Liu, Percy Liang, Li Fei-Fei, Jiayuan Mao, and Jiajun Wu. Embodied agent interface: Benchmarking llms for embodied decision making. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, A...
2024
-
[12]
Core knowledge deficits in multi- modal language models.arXiv preprint arXiv:2410.10855, 2024
Yijiang Li, Qingying Gao, Tianwei Zhao, Bingyang Wang, Haoran Sun, Haiyun Lyu, Robert D Hawkins, Nuno Vasconcelos, Tal Golan, Dezhi Luo, et al. Core knowledge deficits in multi- modal language models.arXiv preprint arXiv:2410.10855, 2024
arXiv 2024
-
[13]
Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods
Weichen Liu, Qiyao Xue, Haoming Wang, Xiangyu Yin, Boyuan Yang, and Wei Gao. Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods. arXiv preprint arXiv:2511.15722, 2025
arXiv 2025
-
[14]
Openeqa: Embodied question answering in the era of foundation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, et al. Openeqa: Embodied question answering in the era of foundation models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16488–16498, 2024. 12
2024
-
[15]
Gpt-5.4.https://openai.com/index/introducing-gpt-5-4/, 2026
OpenAI. Gpt-5.4.https://openai.com/index/introducing-gpt-5-4/, 2026
2026
-
[16]
Qwen3.6-27B: Flagship-level coding in a 27B dense model, April 2026
Qwen Team. Qwen3.6-27B: Flagship-level coding in a 27B dense model, April 2026
2026
-
[17]
Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026
Qwen Team. Qwen3.6-35B-A3B: Agentic coding power, now open to all, April 2026
2026
-
[18]
Pooyan Rahmanzadehgervi, Logan Bolton, Mohammad Reza Taesiri, and Anh Totti Nguyen. Vision language models are blind: Failing to translate detailed visual features into words.arXiv preprint arXiv:2407.06581, 2024
-
[19]
Does spatial cognition emerge in frontier models?arXiv preprint arXiv:2410.06468, 2024
Santhosh Kumar Ramakrishnan, Erik Wijmans, Philipp Kraehenbuehl, and Vladlen Koltun. Does spatial cognition emerge in frontier models?arXiv preprint arXiv:2410.06468, 2024
arXiv 2024
-
[20]
Layoutvlm: Differentiable optimization of 3d layout via vision- language models
Fan-Yun Sun, Weiyu Liu, Siyi Gu, Dylan Lim, Goutam Bhat, Federico Tombari, Manling Li, Nick Haber, and Jiajun Wu. Layoutvlm: Differentiable optimization of 3d layout via vision- language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29469–29478, 2025
2025
-
[21]
Spacevista: All-scale visual spatial reasoning from mm to km.arXiv preprint arXiv:2510.09606, 2025
Peiwen Sun, Shiqiang Lang, Dongming Wu, Yi Ding, Kaituo Feng, Huadai Liu, Zhen Ye, Rui Liu, Yun-Hui Liu, Jianan Wang, et al. Spacevista: All-scale visual spatial reasoning from mm to km.arXiv preprint arXiv:2510.09606, 2025
Pith/arXiv arXiv 2025
-
[22]
Kimi k2.5: Visual agentic intelligence, 2026
Kimi Team and et al. Kimi k2.5: Visual agentic intelligence, 2026
2026
-
[23]
Is a picture worth a thousand words? delving into spatial reasoning for vision language models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Yixuan Li, and Neel Joshi. Is a picture worth a thousand words? delving into spatial reasoning for vision language models. Advances in Neural Information Processing Systems, 37:75392–75421, 2024
2024
-
[24]
Shengyuan Wang, Zhiheng Zheng, Yu Shang, Lixuan He, Yangcheng Yu, Fan Hangyu, Jie Feng, Qingmin Liao, and Yong Li. Raisecity: A multimodal agent framework for reality-aligned 3d world generation at city-scale.arXiv preprint arXiv:2511.18005, 2025
-
[25]
Embodied scene understanding for vision language models via metavqa
Weizhen Wang, Chenda Duan, Zhenghao Peng, Yuxin Liu, and Bolei Zhou. Embodied scene understanding for vision language models via metavqa. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22453–22464, 2025
2025
-
[26]
Site: towards spatial intelligence thorough evaluation
Wenqi Wang, Reuben Tan, Pengyue Zhu, Jianwei Yang, Zhengyuan Yang, Lijuan Wang, Andrey Kolobov, Jianfeng Gao, and Boqing Gong. Site: towards spatial intelligence thorough evaluation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9058–9069, 2025
2025
-
[27]
Spatial457: A diagnostic benchmark for 6d spatial reasoning of large mutimodal models
Xingrui Wang, Wufei Ma, Tiezheng Zhang, Celso M de Melo, Jieneng Chen, and Alan Yuille. Spatial457: A diagnostic benchmark for 6d spatial reasoning of large mutimodal models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 24669–24679, 2025
2025
-
[28]
Visual room rearrange- ment
Luca Weihs, Matt Deitke, Aniruddha Kembhavi, and Roozbeh Mottaghi. Visual room rearrange- ment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5922–5931, 2021
2021
-
[29]
Spatialtree : How spatial abilities branch out in MLLMs
Yuxi Xiao, Longfei Li, Shen Yan, Xinhang Liu, Sida Peng, Yunchao Wei, Xiaowei Zhou, and Bingyi Kang. Spatialtree : How spatial abilities branch out in MLLMs. InThe First Workshop on Efficient Spatial Reasoning, 2026
2026
-
[30]
Haotian Xu, Yue Hu, Zhengqiu Zhu, Chen Gao, Ziyou Wang, Junreng Rao, Wenhao Lu, Weishi Li, Quanjun Yin, and Yong Li. Citycube: Benchmarking cross-view spatial reasoning on vision-language models in urban environments.arXiv preprint arXiv:2601.14339, 2026
-
[31]
Defining and evaluating visual language models’ basic spatial abilities: A perspective from psychometrics
Wenrui Xu, Dalin Lyu, Weihang Wang, Jie Feng, Chen Gao, and Yong Li. Defining and evaluating visual language models’ basic spatial abilities: A perspective from psychometrics. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11571–11590, 2025. 13
2025
-
[32]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[33]
Holodeck: Language guided generation of 3d embodied ai environments
Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, et al. Holodeck: Language guided generation of 3d embodied ai environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16227–16237, 2024
2024
-
[34]
Spatial mental modeling from limited views
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, et al. Spatial mental modeling from limited views. InStructural Priors for Vision Workshop at ICCV’25, 2025
2025
-
[35]
Songsong Yu, Yuxin Chen, Hao Ju, Lianjie Jia, Fuxi Zhang, Shaofei Huang, Yuhan Wu, Rundi Cui, Binghao Ran, Zaibin Zhang, et al. How far are vlms from visual spatial intelligence? a benchmark-driven perspective.arXiv preprint arXiv:2509.18905, 2025
-
[36]
Et-plan- bench: Embodied task-level planning benchmark towards spatial-temporal cognition with foundation models
Lingfeng Zhang, Yuening Wang, Hongjian Gu, Atia Hamidizadeh, Zhanguang Zhang, Yuecheng Liu, Yutong Wang, David Gamaliel Arcos Bravo, Junyi Dong, Shunbo Zhou, et al. Et-plan- bench: Embodied task-level planning benchmark towards spatial-temporal cognition with foundation models. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IR...
2025
-
[37]
Theory of space: Can foundation models construct spatial beliefs through active exploration? InThe Fourteenth International Conference on Learning Representations, 2026
Pingyue Zhang, Zihan Huang, Yue Wang, Jieyu Zhang, Letian Xue, Zihan Wang, Qineng Wang, Keshigeyan Chandrasegaran, Ruohan Zhang, Yejin Choi, et al. Theory of space: Can foundation models construct spatial beliefs through active exploration? InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[38]
SPHERE: Unveiling spatial blind spots in vision-language models through hierarchical evaluation
Wenyu Zhang, Wei En Ng, Lixin Ma, Yuwen Wang, Junqi Zhao, Allison Koenecke, Boyang Li, and Lu Wang. SPHERE: Unveiling spatial blind spots in vision-language models through hierarchical evaluation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11591–11609, Vienna, Austria, July
-
[39]
Association for Computational Linguistics
-
[40]
Cityeqa: A hierarchical llm agent on embodied question answering benchmark in city space
Yong Zhao, Kai Xu, Zhengqiu Zhu, Yue Hu, Zhiheng Zheng, Yingfeng Chen, Yatai Ji, Chen Gao, Yong Li, and Jincai Huang. Cityeqa: A hierarchical llm agent on embodied question answering benchmark in city space. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12476–12491, 2025
2025
-
[41]
Haoyu Zhen, Xiaolong Li, Yilin Zhao, Han Zhang, Sifei Liu, Kaichun Mo, Chuang Gan, and Subhashree Radhakrishnan. 3d-layout-r1: Structured reasoning for language-instructed spatial editing.arXiv preprint arXiv:2603.22279, 2026
-
[42]
InternScenes: A Large-scale Simulatable Indoor Scene Dataset with Realistic Layouts
Weipeng Zhong, Peizhou Cao, Yichen Jin, Li Luo, Wenzhe Cai, Jingli Lin, Hanqing Wang, Zhaoyang Lyu, Tai Wang, Bo Dai, et al. Internscenes: A large-scale simulatable indoor scene dataset with realistic layouts.arXiv preprint arXiv:2509.10813, 2025. 14 A Appendix A.1 Discussion and Future Work Our results reveal persistent challenges in multi-turn reasoning...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.