ERGeoBench:A Comprehensive Benchmark for Embodied Reasoning and Geo-localization in Multimodal Large Language Models
Pith reviewed 2026-06-28 22:58 UTC · model grok-4.3
The pith
Multimodal models infer high-level geographic semantics but struggle with fine-grained perceptual operations, metric localization, and spatial consistency across views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ERGeoBench shows that current MLLMs succeed at high-level geographic semantics but fail at fine-grained perceptual operations, metric localization, and spatial consistency across views, with geo-localization performance strongly correlated to the other three capability dimensions and therefore dependent on integrated perception, spatial reasoning, and commonsense inference rather than isolated visual recognition.
What carries the argument
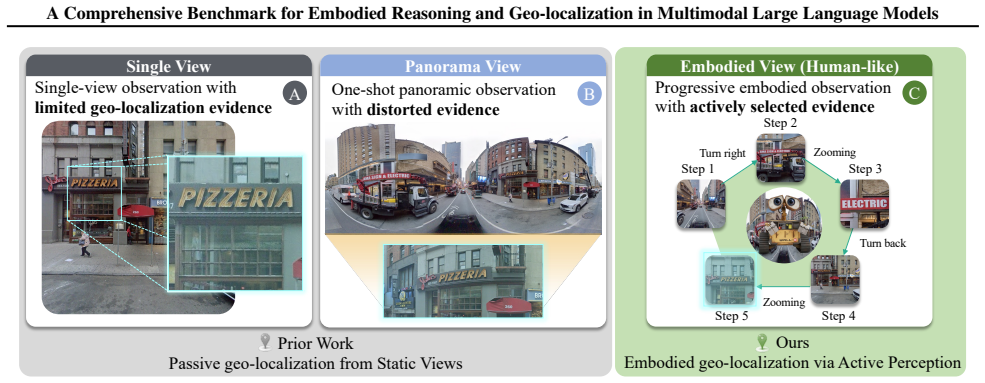
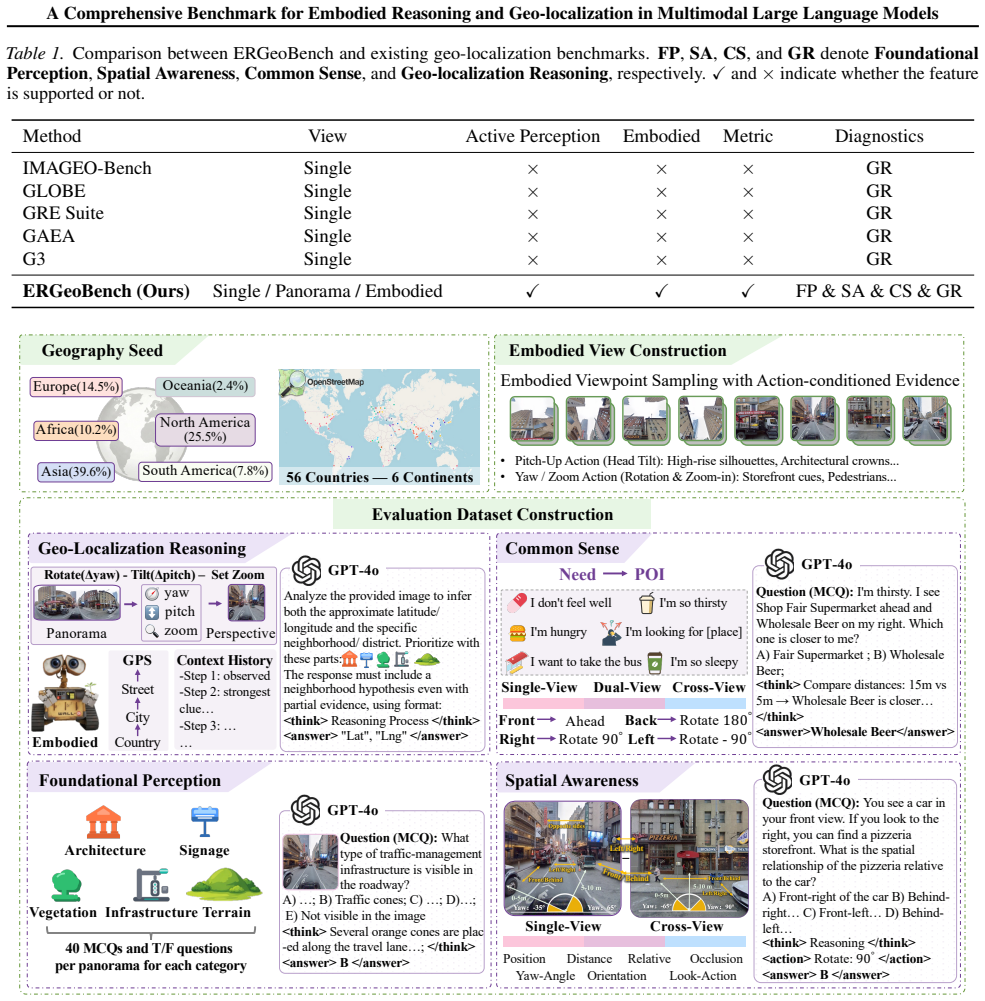
ERGeoBench benchmark that evaluates models on four complementary capabilities under three progressive viewing settings using 2,207 panoramas where agents can acquire sequential observations.
If this is right
- Accurate geo-localization in MLLMs requires combining perception, spatial awareness, and commonsense reasoning instead of relying on any single dimension.
- Embodied agents benefit from the ability to actively acquire sequential observations through yaw, pitch, and zoom adjustments.
- Models that perform well on the benchmark's four dimensions are more likely to support human-like navigation tasks.
- The three viewing settings expose gaps in spatial consistency that single static images do not reveal.
Where Pith is reading between the lines
- Models trained with explicit multi-view consistency objectives may close the observed performance gaps on embodied tasks.
- The benchmark could be extended to test whether the same capability correlations appear in dynamic video streams or real robot deployments.
- Success on ERGeoBench may predict performance on other spatial reasoning problems that require integrating semantics with metric judgments.
Load-bearing premise
The 2,207 globally distributed panoramas and the four capability dimensions together with the three viewing settings provide a faithful and unbiased proxy for real-world embodied geo-localization challenges without systematic selection bias in scene types or question phrasing.
What would settle it
A follow-up evaluation in which leading MLLMs achieve high accuracy on metric localization and maintain spatial consistency across views while showing no correlation with the other capability dimensions would falsify the central claim.
Figures

read the original abstract
Multimodal large language models (MLLMs) have shown strong potential as embodied agents, yet embodied geo-localization remains underexplored due to the lack of fine-grained evaluation. We introduce ERGeoBench, a diagnostic benchmark for vision-driven embodied geo-localization. ERGeoBench evaluates models under three progressive settings -- single-view, panorama-view, and embodied-view -- where agents may actively acquire observations through sequential changes in yaw, pitch, and zoom. The benchmark contains 2,207 globally distributed street-view panoramas and measures four complementary capabilities: foundational perception, spatial awareness, common sense reasoning, and geo-localization reasoning. Evaluations of leading proprietary and open-source MLLMs show that current models can infer high-level geographic semantics, but still struggle with fine-grained perceptual operations, metric localization, and spatial consistency across views. We further observe that geo-localization is strongly correlated with the other capability dimensions, suggesting that accurate localization depends on integrated perception, spatial reasoning, and commonsense inference rather than isolated visual recognition. Overall, ERGeoBench provides a unified framework for diagnosing and advancing human-like embodied geo-localization. Project Page: https://kaixuewen.github.io/ERGeoBench/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ERGeoBench, a benchmark with 2,207 globally distributed street-view panoramas for evaluating MLLMs on embodied geo-localization. Models are tested under three progressive settings (single-view, panorama-view, embodied-view) across four capability dimensions: foundational perception, spatial awareness, common sense reasoning, and geo-localization reasoning. Evaluations of proprietary and open-source models indicate strong performance on high-level geographic semantics but weaknesses in fine-grained perception, metric localization, and cross-view consistency. A correlation is reported between geo-localization accuracy and the other dimensions, suggesting integrated capabilities are required.
Significance. If the empirical results hold, ERGeoBench offers a diagnostic framework that isolates specific failure modes in current MLLMs for embodied tasks, moving beyond static image benchmarks. The active observation setting and multi-dimensional design could inform targeted improvements in spatial reasoning modules. The correlation finding, if robust, supports joint modeling approaches over isolated skill training.
major comments (2)
- [Evaluation] Evaluation methodology: the definitions of the scoring metrics for each of the four capability dimensions, the exact annotation protocol, and any inter-annotator agreement statistics are not provided. This directly affects the reproducibility and strength of the central claims about model limitations and the observed correlation.
- [Results] Results section: no statistical tests, confidence intervals, or variance estimates are reported for the performance differences across models, settings, or capability dimensions. This leaves the reported gaps and correlation observation only moderately supported.
minor comments (2)
- [Abstract] The abstract would benefit from stating the number of models evaluated.
- [Benchmark Construction] Clarify in the benchmark construction how question phrasing was controlled to avoid bias across the four dimensions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects for improving the reproducibility and statistical rigor of ERGeoBench. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation methodology: the definitions of the scoring metrics for each of the four capability dimensions, the exact annotation protocol, and any inter-annotator agreement statistics are not provided. This directly affects the reproducibility and strength of the central claims about model limitations and the observed correlation.
Authors: We agree that these details are essential for reproducibility. The original manuscript provided high-level descriptions of the four capability dimensions and the three settings but did not include explicit metric formulas, full annotation guidelines, or inter-annotator agreement numbers. In the revised version we will add a new subsection (likely Section 3.3) that (i) defines each scoring metric with precise formulas and example annotations, (ii) details the annotation protocol including how questions were generated and verified, and (iii) reports inter-annotator agreement statistics (e.g., percentage agreement and Cohen’s kappa) computed on a held-out subset of the 2,207 panoramas. These additions will directly support the claims about model limitations and the correlation analysis. revision: yes
-
Referee: [Results] Results section: no statistical tests, confidence intervals, or variance estimates are reported for the performance differences across models, settings, or capability dimensions. This leaves the reported gaps and correlation observation only moderately supported.
Authors: We acknowledge the absence of statistical support. The current results report raw accuracies and a single correlation coefficient without error bars or significance tests. In the revision we will (i) add bootstrap-derived 95% confidence intervals for all reported accuracies, (ii) include standard errors or variance estimates across the three settings, and (iii) perform and report appropriate statistical tests (e.g., McNemar’s test for paired model comparisons and Pearson correlation with p-values and confidence intervals). These changes will provide stronger quantitative backing for the observed gaps and the correlation finding. revision: yes
Circularity Check
No significant circularity in empirical benchmark construction
full rationale
The paper introduces ERGeoBench as an empirical evaluation framework consisting of 2,207 panoramas evaluated under three viewing settings across four capability dimensions. No mathematical derivations, parameter fittings, predictions derived from fitted inputs, or load-bearing self-citations are present. All claims rest on direct model evaluations against the constructed benchmark data, which is externally verifiable and independent of any internal reduction to the paper's own inputs. This is a standard benchmark paper with no derivation chain to inspect for circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three progressive viewing settings (single-view, panorama-view, embodied-view) and the four capability dimensions faithfully represent the requirements of embodied geo-localization.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025a. Bai, S. et al. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Bai, S. et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025b. Caesar, H., Bankiti, V ., Lang, A. H., V ora, S., Liong, V . E., Xu, Q., Krishnan, A., Pan, Y ., Baldan, G., and Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11621–11631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
P., Gupta, R., Dutta, A., and Shah, M
9 A Comprehensive Benchmark for Embodied Reasoning and Geo-localization in Multimodal Large Language Models Campos, R., Vayani, A., Kulkarni, P. P., Gupta, R., Dutta, A., and Shah, M. Gaea: A geolocation aware conversational model.arXiv preprint arXiv:2503.16423,
-
[4]
Chen, Z. et al. Expanding performance boundaries of open-source multimodal models with internvl2.5.arXiv preprint arXiv:2412.05271,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Multimodal large language models for text-rich image understanding: A comprehensive review.Findings of the Association for Computational Linguistics: ACL 2025, pp
Fu, P., Guan, T., Wang, Z., Guo, Z., Duan, C., Sun, H., Chen, B., Jiang, Q., Ma, J., Zhou, K., et al. Multimodal large language models for text-rich image understanding: A comprehensive review.Findings of the Association for Computational Linguistics: ACL 2025, pp. 19941–19958,
2025
-
[6]
Google DeepMind. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025a. Google DeepMind. Gemini 3 flash: Frontier intelligence built for speed.Technical Report, 2025b. Gottlieb, J. and Oudeyer, P.-Y . Towards a neuroscience of active sampling a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Li, L., Yu, R., Hu, Q., Li, B., Deng, M., Zhou, Y ., and Jia, X. From pixels to places: A systematic benchmark for evaluating image geolocalization ability in large language models.arXiv preprint arXiv:2508.01608, 2025a. Li, L., Zhou, Y ., Liang, Y ., Tsung, F., and Wei, J. Recognition through reasoning: Reinforcing image geo- localization with large visi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
10 A Comprehensive Benchmark for Embodied Reasoning and Geo-localization in Multimodal Large Language Models Wang, C., Ye, X., Pan, X., Pan, Z., Wang, H., and Song, Y . Gre suite: Geo-localization inference via fine-tuned vision-language models and enhanced reasoning chains. arXiv preprint arXiv:2505.18700,
- [9]
-
[10]
Zhang, X. and Cheng, X. Evaluation of geolocation capabilities of multimodal large language models and analysis of associated privacy risks.arXiv preprint arXiv:2506.23481,
-
[11]
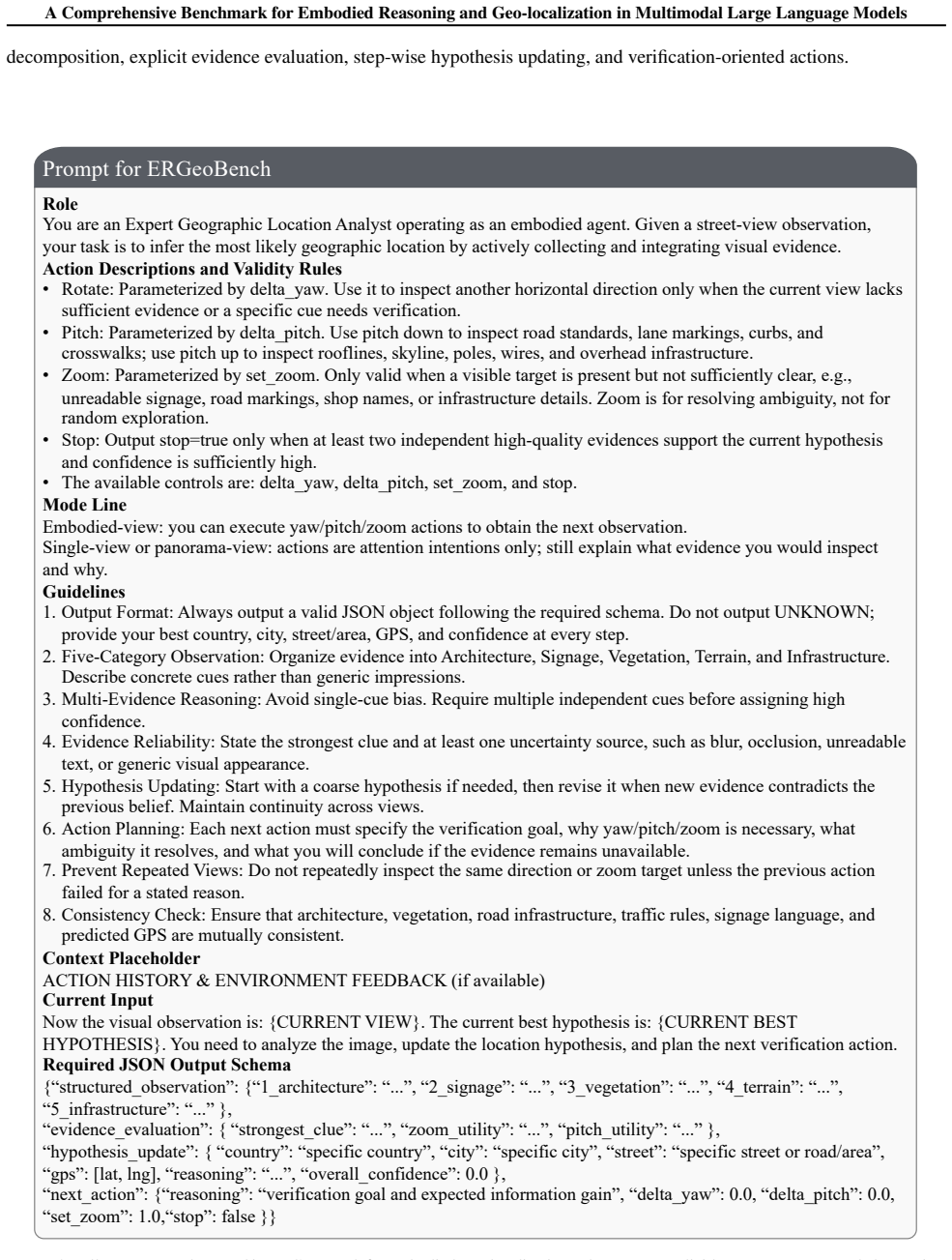
The structured schema supports automatic parsing while also requiring the model to expose evidence, uncertainty, and the intended verification action. B.5. Verification-Oriented Action Protocol The prompt constrains actions to be verification-oriented rather than arbitrary exploration. Yaw and pitch are used to search for additional evidence, while zoom i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.