Separating Secrets from Placeholders: A Hybrid CNN-CodeBERT Framework for Three-Class Credential Leakage Detection
Pith reviewed 2026-06-28 21:20 UTC · model grok-4.3
The pith
A hybrid CNN-CodeBERT model classifies code credentials into genuine leaks, placeholders, and non-credentials to cut false alerts by one third.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
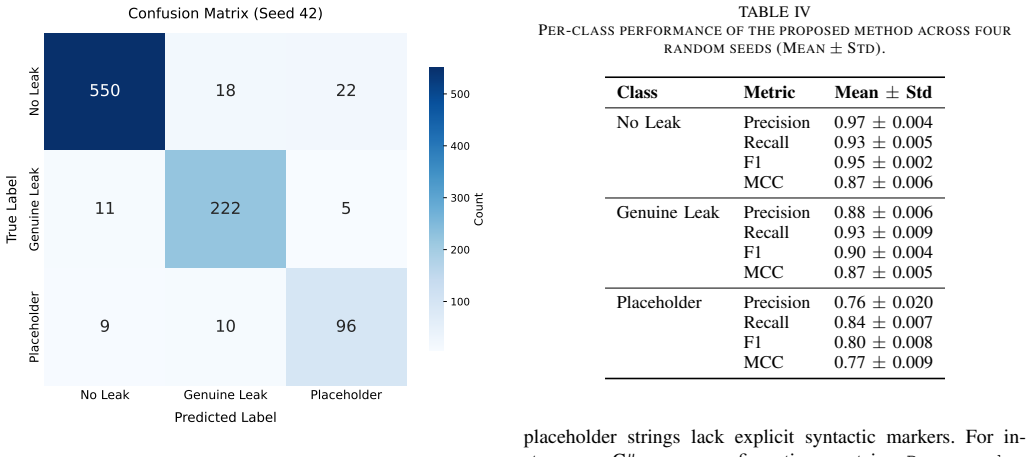
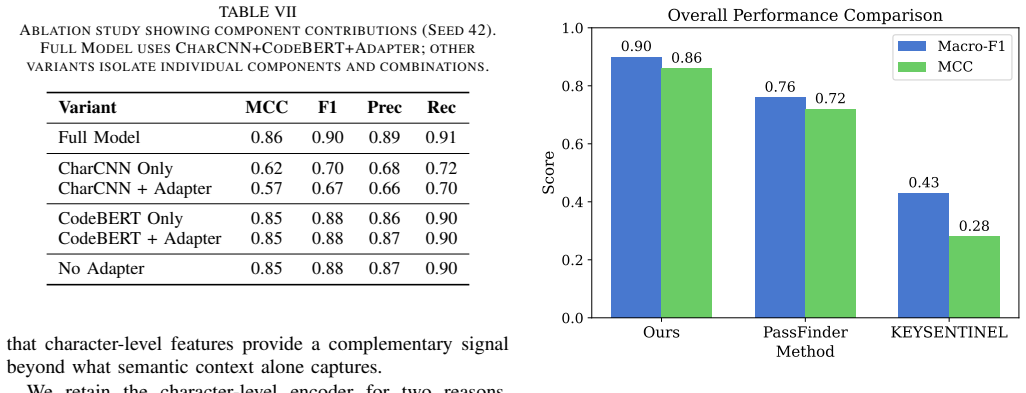
On the 9,426-sample dataset the hybrid model reaches a Matthews correlation coefficient of 0.86 and macro F1 of 0.90, delivering 93 percent recall and 89 percent precision on genuine credential leaks, cutting high-severity alerts from 373 to 250, and lifting placeholder-or-weak-credential F1 from 54 percent to 81 percent while preserving coverage across languages.
What carries the argument
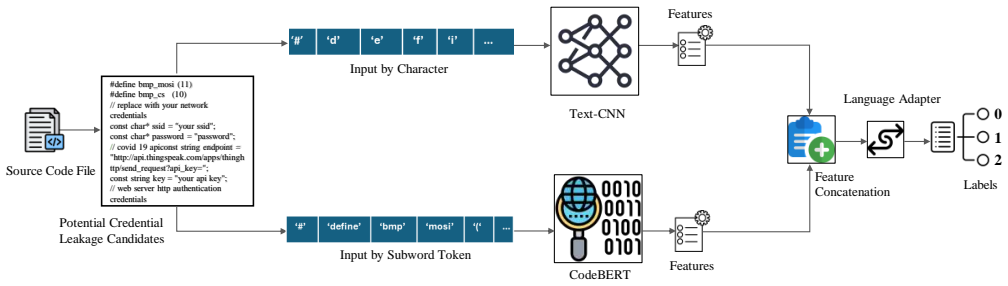
The hybrid CNN-CodeBERT three-class classifier that combines semantic embeddings from CodeBERT with character-level convolutional pattern detection.
If this is right
- Genuine credential leaks are detected at 93 percent recall and 89 percent precision.
- High-severity alerts drop by 33 percent from 373 to 250 while security coverage stays intact.
- Placeholder and weak credential detection rises from 54 percent to 81 percent F1.
- Nine of the ten languages reach F1 above 0.80 under leave-one-language-out testing.
Where Pith is reading between the lines
- Security scanning tools could integrate the three-class output to route only genuine-leak candidates to human analysts.
- The same separation of intentional placeholders from accidental leaks may generalize to other sensitive string types such as API tokens or database connection strings.
- Development environments could adopt the classifier for inline warnings that distinguish real exposures from test values without constant false alarms.
Load-bearing premise
The three-class labels assigned to the 9,426 samples are accurate and free of systematic bias or error across the ten languages.
What would settle it
Re-label a random 20 percent subset of the dataset by independent reviewers, retrain the model, and measure whether the reported MCC, F1 scores, and alert reduction remain within five percent of the original figures.
Figures
read the original abstract
Credential leakage in public source code repositories poses a critical security threat, with over 23.8 million secrets exposed in 2024 alone. Existing detection tools suffer from high false-positive rates because rigid pattern matching and binary classification schemes fail to distinguish genuine credentials from placeholder or weak credentials. We propose a three-class classification framework that explicitly models placeholder or weak credentials as a distinct class, leveraging CodeBERT-based semantic understanding combined with character-level pattern recognition. We evaluate our approach on a newly constructed dataset of 9,426 samples spanning 10 programming languages. Our model achieves a Matthews Correlation Coefficient of 0.86 and a macro F1-score of 0.90, achieving 93% recall and 89% precision for genuine credential leaks while reducing high severity alerts by 33.0% (from 373 to 250) without sacrificing security coverage. Compared to prior character-level approaches, our method improves placeholder or weak credential detection from 54% to 81% F1-score while maintaining strong cross language generalization, with 9 of 10 languages achieving F1 above 0.80 under leave-one-language-out evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hybrid CNN-CodeBERT framework for three-class credential leakage detection in source code (genuine leaks vs. placeholders/weak credentials vs. none), evaluated on a newly constructed 9,426-sample dataset spanning 10 languages. It claims MCC of 0.86, macro F1 of 0.90, 93% recall and 89% precision on genuine leaks, 33% reduction in high-severity alerts (373 to 250), and improved placeholder detection F1 from 54% to 81%, with strong leave-one-language-out generalization.
Significance. If the three-class labels prove reliable and representative, the work could meaningfully advance credential detection by explicitly modeling placeholders as a separate class, reducing alert fatigue while preserving coverage. The cross-language evaluation and comparison to prior character-level baselines are strengths that would support practical adoption in security tooling if validated.
major comments (2)
- [Abstract and dataset construction] Abstract and dataset description: All headline metrics (MCC 0.86, macro F1 0.90, 93% recall/89% precision on genuine leaks, 33% alert reduction) rest on the correctness of the three-class labels for the 9,426 samples. No annotation protocol, inter-annotator agreement, ground-truth source for secrets, or bias-mitigation steps are provided, so it is impossible to determine whether the reported gains are supported by accurate labels or undermined by mislabeling between genuine and placeholder classes.
- [Evaluation] Evaluation and results sections: The claim of reducing high-severity alerts by 33% without sacrificing security coverage, plus the per-class F1 improvements and leave-one-language-out results, cannot be assessed without details on how the test set was sampled, labeled, or validated across the 10 languages. If labeling error exceeds ~15%, both the security-coverage assertion and the cross-language generalization claim become unreliable.
minor comments (2)
- [Abstract] The abstract mentions 'character-level pattern recognition' combined with CodeBERT but provides no diagram or equation for the hybrid architecture; a figure or pseudocode would clarify the CNN integration.
- [Results] Table or figure reporting per-language F1 scores under leave-one-out evaluation is referenced but not described in sufficient detail for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the current manuscript insufficiently documents the dataset labeling process and test set construction, which are foundational to interpreting the reported metrics. We will revise the paper to provide these details.
read point-by-point responses
-
Referee: [Abstract and dataset construction] Abstract and dataset description: All headline metrics (MCC 0.86, macro F1 0.90, 93% recall/89% precision on genuine leaks, 33% alert reduction) rest on the correctness of the three-class labels for the 9,426 samples. No annotation protocol, inter-annotator agreement, ground-truth source for secrets, or bias-mitigation steps are provided, so it is impossible to determine whether the reported gains are supported by accurate labels or undermined by mislabeling between genuine and placeholder classes.
Authors: We acknowledge that the manuscript does not describe the annotation protocol. The 9,426 samples were derived from candidate strings extracted via pattern matching from public GitHub repositories across 10 languages, followed by manual labeling into genuine leaks, placeholders/weak credentials, and none. In the revised version we will add a dedicated Dataset Construction subsection that specifies the labeling guidelines (including decision criteria for distinguishing genuine credentials from placeholders based on context and entropy), the annotator background, any automated pre-filtering steps, and bias-mitigation measures such as stratified sampling by language and repository. We will also state whether multiple annotators were used and, if so, report inter-annotator agreement; if labeling was performed by a single expert, we will describe the validation steps taken. revision: yes
-
Referee: [Evaluation] Evaluation and results sections: The claim of reducing high-severity alerts by 33% without sacrificing security coverage, plus the per-class F1 improvements and leave-one-language-out results, cannot be assessed without details on how the test set was sampled, labeled, or validated across the 10 languages. If labeling error exceeds ~15%, both the security-coverage assertion and the cross-language generalization claim become unreliable.
Authors: We agree that additional information on test-set sampling and validation is required. The test portion was drawn from the full 9,426-sample corpus with explicit stratification to maintain class and language balance. In the revision we will expand the Evaluation section to detail the exact train/test split ratios, the sampling procedure, how labels on the test set were independently verified, and any sensitivity analysis of the 33% alert-reduction figure under plausible labeling-error rates. We will also include per-language breakdown tables for the leave-one-language-out experiments to further substantiate the generalization claims. revision: yes
Circularity Check
No circularity; metrics evaluated on independently constructed dataset
full rationale
The paper reports MCC 0.86 and macro F1 0.90 on a newly constructed 9,426-sample three-class dataset spanning 10 languages, with explicit leave-one-language-out evaluation and comparison to prior methods. No self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation. The central results are standard supervised classification metrics on held-out data; label construction is asserted but does not reduce any equation or claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Automated detection of password leakage from public github repositories,
R. Fenget al., “Automated detection of password leakage from public github repositories,” inProceedings of the International Conference on Software Engineering (ICSE), pp. 175–186, 2022
2022
-
[2]
IssueGuard: Real-Time Secret Leak Prevention Tool for GitHub Issue Reports
M. N. Rahman, S. Ahmed, Z. Wahab, G. Uddin, and R. Shahriyar, “IssueGuard: Real-time secret leak prevention tool for GitHub issue reports,”arXiv preprint arXiv:2602.08072, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
State of secrets sprawl 2025: The definitive annual report on the state of secrets exposure on github,
GitGuardian, “State of secrets sprawl 2025: The definitive annual report on the state of secrets exposure on github,” tech. rep., GitGuardian, March 2025
2025
-
[4]
Information about 2016 data security incident,
Uber Technologies Inc., “Information about 2016 data security incident,” 2016
2016
-
[5]
How bad can it git? characterizing secret leakage in public github repositories,
M. Meliet al., “How bad can it git? characterizing secret leakage in public github repositories,” inProceedings of the Network and Distributed System Security Symposium (NDSS), 2019
2019
-
[6]
Gitleaks: Detecting hardcoded secrets using pat- tern matching and entropy analysis
Gitleaks Project, “Gitleaks: Detecting hardcoded secrets using pat- tern matching and entropy analysis.” https://github.com/gitleaks/gitleaks, 2024
2024
-
[7]
TruffleHog: Searching for high-entropy strings and secrets in git repositories
Truffle Security, “TruffleHog: Searching for high-entropy strings and secrets in git repositories.” https://github.com/trufflesecurity/trufflehog, 2024
2024
-
[8]
A comparative study of software secrets reporting by secret detection tools,
S. K. Basaket al., “A comparative study of software secrets reporting by secret detection tools,” inProceedings of ESEM, pp. 1–12, 2023
2023
-
[9]
Asleep at the keyboard? assessing the security of ai-generated code,
A. Pearce, L. Li, and K. Sen, “Asleep at the keyboard? assessing the security of ai-generated code,” inProc. of the IEEE Symposium on Security and Privacy, pp. 765–783, 2022
2022
-
[10]
Lost at c: A user study on the security implications of large language model code assistants,
G. Sandoval, H. Pearce, T. Nys, R. Karri, S. Garg, and B. Dolan-Gavitt, “Lost at c: A user study on the security implications of large language model code assistants,” in32nd USENIX Security Symposium (USENIX Security 23), pp. 2205–2222, 2023
2023
-
[11]
Static analysis for security,
B. Chess and G. McGraw, “Static analysis for security,”IEEE Security & Privacy, vol. 2, no. 6, pp. 76–79, 2004
2004
-
[12]
Why secret detection tools are not enough: An industrial case study,
M. R. Rahmanet al., “Why secret detection tools are not enough: An industrial case study,”Empirical Software Engineering, vol. 27, no. 3, pp. 1–29, 2022
2022
-
[13]
A survey of machine learning for big code and naturalness,
M. Allamanis, E. T. Barr, P. Devanbu, and C. Sutton, “A survey of machine learning for big code and naturalness,”ACM Computing Surveys, vol. 51, no. 4, pp. 1–37, 2018
2018
-
[14]
The seven sins: Security smells in infrastructure as code scripts,
A. Rahman, C. Parnin, and L. Williams, “The seven sins: Security smells in infrastructure as code scripts,” in2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), pp. 164–175, IEEE, 2019
2019
-
[15]
Hey, your secrets leaked! detecting and characterizing secret leakage in the wild,
J. Zhouet al., “Hey, your secrets leaked! detecting and characterizing secret leakage in the wild,” inProceedings of the IEEE Symposium on Security and Privacy (SP), pp. 449–467, 2025
2025
-
[16]
Don’t leak your keys: Understanding, measuring, and exploiting the appsecret leaks in mini-programs,
Y . Zhang, Y . Yang, and Z. Lin, “Don’t leak your keys: Understanding, measuring, and exploiting the appsecret leaks in mini-programs,” in Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, pp. 2411–2425, 2023
2023
-
[17]
The skeleton keys: A large-scale analysis of credential leakage in mini- apps,
Y . Shi, G. Yang, Z. Yang, Y . Yang, M. Yang, K. Zhong, and X. Zhang, “The skeleton keys: A large-scale analysis of credential leakage in mini- apps,” inProceedings of the Network and Distributed System Security Symposium (NDSS), (San Diego, CA, USA), Internet Society, 2025
2025
-
[18]
Secrets revealed in container images: an internet-wide study on occurrence and impact,
M. Dahlmanns, C. Sander, R. Decker, and K. Wehrle, “Secrets revealed in container images: an internet-wide study on occurrence and impact,” inProceedings of the 2023 ACM Asia Conference on Computer and Communications Security, pp. 797–811, 2023
2023
-
[19]
Leaky apps: Large-scale analysis of secrets distributed in android and ios apps,
D. Schmidt, S. Schrittwieser, and E. Weippl, “Leaky apps: Large-scale analysis of secrets distributed in android and ios apps,” inProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pp. 2459–2473, 2025
2025
-
[20]
Secrets in source code: Reducing false positives using machine learning,
A. Sahaet al., “Secrets in source code: Reducing false positives using machine learning,” inProceedings of COMSNETS, pp. 168–175, 2020
2020
-
[21]
Why don’t software developers use static analysis tools to find bugs?,
B. Johnson, Y . Song, E. Murphy-Hill, and R. Bowdidge, “Why don’t software developers use static analysis tools to find bugs?,” in2013 35th International Conference on Software Engineering (ICSE), pp. 672–681, IEEE, 2013
2013
-
[22]
Evaluating static analysis defect warnings on production software,
N. Ayewah, W. Pugh, J. D. Morgenthaler, J. Penix, and Y . Zhou, “Evaluating static analysis defect warnings on production software,” in Proceedings of the 7th ACM SIGPLAN-SIGSOFT workshop on Program analysis for software tools and engineering, pp. 1–8, 2007
2007
-
[23]
Using static analysis to find bugs,
N. Ayewah, W. Pugh, D. Hovemeyer, J. D. Morgenthaler, and J. Penix, “Using static analysis to find bugs,”IEEE software, vol. 25, no. 5, pp. 22–29, 2008
2008
-
[24]
The google findbugs fixit,
N. Ayewah and W. Pugh, “The google findbugs fixit,” inProceedings of the 19th international symposium on Software testing and analysis, pp. 241–252, 2010
2010
-
[25]
Why secret detection tools are not enough: It’s not just about false positives-an industrial case study,
M. R. Rahman, N. Imtiaz, M.-A. Storey, and L. Williams, “Why secret detection tools are not enough: It’s not just about false positives-an industrial case study,”Empirical Software Engineering, vol. 27, no. 3, p. 59, 2022
2022
-
[26]
Assetharvester: A static analysis tool for detecting secret- asset pairs in software artifacts,
S. K. Basak, K. V . English, K. Ogura, V . Kambara, B. Reaves, and L. Williams, “Assetharvester: A static analysis tool for detecting secret- asset pairs in software artifacts,”arXiv preprint arXiv:2403.19072, 2024
-
[27]
Large language model for vulnerability detection: Emerging results and future directions,
X. Zhou, T. Zhang, and D. Lo, “Large language model for vulnerability detection: Emerging results and future directions,” inProceedings of the 46th International Conference on Software Engineering: New Ideas and Emerging Results (ICSE-NIER), 2024
2024
-
[28]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, and et al., “On the opportunities and risks of foundation models,”arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
H. Husain, H.-H. Wu, T. Gazit, M. Allamanis, and M. Brockschmidt, “Codesearchnet challenge: Evaluating the state of semantic code search,” arXiv preprint arXiv:1909.09436, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[30]
The vault: A comprehensive multilingual dataset for advancing code understanding and generation,
D. Nguyen, L. Nam, A. Dau, A. Nguyen, K. Nghiem, J. Guo, and N. Bui, “The vault: A comprehensive multilingual dataset for advancing code understanding and generation,” inFindings of the Association for Computational Linguistics: EMNLP 2023, pp. 4763–4788, 2023
2023
-
[31]
Codebert: A pre-trained model for programming and natural languages,
Z. Fenget al., “Codebert: A pre-trained model for programming and natural languages,” inFindings of EMNLP, 2020
2020
-
[32]
Graphcodebert: Pre-training code representations with data flow,
D. Guo, S. Ren, S. Lu,et al., “Graphcodebert: Pre-training code representations with data flow,” inProceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[33]
Unified pre- training for program understanding and generation,
W. Ahmad, S. Chakraborty, B. Ray, and K.-W. Chang, “Unified pre- training for program understanding and generation,” inProceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies, pp. 2655– 2668, 2021
2021
-
[34]
UniXcoder: Unified Cross-Modal Pre-training for Code Representation
D. Guo, S. Lu, N. Duan, Y . Wang, M. Zhou, and J. Yin, “Unixcoder: Unified cross-modal pre-training for code representation,”arXiv preprint arXiv:2203.03850, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
PyGithub: Typed interactions with the GitHub API v3
PyGithub Contributors, “PyGithub: Typed interactions with the GitHub API v3.” https://github.com/PyGithub/PyGithub, Feb. 2026
2026
-
[36]
The promises and perils of mining github,
E. Kalliamvakou, G. Gousios, K. Blincoe, L. Singer, D. M. German, and D. Damian, “The promises and perils of mining github,” inProceedings of the 11th working conference on mining software repositories, pp. 92– 101, 2014
2014
-
[37]
A systematic map- ping study of software development with github,
V . Cosentino, J. L. C. Izquierdo, and J. Cabot, “A systematic map- ping study of software development with github,”Ieee access, vol. 5, pp. 7173–7192, 2017
2017
-
[38]
Inter-coder agreement for computational linguistics,
R. Artstein and M. Poesio, “Inter-coder agreement for computational linguistics,”Computational linguistics, vol. 34, no. 4, pp. 555–596, 2008
2008
-
[39]
Character-level convolutional net- works for text classification,
X. Zhang, J. Zhao, and Y . LeCun, “Character-level convolutional net- works for text classification,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[40]
Focal loss for dense object detection,
T.-Y . Linet al., “Focal loss for dense object detection,” inProceedings of ICCV, pp. 2980–2988, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.