The Invisible Coalition Partner: How LLMs Vote When Democracy Gets Concrete
Pith reviewed 2026-07-01 00:31 UTC · model grok-4.3
The pith
LLMs show left bias on abstract surveys but align with centrist parties on concrete Swiss referenda.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
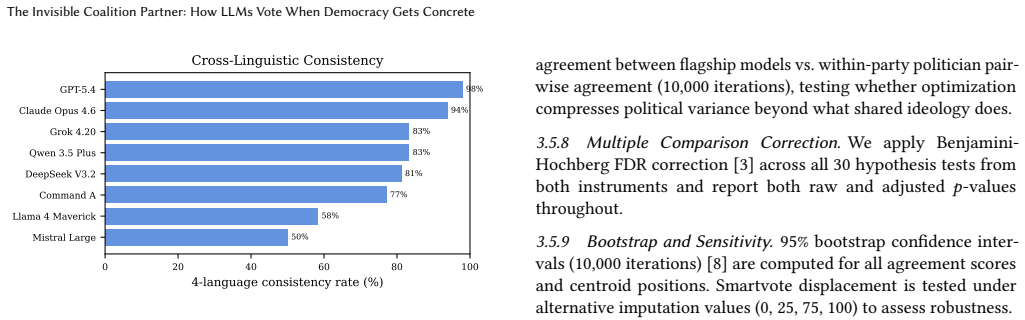
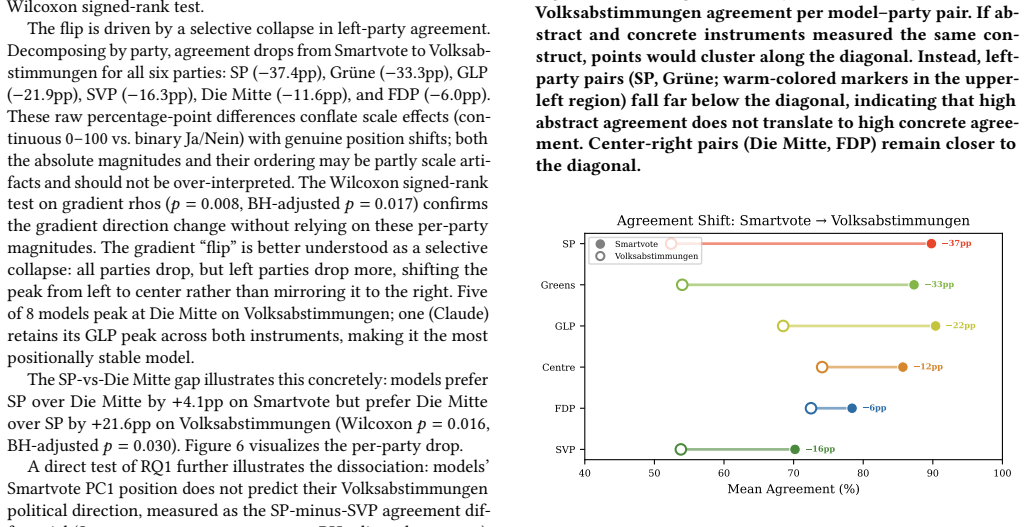
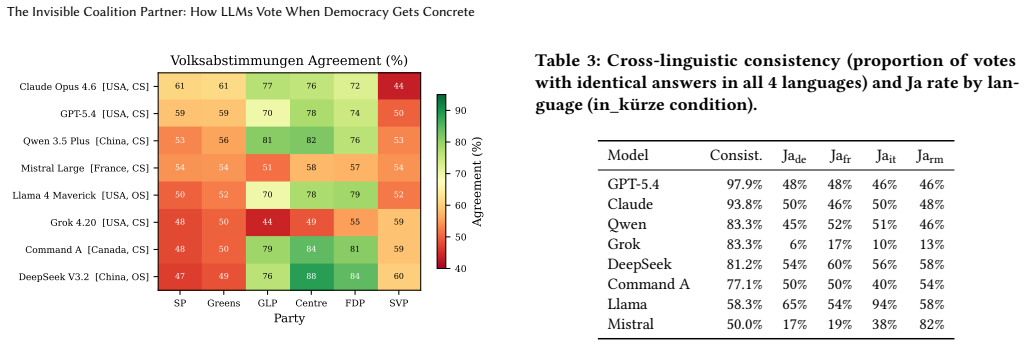
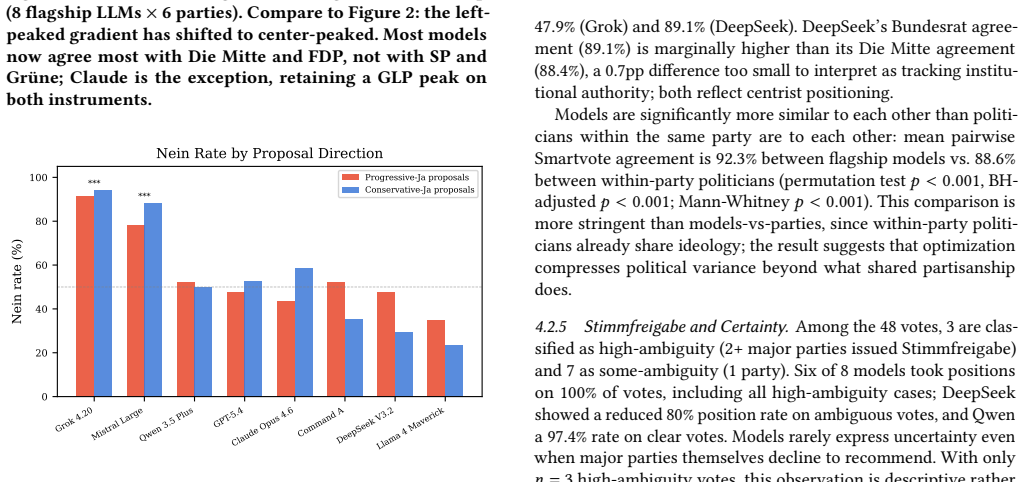
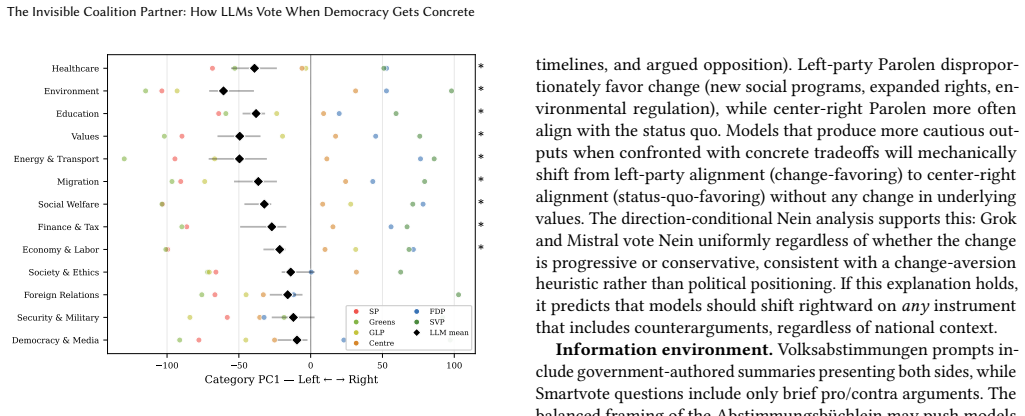
Abstract questionnaires do not predict concrete behavior: the left-to-right agreement gradient on Smartvote shifts from left-peaked to center-peaked on Volksabstimmungen, where models align most with centrist Die Mitte and FDP rather than leftist SP and Gruene. For some models language alters answers more than political content, and two models display systematic change-aversion by voting no on 83-94 percent of referenda regardless of direction.
What carries the argument
The dual-instrument methodology that contrasts abstract Smartvote questionnaire responses with votes on real Swiss federal referenda under varying information and language conditions.
If this is right
- Findings of left bias from abstract instruments may not transfer to real policy simulation tasks.
- On concrete decisions LLMs can behave more like status-quo-favoring agents than ideological coalition partners.
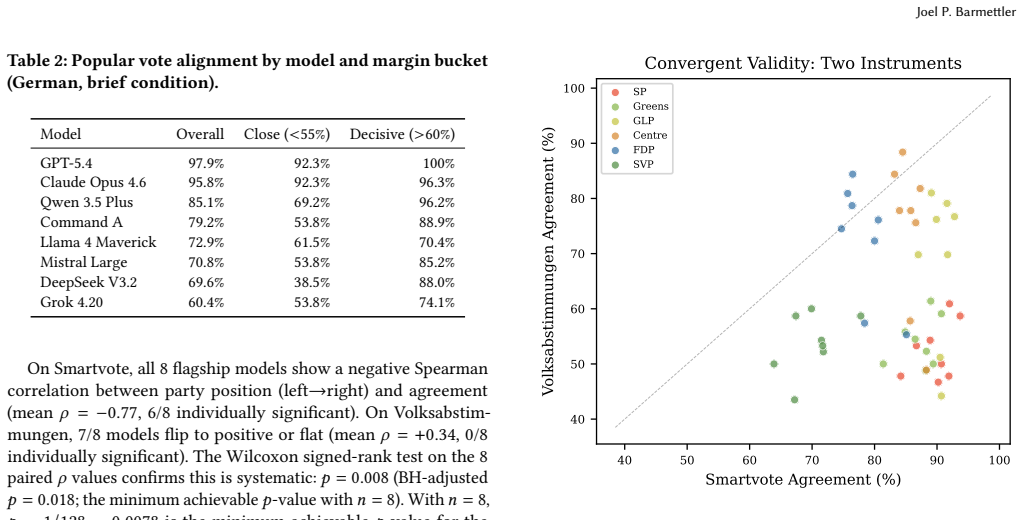
- Cross-linguistic consistency in political answers ranges widely across models from 50 to 98 percent.
- Change-aversion can dominate political alignment in certain models.
Where Pith is reading between the lines
- Similar concrete-policy tests in other countries could show whether the centrist pattern is Switzerland-specific or more general.
- Model developers might need separate evaluation tracks for abstract attitude probes versus actual decision scenarios.
- Language sensitivity in political responses suggests that multilingual consistency checks belong in standard bias audits.
Load-bearing premise
The 48 selected federal referenda and the three information conditions provide a valid test of concrete policy decision-making by LLMs.
What would settle it
A new set of referenda or additional models that produces the same left alignment on both the abstract questionnaire and the concrete votes would falsify the claim that the bias does not generalize.
Figures



read the original abstract
Prior research has established that instruction-tuned large language models exhibit left-of-center political bias, measured exclusively through abstract political questionnaires. We show that this finding does not generalize to concrete policy decisions. We introduce a dual-instrument methodology grounded in Swiss democratic reality. The Smartvote questionnaire (75 abstract policy questions) is administered to 66 LLMs from 27 model families and compared to 184 elected members of the Swiss National Council, replicating the established leftward convergence (Cohen's d = 3.64, p = 0.0002). Then, novel to this work, 9 flagship LLMs are confronted with 48 real federal referenda (Volksabstimmungen) in four national languages (German, French, Italian, Romansh) under three information conditions, comparing votes to actual outcomes and party recommendations (Parolen). Three findings challenge the prevailing narrative. (1) Abstract questionnaires do not predict concrete behavior: the left-to-right agreement gradient on Smartvote shifts from left-peaked to center-peaked on Volksabstimmungen, where models align most with centrist Die Mitte and FDP rather than leftist SP and Gruene (Wilcoxon p = 0.008). (2) For some models, the language of a political question changes the answer more than the political content does: cross-linguistic consistency ranges from 50% (Mistral) to 98% (GPT-5.4). (3) Two models exhibit systematic change-aversion rather than political bias, voting Nein on 83-94% of referenda regardless of direction (binomial p < 0.0001). What prior work measured as "leftward bias" may not generalize beyond abstract instruments. On concrete policy decisions, LLMs behave less like coalition partners of the left and more like cautious civil servants: centrist, status-quo-favoring, and inconsistent across languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit left-of-center bias on abstract questionnaires (Smartvote, 75 items; 66 models, replicating Cohen's d=3.64 vs. Swiss parliamentarians) but that this does not generalize to concrete policy decisions. On 48 real Swiss federal referenda (Volksabstimmungen) administered to 9 flagship models in four languages under three information conditions, alignment shifts to center-peaked (strongest with Die Mitte and FDP rather than SP/Gruene; Wilcoxon p=0.008), with additional findings of language-dependent answers (consistency 50-98%) and change-aversion in two models (Nein votes 83-94%, binomial p<0.0001). The dual-instrument design grounded in Swiss direct democracy is presented as evidence that prior bias measurements are instrument-specific.
Significance. If the central comparison holds, the work provides a valuable corrective to the literature on LLM political bias by demonstrating that abstract instruments do not predict behavior on real policy votes. The use of actual referenda outcomes and party Parolen as benchmarks, plus the multi-language and multi-condition design, strengthens ecological validity over purely synthetic questionnaires. This could shift how bias is measured and interpreted in applied settings.
major comments (2)
- [Methods (Volksabstimmungen instrument)] Methods section on Volksabstimmungen instrument construction: the claim that the left-to-right gradient shift is attributable to concreteness rather than framing requires explicit confirmation that referenda prompts do not systematically include party Parolen, outcome history, or multi-sentence descriptions absent from the 75 Smartvote items. Without this, the center-peaked pattern (Wilcoxon p=0.008) could arise from prompt differences independent of the abstract-concrete distinction.
- [Results (instrument comparison)] Results (instrument comparison): only 9 models are tested on the concrete referenda versus 66 on Smartvote. The generalization that abstract questionnaires do not predict concrete behavior therefore rests on a small subsample; the paper should report whether the 9 models are representative or include a sensitivity check for prompt variations.
minor comments (1)
- [Abstract] Abstract: the statement that models align most with centrist parties should specify the exact agreement metric used for the Wilcoxon test to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of instrument construction and generalizability. We address each major comment below.
read point-by-point responses
-
Referee: [Methods (Volksabstimmungen instrument)] Methods section on Volksabstimmungen instrument construction: the claim that the left-to-right gradient shift is attributable to concreteness rather than framing requires explicit confirmation that referenda prompts do not systematically include party Parolen, outcome history, or multi-sentence descriptions absent from the 75 Smartvote items. Without this, the center-peaked pattern (Wilcoxon p=0.008) could arise from prompt differences independent of the abstract-concrete distinction.
Authors: We agree that prompt details must be documented explicitly to support attribution to concreteness. The base condition uses only the official referendum title and a short neutral description (comparable in length and style to Smartvote items), with party Parolen and outcome history introduced only in the separate information conditions. We will revise the Methods section to include the full prompt templates and confirm the absence of these elements from the base prompts, thereby ruling out systematic framing differences as the source of the center-peaked pattern. revision: yes
-
Referee: [Results (instrument comparison)] Results (instrument comparison): only 9 models are tested on the concrete referenda versus 66 on Smartvote. The generalization that abstract questionnaires do not predict concrete behavior therefore rests on a small subsample; the paper should report whether the 9 models are representative or include a sensitivity check for prompt variations.
Authors: The 9 flagship models were chosen to represent leading developers and include those exhibiting the strongest left bias on Smartvote. We will add to the Results section the Smartvote scores specifically for these 9 models (which replicate the overall leftward shift) to demonstrate that the instrument comparison is not driven by atypical models. The three information conditions already serve as a robustness check against prompt variations; a broader sensitivity analysis on wording would require new experiments outside the current design. We will note the subsample size as a limitation while emphasizing the consistency of the shift on the tested models. revision: partial
Circularity Check
No significant circularity; empirical results grounded in external Swiss data
full rationale
The paper's derivation chain consists of administering the established Smartvote instrument to LLMs and comparing outputs to real Swiss National Council members (replicating prior leftward bias), then testing 9 LLMs on 48 actual federal referenda against documented outcomes and party Parolen under multiple information conditions. These comparisons rely on independent external benchmarks rather than any fitted parameters, self-defined quantities, or self-citations that reduce the central claim (abstract vs. concrete divergence) to its own inputs by construction. No equations or ansatzes are present, and the methodology is described as novel but directly tied to Swiss democratic reality without load-bearing internal loops.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Smartvote questionnaire and Volksabstimmungen represent comparable measures of political orientation.
- domain assumption LLM responses to referendum prompts can be interpreted as votes.
Reference graph
Works this paper leans on
-
[1]
Nouar Aldahoul, Hazem Ibrahim, Matteo Varvello, Aaron Kaufman, Talal Rah- wan, and Yasir Zaki. 2025. Large Language Models are often politically extreme, usually ideologically inconsistent, and persuasive even in informational contexts. arXiv:2505.04171 [cs.CY] https://arxiv.org/abs/2505.04171
-
[2]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv:2204.05862 [cs.CL] https://arxiv.org/abs/2204. 05862
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Yoav Benjamini and Yosef Hochberg. 1995. Controlling the False Dis- covery Rate: A Practical and Powerful Approach to Multiple Testing. Journal of the Royal Statistical Society: Series B (Methodological)57, 1 (1995), 289–300. arXiv:https://rss.onlinelibrary.wiley.com/doi/pdf/10.1111/j.2517- 6161.1995.tb02031.x doi:10.1111/j.2517-6161.1995.tb02031.x
-
[5]
Benjamin M. Bolker, Mollie E. Brooks, Connie J. Clark, Shane W. Geange, John R. Poulsen, M. Henry H. Stevens, and Jada-Simone S. White. 2009. Generalized linear mixed models: a practical guide for ecology and evolution.Trends in Ecology & Evolution24, 3 (01 Mar 2009), 127–135. doi:10.1016/j.tree.2008.10.008
-
[6]
Maarten Buyl, Alexander Rogiers, Sander Noels, Guillaume Bied, Iris Dominguez- Catena, Edith Heiter, Iman Johary, Alexandru-Cristian Mara, Raphaël Romero, Jefrey Lijffijt, and Tijl De Bie. 2026. Large language models reflect the ideology of their creators.npj Artificial Intelligence2, 1 (2026), 7. doi:10.1038/s44387-025- 00048-0
-
[7]
Tanise Ceron, Neele Falk, Ana Barić, Dmitry Nikolaev, and Sebastian Padó
-
[8]
Beyond Prompt Brittleness: Evaluating the Reliability and Consistency of Political Worldviews in LLMs.Transactions of the Association for Computational Linguistics12 (11 2024), 1378–1400. doi:10.1162/tacl_a_00710
-
[9]
Neutrally
Ina Dormuth, Sven Franke, Marlies Hafer, Tim Katzke, Alexander Marx, Em- manuel Müller, Daniel Neider, Markus Pauly, and Jérôme Rutinowski. 2026. A Cautionary Tale About “Neutrally” Informative AI Tools Ahead of the 2025 Fed- eral Elections in Germany. InExplainable Artificial Intelligence, Riccardo Guidotti, Ute Schmid, and Luca Longo (Eds.). Springer Na...
2026
-
[10]
1994.An introduction to the bootstrap
Bradley Efron and Robert J Tibshirani. 1994.An introduction to the bootstrap. Chapman and Hall/CRC
1994
- [11]
- [13]
-
[14]
Kobi Hackenburg and Helen Margetts. 2024. Evaluating the persuasive influence of political microtargeting with large language models.Pro- ceedings of the National Academy of Sciences121, 24 (2024), e2403116121. arXiv:https://www.pnas.org/doi/pdf/10.1073/pnas.2403116121 doi:10.1073/pnas. 2403116121
- [15]
- [16]
- [17]
-
[18]
Andreas Ladner, Jan Fivaz, and Joëlle Pianzola. 2012. Voting advice applications and party choice: evidence from smartvote users in Switzerland.International Journal of Electronic Governance5, 3-4 (2012), 367–387
2012
-
[19]
2010.Swiss Democracy: Possible Solutions to Conflict in Multicultural Societies(3rd ed.)
Wolf Linder. 2010.Swiss Democracy: Possible Solutions to Conflict in Multicultural Societies(3rd ed.). Palgrave Macmillan
2010
-
[20]
Ruibo Liu, Chenyan Jia, Jason Wei, Guangxuan Xu, and Soroush Vosoughi. 2022. Quantifying and alleviating political bias in language models.Artificial Intelli- gence304 (2022), 103654. doi:10.1016/j.artint.2021.103654
-
[21]
Fabio Motoki, Valdemar Pinho Neto, and Victor Rodrigues. 2024. More human than human: measuring ChatGPT political bias.Public Choice198, 1 (2024), 3–23. doi:10.1007/s11127-023-01097-2
-
[22]
Motoki, Valdemar Pinho Neto, and Victor Rangel
Fabio Y.S. Motoki, Valdemar Pinho Neto, and Victor Rangel. 2025. Assessing political bias and value misalignment in generative artificial intelligence.Journal of Economic Behavior & Organization234 (2025), 106904. doi:10.1016/j.jebo.2025. 106904
- [23]
- [24]
-
[25]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cour- napeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine Learning in Python.Journal of Machine Learning Research12 (2011), 2825–2830
2011
-
[26]
Tai-Quan Peng, Kaiqi Yang, Sanguk Lee, Hang Li, Yucheng Chu, Yuping Lin, and Hui Liu. 2026. Beyond partisan leaning: a comparative analysis of political bias in large language models.Journal of Information Technology & Politics0, 0 (2026), 1–18. arXiv:https://doi.org/10.1080/19331681.2026.2646990 doi:10.1080/19331681. 2026.2646990
-
[27]
Politools. 2026. smartvote: Online Voting Advice Application
2026
-
[28]
Yujin Potter, Shiyang Lai, Junsol Kim, James Evans, and Dawn Song. 2024. Hidden Persuaders: LLMs’ Political Leaning and Their Influence on Voters. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA...
-
[29]
Luca Rettenberger, Markus Reischl, and Mark Schutera. 2025. Assessing political bias in large language models.Journal of Computational Social Science8, 2 (2025),
2025
-
[30]
doi:10.1007/s42001-025-00376-w
-
[31]
Paul Röttger, Valentin Hofmann, Valentina Pyatkin, Musashi Hinck, Hannah Kirk, Hinrich Schuetze, and Dirk Hovy. 2024. Political compass or spinning arrow? towards more meaningful evaluations for values and opinions in large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1...
2024
-
[32]
David Rozado. 2023. The Political Biases of ChatGPT.Social Sciences12, 3 (2023),
2023
-
[33]
doi:10.3390/socsci12030148
-
[34]
David Rozado. 2024. The political preferences of LLMs.PLOS ONE19, 7 (07 2024), 1–15. doi:10.1371/journal.pone.0306621
- [35]
-
[36]
Jérôme Rutinowski, Sven Franke, Jan Endendyk, Ina Dormuth, Moritz Roidl, and Markus Pauly. 2024. The Self-Perception and Political Biases of Chat- GPT.Human Behavior and Emerging Technologies2024, 1 (2024), 7115633. arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1155/2024/7115633 doi:10.1155/ 2024/7115633
-
[37]
Adib Sakhawat, Tahsin Islam, Takia Farhin, Syed Rifat Raiyan, Hasan Mahmud, and Md Kamrul Hasan. 2026. Political Alignment in Large Language Mod- els: A Multidimensional Audit of Psychometric Identity and Behavioral Bias. arXiv:2601.06194 [cs.CY] https://arxiv.org/abs/2601.06194
-
[38]
Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. 2023. Whose Opinions Do Language Models Reflect?. In Proceedings of the 40th International Conference on Machine Learning (Proceed- ings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, an...
2023
-
[39]
Oleg Smirnov. 2026. The Language You Ask In: Language-Conditioned Ideological Divergence in LLM Analysis of Contested Political Documents. arXiv:2601.12164 [cs.CY] https://arxiv.org/abs/2601.12164
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Aleksandra Urman and Mykola Makhortykh. 2025. The silence of the LLMs: Cross-lingual analysis of guardrail-related political bias and false information prevalence in ChatGPT, Google Bard (Gemini), and Bing Chat.Telematics and Informatics96 (2025), 102211. doi:10.1016/j.tele.2024.102211
-
[41]
Sean J Westwood, Justin Grimmer, and Andrew B Hall. 2025. Measuring perceived slant in large language models through user evaluations.Standford Business School(2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.