Business Utility of Large Language Models as Exploratory Data Analysis Agents
Pith reviewed 2026-06-30 23:23 UTC · model grok-4.3
The pith
Most LLM configurations are not reliable enough for autonomous business exploratory data analysis even when average scores look acceptable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
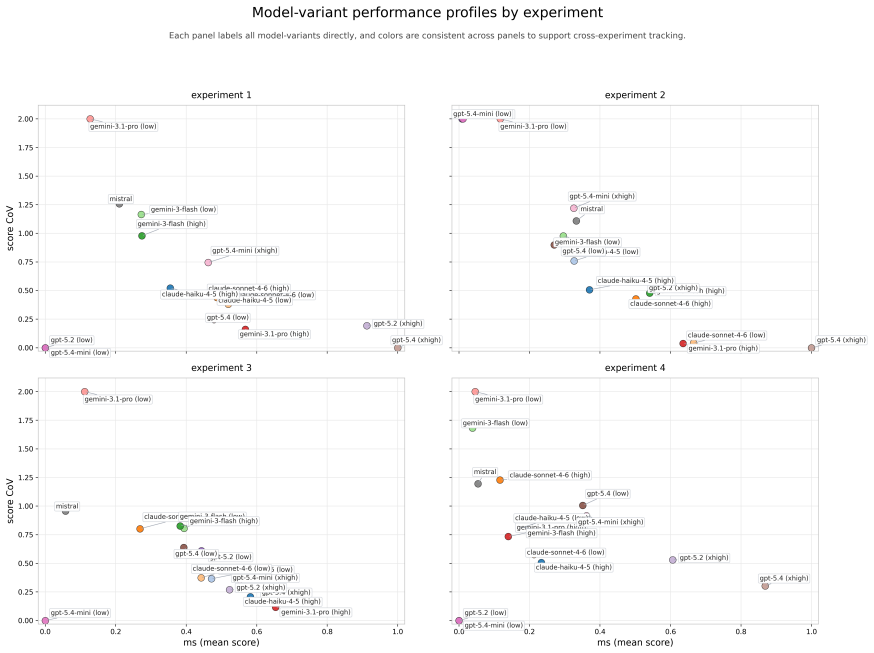
The paper claims that most of the fifteen model-variant configurations are not reliable enough for autonomous EDA use, even when their average scores appear acceptable. GPT-5.4 with extra-high reasoning effort achieved the strongest overall profile with an experiment-averaged mean score of 0.8748 and business utility of 0.6952, while the next-best configurations lost substantially more utility after variability discounting. The findings indicate that average quality, repeatability, and condition sensitivity function as complementary dimensions of operational trustworthiness.
What carries the argument
The business utility metric, a risk-adjusted measure that summarises quality and repeatability in a single operational score by discounting mean performance for output variability across repeated runs and conditions.
If this is right
- Business utility provides a single operational measure that penalises configurations whose outputs vary too much across runs or conditions.
- Most tested configurations lose substantial utility once variability is discounted, even if raw mean scores appear high.
- Evaluation of EDA agents must incorporate cross-condition significance tests in addition to mean scores and coefficients of variation.
- Only configurations that maintain both high mean scores and low variation qualify as candidates for autonomous deployment.
Where Pith is reading between the lines
- Organisations considering LLM-based EDA tools may need to run repeated trials on their own data before granting autonomous access.
- The simulation-based benchmark could be adapted to test other analytical tasks such as customer segmentation or inventory forecasting.
- Model providers might prioritise training objectives that reduce output variance rather than maximising average benchmark scores alone.
Load-bearing premise
The agent-based supply chain simulation and its indirect operational traces constitute a valid proxy for the challenges of real-world business exploratory data analysis tasks.
What would settle it
Applying the top-performing configuration to actual company operational data and measuring whether its business utility score remains comparable to the 0.6952 level obtained in the simulation.
Figures
read the original abstract
Large Language Models (LLMs) are increasingly used in analytical workflows, but their suitability as exploratory data analysis (EDA) agents in business settings remains uncertain. In practice, a deployable EDA agent must provide not only useful average performance but also sufficient repeatability to support trust in its outputs. We evaluate this requirement in a controlled, business-relevant benchmark built on an agent-based supply chain simulation. The task is to identify supplier-product combinations responsible for low quality and downstream sales loss by reasoning from indirect operational traces rather than from explicit labels. Fifteen model-variant configurations from eight model families were evaluated under four experimental conditions that varied data representation, prompt clarity, and signal strength, with five trajectories per condition. Outputs were scored against deterministic ground truth using the Jaccard index and assessed through a framework that combines mean score (ms), coefficient of variation (CV), exploratory cross-condition significance tests, and Business utility, a risk-adjusted metric that we propose to summarise quality and repeatability in a single operational measure. The results show that most configurations are not reliable enough for autonomous EDA use, even when their average scores appear acceptable. GPT-5.4 with extra-high reasoning effort achieved the strongest overall profile, with an experiment-averaged ms of 0.8748 and an experiment-averaged Business utility of 0.6952, while the next-best configurations lost substantially more utility after variability discounting. Our findings suggest that evaluation of EDA agents should treat average quality, repeatability, and condition sensitivity as complementary dimensions of operational trustworthiness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates 15 LLM configurations across 8 families as EDA agents on a supply-chain simulation benchmark. The task requires recovering supplier-product combinations from indirect operational traces using Jaccard scoring. Four conditions vary data representation, prompt clarity, and signal strength, with five trajectories each. The authors propose a new 'Business utility' metric that combines mean score (ms) and coefficient of variation (CV) into a single risk-adjusted measure. They conclude that most configurations lack sufficient repeatability for autonomous use even when average scores appear acceptable, with GPT-5.4 (extra-high reasoning) strongest at experiment-averaged ms 0.8748 and Business utility 0.6952.
Significance. If the benchmark holds, the work usefully shifts attention from average performance alone to repeatability and condition sensitivity for business deployment of LLM agents. The multi-condition design and explicit proposal of a risk-adjusted metric are strengths that could inform evaluation practices. Credit is due for testing multiple model families and for framing trustworthiness in operational terms rather than purely academic metrics.
major comments (3)
- [Abstract and Methods (metric definition)] The exact formula for Business utility (how ms is discounted or weighted by CV) is never stated, only described qualitatively as 'risk-adjusted'. This definition is load-bearing for all reported utility values (e.g., 0.6952) and for the central claim that variability causes substantial utility loss.
- [Experimental design (trajectories per condition)] Only five trajectories per condition are used to compute CV. With n=5 the sampling variability of the CV estimator itself is large, directly affecting the stability of the Business utility scores and the conclusion that 'most configurations are not reliable enough'.
- [Benchmark construction] No validation or sensitivity analysis is provided for the agent-based supply-chain simulation as a proxy for real enterprise EDA tasks. If the generated traces have lower noise or narrower ambiguity than actual business data, both the observed CVs and the utility metric will understate deployment risk, weakening the general claim about autonomous EDA suitability.
minor comments (2)
- [Results] The abstract refers to 'exploratory cross-condition significance tests' but neither the test statistic, correction method, nor any p-values appear in the provided summary; these details should be added for reproducibility.
- [Reproducibility] Raw trajectory data, exact Jaccard implementation, and prompt templates are not stated to be released; making them available would strengthen the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and Methods (metric definition)] The exact formula for Business utility (how ms is discounted or weighted by CV) is never stated, only described qualitatively as 'risk-adjusted'. This definition is load-bearing for all reported utility values (e.g., 0.6952) and for the central claim that variability causes substantial utility loss.
Authors: We agree that the precise mathematical definition of Business utility was not explicitly stated, which is an oversight given its central role. We will revise the Methods section to include the exact formula combining mean score (ms) and coefficient of variation (CV) as a risk-adjusted measure. This will ensure the reported values such as 0.6952 are fully reproducible. revision: yes
-
Referee: [Experimental design (trajectories per condition)] Only five trajectories per condition are used to compute CV. With n=5 the sampling variability of the CV estimator itself is large, directly affecting the stability of the Business utility scores and the conclusion that 'most configurations are not reliable enough'.
Authors: We acknowledge that n=5 per condition introduces substantial sampling variability in the CV estimates, which affects the precision of the Business utility metric. We will add an explicit discussion of this limitation in a new Limitations subsection, including its implications for the reliability conclusions, while noting that the design prioritizes breadth across conditions and models. revision: partial
-
Referee: [Benchmark construction] No validation or sensitivity analysis is provided for the agent-based supply-chain simulation as a proxy for real enterprise EDA tasks. If the generated traces have lower noise or narrower ambiguity than actual business data, both the observed CVs and the utility metric will understate deployment risk, weakening the general claim about autonomous EDA suitability.
Authors: The simulation is presented as a controlled proxy to isolate factors such as data representation, prompt clarity, and signal strength. We will expand the manuscript with additional discussion of the simulation's assumptions, design rationale, and potential differences from real enterprise data that could affect risk estimates. Full validation against proprietary real-world datasets is not feasible within this study. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's core claims rest on an empirical evaluation: LLMs are tested on a fixed agent-based supply chain simulation, outputs are scored deterministically via Jaccard index against ground truth, and a new composite metric (Business utility) is proposed to combine observed ms and CV. No equations, self-citations, or derivations are quoted that reduce any reported result to a fitted parameter or prior self-work by construction. The simulation and scoring procedure are externally specified and falsifiable; the metric is introduced as a summary statistic rather than a predictive derivation. This is a standard empirical benchmark study with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Jaccard index is suitable for scoring LLM-generated supplier-product sets against deterministic ground truth.
- domain assumption Five trajectories per condition suffice to estimate coefficient of variation for business utility.
invented entities (1)
-
Business utility metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Exploratory Text Data Analysis for Quality Hypothesis Generation
“Exploratory Text Data Analysis for Quality Hypothesis Generation. ” Quality Engineering 30 (4): 701–12. https://doi.org/10.1080/0898 2112.2018.1481216. Cai, Yifu, Xinyu Li, Mononito Goswami, Michał Wiliński, Gus Welter, and Artur Dubrawski
-
[2]
https://doi.org/10.48550/ARXIV.2505.13291
TimeSeriesGym: A Scalable Benchmark for (Time Series) Machine Learning Engineering Agents . https://doi.org/10.48550/ARXIV.2505.13291. Cao, Ruisheng, Fangyu Lei, Haoyuan Wu, et al
-
[3]
Chan, Jun Shern, Neil Chowdhury, Oliver Jaffe, et al
Spider2-V: How Far Are Multimodal Agents from Automating Data Science and Engineering Workflows? https://doi.org/10.48550/arXiv.2407.10956. Chan, Jun Shern, Neil Chowdhury, Oliver Jaffe, et al
-
[4]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
MLE-Bench: Evaluating Machine Learning Agents on Machine Learning Engineering . https://doi.org/10.48550/arXiv.2410.07095. Chittepu, Yaswanth, Raghavendra Addanki, Tung Mai, Anup Rao, and Branislav Kveton
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.07095
-
[5]
https://doi.org/10.48550/arXiv.2512.00672
ML- Tool-Bench: Tool-Augmented Planning for ML Tasks . https://doi.org/10.48550/arXiv.2512.00672. De Mast, Jeroen, and Albert Trip
-
[6]
Exploratory Data Analysis in Quality-Improvement Projects
“Exploratory Data Analysis in Quality-Improvement Projects. ” Journal of Quality Technology 39 (4): 301–11. https://doi.org/10.1080/00224065.2007.11917697. Egg, Alex, Martin Iglesias Goyanes, Friso Kingma, Andreu Mora, Leandro von Werra, and Thomas Wolf
-
[7]
DABstep: Data Agent Benchmark for Multi-Step Reasoning . https://doi.org/10.48550/arXiv .2506.23719. 14 Gao, Yunfan, Yun Xiong, Xinyu Gao, et al
work page internal anchor Pith review doi:10.48550/arxiv
-
[8]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-Augmented Generation for Large Language Models: A Survey . https://doi.org/10.48550/arXiv.2312.10997. Good, I. J
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997
-
[9]
The Philosophy of Exploratory Data Analysis
“The Philosophy of Exploratory Data Analysis. ” Philosophy of Science 50 (2): 283–95. https://doi.org/10.1086/289110. Hu, Xueyu, Ziyu Zhao, Shuang Wei, et al
-
[10]
https://doi.org/10.48550/arXiv.2401.05507
InfiAgent-DABench: Evaluating Agents on Data Analysis Tasks. https://doi.org/10.48550/arXiv.2401.05507. Huang, Qian, Jian Vora, Percy Liang, and Jure Leskovec
-
[11]
https://doi.org/10.48550/arXiv.2410.07331
DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models . https://doi.org/10.48550/arXiv.2410.07331. Jansen, Jacqueline A., Artür Manukyan, Nour Al Khoury, and Altuna Akalin
-
[12]
Leveraging Large Language Models for Data Analysis Automation
“Leveraging Large Language Models for Data Analysis Automation. ” PLOS ONE 20 (2): e0317084. https: //doi.org/10.1371/journal.pone.0317084. Jimenez, Carlos E., John Yang, Alexander Wettig, et al
-
[13]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
SWE-Bench: Can Language Models Resolve Real-World GitHub Issues? https://doi.org/10.48550/arXiv.2310.06770. Jing, Liqiang, Zhehui Huang, Xiaoyang Wang, et al
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06770
-
[14]
Kahneman, Daniel, and Amos Tversky
DSBench: How Far Are Data Science Agents to Becoming Data Science Experts? https://doi.org/10.48550/arXiv.2409.07703. Kahneman, Daniel, and Amos Tversky
-
[15]
Prospect theory: An analysis of decision under risk
“Prospect Theory: An Analysis of Decision Under Risk. ” Econometrica 47 (2): 263–91. https://doi.org/10.2307/1914185. Łabędzki, Rafał, Katarzyna Mikołajczyk, Anna Biłyk, and Monika Trojanowska
-
[16]
Understanding Human-AI Collaboration: A Systematic Review of Challenges and Research Methods in Manage- ment
“Understanding Human-AI Collaboration: A Systematic Review of Challenges and Research Methods in Manage- ment. ” In HCI International 2025 Posters , edited by Constantine Stephanidis, Margherita Antona, Stavroula Ntoa, and Gavriel Salvendy, vol
2025
-
[17]
Communications in Computer and Information Science. Springer. https://doi.org/10.1007/978-3-031-94171-9_32 . Lai, Yuhang, Chengxi Li, Yiming Wang, et al
-
[18]
https://doi.org/10.48550/arXiv.2211.11501
DS-1000: A Natural and Reliable Benchmark for Data Science Code Generation . https://doi.org/10.48550/arXiv.2211.11501. Lei, Fangyu, Jinxiang Meng, Yiming Huang, et al
-
[19]
https://doi.org/10.48550/arXiv.2512.04324
DAComp: Benchmarking Data Agents Across the Full Data Intelligence Lifecycle . https://doi.org/10.48550/arXiv.2512.04324. Li, Hanyu, Haoyu Liu, Tingyu Zhu, et al
-
[20]
https://doi.org/10.48550/arXiv.2505.18223
IDA-Bench: Evaluating LLMs on Interactive Guided Data Analysis . https://doi.org/10.48550/arXiv.2505.18223. Li Vigni, Mario, Caterina Durante, and Marina Cocchi
-
[21]
https://doi.org/10.1016/B978-0-444-59528- 7.00003-X
Elsevier. https://doi.org/10.1016/B978-0-444-59528- 7.00003-X. Li, Xinyi, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang
-
[22]
https://doi.org/10.48550/arXiv.2401.02982
BIBench: Benchmarking Data Analysis Knowledge of Large Language Models . https://doi.org/10.48550/arXiv.2401.02982. Liu, Xinyu, Shuyu Shen, Boyan Li, Nan Tang, and Yuyu Luo
-
[23]
NL2SQL-BUGs: A Benchmark for Detecting Semantic Errors in NL2SQL Translation
“NL2SQL-BUGs: A Benchmark for Detecting Semantic Errors in NL2SQL Translation. ” Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining , August, 5662–73. https://doi.org/10.1145/37 15 11896.3737427. Luo, Tianqi, Chuhan Huang, Leixian Shen, et al
-
[24]
https://doi.org/10.48550/ARXIV.2503.12880
nvBench 2.0: Resolving Ambiguity in Text-to- Visualization Through Stepwise Reasoning . https://doi.org/10.48550/ARXIV.2503.12880. Morgenthaler, Stephan
-
[25]
“Exploratory Data Analysis. ” WIREs Computational Statistics 1 (1): 33–44. https://doi.org/10.1002/wics.2. Rahman, Mizanur, Md Tahmid Rahman Laskar, Shafiq Joty, and Enamul Hoque
-
[26]
https: //doi.org/10.48550/arXiv.2507.19969
Text2Vis: A Challenging and Diverse Benchmark for Generating Multimodal Visualizations from Text . https: //doi.org/10.48550/arXiv.2507.19969. Tang, Xiangru, Yuliang Liu, Zefan Cai, et al
-
[27]
https://doi.org/10.48550/arXiv.2311
ML-Bench: Evaluating Large Language Models and Agents for Machine Learning Tasks on Repository-Level Code . https://doi.org/10.48550/arXiv.2311. 09835. Tukey, John Wilder
-
[28]
Advances in Prospect Theory: Cumulative Representa- tion of Uncertainty
“Advances in Prospect Theory: Cumulative Representa- tion of Uncertainty. ” Journal of Risk and Uncertainty 5 (4): 297–323. https://doi.org/10.1007/BF 00122574. Wang, Ziting, Shize Zhang, Haitao Yuan, et al
-
[29]
FDABench: A Benchmark for Data Agents on Analytical Queries over Heterogeneous Data
FDABench: A Benchmark for Data Agents on Analytical Queries over Heterogeneous Data . https://doi.org/10.48550/arXiv.2509.02473. Zhang, Dan, Sining Zhoubian, Min Cai, et al
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.02473
-
[30]
https://doi.org/10.48550/arXiv.2502.13897
DataSciBench: An LLM Agent Benchmark for Data Science. https://doi.org/10.48550/arXiv.2502.13897. Zhang, Yuge, Qiyang Jiang, Xingyu Han, Nan Chen, Yuqing Yang, and Kan Ren
-
[31]
https://doi.org/10.48550/arXiv.2402.17168
Benchmarking Data Science Agents . https://doi.org/10.48550/arXiv.2402.17168. Zhu, Zhenghao, Yuanfeng Song, Xin Chen, et al
-
[32]
https://doi.org/10.48550/arXiv.2511.2288
InsightEval: An Expert-Curated Benchmark for Assessing Insight Discovery in LLM-Driven Data Agents . https://doi.org/10.48550/arXiv.2511.2288
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.